scikit-learnで線形SVC(SVM)クラス分類するテンプレプログラム

自動車の種類を予測するこちらの問題を想定しています。
https://signate.jp/competitions/122
インプットデータ
https://archive.ics.uci.edu/ml/datasets/Car+Evaluation
こちらのデータに、
・id列が付与
・1行目に見出しが付与
という状態が「train.tsv」、
・id列が付与
・class列が削除
・1行目に見出しが付与
という状態が「test.tsv」です。
問題
test.csvのclassを予測します。
プログラム全体
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
from sklearn.svm import LinearSVC
import sklearn.model_selection
from sklearn.metrics import accuracy_score
#訓練データの読み込み
train_data = pd.read_csv("ディレクトリ/train.tsv", delimiter='\t')
X = train_data.drop(["id", "class"], 1)
#特徴量の変換
scale_mapper_lug_boot = {
"big" : 3,
"mid" : 2,
"small" : 1
}
scale_mapper_persons = {
"more" : 5
}
scale_mapper_safety = {
"high" : 3,
"med" : 2,
"low" : 1
}
scale_mapper_buying = {
"vhigh" : 10,
"high" : 5,
"med" : 2,
"low" : 1,
}
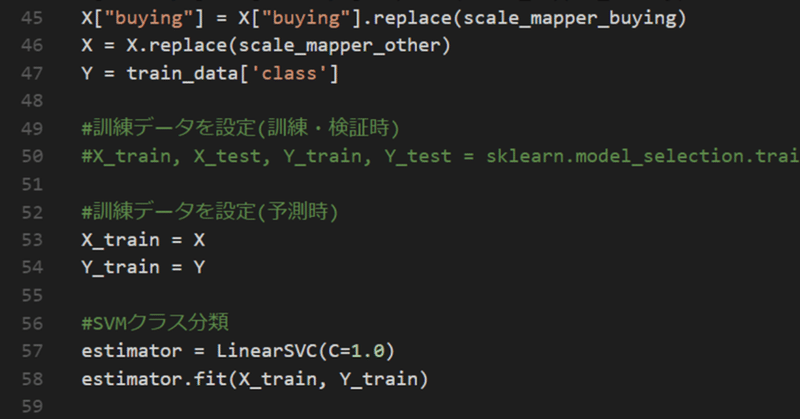
scale_mapper_other = {
"vhigh" : 5,
"high" : 4,
"med" : 2,
"low" : 1,
"5more" : 5
}
#特徴量を置き換えながら訓練データを作成
X["lug_boot"] = X["lug_boot"].replace(scale_mapper_lug_boot)
X["persons"] = X["persons"].replace(scale_mapper_persons)
X["safety"] = X["safety"].replace(scale_mapper_safety)
X["buying"] = X["buying"].replace(scale_mapper_buying)
X = X.replace(scale_mapper_other)
Y = train_data['class']
#訓練データを設定(訓練・検証時)
#X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X,Y)
#訓練データを設定(予測時)
X_train = X
Y_train = Y
#SVMクラス分類
estimator = LinearSVC(C=1.0)
estimator.fit(X_train, Y_train)
#検証データの読み込み(予測時)
test_data = pd.read_csv("ディレクトリ/test.tsv", delimiter='\t')
X_test = test_data.drop(["id"], 1)
X_test["lug_boot"] = X_test["lug_boot"].replace(scale_mapper_lug_boot)
X_test["persons"] = X_test["persons"].replace(scale_mapper_persons)
X_test["safety"] = X_test["safety"].replace(scale_mapper_safety)
X_test["buying"] = X_test["buying"].replace(scale_mapper_buying)
X_test = X_test.replace(scale_mapper_other)
#検証
predict_output = DataFrame(estimator.predict(X_test))
#モデル精度評価(訓練・検証時)
#print(accuracy_score(Y_test, predict_output))
#結果出力(予測時)
predict_output.index = test_data['id']
predict_output.to_csv("ディレクトリ/output.csv", header=False)
前処理
#訓練データの読み込み
train_data = pd.read_csv("ディレクトリ/train.tsv", delimiter='\t')
X = train_data.drop(["id", "class"], 1)
#特徴量の変換
scale_mapper_lug_boot = {
"big" : 3,
"mid" : 2,
"small" : 1
}
scale_mapper_persons = {
"more" : 5
}
scale_mapper_safety = {
"high" : 3,
"med" : 2,
"low" : 1
}
scale_mapper_buying = {
"vhigh" : 10,
"high" : 5,
"med" : 2,
"low" : 1,
}
scale_mapper_other = {
"vhigh" : 5,
"high" : 4,
"med" : 2,
"low" : 1,
"5more" : 5
}
#特徴量を置き換えながら訓練データを作成
X["lug_boot"] = X["lug_boot"].replace(scale_mapper_lug_boot)
X["persons"] = X["persons"].replace(scale_mapper_persons)
X["safety"] = X["safety"].replace(scale_mapper_safety)
X["buying"] = X["buying"].replace(scale_mapper_buying)
X = X.replace(scale_mapper_other)
Y = train_data['class']・訓練データが「big」「small」などの文字で定義されているので、これを数値に変換します
・変換する数値は適当に設定しており、ここのチューニングで精度が変わってくるはずです
分類処理
#訓練データを設定(訓練・検証時)
#X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X,Y)
#訓練データを設定(予測時)
X_train = X
Y_train = Y
#SVMクラス分類
estimator = LinearSVC(C=1.0)
estimator.fit(X_train, Y_train)・訓練時はtrain.tsvを訓練用と検証用に分割、予測時はtrain.tsvをすべて訓練データに充てます
検証・予測
#検証データの読み込み(予測時)
test_data = pd.read_csv("ディレクトリ/test.tsv", delimiter='\t')
X_test = test_data.drop(["id"], 1)
X_test["lug_boot"] = X_test["lug_boot"].replace(scale_mapper_lug_boot)
X_test["persons"] = X_test["persons"].replace(scale_mapper_persons)
X_test["safety"] = X_test["safety"].replace(scale_mapper_safety)
X_test["buying"] = X_test["buying"].replace(scale_mapper_buying)
X_test = X_test.replace(scale_mapper_other)
#検証
predict_output = DataFrame(estimator.predict(X_test))
#モデル精度評価(訓練・検証時)
#print(accuracy_score(Y_test, predict_output))
#結果出力(予測時)
predict_output.index = test_data['id']
predict_output.to_csv("ディレクトリ/output.csv", header=False)・予測時は、test.tsvを読み込んで、train.tsvと同じ変換処理を施します
・検証後、訓練時は正解率を評価して出力、予測時はoutput.csvに結果を出力
実行結果
0.8009259259259259・正解率80%です。
この記事が気に入ったらサポートをしてみませんか?