[digital healthの調べ] 2019年前半までのgoogle 電子カルテ x deep learning アプローチ

私は、普段、デジタルヘルス領域で研究開発をしています。日々すごい勢いで進む機械学習の研究が、医療の分野でも成果がでつつありますので、少しずつアウトプットして、自分の頭の整理をして行くための記事です。
自己紹介
私は、10年間、医療分野のIoTフルスタックエンジニアとして、医療機器を中心に開発していましたが、現在は、転職して、digital health分野における研究開発をしています。
googleの医療 x 自然言語処理アプローチ
近年、googleが巨大なコンピュータリソースと人工知能のテクノロジーを武器にhealthcareの分野の研究を力を入れて進めています。事業としてのアプローチは、現在のところ、あまり明確ではないように思えますが、他社に対する差別化が図れるほどの結果を出し続けている印象です。
そのdeep learningを進めてきた結果として、今年の1月にスタンフォード大学とgoogle researchがhealthcareの分野におけるdeep learningの活用に関する記事を書いています[1]。

今回は、その記事にもある自然言語分野におけるアプローチとして、電子カルテの研究内容を見ていきたいと思います。
電子カルテのデータ活用の期待
電子カルテには、膨大な医療に関するデータが存在し、このデータを学習に使えれば、様々な種類の病気に対する知見を活用できるのではないかと言われています。
先ほどの[1]の文献でも以下のように記載されています。
- 大規模な医療機関の電子カルテは、10年間で10000万人を超える患者の医療情報が記録されている
- 1回の入院で、通常150,000個程度のデータが生成されている
- この膨大なデータは、非常に稀な病気も網羅できているでは、この大規模なデータはなぜ活用されていないのでしょうか?
電子カルテのデータ活用に関する課題
電子カルテのデータ、非構造化データと言われる定型化されていない医療者のフリーテキストがかなりの量を占めています。これらのデータを活用するには、大きなハードルがあります。それは、膨大なデータを成形して、学習可能なデータフォーマットに変換しなければいけないのです。
このような課題に取り組んだのが、googleとカリフォルニア大学の共同研究です[2]

解決の糸口になるDeep learning
上記でも引用した"Scalable and accurate deep learning with electronic health records"では、Deep learingが自然言語処理、シーケンス予測、マルチモーダルデータ解析において有用であることが示されており、上記のような非構造化データにおいても大量の処理ができる可能性があることを言及しています。
そこで、この論文では、Deep learningを使用して、フリーテキストを含む電子カルテ全体のデータを取り込んだ予測モデルを作成し、検証しました。
これにより、これまでデータ入手の容易なICUの事例が大半を占めていた予測研究に対して、6倍以上の患者がいる非ICU入院患者を対象に研究できることが大きな利点になります。
また、この研究では、単施設におけるデータ活用だと汎用性が出ないので、複数施設において、解析結果が有用であるか検証していますが、今回は長くなるのでこの部分には触れません。
研究で取り組んだ内容
多種多様な予測問題設定でdeep learningを適用し、有効性を示すことにフォーカスを当てています。具体的には、入院患者の死亡予測、30日以内の再入院予測、7日以上の入院予測など、病院経営にインパクトある指標に関する予測をチャレンジしています。
この予測に対して、三つの機械学習モデルを使い分けて検討したようですが、メインは、時系列データを扱う機械学習の手法であるRNNの中でもLSTMというモデルを活用したことでしょう。
その時系列データをどのように扱うのか、その概念的な内容は論文にも掲載されているので、それを参照します。

このように、1患者が時系列で入力されているデータをまとめ、LSTMにその時系列データを突っ込んだと考えれます。
より俯瞰的な視点から見たものが、googleが提出している特許[3]から見ることができます。システム構成、使用するデータ構造、データ解析フロー、ユーザーの利用画面を具体的にどのようにgoogleが考えているのかよくわかる図になっているので特許出願資料は非常に有用だと改めて感じます。(ちなみに、まだ特許になっていないように見えます)

Fig. 1が全体のシステム構成、Fig. 2がデータ構造、Fig. 3C2が予測・解析、Fig. 8Aがユーザーが使用する予測結果表示ダッシュボード。
研究の結果
これまでの伝統的な手法で算出したbaselineに比べ、今回のモダンな手法で予測結果がどれほどよくなったのか、文献[2]を引用します。
値は、ROC曲線化の面積です。それがどのような意味を持つか知りたい方は文献[4]などをご参照ください。1で完全な予測、0.5でランダムな予測を意味しており、1に近い方が良いということになります。
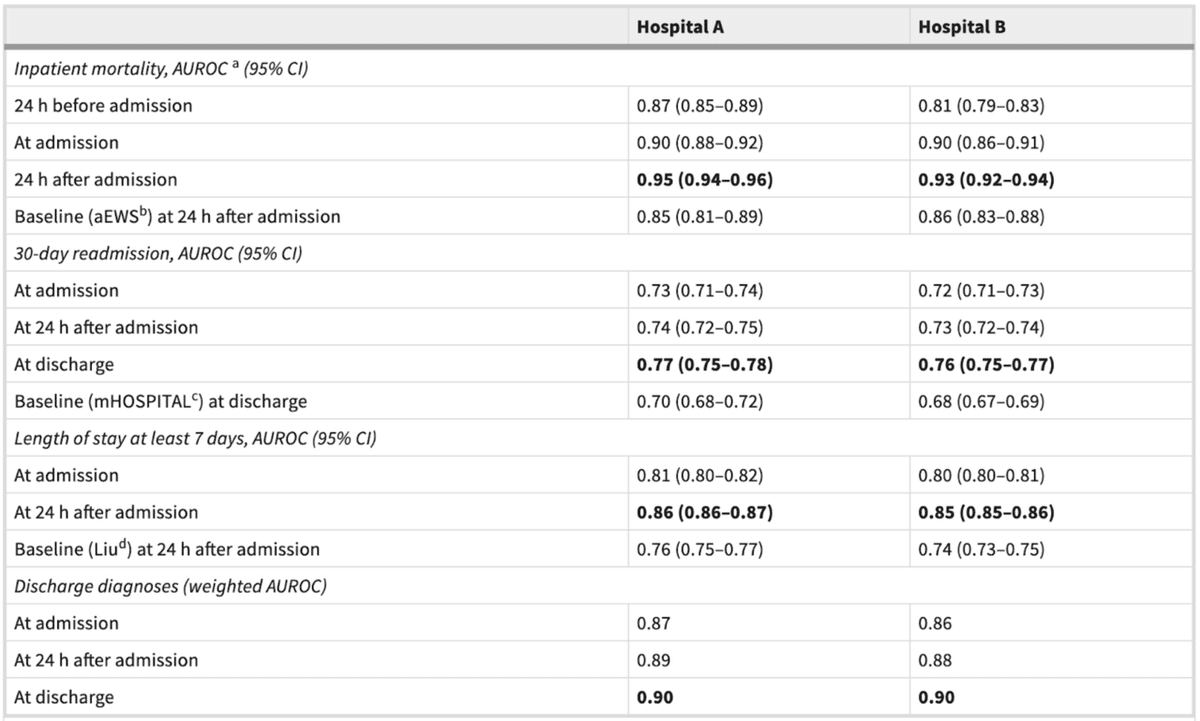
・入院患者死亡予測:入院24時間後の予測で、baseline 0.85に対し、0.95
・30日以内の再入院予測:退院時の予測で、baseline 0.70に対し、0.77
・7日以上の入院期間予測:入院24時間後の予測で、baseline 0.76に対し、0.86
最後に...
時系列の機械学習手法を使用して、フリーテキストを取り込み、病院の経営にインパクトのある指標を予測する取り組みについて紹介しました。ここで取り上げた内容は、予測結果もさることながら、何億の非構造化データを活用できるようにした工程があることを考えると、深い尊敬の念を抱きます。
次々に出てくる注目のgoogleの研究から目が離せない状況です。
参考文献
[1]A guide to deep learning in healthcare, nature medicine, 07 January 2019
[2]Scalable and accurate deep learning with electronic health records, npj digital medicine, number: 18 (2018)
[3]US patent(google) : System and Method for Predicting and Summarizing Medical Events from Electronic Health Records, Publication Date: 31.01.2019, Application Date: 30.08.2017
出張したときの探索費をいただけると助かります笑