
【TreasureData】GISデータ解析~人口ヒートマップ検索を作ろう!~(2/5)

こんにちは!noteをお読みいただきありがとうございます。
smkt事業部note運用チームです。
本稿はTreasureDataを使ったGISデータ解析の第2回目となります。
(第1回のデータ準備編をお読みでない方は、是非そちらからお読みください!)
全5回を予定しており、第2回はメッシュデータ編となります。
Pythonでの緯度経度計算のやり方、多次元モデル形式データの縦形式データへの変換方法 を解説していきます。
手順が分かりやすいよう、ハンズオン形式で解説していくので、
TreasureData初心者の方も是非チャレンジしてみてください。
データの準備
● 国勢調査データのダウンロード
500mメッシュ別将来推計人口(H30国政局推計)
ページ下部の「東京」からダウンロード
データの項目は下記のPDFで確認できますhttps://nlftp.mlit.go.jp/ksj/gml/datalist/mesh500_1000_h30_datalist.pdf

データ加工
● メッシュデータ → 緯度経度計算
メッシュデータとは、地球上を格子で分割して、何枚目のエリアかを管理したコード体系のことです
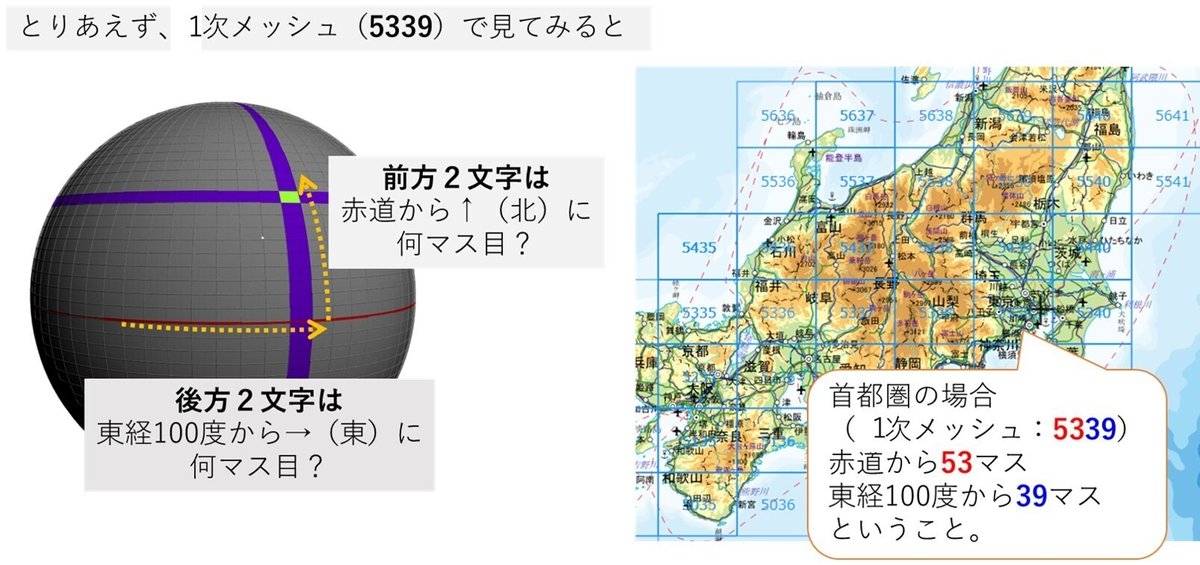
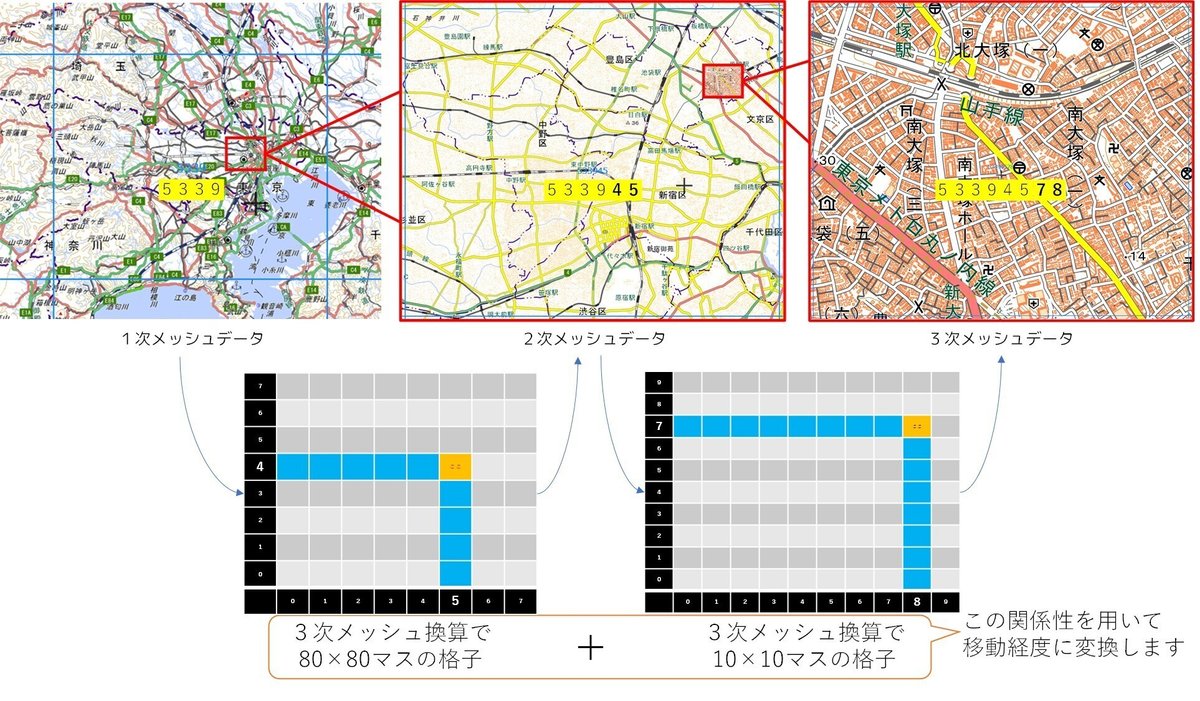
次に、1~3次メッシュの関係性を見てみましょう
実際に、「53394578」の緯度経度を計算しましょう
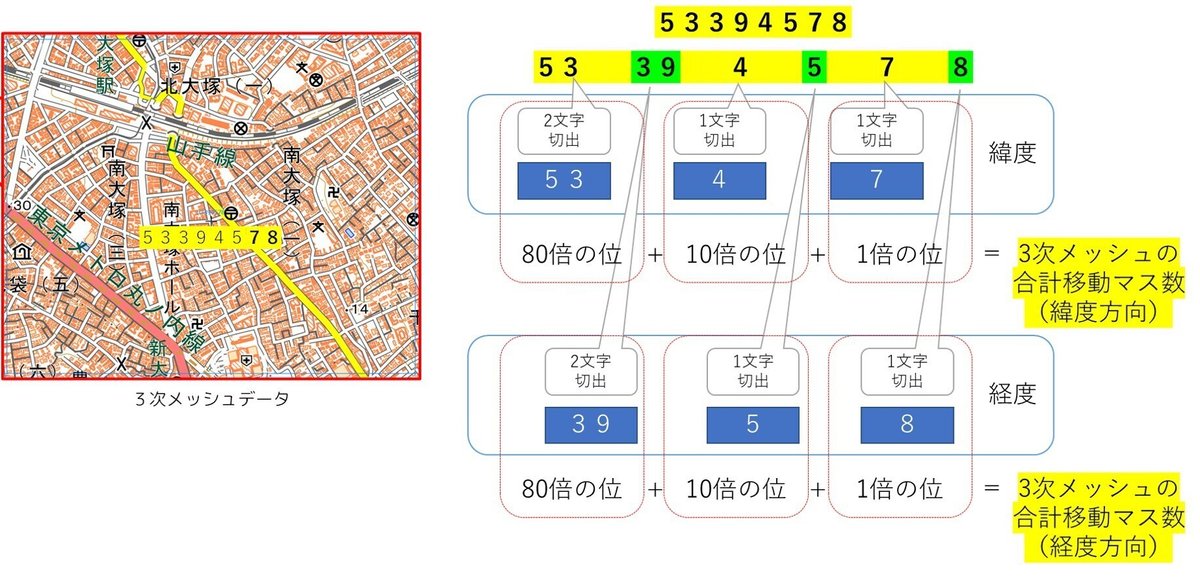
北に53×80+4×10+7 (マス分の3次メッシュ)
東に39×80+5×10+8 (マス分の3次メッシュ)
ここで、3次メッシュの単位について思い出しましょう
上記によれば、1個の3次メッシュの幅は
「緯度:30秒」「経度:45秒」ですね
30秒 → 30/3600度、45秒 → 45/3600度を上記のマス数に掛け算します
・緯度 =(53×80+4×10+7) ×30/3600
・経度 =(39×80+5×10+8) ×45/3600 +100
※+100は東経100が基準のため
北緯:35.725 度
東経:139.725 度
と、なりました
● 以下、Pythonでの実装例です
def mesh2lonlat(mesh_id):
"""
メッシュIDから緯度、経度を計算する
Parameters
----------
mesh_id : any
任意のメッシュID
Returns
-------
min_latitude
対象エリアの最小緯度(北緯換算 度)=左下の緯度
min_longitude
対象エリアの最小経度(東経換算 度)=右上の経度
max_latitude
対象エリアの最大緯度(北緯換算 度)=左下の緯度
max_longitude
対象エリアの最大経度(東経換算 度)=右上の経度
"""
if type(mesh_id) == int:
mesh_id = str(mesh_id)
lat_spt1 = int(mesh_id[0:2])
lon_spt1 = int(mesh_id[2:4])
lat_spt2 = int(mesh_id[4:5])
lon_spt2 = int(mesh_id[5:6])
lat_spt3 = int(mesh_id[6:7])
lon_spt3 = int(mesh_id[7:8])
if len(mesh_id) == 8:
# 8桁ならば、3次メッシュということで、アルゴリズムの通りに実装
min_lat = ((lat_spt1 * 80) + (lat_spt2 * 10) + lat_spt3) * (30 /3600)
min_lon = ((lon_spt1 * 80) + (lon_spt2 * 10) + lon_spt3) * (45 /3600) + 100
max_lat = ((lat_spt1 * 80) + (lat_spt2 * 10) + lat_spt3 + 1) * (30 /3600)
max_lon = ((lon_spt1 * 80) + (lon_spt2 * 10) + lon_spt3 + 1) * (45 /3600) + 100
elif len(mesh_id) == 9:
# こちらは、第9桁目が入力された場合です
# 9桁目の数字を変数に格納
mesh_mod = int(mesh_id[8:9])
# 9桁目が1~4のいずれかで判定して、北緯方向・東経方向に0.5プラスします
if mesh_mod == 1 :
difx = 0
dify = 0
elif mesh_mod == 2 :
difx = 0.5
dify = 0
elif mesh_mod == 3 :
difx = 0
dify = 0.5
elif mesh_mod == 4 :
difx = 0.5
dify = 0.5
min_lat = ((lat_spt1 * 80) + (lat_spt2 * 10) + lat_spt3 + dify) * (30 /3600)
min_lon = ((lon_spt1 * 80) + (lon_spt2 * 10) + lon_spt3 + difx) * (45 /3600) + 100
max_lat = ((lat_spt1 * 80) + (lat_spt2 * 10) + lat_spt3 + dify + 0.5) * (30 /3600)
max_lon = ((lon_spt1 * 80) + (lon_spt2 * 10) + lon_spt3 + difx + 0.5) * (45 /3600) + 100
return [min_lat,min_lon,max_lat,max_lon]地図画像出典:「地理院地図 / GSI Maps|国土地理院」
参考にさせていただいたサイト様:「地図のページ」
● 元データ(500mメッシュ別将来推計人口)データの変換
元の多次元モデル形式のままでは扱いにくいので、縦形式のデータに変換したいと思います
まずは、必要なデータの設計です
元データだと、列方向に「属性情報」が分かれてしまっておりそのままでは扱いずらいので、「性別」「年齢」カラムを新設して「属性情報」を縦に管理します
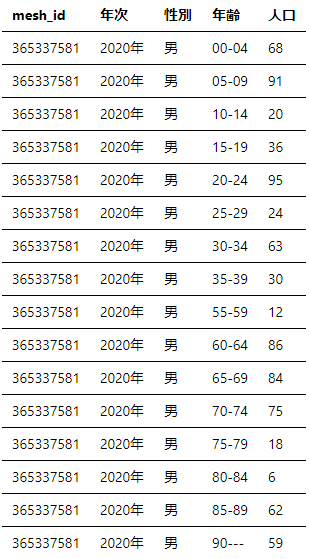
● 以下、Pythonでの実装例です
def cross2liner(inf,out):
# 年次のラベルを配列に格納します
# メッシュ別将来推計人口(H30年版)には2020~2050年の予測値までが掲載されてます
nenjiLbl = ['2020', '2025', '2030', '2035', '2040', '2045', '2050']
# 性別のラベル配列です
# こちらは、2次元配列にしてデータ内部の識別子(M,F)と表示用のラベルをペアにしてます
gendrLbl = [
['M','男'],
['F','女']
]
# 最後に、年齢のラベル配列です
# データ内部の識別子1~19に対応して、5歳単位でデータ収録されているので、その形式で2次元配列を用意
ageLbl = [
['1','00-04'],
['2','05-09'],
['3','10-14'],
['4','15-19'],
['5','20-24'],
['6','25-29'],
['7','30-34'],
['8','35-39'],
['9','40-44'],
['10','45-49'],
['11','50-54'],
['12','55-59'],
['13','60-64'],
['14','65-69'],
['15','70-74'],
['16','75-79'],
['17','80-84'],
['18','85-89'],
['19','90---']
]
# 出力用のから配列です
output = []
# open関数で対象のファイルをcsvfに構造体を格納
csvf = open(inf, "r", encoding="ms932", errors="", newline="" )
# 辞書型でデータを読取ります
df = csv.DictReader(csvf, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
# CSVを読み込んだ辞書型配列に対して逐次的にloopを回します
# for ~ in メソッドで各配列の要素を「row」に書き込みます
for row in df:
# メッシュIDの取得:'MESH_ID'で引き出す
meshid = row['MESH_ID']
# 緯度経度配列を取得したメッシュIDから生成します
lonlat = mesh2lonlat(meshid)
min_lon = lonlat[0]
min_lat = lonlat[1]
max_lon = lonlat[2]
max_lat = lonlat[3]
for nenji in nenjiLbl:
for gn in gendrLbl:
for ag in ageLbl:
keystr = 'P' + gn[0] + ag[0] + '_' + nenji
if keystr in row:
output.append([meshid,nenji,gn[1],ag[1],row[keystr],min_lon,min_lat,max_lon,max_lat])
else:
output.append([meshid,nenji,gn[1],ag[1],0.0,min_lon,min_lat,max_lon,max_lat])
headerlist = [
"mesh_id",
"year",
"gender",
"age_range",
"population",
"min_longitude",
"min_latitude",
"max_longitude",
"max_latitude"
]
with open(out, 'w',newline='') as f:
writer = csv.writer(f)
# ヘッダー情報の書き出し
writer.writerow(headerlist)
# データ入れるの逐次書き出し
for rw in output:
writer.writerow(rw)と、長くなってしまったので、TreasureData上でのcustomscriptでの実装は次回にします
今回は、ローカル上のCSVファイルを対象に書き換えを実施しましたが、TreasureData上ではテーブルを対象にデータ変換を実装してみます
次回
● TreasureData上で実際に、今回のプログラムを実行していきます
1.テーブル作成とデータ投入
2.投入したデータセットに対して、customscriptからデータ加工を行い、加工後データセットを作成します
● それ以降、3次元データを用いた疑似人口密度換算を実装します
日本全国の3D都市モデルの整備・オープンデータ化プロジェクト PLATEAU [プラトー]
ファイルダウンロード(obj形式)
ページ中央付近の「OBJ」の「詳細」からダウンロードを選択
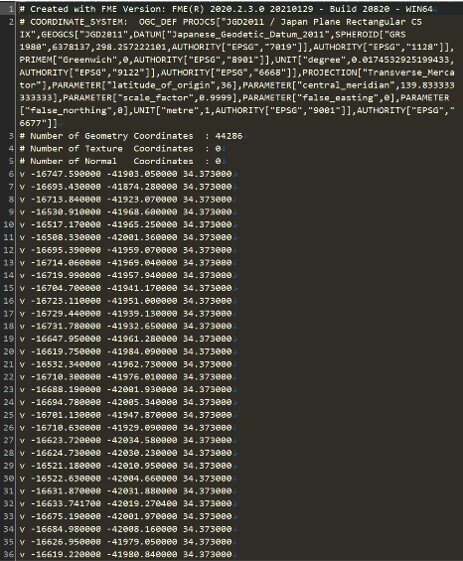
● 平面直角座標系(第9系) ⇔ 緯度経度変換
OBJデータの座標系が平面直角座標系(第9系)に準拠してるので
データセットの完成系イメージに合わせて変換が必要になります
● OBJ形式の3次元データの解析
ノンバイナリーでシンプルな3次元データを触ってみます
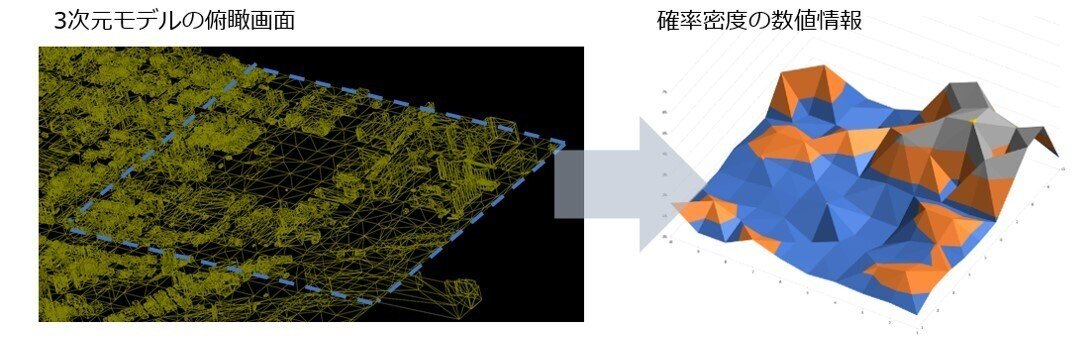
XYZ座標の扱ってみましょう
● 半径を指定した回転楕円体上の2点間の距離計算
ヒュベニの近似公式を用いてターゲットとの距離を計算します
最後までお読みいただきありがとうございました!
●●●
パーソルP&Tでは、CDP導入・活用支援サービスに注力しています。
✉ サービスに関するお問い合わせ ✉
パーソルプロセス&テクノロジー SMKT事業部
smkt_markegr_note@persol-pt.co.jp
●●●
またSMKT事業部では データエンジニアを募集しています。
ご興味をお持ちの方はこちらからご応募ください!
▽その他募集職種こちらから▽
●●●
マガジン「Treasure Data Tips集」では、現場で役立つTipsをまとめています。是非こちらもご覧ください。