
トポロジカルソート(再帰を使わないかつ、スタックを使う)

下記のようなトポロジカルソートをJavaScriptで実装してみた。トポロジカルソートを実装する場合、キューを使った非再帰の幅優先探索か、再帰を使った深さ優先探索で実装することが多いように思う。そのため、下記のような非再帰であってスタックを使った実装は珍しいかもしれない。と言っても、再帰を使った深さ優先探索を非再帰に変換しただけだが。
const tsort = (graph) => {
const visited = graph.map(_ => false);
const answer = [];
for (const node of graph.keys()) {
const stack = [[node, -1]];
while (stack.length !== 0) {
const [n, i] = stack.pop();
if (i < 0 && !visited[n]) {
visited[n] = true;
stack.push([n, 0]);
}
else if (0 <= i && i < graph[n].length) {
stack.push([n, i + 1]);
stack.push([graph[n][i], -1]);
}
else if (i >= graph[n].length) {
answer.push(n);
}
}
}
answer.reverse();
return answer;
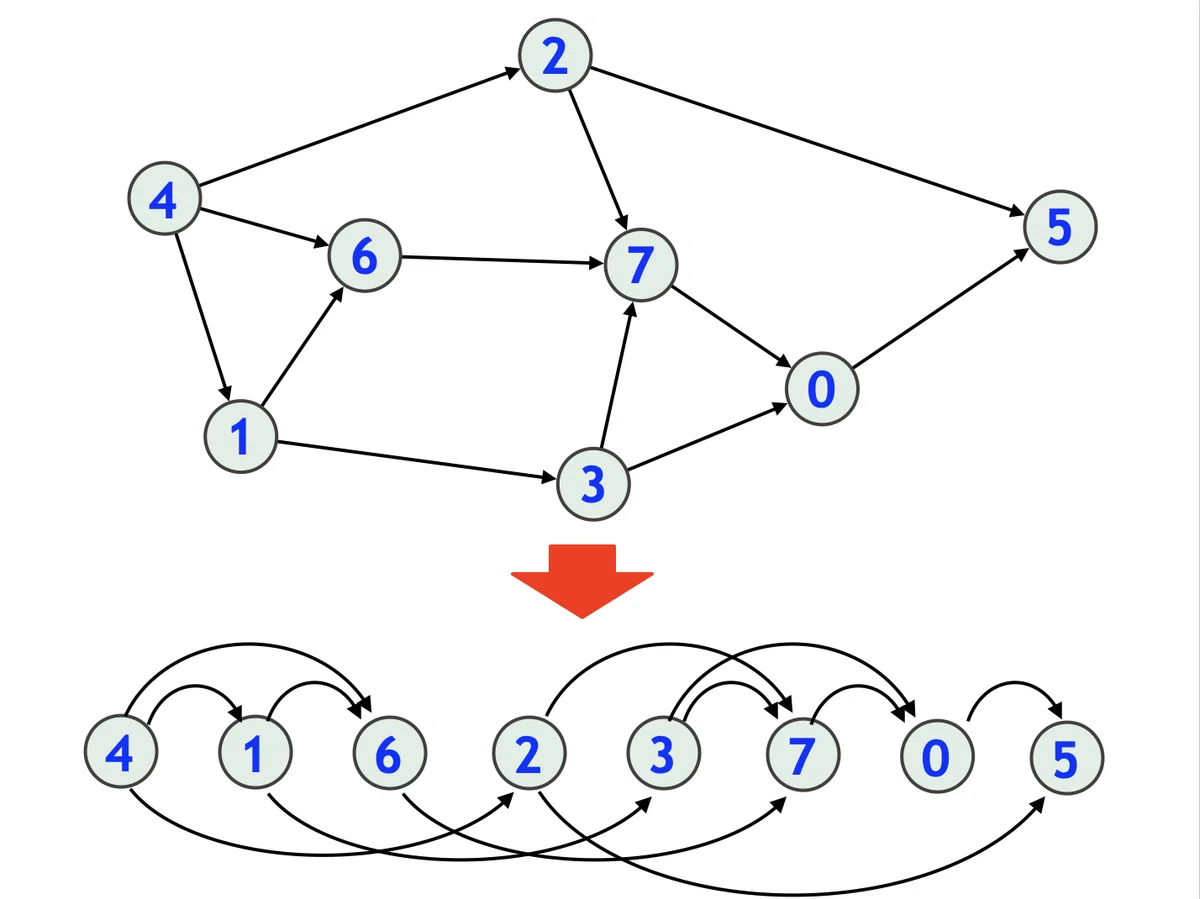
};なお、グラフは数値の配列の配列(隣接リスト)で表現している。例えば、次の配列の配列で表されるグラフは、下記の図のようなグラフになる。
[
[5],
[3, 6],
[5, 7],
[0, 7],
[1, 2, 6],
[],
[7],
[0]
]
Playground
オンラインで動作を試す用のリンク。
以降は、関連用語の雑多なメモ。
グラフとは?
グラフとは、頂点と辺からなる構造のことである。図示する場合、頂点は丸などの図形で、辺は頂点どうしをつなぐ線や矢印で描かれることが多い。グラフには様々なクラス(類)があり、例えば次のようなクラスがある。
無向グラフ:辺に方向がないグラフ。
有向グラフ:辺に方向があるグラフ。
有向非巡回グラフ:グラフ内に巡回(サイクル)がないグラフ。
木:巡回がない連結な無向グラフ
重み付きグラフ:辺に重みがあるグラフ。重みによって頂点間の移動コストや距離を表せる。
これらのグラフは、様々な場面で使われる。例えば、有向グラフは情報のフローやプロセスを表すのによく使われる。重み付きグラフは、最短経路問題や最小全域木問題などを解くのによく使われる。
有向グラフとは?
有向グラフ(directed graph)とは、頂点と有向辺からなるグラフである。有向辺には方向があり、向きを表す矢印が付いている。そのため、各有向辺はある頂点から別の頂点に向かって伸びている。
有向グラフは、情報のフローやプロセスを表すのによく使われる。例えば、Web サイトのページ間のリンクを表すのに有向グラフを使うことができる。あるページから別のページへのリンクを表す有向辺を引いて、各ページを頂点として表すことで、各ページの関係性を有向グラフとして表すことができる。また、ワークフローやビルドの依存関係など、複雑なプロセスを表すのにも有向グラフを使うことがある。
有向非巡回グラフとは?
有向非巡回グラフ(DAG: directed acyclic graph)とは、巡回のない有向グラフである。巡回があるとは、ある頂点から開始して、最終的に同じ頂点に戻るように、有向辺をたどることができることを指す。したがって、巡回がないDAGでは、どの頂点からどの有向辺をたどっても、一度通った頂点には二度と戻って来れない。
DAG はタスクのスケジューリングやビルドの依存関係を表すのによく使われる。依存関係がある場合、あるタスクが完了する前に、そのタスクに依存する別のタスクをすべて完了させる必要がある。DAG を使えば、このような依存関係を表現できる。
トポロジカルソートとは?
トポロジカルソートとは、有向非巡回グラフ(DAG: directed acyclic graph)のある頂点の順序を決定するアルゴリズムである。このアルゴリズムは、有向グラフ内のすべての有向辺 (u, v) について、頂点 u が頂点 v の前に来るようにすることで、頂点の順序を決定する。
トポロジカルソートは、タスクを実行する際に、それらのタスク間の依存関係をすべて考慮した順序でスケジュールする場合によく使われる。例えば、あるタスクが他のタスクの完了を前提とする場合、それらのタスクをすべて完了させる必要がある。そこで、タスクを頂点、タスクの依存関係を有向辺として有向グラフを考えれば、トポロジカルソートが使える。トポロジカルソートを使えば、そのような依存関係を考慮して、タスクを実行する順序を決められる。
なお、タスクの依存関係がDAGにならないなら、巡回する依存関係がある。それはデッドロックのようなもので、つまりタスクを正しく実行する順序が存在しないことになる。あるいは無限ループのようにタスクが永遠に終わらなくなる。そのため、巡回を検知できるように改良されたトポロジカルソートを考える場合もある。
有向グラフのデータ構造にはどのようなものがあるか?
有向グラフのデータ構造には、次のようなものがある。
隣接リスト
隣接行列
これらのデータ構造は、有向グラフを表すのに使われる。どのデータ構造を使うかは、グラフの性質や、使用するアルゴリズムによって使い分ける。
隣接リストとは何か?
隣接リストとは、グラフを表すデータ構造の1つである。各頂点に、隣接する頂点のリストを持たせることで頂点と有向辺を表す。隣接リストを使うと、ある頂点から出る有向辺をすべて取得することができる。また、同じことだが、その頂点が隣接する頂点をすべて取得することもできる。
入次数とは何か?
入次数とは、頂点へ入ってくる有向辺の数である。依存性を有向グラフで表現する場合、入次数を計算することで、ある頂点が他の頂点に依存しているかどうかがわかる。例えば、ある頂点 v に対して、v の入次数が0である場合、v は他の頂点に依存していない。つまり、v を処理する前に、他の頂点を処理する必要がない。そのため、入次数が0である頂点を優先的に処理することで、依存性を考慮した処理が可能になる。
キューとは何か?
キューとは、末尾からデータを追加し、先頭からデータを取り出せるリストである。キューは、先入れ先出し(FIFO: First-In, First-Out)といわれる原則に従ってデータを管理する。
キューは、様々な場面で使われる。たとえば、プロセスを管理するときに、プロセスを実行する順番を決めるために使われることがある。また、最短経路問題や幅優先探索などでも、キューを使用することがある。
キューは次のような操作をサポートしている。
enqueue:キューの末尾にデータを追加する。
dequeue:キューの先頭からデータを取り出す。
isEmpty:キューが空であるかどうかを判定する。
スタックとは何か?
スタックとは、先頭からデータを追加し、先頭からデータを取り出せるリストである。スタックは、後入れ先出し(LIFO: Last-In, First-Out)といわれる原則に従ってデータを管理する。
スタックは、様々な場面で使われる。たとえば、関数呼び出しや深さ優先探索などでも、スタックを使用することがある。
スタックは、次のような操作をサポートする。
push:スタックの先頭にデータを追加する。
pop:スタックの先頭からデータを取り出す。
isEmpty:スタックが空であるかどうかを判定する。
コールスタックとは何か?
コールスタックとは、プログラムの関数を呼び出すときに、その関数を呼び出した関数の環境や、呼び出した関数が終了したときに戻る先を保存するスタックである。
トポロジカルソートの疑似コード(キューを使った非再帰の幅優先探索)
下記の疑似コードでは、VはグラフGの頂点の集合であり、EはグラフGの有向辺の集合である。また、Qはキューを表す。入次数(v)は頂点vへ入ってくる有向辺の数を表す。
下記の疑似コードでは、入次数が0である頂点を探して、それらをキューに追加していく。キューから頂点 v を取り出すと、v をリストLの末尾に追加する。また、v から出る有向辺の先にある頂点 w への入次数を1減らす(すなわちグラフから v を取り除く)。入次数が0になったら、その頂点をキューに追加する。最終的にキューが空になると、トポロジカルソートは終了し、L がトポロジカルソートされたリストであることが保証される。
このアルゴリズムは、再帰を使わないため、コールスタックを消費せずに実装できる。
トポロジカルソート(G)
入力: グラフ G = (V, E)
出力: トポロジカルソートされた頂点のリスト L
以下を実行する:
Q = 空のキュー
L = 空リスト
入次数を計算する
for all v in V do
if 入次数(v) = 0 then
Q.enqueue(v)
while Q is not empty do
v = Q.dequeue()
L = L + v
for all edges (v, w) in E do
入次数(w) = 入次数(w) - 1
if 入次数(w) = 0 then
Q.enqueue(w)
return L
トポロジカルソートの疑似コード(再帰を使った深さ優先探索)
下記の疑似コードでは、VはグラフGの頂点の集合であり、EはグラフGの有向辺の集合である。また、トポロジカルソートの本体となる関数「トポロジカルソート_再帰」を再帰的に呼び出している。頂点 v を訪問すると、v から出るすべての有向辺をたどり、その頂点を再帰的に訪問する。それらの訪問が終わったら、v をリストLの先頭に追加する。v から訪問可能な頂点はすでにリストに追加されているので、最終的に、L はトポロジカルソートされたリストであることが保証される。
トポロジカルソート(G)
入力: グラフ G = (V, E)
出力: トポロジカルソートされた頂点のリスト L
以下を実行する:
L = 空リスト
for all v in V do
トポロジカルソート_再帰(G, v, L)
return L
トポロジカルソート_再帰(G, v, L)
入力: グラフ G = (V, E), 頂点 v, 頂点のリスト L
以下を実行する:
if v はまだ訪問されていない then
v を訪問済みにする
for all edges (v, w) in E do
トポロジカルソート_再帰(G, w, L)
L = v + L
すべてのプログラマーが試すべき挑戦的なアルゴリズムとデータ構造
面白げな実装を思いついたら他のも挑戦しようかな。
全てのプログラマーが試すべき挑戦的なアルゴリズムとデータ構造(6選)
— lotz (@lotz84_) December 29, 2022
・トポロジカルソート
・再帰下降構文解析
・Myersアルゴリズム(差分検出)
・ブルームフィルター
・Piece Table
・スプレー木
年末年始でじっくり調べると楽しそうhttps://t.co/HyPhyXEKHG
この記事が気に入ったらサポートをしてみませんか?