ChatGPTを動かす機械学習モデルTransformerをゼロから理解する。

Transformerは、簡単に言うと文章の文脈に合わせて、次に来る確率の高い単語で文章の続きを生成する技術です。A I脅威論やシンギュラリティなどで盛り上がってますが、いたずらに不安をかき立てる前に、アルゴリズムを通して本質を理解しましょう。
以下の説明がわかりやすかったので翻訳してみました。英語がわかる人は原文を読んだ方が早いです。
以下の本文
※かなり単純化しているので、詳細を知りたい方は本記事最後の専門書を参照してください。
Transformerとは具体的に何をするのでしょうか?携帯電話でテキストメッセージを入力しているときを想像してください。単語を入力した後に、3つの候補が表示されることがあります。例えば、「Hello, how are」と入力すると、次の単語として「you」や「your」が提案されることがあります。もちろん、携帯電話で提案された単語を選択し続けると、構成されるメッセージはデタラメになります。3つか4つの連続する単語だけ見ると意味があるかもしれませんが、続けて選択すると単語が意味のある文章になることはありません。これは、携帯電話で使用されているモデルがメッセージ全体の文脈を考慮していないためであり、入力者の過去の履歴によって予測しているためです。一方、Transformerは書かれている文脈を追跡し続けるため、最終的なテキストは意味が通るものとなります。

では、なぜトランスフォーマーモデルが単語ごとにテキストを構築するのでしょうか?単純に、それが非常にうまくいくからです。もっと言うと、トランスフォーマーが文脈を追跡するのが非常に優れているため、次に選ぶ単語が文脈を続けるために必要だということを自動で選択できるからです。 では、トランスフォーマーはどのように訓練されるのでしょうか?大量のデータ、実際にはインターネット上のすべてのデータを使って訓練されます。ですから、「Hello, how are」という文をトランスフォーマーに入力すると、インターネット上のすべてのテキストに基づいて、最適な次の単語は「you」であると瞬時にわかります。もっと複雑なコマンドを与えると、例えば、「Write a story.」とすると、次に使用する良い単語は「Once」と判断するかもしれません。そして、この単語をコマンドに追加し、次の良い単語が「upon」であると判断し、以降も同様に続きます。

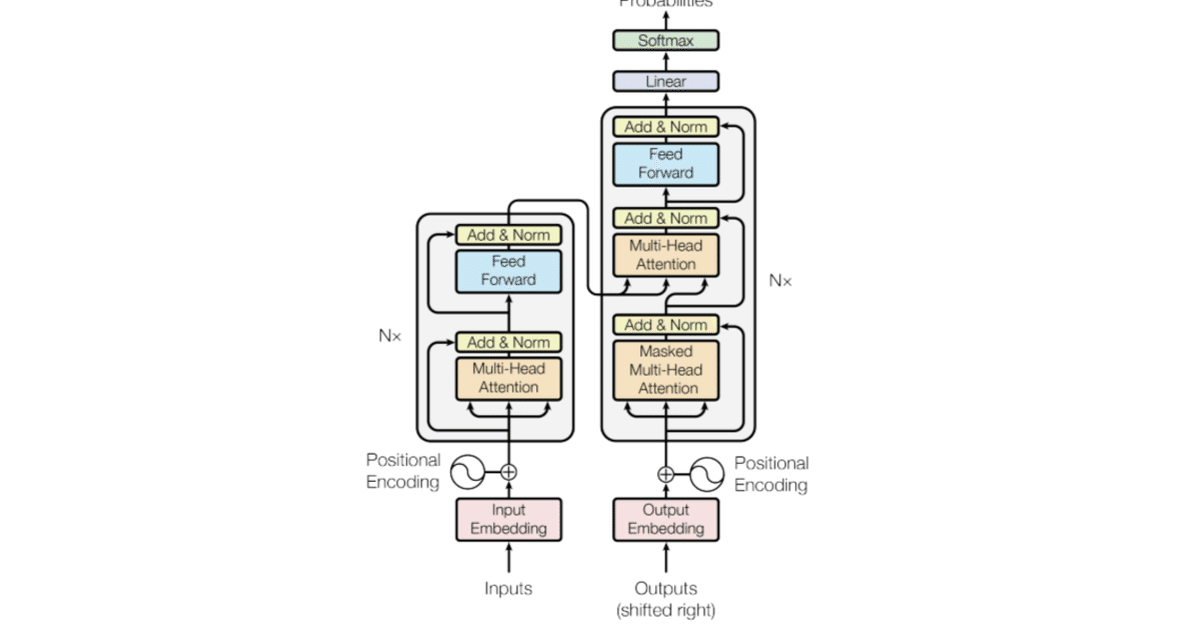
トランスフォーマーは5つの主要な部分から構成されています:
トークン化(Tokenization)
埋め込み(Embedding)
位置エンコーディング(Positional encoding)
トランスフォーマー ブロック(Transformer block()
ソフトマックス(Softmax)
4番目のもの、トランスフォーマーブロックが最も複雑です。トランスフォーマーブロックは複数連結され、それぞれに主要な2つの機能が含まれています:Attentionコンポーネントとフィードフォワードのコンポーネントです。

トークン化(Tokenization)
トークン化は最も基本的なステップです。変換するための参照元は、すべての単語、句読点、などを含む大規模なトークンデータセットで構成されています。トークン化のステップでは、各単語、接頭辞、接尾辞、句読点を取り、トークンデータセットを参照してトークンに変換します。

トークン化:単語をトークンに変換する 例えば、文が「Write a story」である場合、対応する4つのトークンは<Write>、<a>、<story>、および<.>になります。
埋め込み(Embedding)
入力がトークン化されたら、単語を数値に変換します。これには、埋め込みによって行います。埋め込みは、あらゆる大規模言語モデルの最も重要な部分の一つです。これは、テキストを数値に変換する橋渡しの役割を果たします。人間はテキストを、コンピュータは数値を扱うのが得意なので、この変換がうまくいけばいくほど、強力な言語モデルになります。
簡単に言うと、テキスト埋め込みは、すべてのテキストを数値のベクトル(リスト)に変換します。2つのテキストが似ている場合、それぞれのベクトルの数値は互いに似ています(成分ごとに、つまり同じ位置にある数値のペアが似ている)。それ以外の場合、2つのテキストが異なる場合、それぞれのベクトルの数値は異なります。
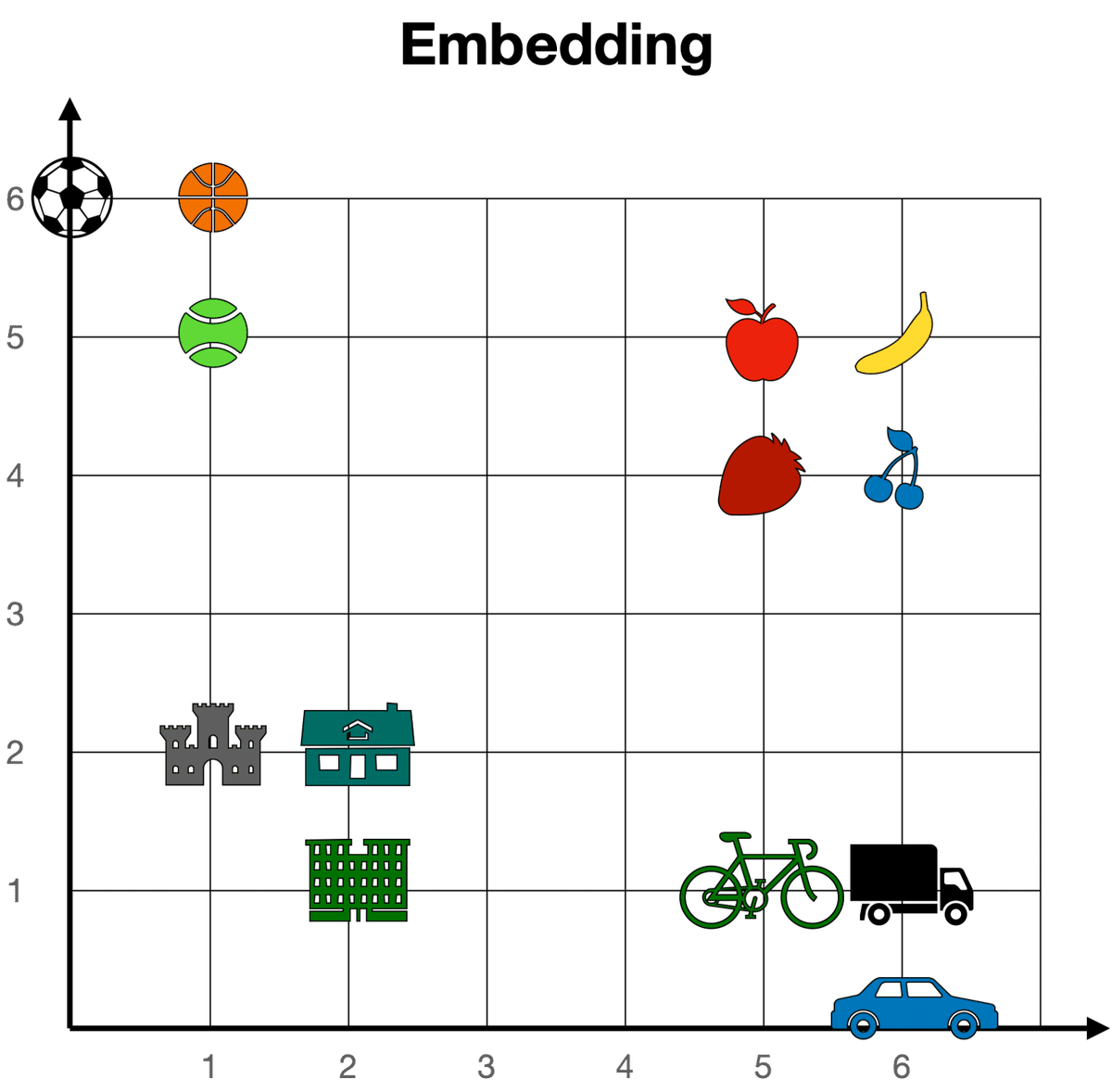
埋め込みにより数値化できるで、2次元でイメージするとよりわかりやすいです。すべての単語を長さ2のベクトル(つまり、2つの数値のリスト)に送る非常に単純な埋め込みがあると想像してみてください。2つの数値によって与えられた座標で各単語を配置すると、すべての単語が大きな平面上で表現できます。この平面では、似ている単語は互いに近くに現れ、異なる単語は互いに遠くに現れます。例えば、下の埋め込みでは、チェリーの座標は[6,4]で、ストロベリーの[5,4]に近いですが、城の[1,2]からは遠いです。
もっと大きな埋め込みの場合、各単語がより長いベクトル(例えば、長さ4096)に送られる場合、単語はもはや2次元平面では表現できず、大きな4096次元空間に存在します。しかし、その大きな空間でさえ、単語が互いに近くや遠くにあると考えることができるので、埋め込みの概念は依然として意味を持ちます。
単語の埋め込みは、テキストの埋め込みに一般化され、文全体、段落、さらにはより長いテキストがベクトルに変換します。ただし、トランスフォーマーの場合、単語の埋め込みを使用します。つまり、文章の各単語が対応するベクトルに変換します。具体的には、入力テキストのすべてのトークンが埋め込み内の対応するベクトルに変換します。
例えば、「Write a story.」という文を考え、トークンが<Write>、<a>、<story>、および<.>の場合、それぞれが長いベクトルに変換し、4つのベクトルが得られます。

位置エンコーディング(Positional encoding)
文章の各トークンに対応するベクトルが得られたら、次のステップは、これらすべてを1つのベクトルに変換して処理することです。いくつかのベクトルを1つのベクトルに変換する最も一般的な方法は、それらを成分ごとに加算することです。つまり、各座標を別々に加算します。例えば、長さ2のベクトルが[1,2]と[3,4]の場合、対応する和は[1+3, 2+4]で、[4, 6]となります。これには注意点があり、同じ数値を異なる順序で加算しても同じ結果が得られます。その場合、「I'm not sad, I'm happy」という文と、「I'm not happy, I'm sad」という文は、単語が同じで順序が異なるだけであるため、同じベクトルになります。したがって、2つの文に異なるベクトルを与える方法を考える必要があります。その場合、位置エンコーディングを採用します。位置エンコーディングは、事前に定義されたベクトルのシーケンスを単語の埋め込みベクトルに加算することで構成されます。これにより、すべての文に対して一意のベクトルが得られ、異なる順序で同じ単語が並ぶ文には異なるベクトルが割り当てられます。下の例では、「Write」、「a」、「story」、および「.」に対応するベクトルは、位置情報を持つ修正されたベクトル、「Write (1)」、「a (2)」、「story (3)」、および「. (4)」になります。

これで、文に対応する一意のベクトルができ、ベクトルが文中のすべての単語と順序の情報を持っていることがわかりました。
トランスフォーマー ブロック(Transformer block)
これまでの内容をおさらいしましょう。単語が入力され、トークンに変換される(トークン化)、次に順序が考慮される(位置エンコーディング)。これにより、モデルに入力される各トークンに対応するベクトルが得られます。次のステップは、この文章の次の単語を予測することです。これは、非常に非常に大きなニューラルネットワークを使って行われ、文章の次の単語を予測するという目的で訓練されています。
Attentionコンポーネントを追加することで大幅に改善することができます。「Attention is All you Need」という画期的な論文で紹介されたAttentionは、トランスフォーマーモデルの主要な要素の1つであり、意味が通る文章を生成できる理由の1つです。Attentionは次のセクションで説明しますが、今のところ、テキスト内の各単語に文脈を追加する方法と考えてください。
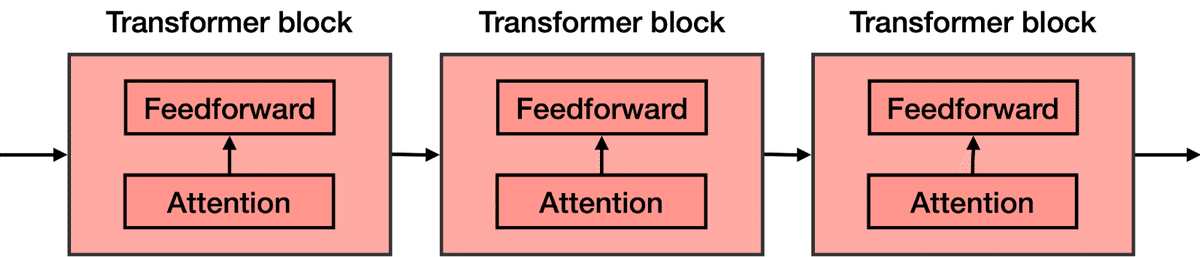
Attentionコンポーネントは、フィードフォワードネットワークの各ブロックに追加されます。したがって、次の単語を予測することを目的とした大規模なフィードフォワードニューラルネットワークを想像してください。これは、より小さなニューラルネットワークのいくつかのブロックで構成されています。これらのブロックのそれぞれにAttentionコンポーネントが追加されます。トランスフォーマーの各構成要素はトランスフォーマーブロックと呼ばれ、次の2つの主要な構成要素で構成されています。
Attentionコンポーネント
フィードフォワードコンポーネント
トランスフォーマーは、多数のトランスフォーマーブロックの連結です。
注意機構(Attention)
Attentionステップは、今回のアルゴリズムで一番重要な文脈の問題を解決します。同じ単語が異なる意味で使用されることがありますが、これは言語モデルに混乱を招くことがあります。なぜなら、埋め込みは単語をベクトルに変換するだけで、単語がどのような意味で使用しているか定義できてないからです。
Attentionは、言語モデルが文脈を理解するのに非常に役立つ技術です。Attentionがどのように機能するかを理解するために、次の2つの文章を考えてみてください。
Sentence 1: The bank of the river.
Sentence 2: Money in the bank.
ご覧のとおり、「bank」という単語がどちらにも現れますが、定義が異なります。文1では、川の脇の土地を指しており(川の土手)、文2では銀行を指しています。コンピューターはこれを理解していませんので、何らかの方法で理解させる必要があります。そこで、文中の他の単語が理解の助けになります。最初の文では、「the」と「of」は役に立ちません。しかし、「river」という単語は、川の土手について言及していることがわかります。同様に、文2では、「Money」という単語が、「bank」という単語が銀行を指しています。

端的に言えば、Attentionとは、文(またはテキスト)内の単語を単語の埋め込みでより近づけることです。そのようにして、「Money in the bank」という文の「bank」という単語は、「Money」という単語に近づけられます。同様に、「The bank of the river」(川の土手)という文では、「bank」という単語が「river」という単語に近づけられます。そのようにして、2つの文のそれぞれで修正された単語「bank」は、隣接する単語の情報の一部を持ち、文脈を追加します。
トランスフォーマーモデルで使用されるAttentionステップは、実際にはもっと強力で、multi-head Attentionと呼ばれています。multi-head Attentionでは、複数の異なる埋め込みが使用されてベクトルを修正し、文脈を追加します。multi-head Attentionは、言語モデルがテキストの処理と生成においてはるかに高い効果を達成しました。
ソフトマックス層(Softmax Layer)
トランスフォーマーが、Attention層とフィードフォワード層を含む多くのトランスフォーマーブロックの層で構成されていることがわかったので、文中の次の単語を予測する大規模なニューラルネットワークと考えることができます。トランスフォーマーは、すべての単語に対してスコアを出力し、最も高いスコアが文中で次に来る可能性が最も高い単語に付与されます。
トランスフォーマーの最後のステップは、softmax層で、これらのスコアを(合計で1になる)確率に変換し、最も高いスコアが最も高い確率に対応します。次に出現する単語はこの確率から生成することができます。以下の例では、トランスフォーマーは「Once」に最も高い確率0.5を与え、「Somewhere」と「There」にそれぞれ0.3と0.2の確率を与えます。「Once」という単語が選択され、トランスフォーマーの出力になります。

それでは、手順を繰り返しましょう。 今度は、「Write a story. Once」というテキストをモデルに入力します。おそらく、出力は「upon」になるでしょう。 この手順を何度も繰り返すことで、トランスフォーマーは「Once upon a time, there was a ...」のようなストーリーを書くことになります。
まとめ
以上、トランスフォーマーの仕組みを学びました。トランスフォーマーは、複数のブロックから構成されており、それぞれが独自の機能を持ち、テキストを理解し、次の単語を生成するために連携して働きます。
トークナイザー:単語をトークンに変換します。
埋め込み:トークンを数値(ベクトル)に変換します。
位置エンコーディング:テキスト内の単語に順序を付与します。
トランスフォーマーブロック:次の単語を推測します。Attentionブロックとフィードフォワードブロックで構成されています。
アテンション(Attention):テキストに文脈を追加します。
フィードフォワード:トランスフォーマーニューラルネットワークのブロックで、次の単語を推測します。
ソフトマックス:スコアを確率に変換し、次の単語を生成するために使用します。
トランスフォーマーが作成する素晴らしいテキストは、これらのステップの繰り返しによって成し遂げられるのです。
ChatGPTのプロンプトをたくさん覚えるより、本質が確率だということが理解できれば自ずと有効なプロンプトを作れると思います。
初心者ならこの本が超いいです。
ブレない本質を知りたいなら。
合わせて読んでみてください!
この記事が気に入ったらサポートをしてみませんか?