
偽情報撲滅を目指すAI~最新のディープフェイク検知技術~

生成AI技術が発展し、近年ディープフェイクは大きな社会問題となっています。前々回の記事でお伝えしたとおり、ディープフェイクには大きくテキスト、画像、音声、動画の4つの形態があり、それぞれの領域で検知技術が研究されています。前回の記事では、テキストと画像の最新論文を紹介しました。今回は、音声・動画のディープフェイクを検知する最新論文を紹介します。
音声・動画ディープフェイク検知
CVPR 2023 workshopに採択された音声・動画検出の最新論文を紹介します。「Multimodaltrace: Deepfake Detection using Audiovisual Representation Learning」
既存手法と本手法の比較
既存手法は(a) Ensemble models, (b) Single Label Multiclass multimodalの2タイプありますが、それらは主に動画か音声のどちらか一方しか扱えませんでした。本研究では、動画と音声それぞれの信頼度を予測できる新モデル「Multimodaltrace」を提案しています。((c) Multilabel multiclass multimodal)。
(a) Ensemble models
音声用のモデルと映像用のモデルを別々に学習させ、最終的にそれらの出力を組み合わせて判定を行います。
音声モデルと映像モデルをそれぞれ学習し、両モデルの出力スコアの平均をとるなどの手法がこれに該当します。
音声と映像の関係性を活用しきれないのが課題です。
(b) Single Label Multiclass multimodal
音声と映像の両方の入力を受け取り、単一のモデルで学習を行います。
出力は複数のクラス(リアル、フェイク音声のみ、フェイク映像のみ、両方フェイクなど)の中から1つを選択する多クラス分類となります。
単一ラベルでは、マルチラベル出力に比べて詳細な判定ができない。
(c) Multilabel multiclass multimodal (proposed)
入力は(b)と同様に音声と映像の両方を受け取りますが、出力はマルチラベル分類となっています。
つまり、音声がリアル/フェイクか、映像がリアル/フェイクかを、それぞれ別個のラベルで出力します。
マルチラベル分類で詳細な判定を行いつつ、モダリティ間の関係性も効果的に捉えられるよう設計しています。

(b) Single Label Multiclass multimodal
(c) Multilabel multiclass multimodal (本論文の提案手法)
検知モデル
提案モデル(Multimodaltrace)では、動画と音声の両方から特徴を抽出し、それらを組み合わせることで高い精度でディープフェイクを検出することができます。
まず、動画と音声それぞれから特徴量を抽出する処理を行います。
次に、抽出した動画と音声の特徴量を、それぞれ別々の「IntrAmodality Mixer Layer」に入力します。このレイヤーは、同じモダリティ(動画または音声)内の特徴量同士を組み合わせる役割があります。例えば、動画の特徴量同士を掛け合わせたり、足し合わせたりすることで、より高次の特徴を生成します。
その後、動画と音声のそれぞれの高次特徴量を「IntErmodality Mixer Layer」に入力します。このレイヤーでは、動画と音声のモダリティ間の関係性を学習し、それらを統合した特徴量を生成します。ディープフェイクでは、動画と音声の同期が合っていない場合が多いため、この統合された特徴量が重要な手がかりとなります。
最後に、統合された特徴量を分類器に入力し、動画と音声がそれぞれリアルかフェイクかを判定するマルチラベル分類を行います。

検証データセット
研究チームはFakeAVCeleb、World Leaders、Presidential Deepfake Detection(PDD)の3つのデータセットでMultimodaltraceを評価しました。FakeAVCelebデータセットを学習に用い、後者2つで転移学習を行いました。
WLDはFaceSwap、LipSync、Imposterの3つのサブセットに分かれており、それぞれ顔入れ替え、口元合成、すり替えによるディープフェイクを含んでいます。PDDは大統領のディープフェイクビデオから成るデータセットです。
PDDのデータの例:トランプ大統領がオバマ大統領に関する偽のスピーチを行っている動画
検証結果
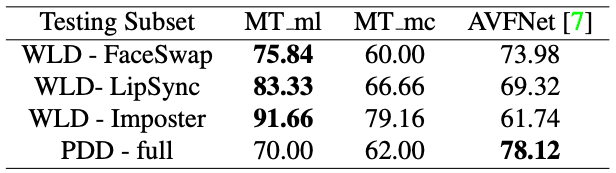
下表の1列目が評価に使用したデータセットのサブセットを表しています。
2列目と3列目は、マルチラベル分類(MT ml)とマルチクラス分類(MT mc)を用いたMultimodaltraceのそれぞれの正解率(Accuracy)、4列目は、アンサンブル手法(上で書いたタイプaのモデル)であるAVFNetの正解率が記載されており、提案手法と比較をしています。
結果を見ると、マルチラベル分類(MT ml)がほとんどの評価セットにおいて最も高い精度を示していることが分かります。つまり、ディープフェイク動画検知のタスクをマルチラベル分類とみなすことで、特定の改ざんに対して高い精度が出せるというわけです。
とはいえ、FaceSwap(顔の入れ替え)やLipSync(口の動きの調整)の性能は90%に満たず、まだまだ改善の余地がありそうです。
まとめ
Multimodaltrace は、動画と音声の両モダリティを活用することで、動画のディープフェイク検出に高い精度を発揮しています。特に、動画と音声の同期がずれている典型的なディープフェイク動画を的確に検知できます。しかし、テキストや画像ほど汎用的に高い性能が出せていないのが現状です。
そのため、今後はさまざまなモダリティに対応できる、より汎用的なディープフェイク検知技術の開発が求められます。
■「TDAI Labについて」
当社は2016年11月創業、東京大学大学院教授鳥海不二夫研究室(工学系研究科システム創成学専攻)発のAIベンチャーです。AIによる社会的リスクを扱うリーディングカンパニーとして、フェイクニュース対策や生成AIの安全な利用法について発信しています。