python:【第1弾】機械にパチスロ大当たり回数を予測させる

いままで色々、機械学習に取り組んできましたが、このブログで人気であるパチスロ関連のデータで機械学習に挑んでみます。
実用的なものになるまで時間がかかりそうなので、何回かにわけて、制作過程を記載し、最終的に整理した記事をわかりやすく、公開していこうと思います。
データの準備
台データオンラインの下記の部分をスクレイピングして、データを取ってみます。
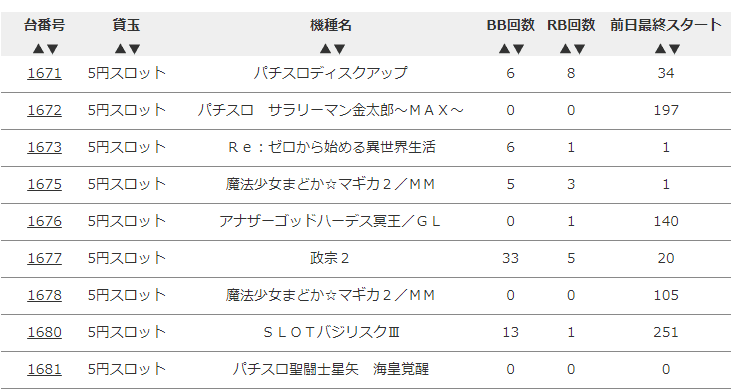
各種ライブラリのインポート
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
各項目の取得
num = 0
data_list = []
store_no = input("店舗番号を入力してください:")
for i in range(1,99,1):
url = "https://daidata.goraggio.com/" + store_no + "/all_list?ps=S&hist_num=" + str(i)
html = urlopen(url)
bsObj = BeautifulSoup(html, "html.parser")
table = bsObj.findAll("table", {"class":"tablesorter"})[0]
try:
for num in range(0,10000,1):
td = table.findAll("td")[num].text
data_list.append(td)
num += 1
print("データ取得件数:"+ str(num) +"件")
except IndexError:
print("データ取得完了")
データの成形とCSV化
data_list_np = np.array(data_list)
a = int(len(data_list_np) / 7)
data_list_np2 = data_list_np.reshape([a, 7])
df = pd.DataFrame(data_list_np2)
df.columns = [' ', '台番号', '貸玉', '機種名', 'BB回数', 'RB回数', '前日最終スタート']
df.to_csv("test.csv", index=None, encoding="utf-8_sig")とりあえず、ここまで実行してみます。すると以下のような形でデータが取得できます。

※日付を抽出するのを忘れてたので、後でCSVファイル上で付け足しました。
データの前処理
・各種ライブラリのインポート
import pandas as pd
import category_encoders as ce
from sklearn.ensemble import RandomForestRegressor
・さきほど抽出した学習ファイルの読み込み
train = pd.read_csv("C:/Users/user/Desktop/pachidata/train.csv")
・データの追加
train["jackpot"] = train["BB回数"] + train["RB回数"]
train["year"] = train["日付"].apply(lambda x : x.split("/")[0])
train["month"] = train["日付"].apply(lambda x : x.split("/")[1])
train["day"] = train["日付"].apply(lambda x : x.split("/")[2])
・『機種名』を数値化
#カラムの指定
columns = ["機種名", "貸玉"]
#数値化したい文字列を指定
change_columns = ce.OrdinalEncoder(cols=columns,handle_unknown='impute')
#数値化した文字列に変換
train_rev = change_columns.fit_transform(train)
train_rev.head()
予測
・説明変数x_trainと目的変数y_trainの設定
x_train = train_rev[["台番号", "貸玉", "機種名", "year", "month", "day"]]
y_train = train_rev["jackpot"]
モデルの構築
model = RandomForestRegressor()
model.fit(x_train, y_train)アルゴリズムは『ランダムフォレスト』を使用。ランダムフォレストは、決定木を弱学習器とする集団学習アルゴリズム
結果を見てみる
pred = model.predict(x_train)
train_rev["pred"] = pred
train_rev["GAP"] = train_rev["jackpot"]- train_rev["pred"]
train_rev.head()

GAPはありますが、大きくは外れていないような感じです。。
テストファイルでも試してみる
#テストファイルの読み込み
test = pd.read_csv("C:/Users/user/Desktop/pachidata/test.csv")
#データの追加
test["jackpot"] = test["BB回数"] + test["RB回数"]
test["year"] = test["日付"].apply(lambda x : x.split("/")[0])
test["month"] = test["日付"].apply(lambda x : x.split("/")[1])
test["day"] = test["日付"].apply(lambda x : x.split("/")[2])
#データの追加2
change_columns2 = ce.OrdinalEncoder(cols=columns,handle_unknown='impute')
test_rev = change_columns2.fit_transform(test)
test_rev.head()
#説明変数 、目的変数の設定
x_test = test_rev[["台番号", "貸玉", "機種名", "year", "month", "day"]]
y_test = test_rev["jackpot"]
#モデルの構築
model = RandomForestRegressor()
model.fit(x_test, y_test)
#モデルで予測
pred_test = model.predict(x_test)
test_rev["pred"] = pred_test
test_rev["GAP"] = test_rev["jackpot"] - test_rev["pred"]
test_rev.head()
#CSV化
test_rev.to_csv("test_rev.csv", encoding="utf-8_sig")グラフで実績と予測を比較してみる
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
plt.plot(test_rev["pred"], color="green")
plt.plot(test_rev["jackpot"], color="yellow", linestyle="dashed")
plt.show()

大体の流れは大きく外れていないような感じですね。。
翌日を予測してみる
ひな形データを準備

上記のような店舗に置いている台番号や貸玉、機種名が記載された一覧を作成しておく
データ成形
template["日付"] = "2020/4/5"
template["year"] = template["日付"].apply(lambda x : x.split("/")[0])
template["month"] = template["日付"].apply(lambda x : x.split("/")[1])
template["day"] = template["日付"].apply(lambda x : x.split("/")[2])
change_columns3 = ce.OrdinalEncoder(cols=columns,handle_unknown='impute')
template_rev = change_columns3.fit_transform(template)
template_rev.head()
x_test = template_rev[["台番号", "貸玉", "機種名", "year", "month", "day"]]
pred_template = model.predict(x_test)
template_rev["pred"] = pred_template
template_rev.head()
template_rev.to_csv("C:/Users/user/Desktop/pachidata/answer.csv", encoding="utf-8_sig")
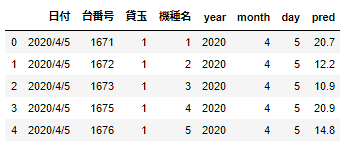
とりあえず、まだ完成形とは言えませんが、とりあえずは実装完了となります。
まだまだ、発展途上なので、第二弾でその部分について、修正追加していきます。最終的には、整理して、見やすいような記事にして投稿をする予定ですのでよろしくお願いします。
過去記事
この記事が気に入ったらサポートをしてみませんか?