
需要予測の巻

こんにちは。Shuzoでございます。
今回はSIGNATEの需要予測問題に挑戦した内容を共有します。
販売実績データの読み込み
データの読み込み
最初にデータを読み込みます。
Pandasをインポートし、SIGNATEの需要予測問題から頂いた学習用データを読み込みます。
※Pandas:データ操作のためのライブラリ。データ抽出・変換・結合や、外部からの取り込み、ファイルへの書き出しなど、データ操作関連のプログラムが提供される
import pandas as pd
train=pd.read_csv('train.csv')データ精査
ファイル内容を確認するため、infoメソッドを使います。
print( train.info() )出力結果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 207 entries, 0 to 206
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 207 non-null object
1 y 207 non-null int64
2 week 207 non-null object
3 soldout 207 non-null int64
4 name 207 non-null object
5 kcal 166 non-null float64
6 remarks 21 non-null object
7 event 14 non-null object
8 payday 10 non-null float64
9 weather 207 non-null object
10 precipitation 207 non-null object
11 temperature 207 non-null float64
dtypes: float64(3), int64(2), object(7)
memory usage: 19.5+ KB
Noneデータフレームの行数、列数、各列の列名、各列のヌル値の有無、格納されるデータの型、メモリ使用量などが確認できました。
補足:各データの詳細
datetime:使用する日付(yyyy-m-d)
y:販売数(目的変数)
week:曜日(月~金)
soldout:完売フラグ(0:完売せず、1:完売)
name:メインメニュー
kcal:おかずのカロリー(kcal)
remarks:特記事項
event:13時開始お弁当持ち込み可の社内イベント
payday:給料日フラグ(1:給料日)
weather:天気
precipitation:降水量。ない場合は "--"
temperature:気温
欠損値の確認
ISNULL関数は各要素に対して判定を行い、欠損値NaNであればTrue、欠損値でなければFalseとなる。
そして、anyメソッドは行・列ごとにTrueがひとつでもあればTrueと判定する。
これらを利用し、欠損値があるか確認する
judge = train.isnull().any()
print(judge)出力結果
kcal、remarks、event、paydayに欠損値があることがわかりました。
datetime False
y False
week False
soldout False
name False
kcal True
remarks True
event True
payday True
weather False
precipitation False
temperature False
dtype: boolでは何個の欠損値があるのか確認してみましょう。
sumメソッドを使い、欠損値の合計数を出します。
print( train.isnull().sum())出力結果
kcalに41個、remarksに186個、eventに193個、paydayに197個の欠損値があることがわかりました。
datetime 0
y 0
week 0
soldout 0
name 0
kcal 41
remarks 186
event 193
payday 197
weather 0
precipitation 0
temperature 0
dtype: int64欠損値のあるカラムの値を確認します。
value_counts関数を使うことで、存在する値とその数をカウントします。
まずはkcalを見てみます。
print(train['kcal'].value_counts() )出力結果
売られた弁当ごとのカロリー数が表示されました
430.0 9
400.0 8
415.0 6
426.0 5
410.0 5
..
330.0 1
333.0 1
325.0 1
342.0 1
394.0 1
Name: kcal, Length: 77, dtype: int64次はremarksについて見てみます
print(train['remarks'].value_counts() )出力結果
6種類のメニューがあることが分かりました。
お楽しみメニュー 12
料理長のこだわりメニュー 5
鶏のレモンペッパー焼(50食)、カレー(42食) 1
酢豚(28食)、カレー(85食) 1
手作りの味 1
スペシャルメニュー(800円) 1
Name: remarks, dtype: int64次はeventについて見てみます
print(train['event'].value_counts() )出力結果
2種類のイベントがあることが分かりました。
ママの会 9
キャリアアップ支援セミナー 5
Name: event, dtype: int64次はpaydayについて見てみます
print(train['payday'].value_counts() )出力結果
1と値のみがあることが分かりました。
給与日かどうかを1という数字で分けていたといるようです。
1.0 10
Name: payday, dtype: int64欠損値の穴埋め
fillnaメソッドを使うことで欠損値を特定の値で置き換えることや列ごとに代表値で置き換えることができるため、欠損値の穴埋めには便利である。
まず、remarksは特記事項を表示する項目のため、欠損値には「特記なし」で埋めることにします。
train["remarks"].fillna("特記なし", inplace=True)eventはイベント名を表示する項目のため、欠損値を「イベントなし」で埋めることにします。
train["event"].fillna("イベントなし", inplace=True)paydayは給料日かどうかを表示する項目のため、欠損値をは給料日ではないと判断し「0」で埋めることにします。
train["payday"].fillna(0, inplace=True)kcalは弁当のカロリーを表示する項目のため、name項目のメインメニュー名と同じものを同等のカロリーと判断し、欠損値を埋めることにします。
groupbyメソッドを指定することで、列名でデータをグループ化した結果を返します。
transformメソッドは()で指定した関数を各グループに適用し、元のデータフレームのサイズとインデックスを保持するものです。
fillna関数は欠損値を穴埋めするものです。 method='ffill'は直前の値を利用して穴埋めの値に使われます。逆にmethod='bfill'は後方方向に向けて穴埋めするということになります。このように2回 もfillna関数を使用するため、transform() メソッドを使用します。
train['kcal'] = train.groupby('name')['kcal'].transform(lambda x: x.fillna(method='ffill').fillna(method='bfill'))※上記の方法では一部、同一の弁当がない場合があり、完全に欠損値を穴埋めできませんでした。
弁当の販売数に影響を与えている要素を探し出す
数的データの基本統計量の確認
describeメソッドで各数的データの基本統計量を見ることができます。
print( train.describe() )出力結果
今回の数的データはyの弁当の販売数、soldoutの完売フラグ(0:完売せず、1:完売) kcalの弁当カロリー数 、paydayの給料日フラグ、temperatureの気温であり、この5つそれぞれの基本統計量が表示されました。
count : データの個数
mean : 平均値
std : 標準偏差
min : 最小値
25% : 第一四分位数
50% : 第二四分位数(中央値)
75% : 第三四分位数
max : 最大値
弁当の販売数、最小値が29で、最大値は171と、差があります。
カロリーは最小値が315で、最大値は462であり、カロリー的にはそんなに差がないと見えます。
気温は最小値が1.2で、最大値は34.6であり、真冬から真夏まで、年間通したデータがあると見えます。
y soldout kcal payday temperature
count 207.000000 207.000000 177.000000 207.000000 207.000000
mean 86.623188 0.449275 405.124294 0.048309 19.252174
std 32.882448 0.498626 29.547464 0.214939 8.611365
min 29.000000 0.000000 315.000000 0.000000 1.200000
25% 57.000000 0.000000 388.000000 0.000000 11.550000
50% 78.000000 0.000000 408.000000 0.000000 19.800000
75% 113.000000 1.000000 427.000000 0.000000 26.100000
max 171.000000 1.000000 462.000000 1.000000 34.600000質的データの基本統計量の確認
describeメソッドに引数 include=["O"]を入れることで質的データの基本統計量を表示できます。
※[]内はゼロではなく、大文字のオーです
print( train.describe(include=["O"]) )出力結果
今回の質的データはdatetimeの日付、weekの曜日(月~金)、nameのメインメニュー、remarksの特記事項、eventのイベント名、weatherの天気、 precipitationの降水量であり、この7つそれぞれの基本統計量が表示されました。
count : データの個数
unique : ユニークな値の個数
top : 最も多く出現した要素の値(最頻値)
freq : 最も多く出現した要素の出現回数
日付はcountとuniqueが一致しているので、重複はないことが分かります。
それ以外の項目は一致ないので重複があると分かります。
メインメニューはuniqueが156もあるので、ほとんど毎日異なるメニューであることがわかります。ここまで多くなると、予測のための説明変数に利用することは難しいかもしれません。
ここまでバリエーションが多くなると、予測のための説明変数に利用することは難しいかもしれません。
datetime week name remarks event weather precipitation
count 207 207 207 207 207 207 207
unique 207 5 156 7 3 7 8
top 2013-11-18 水 メンチカツ 特記なし イベントなし 快晴 --
freq 1 43 6 186 193 53 169グラフを使い各要素を探索
グラフ作成のため、matplotlibとseabornのインポートを行う。
matplotlib:データを可視化するためのライブラリ。データをグラフ化する豊富なプログラムを活用できる。
japanize_matplotlib:matplotlib内で日本語を使えるようにするモジュール。
seaborn:matplotlibより手軽にグラフ作成可能なライブラリ。
from matplotlib import pyplot as plt
!pip install japanize-matplotlib
import japanize_matplotlib
import seaborn as snsまずが弁当の販売推移を見てみます。
plotメソッドで折れ線グラフを作れます。
弁当の販売数は右肩下がりに減少しているように見えます。
train['y'].plot( title="お弁当販売数" )
plt.xlabel("販売日数")
plt.ylabel("販売数")
plt.show()
plotメソッドにhistメソッドを追加することでヒストグラフで、弁当の販売数を可視化することができます。
axvlineメソッドで垂直線の追加をします。引数でmean関数を記載することで弁当販売数の平均値で表示できます。
ピークは50個くらいで平均よりも小さく、分布は右裾広がりになっています。異常値はなさそうです。
train['y'].plot.hist( title="お弁当販売数" )
plt.xlabel("販売数")
plt.ylabel("販売頻度")
plt.axvline(x=train["y"].mean(), color="red")
plt.show()
続きまして、気温と販売数の関係を散布図で見てみます。
scatterメソッドを使うことで散布図で表示できます。
気温が高くなるほど販売数が減っていく傾向が見て取れます。相関関係がありそうに見える。
train.plot.scatter( x="temperature", y='y', c="blue", title="販売数と気温の散布図" )
plt.xlabel("気温")
plt.ylabel("販売数")
plt.show()
続きまして、カロリーと販売数の関係を散布図で見てみます。
カロリーが高くなるほど販売数が上がるように見えなくもないですが、はっきりと相関関係があるが分からない。
train.plot.scatter( x='kcal', y='y', c="blue", title="販売数とカロリーの散布図" )
plt.xlabel("カロリー")
plt.ylabel("販売数")
plt.show()
販売数・気温・カロリーの各変数間の相関係数を表示させ、相関関係を確認します。
corrメソッドを使い、相関係数を算出する
print( train[["y","temperature","kcal"]].corr() )出力内容
販売数と気温については負の相関係数0.66(-0.66)くらいで、そこそこの相関があります。気温が高いほど、弁当の販売数を下げる関係があると考えられます。
販売数とカロリーの方は正の相関係数0.18とあまり相関がない分かりました。
y temperature kcal
y 1.000000 -0.655332 0.188411
temperature -0.655332 1.000000 -0.069324
kcal 0.188411 -0.069324 1.000000続きまして、曜日と販売数の関係を箱ひげ図を用いて見てみます。
boxplotメソッドで箱ひげ図で表示できます。
sns.boxplot( x="week", y="y", data=train, order=["月","火","水","木","金"] )
plt.title("曜日ごとの販売数")
plt.ylabel("販売数")
plt.show()出力結果
特定の曜日が特に販売数が多い・少ないと言えるほどの差はなさそうです。
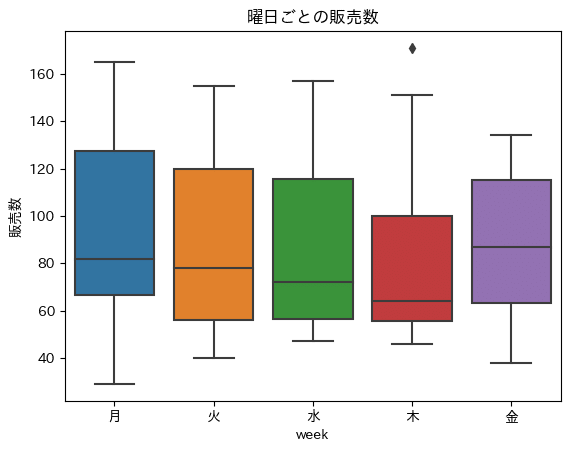
折れ線グラフで曜日と販売数の関係を見てみます。
figure関数を使用してグラフの大きさを変えて見やすくする。
lineplotメソッドで折れ線グラフを作ります。※seabornの場合
plt.figure(figsize=(10,6))
sns.lineplot( x=train.index, y="y", hue="week", data=train )
plt.title("お弁当販売数")
plt.xlabel("販売日数")
plt.ylabel("販売数")
plt.show()出力結果
期間後半から金曜日が時々きわだって販売数が多いことがわかります。
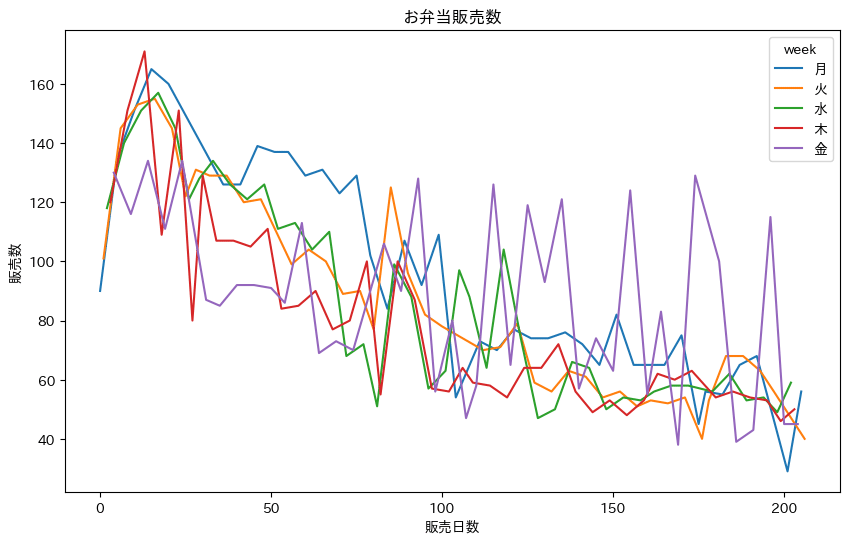
続きまして、特記事項と販売数の関係を箱ひげ図を用いて見てみます。
boxplotメソッドで箱ひげ図で表示できます。
sns.boxplot(x="y", y="remarks", data=train)
plt.title("特記事項ごとの販売数")
plt.xlabel("販売数")
plt.show()出力結果
特記なし以外では、お楽しみメニューの時に販売数が多いことがわかります。
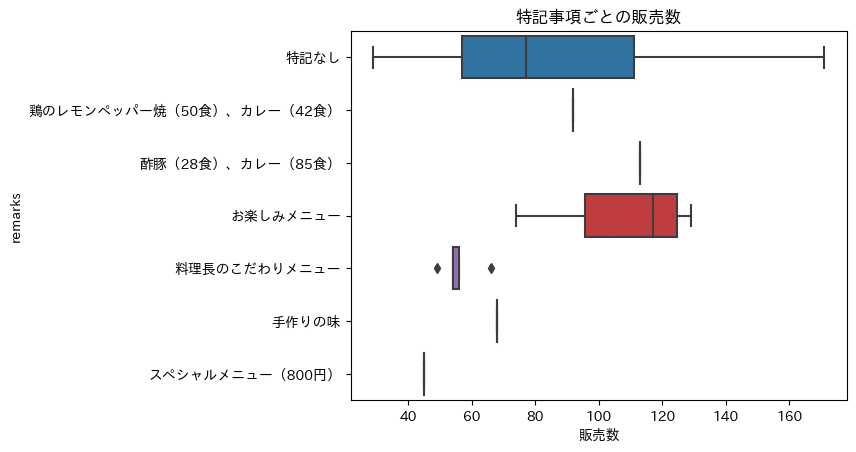
続きまして、イベントと販売数の関係を箱ひげ図を用いて見てみます。
boxplotメソッドで箱ひげ図で表示できます。
sns.boxplot(x="y", y="event", data=train)
plt.title("イベントごとの販売数")
plt.xlabel("販売数")
plt.show()出力結果
最大値には大きな差があるが、全体的には大きな差はないように見える。
続きまして、給料日と販売数の関係を箱ひげ図を用いて見てみます。
boxplotメソッドで箱ひげ図で表示できます。
sns.boxplot(x="payday", y="y", data=train)
plt.title("給料日の有無による販売数")
plt.xlabel("給料日")
plt.ylabel("販売数")
plt.show()出力結果
給料日の方が購入されているように見えますが、それほど大きな差に見えないです。

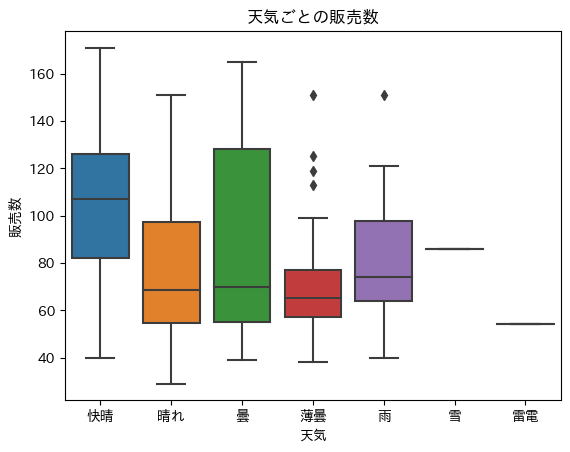
続きまして、天気と販売数の関係を箱ひげ図を用いて見てみます。
boxplotメソッドで箱ひげ図で表示できます。
表示の順番を引数orderで指定しています
sns.boxplot(x="weather", y="y", data=train, order=["快晴","晴れ","曇","薄曇","雨","雪","雷電"])
plt.title("天気ごとの販売数")
plt.xlabel("天気")
plt.ylabel("販売数")
plt.show()出力結果
快晴の日のみ全体的に他よりも高く、弁当の販売数が多いように見えます。
雪と雷電は数が極端に少ないためまとめる必要があるかと思います。
フィルタリングをして各要素を探索
お楽しみメニューの時は販売数が多いことがわかりましたが具体的にどんなメニューなのか見てみましょう。
「お楽しみメニュー」のデータだけを抽出して見て見ましょう
rows = train[ train["remarks"]=="お楽しみメニュー" ]
print( rows )出力結果
お楽しみメニューとして、カレーが人気のようです。カレーの時は毎回100食以上売れています。
お楽しみメニューがカレーの時は、販売数に影響があると考えられます。
datetime y week soldout name kcal remarks event \
83 2014-3-28 106 金 0 キーマカレー 400.0 お楽しみメニュー イベントなし
93 2014-4-11 128 金 1 チキンカレー NaN お楽しみメニュー イベントなし
103 2014-4-25 80 金 0 中華丼 NaN お楽しみメニュー イベントなし
115 2014-5-16 126 金 0 ポークカレー NaN お楽しみメニュー ママの会
125 2014-5-30 119 金 0 チキンカレー NaN お楽しみメニュー イベントなし
135 2014-6-13 121 金 0 キーマカレー 400.0 お楽しみメニュー イベントなし
145 2014-6-27 74 金 0 牛丼 NaN お楽しみメニュー イベントなし
155 2014-7-11 124 金 0 ポークカレー NaN お楽しみメニュー イベントなし
164 2014-7-25 83 金 0 ひやしたぬきうどん・炊き込みご飯 NaN お楽しみメニュー イベントなし
174 2014-8-8 129 金 0 チキンカレー NaN お楽しみメニュー イベントなし
181 2014-8-22 100 金 1 ロコモコ丼 NaN お楽しみメニュー イベントなし
196 2014-9-12 115 金 0 ポークカレー NaN お楽しみメニュー イベントなし 続きました、快晴時は販売数が多いことがわかりましたが、どうなデータになっているか抽出して見て見ましょう。
weather=train[train["weather"]=="快晴"]
print( weather )出力結果
日付を見ると冬の時期が多い。冬は快晴になりやすいため、ただ単に冬の時期に販売数が上がりやすいというものかもしれません。
なので、快晴のみで判断するべきではないと思います。
datetime y week soldout name kcal \
0 2013-11-18 90 月 0 厚切りイカフライ NaN
1 2013-11-19 101 火 1 手作りヒレカツ NaN
2 2013-11-20 118 水 0 白身魚唐揚げ野菜あん NaN
3 2013-11-21 120 木 1 若鶏ピリ辛焼 NaN
4 2013-11-22 130 金 1 ビッグメンチカツ NaN
6 2013-11-26 145 火 0 豚のスタミナ炒め NaN
9 2013-11-29 116 金 0 タルタルinソーセージカツ NaN
10 2013-12-2 151 月 1 マーボ豆腐 396.0
11 2013-12-3 153 火 1 厚揚げ豚生姜炒め NaN
13 2013-12-5 171 木 0 鶏のカッシュナッツ炒め 430.0
14 2013-12-6 134 金 0 手作りロースカツ 440.0
18 2013-12-12 109 木 0 肉じゃが 397.0
19 2013-12-13 111 金 1 タンドリーチキン 426.0
20 2013-12-16 160 月 0 カキフライタルタル NaN
25 2013-12-24 122 火 0 さっくりメンチカツ NaN
26 2013-12-25 121 水 1 手ごね風ハンバーグ NaN
28 2014-1-7 131 火 0 カレー入りソーセージカツ 404.0
31 2014-1-10 87 金 0 手作りロースカツ 440.0
34 2014-1-16 107 木 0 カレイ唐揚げ野菜あんかけ 415.0
35 2014-1-17 85 金 1 回鍋肉 430.0
37 2014-1-21 129 火 1 サバ焼味噌掛け 447.0
38 2014-1-22 126 水 1 手作りひれかつとカレー 426.0
39 2014-1-23 107 木 0 酢豚 400.0
40 2014-1-24 92 金 1 鶏のレモンペッパー焼orカレー 418.0
41 2014-1-27 126 月 1 チンジャオロース 415.0
42 2014-1-28 120 火 0 海老フライタルタル 445.0
43 2014-1-29 121 水 1 チーズ入りメンチカツ 450.0
45 2014-1-31 92 金 1 メダイ照り焼 460.0
48 2014-2-5 126 水 1 鶏のピリ辛焼き 420.0
59 2014-2-21 113 金 0 酢豚orカレー 410.0
61 2014-2-25 104 火 0 マーボ豆腐 396.0
68 2014-3-6 77 木 0 チキンクリームシチュー 409.0
69 2014-3-7 73 金 1 ボローニャ風カツ 396.0
71 2014-3-11 89 火 0 肉じゃが 397.0
72 2014-3-12 68 水 0 ビーフカレー 370.0
75 2014-3-17 129 月 0 鶏の唐揚げおろしソース 382.0
79 2014-3-24 102 月 0 マーボ豆腐 350.0
80 2014-3-25 77 火 0 手作りひれかつ 407.0
83 2014-3-28 106 金 0 キーマカレー 400.0
89 2014-4-7 107 月 0 青梗菜牛肉炒め 387.0
90 2014-4-8 96 火 1 肉団子のシチュー 353.0
93 2014-4-11 128 金 1 チキンカレー NaN
95 2014-4-15 82 火 0 ポーク生姜焼き 370.0
97 2014-4-17 57 木 0 牛丼風煮 333.0
101 2014-4-23 63 水 0 手作りひれかつ 340.0
115 2014-5-16 126 金 0 ポークカレー NaN
124 2014-5-29 64 木 1 いか天ぷら 438.0
148 2014-7-2 50 水 1 タンドリーチキン 363.0
171 2014-8-5 54 火 1 鶏肉のカレー唐揚 400.0
172 2014-8-6 58 水 1 豚キムチ炒め 410.0
179 2014-8-20 56 水 0 豚ロースのピザ風チーズ焼き 423.0
205 2014-9-29 56 月 1 豚肉と玉子の炒め 404.0
206 2014-9-30 40 火 0 鶏肉とカシューナッツ炒め 398.0 予測モデル作成前のデータ前処理
データフレームの加工
天気カテゴリーを整理として、数の少ない雪と雷電は雨にまとめてしまいます。
train["weather"] = train["weather"].apply(lambda x: "雨" if x == "雪" or x == "雷電" else x)続きまして、remarksカラムが「お楽しみメニュー」であり、かつメニュー(nameカラム)がカレーであれば1、そうでなければ0と変換します。
train["remarks"] = train.apply(lambda x: 1 if x["remarks"] == "お楽しみメニュー" and "カレー" in x["name"] else 0, axis=1)続きまして、Datetimeを分割して、年・月のカラムを作成する
split関数で”-”で文字列を分割し、0番目を年、1番目を月とする。
astype関数でデータ型を指定できる。
train["year"] = train["datetime"].apply(lambda x: x.split("-")[0] )
train["month"] = train["datetime"].apply(lambda x: x.split("-")[1] )
train["year"] = train["year"].astype(int)
train["month"] = train["month"].astype(int)続きまして、不要なカラムを削除します。
dropメソッドを使い、columnsで削除したいカラムを指定して削除する。
今回は特記事項・気温・金曜日・天気が影響を与える説明変数と仮定し、それ以外の項目を削除します。
train = train.drop(columns = ["datetime","soldout","name","kcal","event","payday","precipitation","year"])続きまして、質的データを量的データに変換すること(ダミー変数化)をして説明変数として使えることができる。
get_dummies関数を使うことでダミー変数化することが可能。
※明示的に指定する必要はありません。
data = pd.get_dummies(data)販売数予測モデルの作成
機械学習モデルの選択
今回は数値データかつ複数の説明変数で予測するため、「重回帰モデル」で予測を行います。
まず、重回帰モデルを使用する場合には、sklearn.linear_modelからLinearRegressionをインポートします。
scikit-learnでモデルを作成する際には、まずモデルを表す箱を準備し、その箱を表す変数へモデル本体を代入する必要があります。そのため、箱を表す変数modelを用意し、重回帰モデルの初期設定をします。
from sklearn.linear_model import LinearRegression
model = LinearRegression()説明変数の準備
予測モデル作成のため、使用する特記事項・気温・金曜日・天気である説明変数をリスト化し、変数に格納します。
features = ["remarks","temperature","week_金","weather_快晴","weather_晴れ","weather_曇","weather_雨"]学習データの準備
学習データ内の説明変数をtrain_X変数に格納。目的変数である販売数をtrain_y変数に格納。
train_X = train[features]
train_y = train["y"]重回帰モデルの学習を実行
インポートしたLinearRegressionを格納したmodel変数にfitメソッドを使うことで重回帰モデルの学習を実行する。
中には学習データの説明変数であるtrain_Xと目的変数であるtrain_yを記載する。
model.fit(train_X, train_y)予測を実行
モデルを使い、予測値を得る為にはpredict関数を利用します。
引数として予測したいデータの説明変数train_Xを与え計算させ、pred1という変数に格納する。
pred1 = model.predict( train_X )回帰式の算出
LinearRegressionライブラリを用いて回帰係数と切片を算出します。
# 切片
print(model.intercept_)
# 傾き
print('{}'.format(pd.Series(model.coef_,index=features)))出力結果
回帰分析から得られた回帰式は以下の通りである。
𝑦 = 61.5𝑥0 −2.7𝑥1 -11.3𝑥2 + 5.1𝑥3 + 2.2𝑥4 - 3.5𝑥5 - 8.3𝑥6 + 135.8
138.49200127518006
remarks 61.460555
temperature -2.696443
week_金 -11.329282
weather_快晴 5.124849
weather_晴れ 2.217179
weather_曇 -3.500275
weather_雨 -8.273975
dtype: float64回帰式の精度を確認
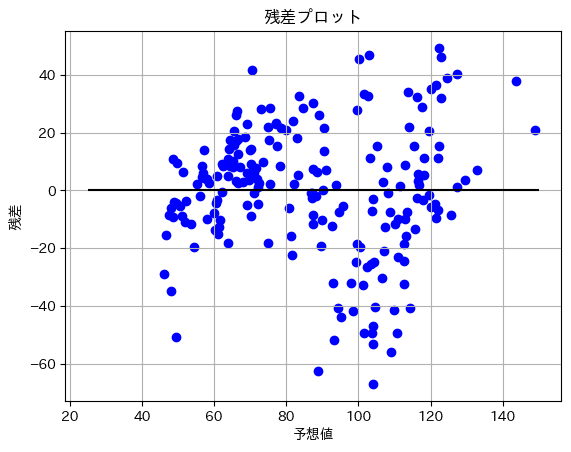
残差プロットを使い、残差のばらつきを見ます。
散布図でx軸を予測値、y軸を予測値と学習データの販売数から引いた数を残差として算出し、表しました。
残差がy軸「0」の付近で均一に分散していることが望ましい
plt.scatter(pred1, pred1-train_y, color='blue')
plt.hlines(y=0,xmin=25,xmax=150,colors='black')
plt.title('残差プロット')
plt.xlabel('予想値')
plt.ylabel('残差')
plt.grid()
plt.show()出力結果
予測値が低いものはy軸に固まっているが、高いものはまだバラけているように見えます。
次に平均二乗誤差を見てみます。
平均二乗誤差は実際の値とモデルによる予測値との誤差の平均値を出します。低ければ低いほど良いです。
from sklearn.metrics import mean_squared_error
print("平均二乗誤差:",mean_squared_error(train_y,pred1) )出力結果
平均二乗誤差: 472.98908427508695続きまして、決定係数を見てみます。
決定係数は説明変数が目的変数をどれくらい説明できているかを表す値であります。
0.6以下の回帰モデルは使い物にならないが、逆に0.9以上の回帰モデルは過学習の可能性があります。
from sklearn.metrics import r2_score
print('決定係数:', r2_score(train_y,pred1))出力結果
0.6以下なので、もう少し精度を高める必要があります。
決定係数: 0.5604321091063089販売数予測モデルの改善
学習データの編集
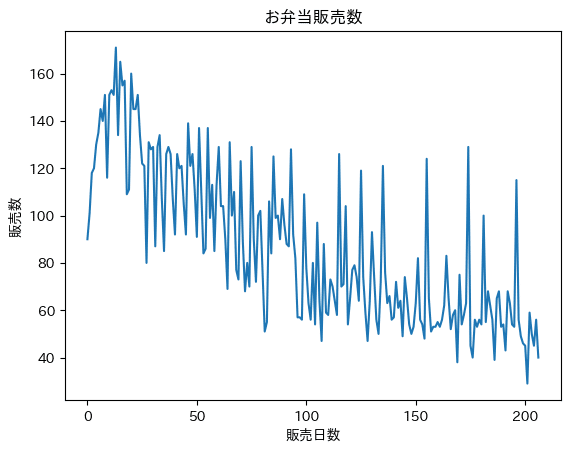
販売数の推移を改めて見て見ます。
最初にガツンと上がった販売数は期間前半に大きく減少する傾向ですが、期間後半からはほぼ横ばい、ないし若干の減少傾向に変わっています。
開店直後は新しさもあって好調だった販売数が、時間とともにだんだん収束して落ち着いていったと考えられます。
なので、後半のみでモデリングした方が精度が上がるかもしれません。
まず、販売数の時間的経過を加味することを意図して、日付情報を追加します。具体的には月(month)を追加し、説明変数データを作り直します。
格納した説明変数をtrain_X変数に格納。目的変数である販売数をtrain_y変数に格納。
features = ["remarks","temperature","week_金","weather_快晴","weather_晴れ","weather_曇","weather_雨","month"]
train_X = train[features]
train_y = train["y"]その後、学習データの説明変数train_Xと目的変数train_yについて、後半半分である100行目以降のみに絞ります。
データフレームが代入された変数[ 指定したい範囲の先頭の行 : 指定したい範囲の最後の行+1 ]で指定したい行のみ絞れます。
今回は100行以降は最後までなので、最終行の記載は省略できます。
train_X = train_X[100:]
train_y = train_y[100:]重回帰モデルを再学習
編集した学習データで重回帰モデルの学習を再実行する。
model.fit( train_X, train_y )再学習したモデルで予測を実行
再学習したモデルを使い、予測値を出します。
引数として予測したいデータの説明変数train_Xを与え計算させ、pred2という変数に格納する。
pred2 = model.predict( train_X )回帰式を再算出
LinearRegressionライブラリを用いて回帰係数と切片を再算出します。
# 切片
print(model.intercept_)
# 傾き
print('{}'.format(pd.Series(model.coef_,index=features)))出力結果
回帰分析から得られた回帰式は以下の通りである。
𝑦 = 61.7𝑥0 + 0.13𝑥1 - 0.93𝑥2 - 2.4𝑥3 - 0.13𝑥4 + 2.4𝑥5 + 8.4𝑥6 - 3.8𝑥7 + 81.1
81.08750337778014
remarks 61.726240
temperature 0.128309
week_金 0.928744
weather_快晴 -2.400059
weather_晴れ -0.130882
weather_曇 2.393647
weather_雨 8.415150
month -3.754731
dtype: float64回帰式の精度を再確認
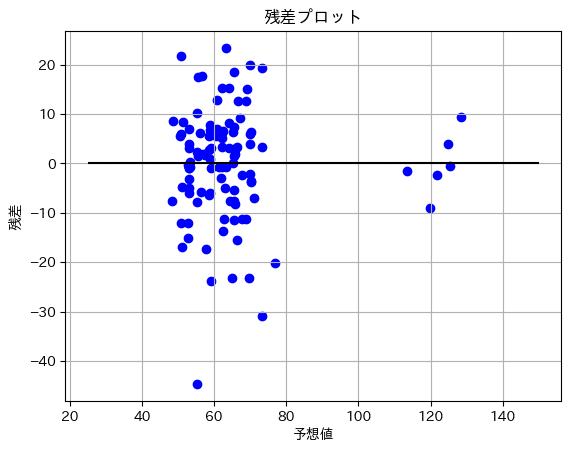
残差プロットを使い、残差のばらつきを見ます。
plt.scatter(pred2, pred2-train_y, color='blue')
plt.hlines(y=0,xmin=25,xmax=150,colors='black')
plt.title('残差プロット')
plt.xlabel('予想値')
plt.ylabel('残差')
plt.grid()
plt.show()出力結果
前回よりはy軸に集中し、外れ値も少ないように見えます。
次に平均二乗誤差を見てみます。
from sklearn.metrics import mean_squared_error
print("平均二乗誤差:",mean_squared_error(train_y,pred2) )出力結果
前回よりも低くなり、精度が上がっているように見えます。
平均二乗誤差: 122.25888695141902続きまして、決定係数を見てみます。
from sklearn.metrics import r2_score
print('決定係数:', r2_score(train_y,pred2))出力結果
0.6以上になったので、回帰モデルは使い物になるレベルであります。
決定係数: 0.6644064277279205作成した予測モデルで販売数を予測
今回は以下の条件をもとに、改善した販売数予測モデルでお弁当の販売数の予測値を出します。
DataFrameで以下の条件になるように説明変数に値を入れて、predictionという変数に入れます。
そして、作成した予測モデルで実行した予測値を出します。
特記事項が「お楽しみメニュー」かつメニューが「カレー」
気温が「27度」
曜日が「金曜日」
天気が「快晴」
月が「9月」
prediction=pd.DataFrame([[1,27,1,1,0,0,0,9]],columns=["remarks","temperature","week_金","weather_快晴","weather_晴れ","weather_曇","weather_雨","month"])
pred=model.predict(prediction)
print(pred)出力結果
約111個になりました。
[111.01420442]結びに
最後まで私のお弁当の需要予測をご覧頂きありがとうございます。
今回、私は特記事項とメニュー、気温、金曜日、天気、月がお弁当の需要予測に影響を与えるものと判断し、それらを説明変数として重回帰モデルを作成しました。
これが唯一の正解ではなく、説明変数を変えたり、データフレームの加工などによりさらに確度のモデルが作れると思います。
ぜひ私のこのモデルを参考により、皆様がより良い予測ができることを期待しています。
(私も精進して参ります!)
データ元:お弁当の需要予測 | SIGNATE - Data ScienceCompetition
https://signate.jp/competitions/24