
BigQueryチートシート

※2022/9/24 UPDATE
データ分析・集計でよく使うクエリを調べる時間を省くためにまとめています。
URLを階層で区切る
ページごとのPVやCTRを集計するときに、階層ごとに切り出して集計しやすくする時に使ったりします。
クエリ
WITH data AS (
SELECT
'https://www.example.com/video/detail?id=100' url
)
SELECT
url,
-- //からパラメータの間をマッチさせ/で分割
split(regexp_extract(url, '//[^/]+([^?#]+)'), '/')[SAFE_ORDINAL(2)] path1,
split(regexp_extract(url, '//[^/]+([^?#]+)'), '/')[SAFE_ORDINAL(3)] path2
FROM
data■SAFE_ORDINAL…インデックスが範囲外の場合に NULLを返す
結果

現在日付・タイムスタンプを取得する
売上のトレンドを逃さないようにリアルタイムで追うため、現在日付の条件で絞ったりするときに使ってます。
クエリ
SELECT
CURRENT_DATE date_utc,
CURRENT_DATE('Asia/Tokyo') date_jst,
DATETIME(CURRENT_TIMESTAMP) datetime_utc,
DATETIME(CURRENT_TIMESTAMP, 'Asia/Tokyo') datetime_jst,
CURRENT_TIMESTAMP timestamp結果

年月日・時分秒を分けて取り出す
例えば、給料日の25日前後で売上に傾向がみられるか月跨ぎで分析するときなどに使ったりします。
クエリ
SELECT
stamp,
EXTRACT(YEAR from stamp) year, -- 年
EXTRACT(MONTH from stamp) month, -- 月
EXTRACT(DAY from stamp) day, -- 日
EXTRACT(DAYOFWEEK from stamp) dayofweek, -- 曜日 1(日曜日) ~ 7(土曜日)
EXTRACT(HOUR from stamp) hour, -- 時
EXTRACT(MINUTE from stamp) minute, -- 分
EXTRACT(SECOND from stamp) second -- 秒
FROM
(
SELECT
CAST(
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', CURRENT_TIMESTAMP, 'Asia/Tokyo') as timestamp
) as stamp
)■EXTRACT…年月日などの特定のフィールドを取り出す
結果

unixtime(秒)をtimestampに変換
クエリ
WITH raw_data AS (
SELECT 1619531893 AS unixtime
)
SELECT
unixtime,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', TIMESTAMP_SECONDS(unixtime), 'Asia/Tokyo') AS to_datetime
FROM
raw_data結果

unixtime(ミリ秒)をtimestampに変換
クエリ
WITH raw_data AS (
SELECT 1619531893111 AS unixtime
)
SELECT
unixtime,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', TIMESTAMP_MILLIS(unixtime), 'Asia/Tokyo') AS to_datetime
FROM
raw_data結果

unixtime(マイクロ秒)をtimestampに変換
クエリ
WITH raw_data AS (
SELECT 1619531893111000 AS unixtime
)
SELECT
unixtime,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', TIMESTAMP_MICROS(unixtime), 'Asia/Tokyo') AS to_datetime
FROM
raw_data結果

経過日数を出す
会員登録、最終購入からの離脱期間や、生年月日から年齢を出すときに利用してます。
データ

クエリ
SELECT
register_stamp,
date(register_stamp, 'Asia/Tokyo') register_date,
DATE_DIFF(CURRENT_DATE('Asia/Tokyo'), date(register_stamp, 'Asia/Tokyo'), DAY) past_days_from_registered,
birth_date,
DATE_DIFF(CURRENT_DATE('Asia/Tokyo'), birth_date, YEAR) age
FROM
`bigdata.mst_users_with_dates`結果

直近N日間 / N週間 / Nヶ月 / Nクオーター / N年 を求める
前日、直近1週間、直近1ヶ月、直近1クオーター、直近1年の売上集計や分析に利用します。
クエリ
SELECT
-- 現在日付
CAST('2020-10-14' as DATE) as now,
-- 1日
DATE_SUB(CAST('2020-10-14' as DATE), INTERVAL 1 DAY) as previous_day,
-- 1週間
DATE_SUB(CAST('2020-10-14' as DATE), INTERVAL 1 WEEK) as previous_week,
-- 1ヶ月
DATE_SUB(CAST('2020-10-14' as DATE), INTERVAL 1 MONTH) as previous_month,
-- 1クオーター前(3ヶ月前に同じ)
DATE_SUB(CAST('2020-10-14' as DATE), INTERVAL 1 QUARTER) as previous_quarter,
-- 1年前
DATE_SUB(CAST('2020-10-14' as DATE), INTERVAL 1 YEAR) as previous_year結果
DATE_SUB関数を利用して、例えば2020-10-14を基準に日付を算出しています。集計クエリの条件式などに利用してください。

■DATE_SUB...DATE から指定した期間を減算する
文字列をDATE型/TIMESTAMP型に変換
広告やCMを打っていた期間に絞ってその効果をみたい時などに使っています。
クエリ
SELECT
CAST ('2020-08-03' as DATE) as _date,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', timestamp('2020-08-03 23:30:17', 'Asia/Tokyo'), 'Asia/Tokyo') as _timestamp_jst結果

年度ごとの四半期売上平均を集計する
四半期決算の売上サマリーを出したいときに利用します。
データ

クエリ
SELECT
year,
-- 年度が締まっていない年は、それまでの期の平均で集計
(COALESCE(q1, 0) + COALESCE(q2, 0) + COALESCE(q3, 0) + COALESCE(q4, 0))
/ (SIGN(COALESCE(q1, 0)) + SIGN(COALESCE(q2, 0)) + SIGN(COALESCE(q3, 0)) + SIGN(COALESCE(q4, 0))) as avg
FROM
`bigdata.quartery_sales`結果

CTR / CVR
会員登録導線、購入導線のファネル分析するときに使ったりします。
データ

クエリ
SELECT
dt,
ad_id,
100.0 * IFNULL(SAFE_DIVIDE(clicks, impressions), 0) as ctr
FROM
`bigdata.advertising_stats` ■SAFE_DIVIDE...計算できない際に NULL
結果

ランキング - スコア順にする
スコアリングした商品をおすすめ順に並び替えるときに利用してます。
データ

クエリ
SELECT
product_id,
score,
-- スコア順に一意なランキングを付与
ROW_NUMBER() OVER(ORDER BY score DESC) AS ROW,
-- 同順位を許容するランキング(1, 2, 2, 4)
RANK() OVER(ORDER BY score DESC) AS rank,
-- 同順位を許容し、同順位の次の順位を飛ばさないランキング(1, 2, 2, 3)
DENSE_RANK() OVER(ORDER BY score DESC) AS dense_rank,
-- 現在行より前の行の値を取得
LAG(product_id) OVER (ORDER BY score DESC) AS lag1,
LAG(product_id, 2) OVER (ORDER BY score DESC) AS lag2,
-- 現在行より後の行の値を取得
LEAD(product_id) OVER (ORDER BY score DESC) AS lead1,
LEAD(product_id, 2) OVER (ORDER BY score DESC) AS lead2
FROM
`bigdata.popular_products`
ORDER BY
ROW結果

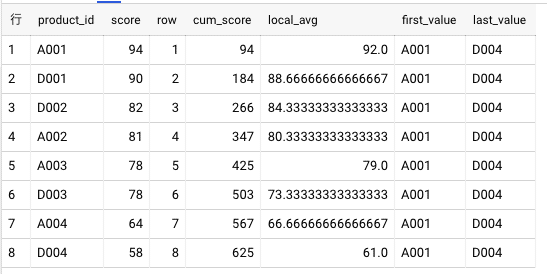
ORDER BYと集約関数と組み合わせる
ランキング最上位、最下位、TOP10の商品をピックアップするのに使ったりしてます。
クエリ
SELECT
product_id,
score,
ROW_NUMBER() OVER(ORDER BY score DESC) AS ROW,
-- ランキング上位からの累計スコア合計を計算する
SUM(score) OVER(
ORDER BY score DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_score,
-- 今の行と前後一行ずつの、合計三行の平均スコアを出す
AVG(score) OVER(
ORDER BY score DESC ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS local_avg,
-- ランキング最上位の商品IDを取得する
FIRST_VALUE(product_id) OVER(
ORDER BY score DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS first_value,
-- ランキング最下位の商品IDを取得する
LAST_VALUE(product_id) OVER(
ORDER BY score DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS last_value
FROM
`bigdata.popular_products`
ORDER BY
ROW■ウィンドウのフレーム指定
フレーム指定とは、現在のレコード位置から相対的なウィンドウを定義するための構文。
■基本形
ROWS BETWEEN [start] AND [end]
start/end
CURRENT ROW(現在行)
n PRECEDING(n行前)
n FOLLOWING(n行後)
UNBOUNDED PRECEDING(前の行全て)
UNBOUNDED FOLLOWING(後の行全て)
結果
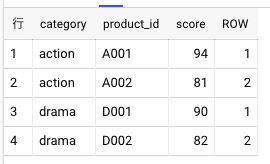
カテゴリーごとに売上ランキング TOP N 件取得
カテゴリーごとに売上ランキングTOP10を調べるときに利用してます。
クエリ
WITH ranking_by_category AS (
SELECT
category,
product_id,
score,
ROW_NUMBER() OVER(PARTITION BY category ORDER BY score DESC) AS ROW
FROM
`bigdata.popular_products`
)
SELECT
*
FROM
ranking_by_category
WHERE
-- ここの数字でTOPNのNを指定できる
ROW <= 2■WINDOW関数はWHERE句に指定できないので、サブクエリかWITH句で囲む必要がある。
結果
カテゴリーごとの最上位を取得する
カテゴリーごとに売上No.1を調べるときに利用してます。
クエリ
SELECT
distinct category,
-- 逆に最下位とる場合は、FIRST_VALUE を LAST_VALUE にする
FIRST_VALUE(product_id) OVER (partition by category order by score desc)
FROM
`bigdata.popular_products`■逆に最下位とる場合は、FIRST_VALUE を LAST_VALUE にすればよい。
結果

UU数の推移
UU数の増加傾向を時系列で可視化するときに利用します。
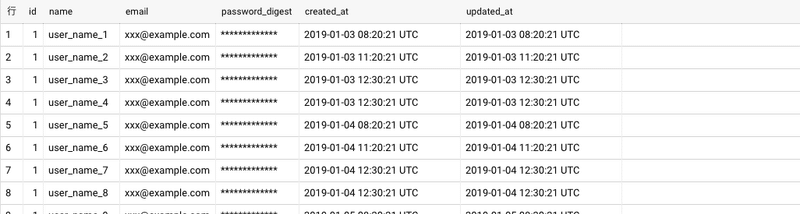
データ
一般的なユーザーテーブルにおいて、レコードの作成日を会員登録日として利用します。以下のイメージでいう「created_at」カラムを会員登録日とします。
クエリ
WITH raw_data AS
(
-- ユーザーテーブルに置き換えてください
SELECT
created_at,
EXTRACT(YEAR from created_at) year,
EXTRACT(MONTH from created_at) month,
CONCAT(
EXTRACT(YEAR from created_at),
'/',
EXTRACT(MONTH from created_at)
) as year_month
FROM
bigdata.users
),
uu_by_month AS (
-- 年月ごとのUU数を集計
SELECT
year_month,
count(*) AS register_uu
FROM
raw_data
GROUP BY
year_month
)
SELECT
year_month,
register_uu,
-- UU数を積み上げ
SUM(register_uu) OVER (ORDER BY year_month ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as uu
FROM
uu_by_month
ORDER BY
year_month■ その月から過去分までのUU数を積み上げるために、現在行から前の行全ての合計を計算する
[構文]
ROWS BETWEEN CURRENT ROW AND UNBOUNDED PRECEDING
CURRENT ROW:現在行
UNBOUNDED PRECEDING:前の行全て
結果
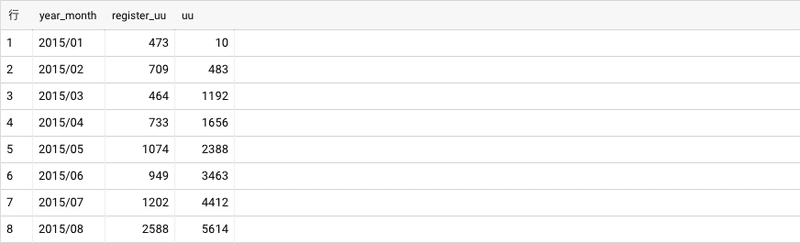
グラフにすると…

CSVデータを1行づつ展開
データレイクのrawデータを整形してデータウェアハウスに入れるときに使っています。
データ

クエリ
WITH user_favorite_fruits AS (
SELECT
'jhon' AS user_name,
'apple,banana,strawberry' AS fruits
UNION ALL
SELECT
'luck' AS user_name,
'pine' AS fruits
)
SELECT
user_name,
fruit
FROM
user_favorite_fruits,
-- SPLITした結果をUNNEST
UNNEST(SPLIT(fruits, ",")) AS fruit■SPLIT...区切り文字を引数に、STRING 型の ARRAY または BYTES 型の ARRAYを返します。
■UNNEST...UNNEST 演算子は ARRAY を受け取り、ARRAY 内の各要素を 1 行にしてテーブルを返します。
結果

JSON形式データをカラムごとに展開
データレイクのrawデータを整形してデータウェアハウスに入れるときに使っています。
データ

クエリ
WITH data AS (
SELECT
12345 AS user_id,
'purchase' AS action,
'{"item_id": 1, "item_name": "ゲームセンターCX DVD/BD", "price": 5000, "quantity": 1}' AS detail
)
SELECT
user_id,
action,
JSON_EXTRACT(detail, '$.item_id') AS item_id,
JSON_EXTRACT(detail, '$.item_name') AS item_name,
JSON_EXTRACT(detail, '$.price') AS price,
JSON_EXTRACT(detail, '$.quantity') AS quantity
FROM
data■JSON_EXTRACT...JSON値をSTRINGで返す。
結果

無からカレンダー生成
日ごとに集計すると日付が歯抜けになるケースがあるので、日付マスタ的なテーブルを生成してジョインするときに利用するとよし。
クエリ
WITH _date AS (
SELECT *
FROM
UNNEST(
GENERATE_DATE_ARRAY(
CAST('2020-07-01' as DATE),
DATE_ADD(CURRENT_DATE('Asia/Tokyo'), INTERVAL 9 DAY)
)
) AS local_date
ORDER BY 1
)
,cal AS (
SELECT
*,
EXTRACT(DAYOFWEEK FROM local_date) as day_of_week_raw
FROM
_date
)
SELECT
*,
CASE
WHEN day_of_week_raw = 1 THEN 'Sun'
WHEN day_of_week_raw = 2 THEN 'Mon'
WHEN day_of_week_raw = 3 THEN 'Tue'
WHEN day_of_week_raw = 4 THEN 'Wed'
WHEN day_of_week_raw = 5 THEN 'Thu'
WHEN day_of_week_raw = 6 THEN 'Fri'
WHEN day_of_week_raw = 7 THEN 'Sat'
END
FROM
cal結果

タイムトラベルで過去データの復元
タイムトラベルでその時点のデータを参照可能です。タイムトラベル可能期間は7日間です(記事時点)。
クエリ
SELECT
*
FROM
`dataset.table`
-- 参照したい時点の日時を指定する
FOR SYSTEM_TIME AS OF TIMESTAMP('2022-09-23 14:00:00', 'Asia/Tokyo');ただし、削除されたテーブルはbqコマンドでテーブルを復元する利用する必要があります。クエリの実行はできないようです(記事時点)。
$ bq cp ${dataset}.${table}@${UNIXタイム(ミリ秒)} ${dataset}.${restored_table}
# 例:bq cp mydataset.table1@1624046611000 mydataset.table1_restoredUNIXタイムスタンプ(ミリ秒)は以下で取得できます。
SELECT
UNIX_MILLIS(TIMESTAMP('2022-09-24 14:00:00', 'Asia/Tokyo'))公式Doc: タイムトラベルを使用した履歴データへのアクセス
--- ✐ --- ✐ --- ✐ ---
参考資料
■ BigQuery ドキュメント
基本的にはBigQueryのドキュメントをみてます。
■ ビッグデータ分析・活用のためのSQLレシピ
黒魔術として名高い「ビッグデータ分析・活用のためのSQLレシピ」。行動ログ分析、集計などで参考にさせていただいてます。これ以上おすすめする本はないと言えるくらい有用な本でした。
■ Qiita
無からカレンダー生成はQiitaの @shiozaki さんの記事を参考にさせていただきました。
よろしければサポートお願いします!クリエイター費として利用させていただきます!