
複雑形状・巨大建築プロジェクトの訂正可能なデータの運用方法

はじめに
先日ニュースを見ていたら、大林組、利益計算が甘く、想定を上回る費用がかかることになり、業績予想が715億円から350億円へと下方修正された
とありました。資材価格の影響は大きいとは思いますが、決算記者会見で小野寺康雄副社長は「戦略的な応札価格を提示したが、詳細設計の見直しが必要になった。資材価格の上昇リスクも現在の水準までになるとは思っていなかった」と言っています。これは総価一式請負契約の負の部分が出たと思いますが、詳細設計の見直しでどれほど費用が膨らんだのか?設計施工一貫だったのか?応札価格の根拠は何だったのか?気になるところがいくつかあります。これらの問題は以前から言っていた見積もりの正当性に通じるものであり、あらゆるリスクを大林組のような大手ゼネコンがを飲み込むような立場にあります。しかし、これもいつまでリスクを取れるのかという問題もあり、今後建築プロジェクトのリスクヘッジをどうしていくのかを考える必要があります。個人的には今後、公共建築や巨大建築で大きな問題として取り上げられる日が来るのではないかと思っています。
訂正可能なデータ
前回の記事では建築プロジェクトは変更箇所や経緯の管理が重要であり、それに耐えうる建築データの作成・管理手法が必要という話をしました。建築データは基本設計の段階から徐々に整合性が失われていき、入札する頃には意匠、構造、設備がバラバラな状態になるため、建築として実現させるにはそれらを調整する必要があります。調整業務が発生するのは建築プロジェクトとしては当たり前ですが、問題はそもそも何をどれだけ修正していいのか把握することが出来ないような、先の見えないブラックボックス状態になることです。しかし、契約上工期は絶対に守らなければならないため、問題が明確になっていなくても予測を立てて工期までに合わせようとします。この予測が外れると冒頭のニュースのようなことが起こるのだと思います。
私は建築プロジェクトを通して、どうしたら訂正可能でありながらも、正しいデータを積み上げていけるフローを作れるのかと頭を悩ませています。
まだ模索段階ではりますが、我々が実際に複雑形状・巨大建築プロジェクトで行っている運用方法を一部紹介したいと思います。
忘れてよい
私が建築プロジェクトで強く感じるのが、人間の意思伝達や記憶おいて限界があることです。ある一定の規模以上になるとデータ量が格段に増えるため、担当者でさえ把握できる範囲が限られ、そこから誰がどの部分を検討しているのか、検討するための情報に何が必要なのかなど、情報やかたちの依存関係が属人化しわからなくなっていきます。そのためまずは状況を整理するためにチェックリストを作ることにし、チェックすべき項目を考察しました。この項目を決めるのが意外と難しく、たくさん項目を入れたら入れたで作業上煩わしかったり、そもそもその情報はここで見る必要が無かったりというのがあります。あとはこれを確認出来たら当然これも確認できるというような情報の優先順位にも配慮する必要があります。
今ではフォーマット化して運用しているのでとても役に立っています。
特に重要な項目を下記に記しておきます。
・質疑・提案・指示の内容
・画像または動画など視覚的にわかるもの
・先方への確認状況
・確認日
・解決状況
・解決日
・回答内容
・データへの反映・対応の完了
・質疑・提案・指示かどうか

他にもいくつか項目がありますが、基本的な項目でもグラフにすると
直感的にどんな問題が未解決かわかるようになります。

これを定期的にプロジェクトメンバーと共有することで、今後の見通しも含めてプロジェクトの状態を確認するこができ、回答し忘れていたものや保留になっていたものを再確認することが出来ます。これだけでも不要な作業やミスなどを防ぐことができ、なぜこのデータになっているのかも辿れるようになります。チェックリストを活用すると他にもいろいろと確認することが出来、どのステークホルダーに課題が集中しているかや建築的にどこの納まりがネックかが把握できるようになります。
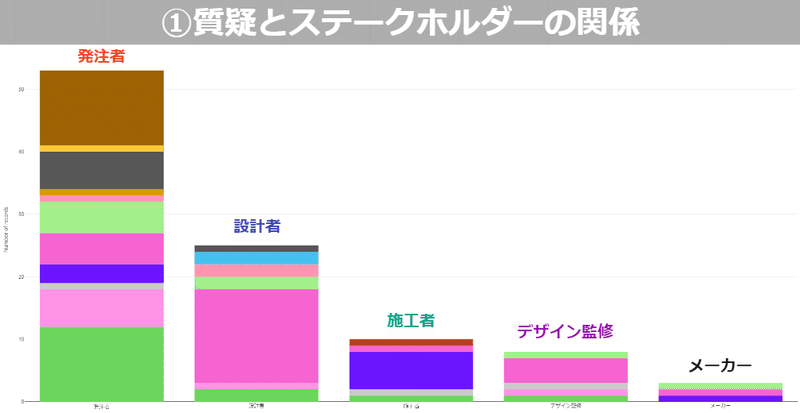

おそらくこのようなことはどの会社もやられているとは思いますが、発注者側がこれらを管理し、建築プロジェクトに関わるステークホルダーに共有することはまだ出来ていません。これがプロジェクト全体で共有されるだけでもプロジェクトそのものの品質が向上すると思います。
訂正してよい
建築プロジェクトはとにかくかたちも情報も変更しながら進むのが当たり前であり、それら建築データを育てていく感覚に近いです。そしてただのかたちから少しずつ建築に成っていきます。その育て方の一般的な手法としては、人海戦術が好まれており基本的に手動で行われているため、建築データの品質管理が難しくなります。よくあるパターンとして以下のような流れがあります。

これは手動で修正を行っていくことで、かたちの依存関係が見えずらく、修正したことでさらに課題が発生したり、適切な改善方法でなかったりすることで修正内容が膨れ上がり人海戦術に頼るというパターンです。
だいたいは海外の人件費の安いところで一気にやってもらっていいよねという判断のもと、指示通りに作ってもらっては、またフィードバックして修正するという往復になり、ほとんどの場合データ作成の仕様やルールなどが共有されないか、したとしてもそれぞれがちょっとずつ違うなどの場合がほとんどです。最終的には人件費もかかり、データの品質も落ちて、工数も増えているので、建築データの品質を考えた場合良い選択なのかはわかりません。
私は出来るだけこの建築データをつくることを自動化しながらもかつ訂正可能であること、要は検討に自由度を持たせるにはどうしたらいいかと考えていました。結論から言いうと検討処理そのものをアセンブリ化するということですが、これはどういうことかと言うと、基本的に建築データというのはCAD内部でいえば点・線・面と情報の集合で成り立っています。そこで、目的の建築物を構成するまでの処理を点・線・面と情報のレベルで細かく区切っていきます。概念的な図で見るとパーセプトロンに似てるがします。

例えばですが、Aには図面データがあり、それを参照して柱が作られます。そして柱が作られたら、今度は柱に付随する部品や建具などを作成し、さらにそこで作成されたデータは参照されていきます。
ここで大事なのは建築の整合性を担保するにはその依存関係を考えなければいけないということです。すごい当たり前のことを言っているようですが、実際これがデータ管理というレベルで全くできていないという現状があります。もう少し実務に則して細かく見ていきたいと思います。

①がどんな処理をしているかの内容を記述しておきます
②参照すべきデータになります。これは何を元にしてデータを作成したかを明示しておく必要があるからです。
③参照したデータの集合データです。(データ内に参照したデータは明示される)
④集合データを元に①で記述した内容を処理します。
⑤検品用のプログラムをはさみます。これは後程ミスしてよいに繋がります
⑥作成されたデータであり、このデータが②の参照データへとなったりします。
これらの集合を建築プロジェクトで活用していくと以下のような図が出来上がります。
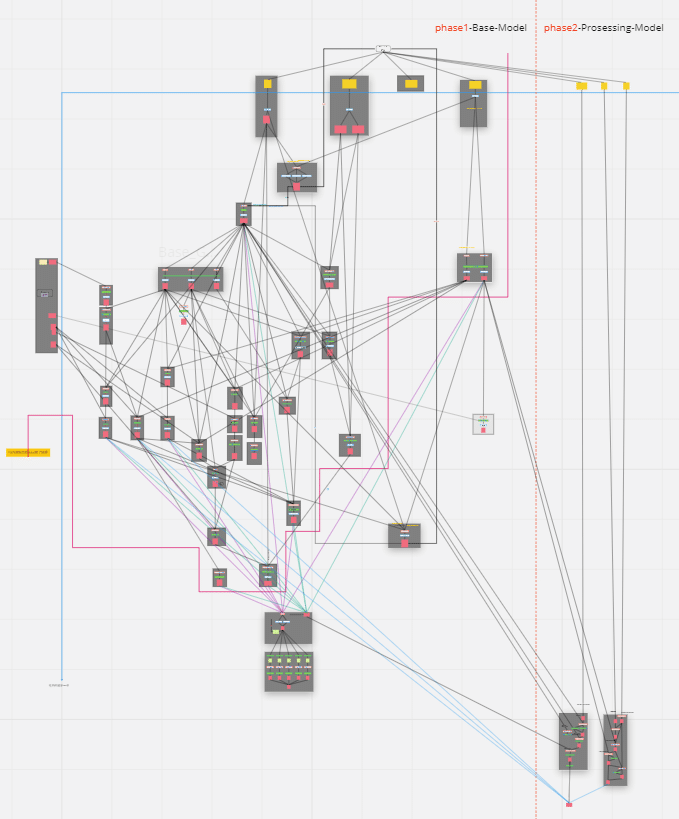
これが前述した処理そのものをアセンブリ化すると言っていたもので、出来上がるこの図が建築データの構成を表したものになります。データの流れそのものが建築物そのものを表している状態をプロジェクトの中で確立すれば、その変更にどれだけ時間がかかるか、ここを変更するとどこに影響がでるか?などを把握しながら検討することが出来、工程も読みやすくなります。また一度作成したフローに従って即座に変更対応することが出来、建築プロジェクトの流動性に建築データが耐えられるようになりました。

※プログラムと建築物との影響関係はマトリックスで見ると便利です。
プログラムAを変更すると柱・金物に影響が出ることがわかる。
ミスしてよい
図面が間違っていることもあるし、図面を見ながら間違えたデータを作成してしまうこともあります。そしてこのエラーなりミスなりを早めに発見する検品作業が建築データを作る上で最難関になります。現状は実質的には現場での対応に依存してしまっている状態なので、実施設計図面そのものを検品はしているものの、現場で問題発覚→対応という方が近いと思います。我々がやらなければならないのは現場で発覚する前に発見し、致命的な問題に発展しないようにすることですが、現状建築データの検品は目視で行われています。最近では干渉チェックなどの検品は行われるようになってきましたが、建築データの検品をする上で考えなければいけないのはモデル同士の干渉だけではなく、それ以外の内容をどう検品するかです。そのため、指標を明確にして情報に当たる必要があります。例えばですが以下は建築データの特定の情報をグラフ化して視覚化したものです。

これは因果関係がある二つの値をグラフ化した際に、外れ値を見つけることで、そのIDが振られたモデルに問題があるかどうかを発見しやすいよう図化しています。こうすることで、本来ではある決められたルールや条件によって作成されるはずの建築データから外れた値を検出できるようになります。ただしこれは例外対処をしている箇所もあるのであくまで、おかしいな?と見つけるための触り程度のものですが、それでも目視で探していくよりもずっと精度と早さが上がります。そしてこのデータから実際の建築データの方に移り目視で確認するという手法をとっています。

建築データはそのすべてを数値化して検品するということはできません。そのために検品のタイミングと方法を考える必要がり、建築データの品質を確保することはとても大変なことです。しかし、私としては建築のデータの品質=プロジェクトの品質=建築物の品質という風に連続したものだと思っているので、今後も模索していきたいです。
建築の検討方法
データの品質を高く保てるとその検討方法でも幅が広がり、建築的な説明がしやすくなります。建築の検討では意匠設計者またはデザイン監修者が作成したデータをそのまま使用し、忠実に再現しようとすることがよくあります。例えば三次曲面形状の屋根や外壁などを円弧近似化することなく、そのまま作るなどです。意匠性を確保しながらも、製造的なコストのバランスも確認しながら検討することが出来るはずなのですが、なぜかそのままの形状を正として特殊な二次部材を大量に作っています。これらが成型材の場合、型枠の数が増えるので当然コストが増えます。以下の図は以前行ったプロジェクトでそのような型数を検討をしたものです。建築形状は見せることが出来ませんが、事例として紹介します。
まずは近似前では540個の型が必要であり、それによって建築の繊細な意匠性を表しています。

次に近似後では166個の型で意匠性を崩さず同じようにな形状を実現することが出来ました。意匠設計者の人に確認してもその違いは判らず、場合によっては前よりもきれいな統一感のある建築形状になります。

単純計算でも一つの型当たり30万円かかったとして、
近似前:540×30万=1億6千200万円
近似後:166×30万=4千980万円
差額:約1億1千220万
となります。あくまでざっくりした計算なので実際にここまでの差額を出せるのかはわかりません。ただ、この差額を生みどう建築をグレードアップするか、または再投資するのかなどまで建築を考える幅が広がるのではないかと思います。これからはただコスト調整と言ってもグレードを下げてのコストダウンなのか、高度な検討により実現しているVE(Value Engineering)なのかで明確に建築の品質が分かれてくると思います。また今後それらの違いを説明できるだけでも、公共建築などの必要予算への対応ができるのではないかと思います。
--------------------------------------------------------------------------------------
・お仕事に関するお問い合わせはこちらからお願いします。
・-建築Tシャツ-をお買い求めの方はこちらからご購入いただけます。
・Rhinoceros7をご購入される方はこちらかたご購入いただけます。
--------------------------------------------------------------------------------------