
[iOS 17] NLContextualEmbedding のベクトルを用いて文章検索を行う

ベクトル化した文章のデータベースから、クエリに近い文章を取り出す、という検索手法がLLM文脈でよく行われる。(RAG: Retrieval Augmented Generation と呼ばれるらしい)
Retrieval-augmented Generation(RAG、検索により強化した文章生成)は、LLMが持つ知識の内部表現を補うために外部の知識ソースにモデルを接地させる(グラウンドさせる)ことで、LLMが生成する回答の質を向上するAIのフレームワークです。LLMベースの質問応答システムにRAGを実装すると、主に2つの利点があります。すなわち、モデルが最新の信頼できる事実にアクセスできることと、ユーザーがモデルの情報ソースにアクセスできるようにすることで、モデルの主張が正確かどうかをチェック可能にし、最終的に信頼できることを保証することです。
これをOpenAIのEmbeddings APIを使ってiOS/Swiftでやってみた、というのがこちらの記事:
で、これと同様のことをiOS 17で追加された NLContextualEmbedding を用いてやってみた、というのが本記事。
Natual LanguageはiOS/macOSの標準フレームワークなので、これでうまくいけばOpenAIのAPIを使わず、ネイティブの機能だけで完結することになる。
Contextual な Embedding とは
簡単にいうと、非Contextualな(Staticな)embeddingは単語からベクトルへの単純な写像に過ぎず、単語に対してモデルは常に同じベクトルを返すが、
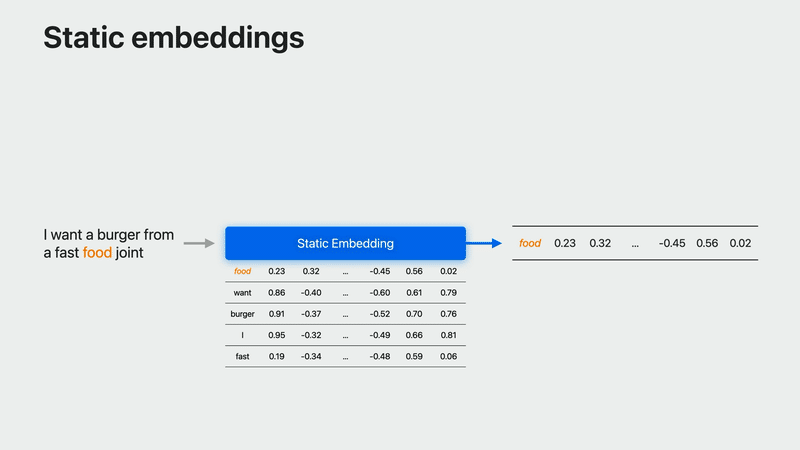
Contextualなembeddingは文中の各単語が文中での使用状況に応じて異なるベクトルにマップされる。

例えば、「fast food joint」の「food」と「food for thought」の「food」は意味が異なるので、異なるベクトルを得ることになる。
なお、WWDC23の "Explore Natural Language multilingual models" セッションで解説されている詳細についてはこちらの記事にまとめた:
NLContextualEmbeddingとBERT
WWDC23での同セッションでは、今回から Transformer ベースの Contextual Embeddings、具体的には BERT embeddings を提供するようになった、と述べている。その埋め込みモデルがCreate MLで利用できるようになり、そして Natural Language フレームワークにもその埋め込みモデルを利用するAPIを追加した、そのAPIが NLContextualEmbedding である、と。
NLContextualEmbedding の APIリファレンスでは明確にBERT Embeddingsモデルであるとは述べられていないが、
しかしWWDC23の同セッションの話を総合するとそういうことのようだ。
NLContextualEmbedding でベクトルを得る
前置きが長くなってしまったが、ここからが実装の話。
データや実装内容は、基本的には冒頭に挙げた記事のOpenAIのEmbeddings API版と同様。(こちらの記事がオリジナル)
NLContextualEmbedding に関する実装部分だけ抜粋して紹介していく。
NLContextualEmbedding の初期化
言語( NLLanguage 型)を指定するだけ。
let embedding = NLContextualEmbedding(language: .japanese)!スクリプト( NLScript 型)を指定するイニシャライザもある。
アセットの取得
NLContextualEmbedding を利用するには、「アセット」をリクエストする必要がある。
上述の通りAPIリファレンスには何も書かれていないのだが、実は hasAvailableAssets というプロパティのヘッダに説明がある:
/* A given NLContextualEmbedding can be loaded and used only if the necessary assets have been loaded onto the current device. Clients may use hasAvailableAssets to determine whether they are, and if they have not been, clients may put in a request for those assets. If they are available for loading, then they will be requested and at some point will be loaded and made available on the device, and the completion handler will be called on an arbitrary queue. The completion handler may be called immediately if the state of the assets is already known or if an error occurs.
*/
open var hasAvailableAssets: Bool { get }与えられたNLContextualEmbeddingは、必要なアセットが現在のデバイスにロードされている場合にのみロードされ、使用されることができる。クライアントはhasAvailableAssetsを使用してアセットがロードされているかどうかを判断することができます。アセットがロード可能であれば、アセットがリクエストされ、ある時点でロードされてデバイス上で利用可能になり、任意のキューで完了ハンドラが呼び出されます。完了ハンドラは、アセットの状態がすでに分かっている場合や、エラーが発生した場合に即座に呼び出されることがあります。
アセットをリクエストするには以下のメソッドのどちらかを使う。
open func requestAssets(completionHandler: @escaping (NLContextualEmbedding.AssetsResult, Error?) -> Void)
open func requestAssets() async throws -> NLContextualEmbedding.AssetsResultなおアセットは NLContextualEmbedding のイニシャライザで異なる言語を指定していれば別途リクエストする必要があるようだ。(.english と .japanese で試して、それぞれリクエストする必要があった)
"Failed to load contextual embedding" エラー
上述のアセットの取得を怠ると、embeddingResult メソッドを呼ぼうとしたところで
Error Domain=NLNaturalLanguageErrorDomain Code=8 "Failed to load contextual embedding"
というエラーになる。
ベクトルの取得
embeddingResult メソッドを利用し、NLContextualEmbeddingResult オブジェクトを得る。
open func embeddingResult(for string: String, language: NLLanguage?) throws -> NLContextualEmbeddingResultそこから tokenVector(at:) メソッド、あるいは enumerateTokenVectors(in:using:) メソッドを用いることで各トークンのベクトルを得られる。
@nonobjc public func tokenVector(at index: String.Index) -> ([Double], Range<String.Index>)?
@nonobjc public func enumerateTokenVectors(in range: Range<String.Index>, using block: ([Double], Range<String.Index>) -> Bool)文章の検索
ここで「あれ?」と気付いたのだが、この NLContextualEmbedding は、文中の「トークン」のベクトルを返す。
トークンは、たとえば
成人とは、法律的には満20歳以上のことを指します。…
というようなテキストであれば、「成人 / と / は / 、 / 法律 / …」という感じで分けられていた。それぞれのベクトルは今のところ512次元だった。(これは NLContextualEmbedding の dimensionプロパティで調べられる)
OpenAIのEmbeddings APIは、渡したテキストに対して1536次元のベクトルで返す。渡すテキストがどんな長さであれ(もちろん最大長の制限はあるが)、ベクトルサイズが固定なので、単純に類似度を計算し、比較できる。
ところがこの NLContextualEmbedding はトークンごとのベクトルが固定長ではあるが、テキスト全体でいえばトークンの数はバラバラで、どう文章同士の類似度を比較すればいいのかがわからなかった。
用途が違う、NLEmbedding を使え、と try! Swift NYC でEmbeddingsについてワークショップをやっていた人には言われてしまった。
ただ「ContextualなEmbedding」というコンセプトだけ見れば、文章全体の特徴をより適切に捉えられるのではと解釈しても良さそうに(自分の理解の範囲では)思える。
以下は「実は間違ってるかもしれないが一応これでうまくいってそうな結果は得られました」という実装について。
ここから先は

#WWDC23 の勉強メモ
WWDC 2023やiOS 17についてセッションやサンプルを見つつ勉強したことを記事にしていくマガジンです。また昨年キャッチアップをお休…
最後まで読んでいただきありがとうございます!もし参考になる部分があれば、スキを押していただけると励みになります。 Twitterもフォローしていただけたら嬉しいです。 https://twitter.com/shu223/