
【NLP】自然言語処理の基礎知識

こんにちは!noteをお読みいただきありがとうございます。
今回の記事は、note運用チームの萩谷が担当しております。
これからも、皆様のお役に立てるような情報を発信していけたらと思いますので、どうぞよろしくお願いいたします!
さて皆様、「自然言語処理」という言葉はご存じでしょうか⁇
最近、AI技術の発展に伴い様々な場面で耳にすることがありそうですが、その内容についてはあまり詳しく知らない方も多いのではないかと思います。
本記事では、「自然言語処理」の基礎について詳しく書きましたのでぜひ一読いただければ嬉しいです。
1.自然言語処理とは
日本語や英語など、普段私たちが使っている言葉を自然言語と言います。自然言語処理とは「自然言語を処理すること」、つまり「私たちの言葉をコンピューターに理解させる」技術のことです。
私たちの身近なところでは、検索エンジンや機械翻訳、チャットボットなどの質疑応答システムに自然言語処理の技術が応用されています。
2.言葉をコンピューターに理解させる
では、言葉をコンピューターに理解させるにはどうしたらよいでしょうか。
私たちの言葉の意味は「単語」によって構成されます。単語は、言い換えれば、意味の最小単位のことです。そのため、自然言語をコンピューターに理解させるためには、「単語の意味」を理解させることが重要となります。
3.「単語の意味」を理解させる手法
以上をまとめると、自然言語処理とは、「私たちの言葉=単語の意味をコンピューターに理解させる」技術です。本記事では、単語の意味を理解させるための手法として次の3つを解説します。
① シソーラスによる手法
② カウントベースの手法
③ 推論ベースの手法
3-1.シソーラスによる手法
1つ目は、人の手によって作られた辞書(シソーラス)を利用する手法です。
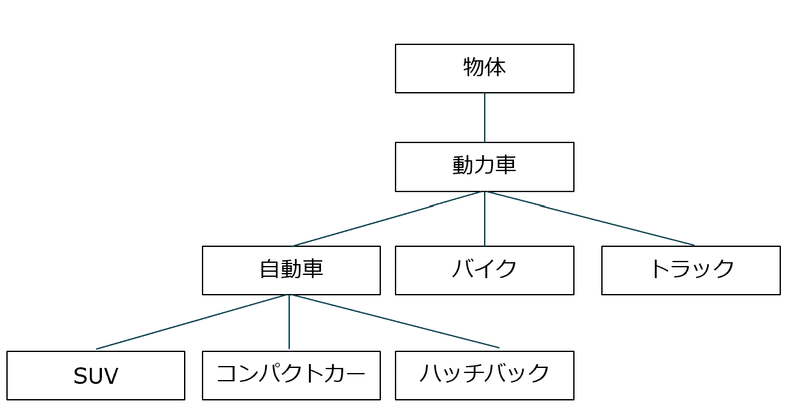
シソーラスとは、同じ意味や似た意味の単語をグループ化した類語辞書で、単語間での「上位と下位」、「全体と部分」などの、関連性も定義されています。図の例では、「自動車」の類義語に「バイク」、「トラック」、上位概念として「動力車」、下位概念として「SUV」、「コンパクトカー」などの具体的な車種があります。
このように、すべての単語に対して作成した辞書を利用することで、コンピューターに単語の意味を授けることができます。
3-2.カウントベースの手法
2つ目は、周辺の単語を数えることで、単語をベクトル表現する手法です。
カウントベースの手法は、「単語の意味は、周辺の単語によって形成される」というアイディア(分布仮説)に基づいています。つまり、単語自体には意味がなく、文脈によって意味が形成されるという考え方です。
「私は毎朝牛乳を飲む。」という文章の例でみると、分布仮説に基づき「牛乳」の周辺の単語をカウントすることで、「牛乳」をベクトル化します。これを巨大な文章の全ての単語に対して行うことで、それぞれの単語をベクトル化していきます。

3-3.推論ベースの手法
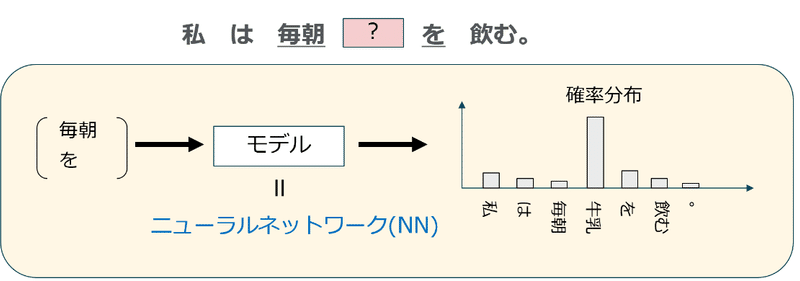
3つ目は、文脈において何の単語が出現するかを推論することで、単語のベクトル表現を得る手法です。
推論ベースの手法では、周辺の単語が与えられたときに「?」に何の単語が出現するのかをニューラルネットワークを使って推測します。ニューラルネットワークが正しい推測ができるように学習を繰り返すことで、その学習の結果として各単語のベクトル表現が得られるのです。
4.まとめ
今回は、「自然言語処理」という言葉の概念と、単語の意味をコンピューターに理解させる3つの手法について紹介しました。
シソーラス、カウントベースはディープラーニング登場以前の古典的な手法なのに対し、推論ベースは、ニューラルネットワークを使用し一般的にWord2Vecと呼ばれる手法です。より深く理解するにはニューラルネットワークの知識が必要ですが、全体を通じて概念理解の一助になれば幸いです!
5.最後に
SMKT事業部では、データアナリスト・データエンジニアを募集しています。
是非こちらもご覧ください。
▽その他募集職種こちらから▽
●●●
✉ サービスに関するお問い合わせ ✉
パーソルプロセス&テクノロジー SMKT事業部
smkt_markegr_note@persol-pt.co.jp