
偽情報と戦うAI ~最新のディープフェイク検知技術~

ディープフェイクによる偽情報が社会問題化する中、その対策技術の研究が加速しています。前回の記事でお伝えしたとおり、ディープフェイクには大きくテキスト、画像、音声、動画の4つの形態があり、それぞれの領域で検知技術が研究されています。今回は、最新の研究動向に焦点を当てて、主にテキストと画像の最新論文を紹介します。
テキスト
テキスト内の偽情報検出に関しては、今年Google DeepMindから発表された最新論文を紹介します。
「LONG-FORM FACTUALITY IN LARGE LANGUAGE MODELS」(2024)
大規模言語モデル(LLM)は返答の中で嘘が混じることがあることが知られています。本研究では、LLMが生成した長文テキストの事実性を定量的に評価する手法「SAFE(Search-Augmented Factuality Evaluator)」が提案されています。
SAFEではまず、下図のように、LLMの長文の出力を一つひとつの事実に分解します。次にGoogle検索を活用して関連する根拠を抽出します。Googleの結果によって各事実がサポートされるかどうかをLLMで評価することで、最終的に長文が事実なのかを評価します。人が一つ一つ事実確認するのとかなり近いシステムになっています。

サポートされるかどうかをLLMで自動化的できるのは人手を大幅に減らすために重要です。ちなみに使用したプロンプトは以下になっています。
Instructions:
1. You have been given a STATEMENT and some KNOWLEDGE points.
2. Determine whether the given STATEMENT is supported by the given KNOWLEDGE. The STATEMENT does not need to be explicitly supported by the KNOWLEDGE, but should be strongly implied by the KNOWLEDGE.
3. Before showing your answer, think step-by-step and show your specific reasoning. As part of your reasoning, summarize the main points of the KNOWLEDGE.
4. If the STATEMENT is supported by the KNOWLEDGE, be sure to show the supporting evidence.
5. After stating your reasoning, restate the STATEMENT and then determine your final answer based on your reasoning and the STATEMENT.
6. Your final answer should be either “Supported” or “Not Supported”. Wrap your final answer in square brackets.
KNOWLEDGE:
[SEARCH RESULT #1] [SEARCH RESULT #2]
...
[SEARCH RESULT #N-1]
STATEMENT:
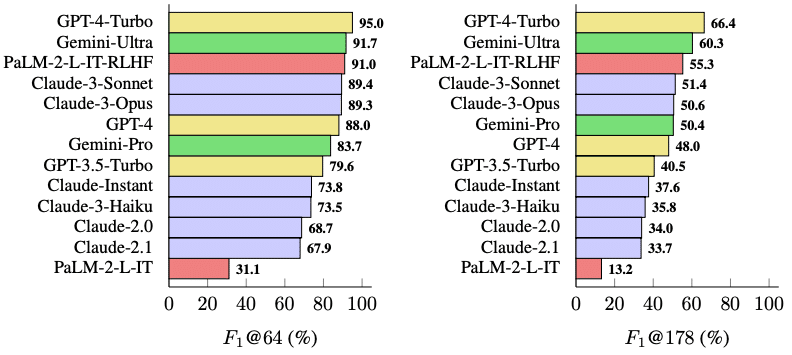
[INDIVIDUAL FACT]評価するための長文生成にあたって、研究チームは38のさまざまな分野にわたる2,280のプロンプト(質問)セット「LongFact」を生成し、13の大規模モデルに解答させて比較評価を行なっています。
実験の結果、より大規模なモデルほど長文の事実性が高い傾向があり、近年登場した13個のLLMを比較すると、GPT-4-Turboが最も事実性の高い長文を出力できることが分かりました。
画像
画像においても、ディープフェイク検知に関する最新研究が活発に行われています。ここでは2つの注目の論文を取り上げて解説します。
最初に紹介する画像検出の最新論文はこちらです。
「Detecting and Grounding Multi-Modal Media Manipulation」(CVPR 2023)
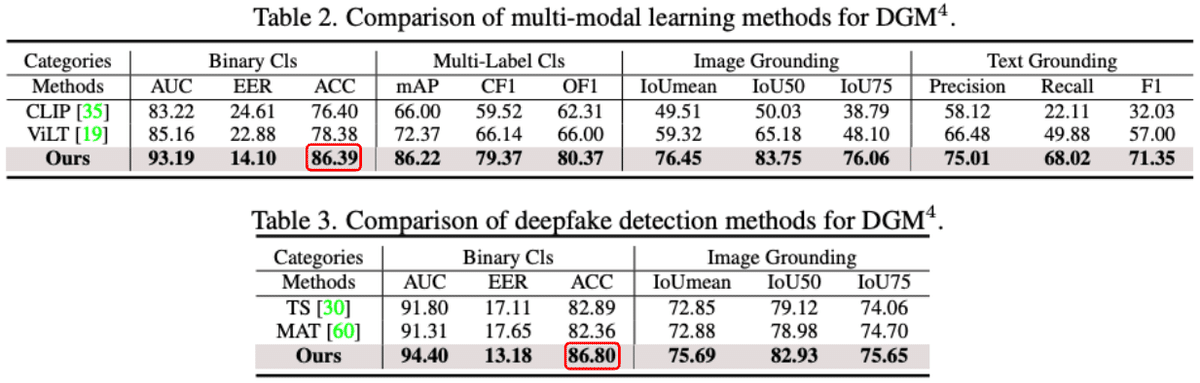
画像と文章の両方を対象としたマルチモーダルなファクトチェックモデル「HAMMER(HierArchical Multi-modal Manipulation rEasoning tRansformer)」が提案されています。
このモデルは、入力されたメディアがフェイクかどうか、どのような加工が施されているか、さらにはその加工箇所を同時に特定できます。判定には入力情報のみを用い、外部情報(ウェブなど)は必要ありません。
画像とテキストの特徴量をそれぞれ抽出した上で、双方の関係性を段階的に捉えていきます。序盤の段階ではそれぞれのモダリティの整合性を確認し、終盤の段階では組み合わせた特徴量から偽作為の検出や具体的箇所の特定を行います。

研究チームは、画像・テキストが組み合わされた23万件におよぶ大規模なマルチモーダルのフェイク検知・箇所検知用データセットを作成しています。
実験の結果、HAMMERが既存の単一モダリティ手法やマルチモーダル手法を大きく上回る86.%の正解率を達成しました。
続いて紹介する画像検出の最新論文はこちらです。
「Open-domain, content-based, multi-modal fact-checking of out-of-context images via online resources.」(CVPR 2022)
画像とテキストのペアの真偽を確認するために、人間の検証プロセスをモデル化し、ウェブ上の根拠情報を用いて検証する手法「CCN(Consistency-Checking Network)」が提案されています。
入力テキストの根拠収集には入力画像を、入力画像の根拠収集には入力テキストを相互に活用します。

さらに、CLIP、ResNet、BERTなどの複数モデルを組み合わせ、収集した画像同士およびテキスト同士の入力と根拠情報の一貫性を測定しています。

実験では最大84.7%の正解率を達成し、従来手法を大きく上回りました。さらに人による評価実験では、この手法が人並みのファクトチェック能力を持つことが示されました。

まとめ
以上が、ディープフェイク検知技術の最新の研究動向の一部です。各形態において着実に進歩が見られる一方で、ディープフェイク生成技術の進化のスピードにも注目が集まっています。検知と生成の技術的な攻防が今後も続くことが予想されます。私たちは、ディープフェイクによる偽情報から身を守るため、常に最新の技術動向を注視する必要があります。検知技術の進化は勿論のこと、併せて法制度の整備や教育の推進など、多角的なアプローチが重要となっていきます。
■「TDAI Labについて」
当社は2016年11月創業、東京大学大学院教授鳥海不二夫研究室(工学系研究科システム創成学専攻)発のAIベンチャーです。AIによる社会的リスクを扱うリーディングカンパニーとして、フェイクニュース対策や生成AIの安全な利用法について発信しています。