
AI時代との向き合い方

更新履歴
☑️第2波 合成AI、ブレインマシーンインターフェースの内容を追加(NEW)
☑️「AI時代の価値曲線」、新インターフェースの内容を追加
☑️ChatGPT「プラグインプラットフォーム」で世界変革が始まった内容を追加
この記事は、こんな人におすすめ
・ChatGPTなどが出てきて世界が変わりはじめたと実感しはじめ、キャッチアップをしたい人(GPT-4,PaLM etc)
・AIツールを触る機会が増えてきたが、AIに関する情報に追われて不安な方
・ビジネスにAIを活用したい、サービスやプロダクトを考えたい方
・経営、マネージメント層でAI時代における戦略・戦術を考える立場の方
・Prompt EngineeringやPrompt Designに興味を持っている方
はじめに
AIの技術進化は目覚ましく、どのようなツールを導入すればいいのか分からないという声をよく聞きます。
この技術革新はほぼ全人類に影響力があり、私たちの生活行動変容が起きていくのも、案外もうすぐなのかもしれません。
AIを活用することによって生産性・効率性・創造性が高まる一方で、『ホワイトワーカーがAIに取って代わられてしまう可能性が高い』という不安があります。
そこで、現時点での「AI時代との向き合い方」をUXデザイナーの個人的な視点から書いています。
元々この記事を書いている最中に、役員に向けのプレゼンを機会をいただいたのでそこで発表した内容も多く記載しています。

私について👇
※私は完全に技術に関しては素人なので、ぜひ読者の方々から間違いや不足あればアドバイスいただきたいです。
結論

結論から言うと…
AIツールが実現できることや生成できるもの、私たちが体験するソリューションにあたる「How」に関して見聞きすることは多いなかで、
なぜ生活行動変容を変えうる力を持っているのか、つまりAIの本質である「Why」について考えることが向き合い方の一つの解だと考えています。
AIの本質は「生成」ではなく「推論」
以前も記事「”あなたの思考を拡張する! チャットAIとの対話アプローチ”」の中でとりあげましたが、よく見かける”Generative AI”という言葉は、一見クリエイティブを模倣また生成するだけのように思われがちです。
ただ、実際のところ今起きているこの革命の重要な点は、我々が既知の事柄を元にして未知の事柄について予想し論じる=「推論」 をAIが行い、そして生成・実行してしまうことなのです。
"generative AI" is IMO a dumb term and i hope it doesn't stick
— Sam Altman (@sama) February 2, 2023
("genAI" is obviously even worse)
「ジェネレーティブ AI」は馬鹿げた言葉であり、定着しないことを願っている。

「推論」とは、既知の事柄から未知の事柄を予想し論じることを指します。この推論能力はクリエイティブ業界だけでなく、人類全員に関わる革命的なものと言えます。
思い浮かべてください…生活のなかでちょっとしたことを決めるときから、企業で意思決定をするとき…多くのシーンで私たちは連鎖的に推論をつかっています。

「推論」能力はまだ生み出されていないこと発見することもあります。
GPT-4は推論にどう影響を与えるのか
まずは「新しいChatGPT!!やばい」と騒がれている、そのモデルGPT-4はマルチモーダルといい、テキスト以外の情報の意味や文脈も理解しコミュニケーションできるツワモノです。
すでに実験的にいくつかのサービスが搭載しています。

ざっくりいうと、Twitterポストにあるように
・マルチモーダル対応
・性能、精度向上
・処理できる量が増えたので、多くの情報のやり取りができる
⚡️「GPT-4」がついにリリース
— しょーてぃー / UX Designer&AI Prompt Designer (@shoty_k2) March 14, 2023
◆テキストだけではなく画像入力にも対応
◆人間なみのパフォーマンス(複数ベンチマーク)
◆ChatGPT+で使えるように!!
◆APIも公開
◆今までよりはるかに多い文脈維持や指示ができるバージョンも(32,000token)
また、大きな波が来た。https://t.co/wKGacVv9CD https://t.co/OaH6XMbRh7 pic.twitter.com/r6BxtuXcX9
実際のチャット例
大きくビジネスが変わるな
— しょーてぃー / UX Designer&AI Prompt Designer (@shoty_k2) March 14, 2023
GPT-4は実際何ができるのか。画像とテキスト入力を合わせると
例えば...
・チャートの読み解き、さらに追加の計算
・長い資料や論文の要約、質問も可能
・画像が表す状態の説明や解説、質問も可能
SNS、EC、あなたの写真フォルダの画像がどう使えるのか考えるだけで.. https://t.co/zpoqrv3uov pic.twitter.com/uPTHyAXJGT
つまり、「AIに目がつき」より多くの情報から高度な推論を行うと言えます。我々が今までパワポで可視化していたドキュメント、漫画やあなたのスマホに入っている写真ですら使えてしまうのです。
一般公開されるのは来年2024年になるとのことです。
さてここからは、この優れた「推論」能力をより解像度高く、もう少し細分化して端的に紹介していきたいと思います。
適応的分解

適応的分解とは…
目的に対して自ら順序立てをして必要な思考やタスクに分解すること。途中で課題や制約があっても筋道を考えて目的に向かう。
目的はとても具体的なことから、曖昧な基準でもそれに合わせて働く。
📝事例
Performer-MPC


さまざまな環境に適応して、社会的に許容される行動を示しながらロボットが狭い空間をナビゲートしています。これもAIの力です。
なにか、モノや人が予期せぬ行動をして障害となったときも、柔軟にプロセスを変えて目的をこなしていきます。
語弊を恐れずに書くと、ChatGPTのインターフェースの裏で動いているLLM(大規模言語モデル)にも、人間が当たり前に行っていることができるようになったのです。
価値付け変換

文脈、相手のスキルやニーズに合わせて適切な情報形式に変換すること
今まで変換の媒介となっていた役割の代替可能性が高まる
通訳者を例にとると分かりやすいと思います。機械的に変換するのではなく、文脈や受け取り側のスキルに合わせて言葉を選んで伝えています。つまり、対象に価値や意味のある状態の情報にするのです。
もちろん、この価値付け変換はこれは言語だけの話にとどまりません。
📝事例
日本語で作りたいものをしゃべるだけで、実装コードを教えてくれるようになりました。
[超朗報!]
— しょーてぃー / UX Designer&AI Prompt Designer (@shoty_k2) February 20, 2023
デモ付き(音あり)
ChatGPTと音声会話できる本プラグインは今は
-日本語で音声入力→対応😍
-日本語で返答出力→カタコト
なので音声入力のみを許可して、
返答はテキストのみでもらう設定がおすすめ
右上のスピーカーアイコンをオフするだけ
タイピング面倒になっていたのでありがたや https://t.co/6ZDtrOesPV pic.twitter.com/iJcCeDEb3e
📟GPT-4を使うと…
手書きのスケッチを写真で撮ってものから、コード付きのWebサイトを生成できます。
拝啓 制作に関わる方へ
— しょーてぃー / UX Designer&AI Prompt Designer (@shoty_k2) March 14, 2023
手書きスケッチからWebサイトへ
GPT-4の力で、手書きからコード付きのちゃんとしたWebサイトに自動変換できる時代がやってきました。
pic.twitter.com/6TGKvvDgKD
これは実装や制作にかぎらず、より企画や戦略のレイヤーにも活用できます。
リバースエンジニアリング(逆解析)
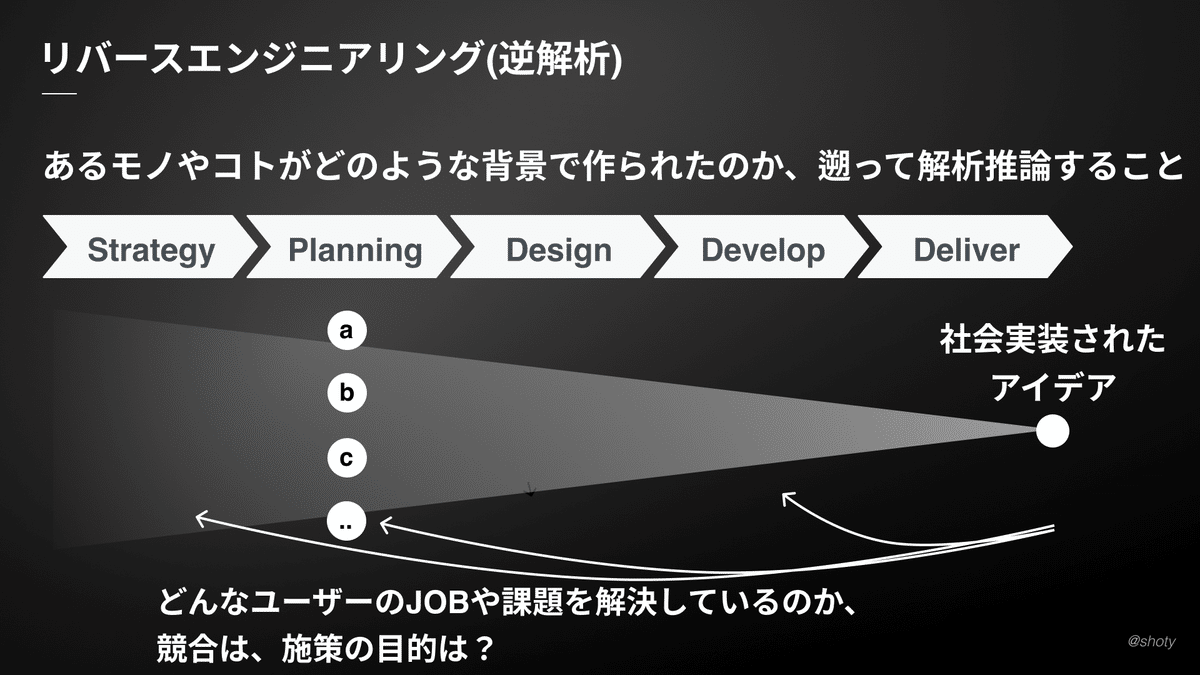
リバースエンジニアリングとは…
一般的には既存の製品、ソフトウェア、またはその他の物体の構造や動作を理解するためのプロセス。
逆方向に設計や解析を行うことを意味する。
非技術者にもこの能力の必要性は高い
言い換えればあるモノやコトがどのような背景で作られたのか、遡って分析し推論する能力といえる
例えばあなたが素敵だと思えるアプリに出会ったときもみたときにも、ビジネスにおいて競合他社の施策を分析するときも、どんな戦略のもとにどのようなユーザーのニーズや課題を解決しているかを考える場面は多いのではないでしょうか。
📝事例
「Value Discovery」
ユーザーの消費メカニズムを深く理解するJOB理論を応用してアイデアからリバースエンジニアリングを行い、顧客のニーズやそれを取り巻く課題、潜在顧客、代替手段やより具体的なアイデアを提案するサービスです。
手前味噌になってしまいますがこれは友人と作ったサービスで、現在は経営層からPdM、UXデザイン、個人事業主やコンサルティング会社の方々に現在ご利用いただいています。(無料お試しあり:2023/6
月時点)
概念ブレンド

概念ブレンドとは…
一見異なる性質・領域の概念、アプローチ、要件、表現などを融合させて新しいそれらを構築すること
📝事例
-異なる領域の職種同士でも使える価値創出アプローチ作る
→UXデザイナーとマーケターが共通言語で使えるフレームワーク作り
-特許同士を融合して、新しい特許を生み出す
-Pythonコード同士を融合して、新しいプログラムを作る
などなど…
絶賛自分も修行中でなので、今回は隣接領域をブレンドする事例をとりあげます。
例えば薬物開発の現場で使われる薬が治療効果を及ぼす仕組みである「作用機序」と、どのような機能や体験があるとユーザーが目的を達成できるのかを考える「UXデザイン」の考え方を融合してみましょう。
今回は「ポケモンGO」を題材にします。狙いは人間の脳や神経にどのようにこのサービス作用するのか、より客観的な仮説を持つためです。
作用機序の例

さて、はじめましょう!

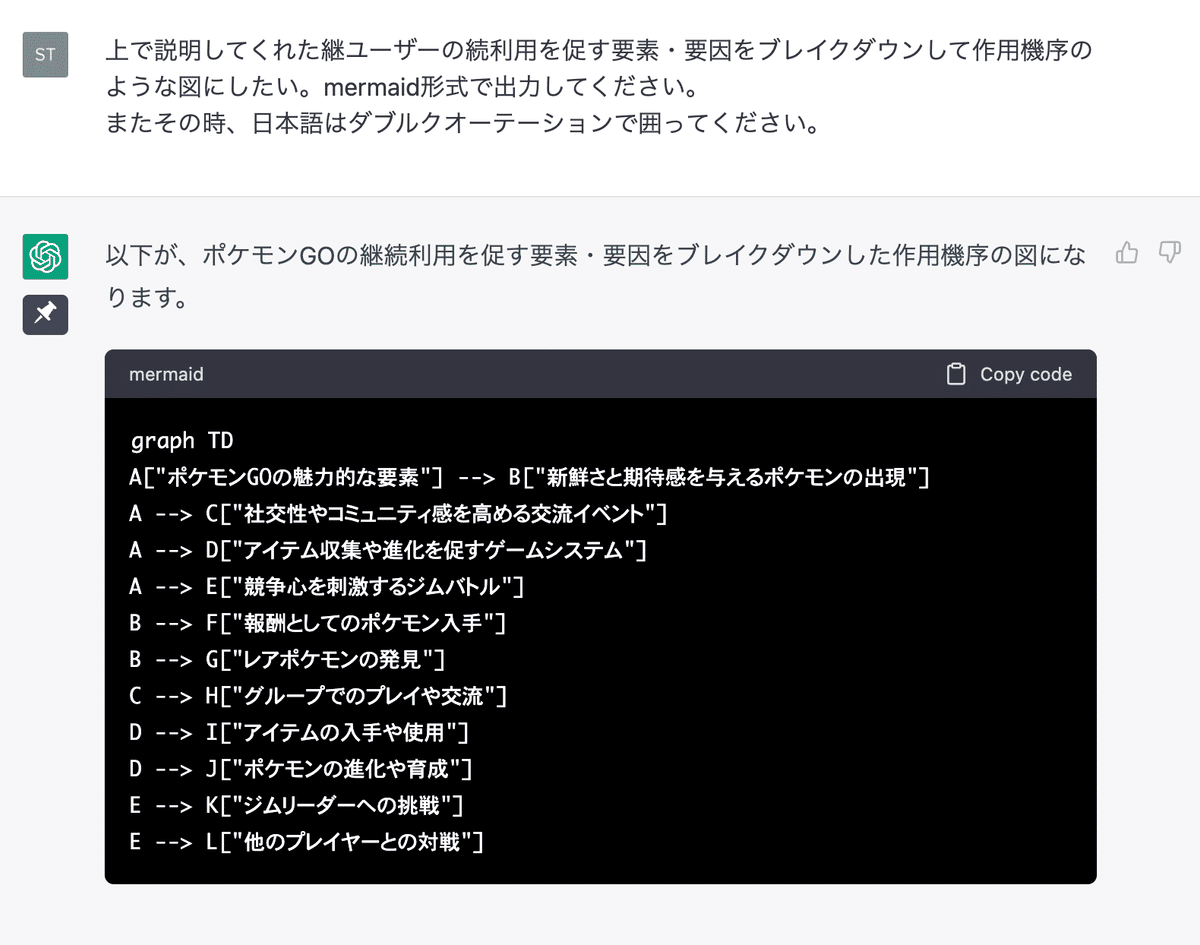
図式化

さらに詳細を聞いて図式化

さらに他の概念と融合してよりシンプル化と関係性の明確化をする
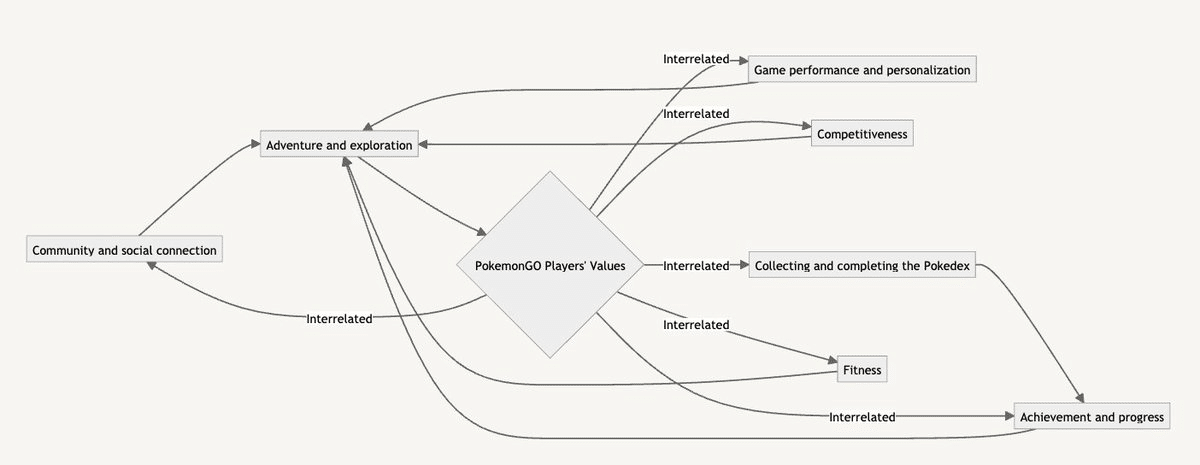
📟マルチモーダル(GPT-4など)なら、さらに飛躍させることができると考えています。
GPT-4は画像やPDF意味その中の文章も理解します。


例えば、複数のビジネスモデルの図解を読み込ませて概念的に昇華し、まったく新しいビジネスモデルやスキームを作り上げることもできるでしょう。
一見遠く異なる領域からの概念を活用して、既存ドメインにブレイクスルーを導き出せるので、私もAIを活用して再現性高く効果的な概念ブレンドできるようにトレーニング予定です。
自己並列化

自己並列化とは…
LLMの中にさらにAIを作り出し、擬似的に1人複数役をこなし価値創出能力を高めること
他AIモデルと共創することも可能
例えば、生成したコードをチェックダブルチェックさせ、間違っていれば自己補完させることや、あるテーマに対して複数のAIが議論し統合的な結論を導くことができます。
よく「ChatGPTは嘘をつく」と言われますが、ChatGPTが出力した結果を人が見る前に正確性が高い特長を持った別のAIモデルを挟むことでフィードバックをかけて答えを修正させて、人に表示させる試みもあり弱点の補完することもできます。
自社のビジネス用に追加学習したAI同士を相互作用させることで、多角的な観点でさらに超高速でビジネス課題の解決に近づくこともできるかもしれません。
📝事例
とはいえ、イメージしにくいと思うので、今回はみなさんが知っているアニメを元に登場人物を2人にシンプル化して紹介します。
ドラゴンボールの「孫悟空」と「フリーザ様」を擬似的にChatGPT内に作り出します。
むろん、片方の思想では偏っているので2人を相互監視させることでバランスのとれた建設的な意見を導き出そうという試みです。



最後のほうは口調が一般人に戻ってきてしまったので
もう一度会話させる

noteの深津さんは9体のAIを召喚して、意見集約させ出力させていました(驚愕のMAGIシステム)

これからの価値曲線
これだけかんたんにモノを作れるようなってきた世界でなにが競争力になるのか考えていかなければならないのでしょうか。
今何が起こり始めているのか。シンプルに捉えるならば、生活者者への提供価値の平均点が上がっていくでしょう。

AIの力で短期&小リソースで仮説検証
そしてリリースを何本も繰り返して、顧客にフィットそうなものを見つけ事業シナジー・UXデザインなどの観点から磨き上げが必要になってくるでしょう。
OpenAIの日本支社シェイン・グウさんが分析する今のリーダーにも体験設計を考えるUXデザイナーがプロットされていることも印象的です。
今回 @NewsPicks weekly @ochyai で伝えたかった事の一つです。https://t.co/8MqKW98T8c pic.twitter.com/ivaWQq7mPo
— シェイン・グウ (@shanegJP) February 2, 2023
固有知

現在、GPTを始めとしたLLM(大規模モデル)には当然ながらあなたの家庭の情報や働いている会社の内部情報は含まれていません。だからこそ、関心がない人もいるのではないでしょうか?
近いうちに個人や各企業固有情報、つまり独自ドメインの固有知を埋め込みや追加学習したLLMを使うのが当たり前になってくると感じています。
そしてGPT-4を代表としたマルチモーダルが進化して今までテキスト、パワーポイントの資料、PDF、画像、音楽、動画といった情報の意味を全部理解してくれるソフトはなかったわけですが、つまるところこれらの意味や文脈を理解して対話できるようになります。

すると今までの企業内にあった経営や戦略に関わる資料から、日々行われるミーティング内容、意思決定の思考・基準、マネージャーやメンバーのスキルがどんどん固有知として使えるようになります。
これは、とんでもなく大きな武器になることは間違いないでしょう。
生成AIだけではなく"合成AI”
B2B用途における生成AIアプリケーションの第1波と第2波
第1波は、情報の発散に焦点を当てており、
指示に基づいて新しいコンテンツを作成する生成AIが注目を浴びています。
第2波では、情報の収束が重要になり、
利用可能な情報を合成してコンテンツを減らすことが期待されます。
この第2波は、合成AI(SynthAI)と呼ばれます。
(a16zの記事参照:🔗For B2B Generative AI Apps, Is Less More? )
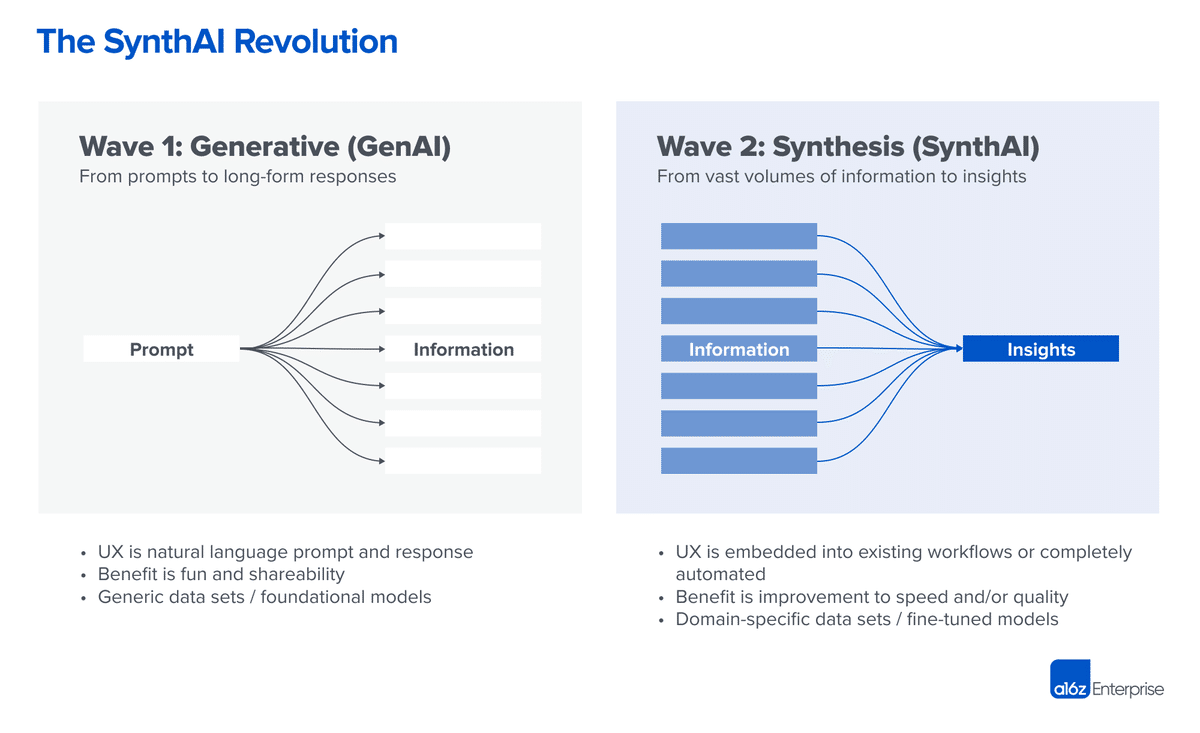
第1波は、消費者向け(B2C)と
企業向け(B2B)アプリケーションの
違いを考慮することが大切でしょう。
B2Cアプリケーションでは、
娯楽・楽しみや共有が目的であり、
品質や正確さ必ずしも重要とは限りません。
しかし、B2Bアプリケーションでは、
時間と品質のコスト・ベネフィット評価が重要です。
第1波のアプリケーションでは、
品質が重要な職場環境での使用には
限定的な成功しかないでしょう。

SynthAIの真の価値とは
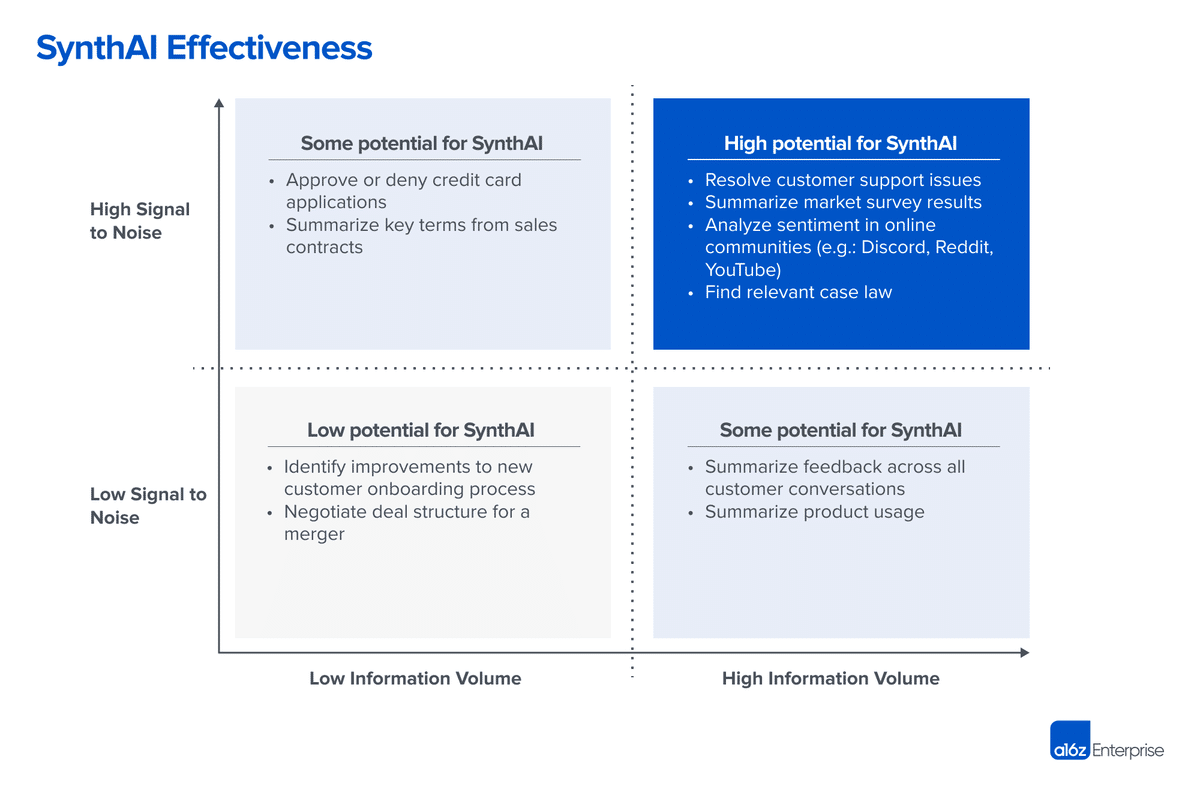
知識労働において、意思決定には大きな価値があります。
従業員は不完全な情報に基づいて意思決定を行い、
生成されたコンテンツの量ではなく、
その意思決定を実行または説明するために
必要なコンテンツの質を重視します。
SynthAIの真の価値は、
人間がより良い意思決定を
より速く行うのを助けることにあります。
B2Bソリューション間の競争は、
AIの能力を"見せびらかす"ことではなく、
これらの能力が企業のワークフローを確立または
再定義する方法にどのように役立つかに
焦点を当てる必要があるでしょう。
世界の変革-connecting dots-
2023年3月24日、OpenAIがプラグインプラットフォームをリリースしました。
これは、彼らが大規模言語モデルと既存のシステム・サービスをつなげ、プラットフォームを形成したことを意味しています。
ChatGPTが進化
— しょーてぃー / UX Designer & Prompt Designer (@shoty_k2) March 23, 2023
⚡️公式プラグイン登場!⚡️
最新情報と連携するので、たとえばチャット上で旅行予約やお買い物まで....新しい体験が生まれる..
スレに事例動画あり↓
<徐々に導入予定>
Slack 、Expedia、FiscalNote、Instacart、KAYAK、Klarna、Milo、OpenTable、Shopify、Speak、Wolfram、Zapier https://t.co/Al7wnrKDHJ pic.twitter.com/FCdJ64wsYd
まずは、ビジネスレイヤーの構造変化を考えてみましょう。
ビジネスレイヤーの変革
ChatGPTが登場以降も、私たちは個々のサービスやアプリケーションを開いて利用していました。そして多くのサービスや個人開発において、GPTモデルが使えるAPIを利用して、ユーザーにサービスを提供していました。

しかし、プラグインプラットフォームが登場したことで、大規模言語モデルと個々のサービスが合流し、ChatGPTはリアルタイム情報を取得し、ナレッジベースを参照して弱点を補完しつつ、さらに各サービスの機能が使えるようになりました。
ただし、各サービスの機能が使えるだけではなく、GPTとサービスが自然言語のコミュニケーションで結びつくことで、ユーザーの期待を上回るパフォーマンスを発揮します。
これは、既存の「サービス」や「アプリケーション」という概念を超えたものです。これによって、既存のSaaSやスタートアップが大きな打撃をうけるでしょう。

上の図を見れば分かる通り、極端な話ユーザーが何かを体験する際の入り口・出口はOpenAIが提供するサービスで完結することになります。
そう私たちはAIにシミュレートされたインターネットに変わる新しいゲームに囲い込まれたわけです。
AI時代にこのエコシステム内で生存競争ゲームが始まったと言えます。
(なお、GoogleはGPTの中核技術のTransformerの特許を持っているし、MSはOpenAIの49%の株式を保持している。くぅー怖い。)

そして、あらゆる事業が自社の
リソースだけではなく他のサービスの持つ機能やその要素と
組み合わせてどんなユーザー価値提供できるのか
考えないと生き残れない、
高度なサービスデザインスキルが
必要になってくる可能性を示唆しています。
ただ、プラグインの検索性能の悪さやユースケースを考慮されていないモノが多いゆえ概念としては崇高だったが、広くは受け入れらないかもしれない。
(11/7更新)
DevDayの蓋を明けてみると、先程の図のService Application LayerとChatGPTやPlugin Layerの上位としてAgentが示唆されて、今後重要性が更に高まっていくことが自明となった。
つまり、Agentを一度通じて多くのタスクを創造、遂行できるようになってくるというわけだ。
また、この話は近々更新する。
次に、私たちの生活変容について考えましょう。
生活レイヤーの変革
人間がシステムに合わせる時代が終わりを告げようとしています。
私たちは、これまで機械の言語やあらゆる制約下でのインターフェースを使用して、システムに合わせる必要がある不自然な体験をしてきました。
しかし、今後はシステムが人間に合わせることができるようになります。
つまり、人間が自然な言葉でシステムに指示を出すことができ、システムがそれを理解して自動的に処理を行うことができるようになるのです。
つまり、人間がシステムに合わせて使い方を学ぶ必要がなくなり、システムが人間に合わせて進化することができるようになるということです。
また、私たちがプロバイダーから受ける体験は、一般的なものから個別ユーザーの状態、ニーズや要望に合わせてパーソナライズされることが必至です。
これにより、よりインタラクティブかつリアルタイムに形を変えていくことが予想されます。
欲しいソフトやアプリが今その場で出来上がる世界線へ突入してる笑
— しょーてぃー / UX Designer & Prompt Designer (@shoty_k2) March 25, 2023
-やりたいことを声で伝える
-@Replit app が自動で実装する
-その場で使える💡
ということで、アプリを探すよりもその場で作ったほうが早いってケースが出てくるわけだpic.twitter.com/RcaTJ64NQ3 https://t.co/us9cXYXY43
ただし、全てのタスクを自動化するわけではないと思っています。自動処理の中でも、ユーザーに”選択・決定”をどのように行わせるかの設計は重要です。
なぜならば、人間は自分自身が選択・決定した結果に基づいて行動することで達成感や満足感を得ることができ、それはエンゲージメントに大きく関わるからです。(詳しくは、Self Determination Theoryを参照してください)
もう少しほりさげると…AIに身をまかせつつも「あたかも自己選択・決定感を感じるような設計」が発明されていくのではないかと思っています。
マルチモーダル but モードレス

まだ直近2-3年は既存デバイスが主人公である一方で、新しいマルチモーダルに対応したモードレスな体験を提供するデバイスが必要になるでしょう。
「モーダルなのにモードレス?」と疑問に思うかもしれません。
そもそも「モード」とは、特定の目的や状況に合わせて、デバイスやシステムの振る舞いを変更するための状態を指します。
狭義の例ではウェブページを見ているときに出てくる関係ないポップアップモーダルもモードを遮っていますし、より広義な例ではなにかするためには物理的なスマートフォンをポケットから取り出し、電話アプリ起動して….とやっているわけです。
先ほども話したように私たちは、システムに合わせて生活をしているのです。
「マルチモーダルに対応したデバイスがモードレスである」とは、複数の入力方法(タッチ、音声、ジェスチャーなど)に対応し、ユーザーが特定の“モード”に制限されることなく、自由にデバイスを操作できることを意味します。
つまり、どのような入力方法でも自然な操作で利用できるわけです。
たとえば、2020年12月に出願された「手や目の前の自動車のエンジンやテーブルなどに情報をプロジェクションするUI」特許は、手によるジェスチャー操作も含まれており、このような技術が今後のデバイスに採用される可能性があります。

この情報をもとにMichaelさんが制作したイメージ動画がこちら。

Here’s a rough mock-up of how I think @Humane’s upcoming AI powered device could help you check in to an Airbnb.
— Michael Mofina (@MichaelMofina) February 25, 2023
Receive relevant instructions, and a personalized welcome message projected on your hand or surfaces in front of you. pic.twitter.com/57peMdXNEL
スタンフォード大学生が現在開発中の
インターネットおよびAIとつながったウェアラブルデバイス
RealityGPT: The world’s first wearable that gives you ✨perfect memory✨
— Joseph Semrai (@josephsemrai) June 2, 2023
🧠 Never forget event details
🤖 Use AI agents in the real world
🌎 Get information from the Internet in real time
🗣️ Speak any language
Be the funniest & smartest person in every room: pic.twitter.com/k5jwoqNyLS
加えてジェスチャーだけではなく私たちがいつも話す言葉で、様々なことができると考えるとワクワクしますね。
未来の話だと思う人もいるかもしれませんが、AIが推論生成するモノと人の関わり方は日々進化していることは間違い無いでしょう。
SensecapeではGPTの出力が空間およびナレッジノードを組みわせた直感的な構造化・可視化が行われている。
(ナレッジノード:知識やアイデアが有機的につながっている状態)
💡GPTの応答が3Dで構造化されたら....
— しょーてぃー / Experience Designer & Prompt Designer (@shoty_k2) April 16, 2023
だから!!
こういうのもっとください!!
グラフィック・ダイアログ!
🔗https://t.co/dLHkzbWcWG#Sensecape pic.twitter.com/SHhBrxOjOf https://t.co/bxAQ48ol0G
creativity.ucsd.edu/ai が発表
チャットや音声コミュニケーション以外の創造的をサポートする形で模索が続いています。
AIは「Pre-emptive」に

近い将来、Pre-emptive AIが生活に溶け込んでいくことが予想されます。Pre-emptiveとは、ある問題やニーズが発生する前にそれを防ぐための行動をすることを指します。
私たちのウェブ上のデータや生活のセンシングしたデータから、高度な「推論」をしてニーズや課題が顕在化する前に察知し、適切な行動をとるPre-emptive AIが、私たちの生活をサポートすることになるでしょう。
この、Pre-emptive AIに影で支えられた生活はどうなるのでしょうか。
Appleが先手を打った"Brain-Machine Interface"
Appleが「Vision Pro」を発表し、世界に衝撃が走りました。
発表したときに思わずVRゴーグルと言ってしまいましたが、
VR、ARゴーグルでは形容詞がしがいでしょう。
Appleの新しいVRゴーグルのCM
— しょーてぃー / Experience Designer & Prompt Designer (@shoty_k2) June 5, 2023
音声操作もあるのか。pic.twitter.com/VJOuPjM6gB https://t.co/PvdMtEC5yE
またこれまでの
"Web/App UI",
"Voice UI(音声入力操作)" ,
"Natural UI(身体入力操作など)"
のみではなく
"Spacial UI",
"Brain-Machine Interface"
といえます。。
直近、1〜2週間で大きな変化が起きている。
— しょーてぃー / Experience Designer & Prompt Designer (@shoty_k2) June 6, 2023
◆"Generative AI"
→ +α "Synthetic AI"
◆"Web/App UI", "Voice UI" , "Natural UI"
→ +α "Spacial UI", "Brain-Machine Interface"
それはどういうことなのか?
このVision Proの機能をリストアップする
AR(拡張現実)とVR(仮想現実)の統合
ユーザーの心身のデータを利用したメンタルステートの検出
アイトラッキング、脳の電気活動、心拍数、筋肉活動、血流密度、血圧、皮膚伝導率などのデータを使用
瞳孔の動きを分析しユーザーがクリックする予測
ユーザーの反応を測定するための視覚や音響の高速提示
状況に応じて最適化されたバーチャル環境の変更
学習、作業、リラックスを促進するためにバックグラウンドで視覚や音響を変更

つまり、眼球や脳波の情報から我々のニーズや
行動を予期して空間世界を最適化していくのである。
それらを体現するインターフェースつまり
"Spacial UI", "Brain-Machine Interface"
であると言える。
おわりに

日々おおくのAI関連のニュースが飛び交い、何をすればいいのか分からなく不安になるかもしれません。一つ一つの新しいツールに振り回されすぎず
・AIの本質的な力において、新しい大きな流れが発生したのか
・それは私たちの生活レベルの行動変容に関わるのか
の2つの視点を持ちつつ、産業革命に匹敵する変革が起こっていることは間違いないので、この大きな波を少しでも楽しく乗りこなすためにまずはAIにふれて試行錯誤してみるのがおすすめです。
最近私はビジネスやユーザー体験の設計において、
AIにどのように自然言語で語りかければその目標が達成できるのか、どのような「問い」をたててAIに投げかければ期待以上のモノをうみだせるのか、
人とAIとのインタラクションをどのようにデザインするか……
と時間があれば”Prompt Design for Experience Design”を試行錯誤しています。
※Prompt:AIに指示する言葉
AIと対話する方法についてさらに興味がある方は、こちらも参考までに👇
数年前の自分の思考の枠組みでは捉えられないことが起きているので、「分からないものは怖い」は当たり前ですし、
AIが自分にできることをどんどん代替していくので…正直なところ毎日、自己否定の連続です。
それでもAIがつまらない作業を代替して楽しいことが残り、そして余暇が増えると思って前向きにやってます笑
おしまい。
★noteやTwitterで、「対話型AIで生活をビジネスを創造的にする具体的なコンテンツ」や「エクスペリエンスデザイン」について発信中しています。
このnoteが役に立ったらぜひTwitterでシェア、またはサポートいただけると嬉しいです!
👇一緒になにかやってみたいぞ!と思ったかも、DMにてお気軽にお声がけください。
Twitter: @shoty_k2 / Profile Bento
いいなと思ったら応援しよう!
