
Pythonを用いて株価予測を行ってみよう!その2(学習の様子をグラフ化してみよう)

こんにちは。蝉の店です。いつも私の拙い記事を読んでいただきありがとうございます!
前回はニューラルネットワークを株価予測に応用できないか確かめるべくプログラムを組んで動かしてみました。
読んでいただけると分かる通り、他人から見たら完全に何をしているか分からなかったですね。ただの数字の羅列と図のない説明のみでしたので。私はブログ書くのも初心者です。うまくなりたひ。
そこで今回は株価予測の簡単な仕組みと学習してどのくらいの正答率およびコスト関数の減少に至っているかを説明していきます。前回に比べて視覚的な結果が出ていますので、少しは見やすくなったかと思います。
1.本記事の目的
本記事では、「株価を予測してくれるような学習器を作成して、その予測に合わせて株を売買できれば不労所得なるものが獲得できるのではないか?」という非常に不純な動機のもとに、ニューラルネットワークについて勉強しながらゆっくりと学習器を作っていくブログです。
あとは、「なんとなく流行に乗ってみた」という感じも否めません。しかしこの株価予測を通じてニューラルネットワークを知れたらいいなぁという目的もあります。
またブログ形式にすることによって、私自身の勉強にもなりますし、現在こんなことを社会人の傍らやってますよぉという発信の場にもしています。ブログ書いておくと将来、何かまた発信したいときに役立つかなぁとも考えています。
またもし株価予測がうまくいけば、アプリ化などを行う予定です。アプリの勉強もしなくてはならないので何年先になるかわかりませんが、のんびりいきましょう。
2.ニューラルネットワークとは?
ニューラルネットワークについて簡単に説明・・・は既にほかのサイトで散々してくれているので、よくわからない人はこちらの記事などを見てください。
これ読んでもよくわかんない!という人は
・入力層・・・データを入れるところ
・出力層・・・データが出てくるところ
・教師あり学習・・・最初に答えつきの学習を行っていること
・学習データ・・・答えつきの学習の時に使うデータたち
・テストデータ・・・学習できているかを確かめるためのデータたち
この5つだけ抑えてくれると嬉しいです。
3.株価予測をどのように行うのか?
この機械学習の趣旨としては
3銘柄分の過去10日間の終値の株価から、予測したい銘柄の、次の日の株価がどうなるか予測する。具体的には前日比2%以上上昇、前日比2%未満上昇、前日比2%未満下降、前日比2%以下下降のどれかを当てる!
以下に用いたデータ、コスト関数などを記述しています。学習器を組み立てるにあたって参考にしたのはここです。
https://nnadl-ja.github.io/nnadl_site_ja/index.html
学習データ・・・3銘柄の2006年から2013年までの終値の株価
3銘柄について、ひとつは予測したい銘柄、残りふたつは主要取引先の銘柄
テストデータ・・・3銘柄の2014年から2019年9月ごろまでの終値の株価
入力層・・・3銘柄それぞれの10日分の終値、つまり30個分
中間層・・・なんとなく40個
出力層・・・4個(前日比2%以上上昇、前日比2%未満上昇、前日比2%未満下降、前日比2%以下下降)
コスト関数はクロスエントロピーコスト関数を用いています。
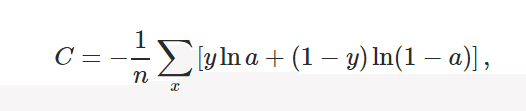
コスト関数は値が下がれば下がるほど、学習が進んでいるという指標になります。なので学習の様子を見る時の指標となっています。
また重みやバイアスについては、逆伝搬法を用いて修正を行っています。
4.結果と考察
ここでは実際に計算した結果を載せていきます。
以下のグラフは横軸に世代数、縦軸にコスト関数の値を求めたものです。青色のグラフは学習データを、オレンジ色のグラフはテストデータを表しています。また両グラフとも1世代目のコスト関数の値で規格化を行っています。
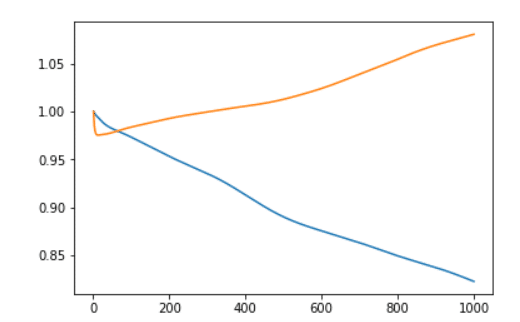
色々と残念な結果であることがよくわかると思います。肝心のテストデータのコスト関数はぐんぐん上がってしまっています。また学習データは順調に下がってはいますが、1000世代学習させても元の80%程のコスト関数の値にしかなりませんでした。
予測という意味では、テストデータのコスト関数が減少しなくてはなりませんので、残念ながらまだ学習器は完成していないということです・・・。次に正答率を見てみましょう。
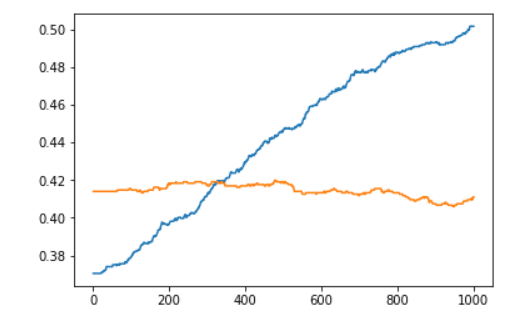
え?4択問題だから正答率が25%をはるかに超えているのってすごくない?と思ってくれた方、その言葉はとても嬉しいのですが、残念ながら前回も紹介しましたように裏があるんです・・・。
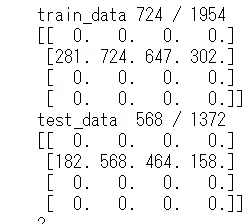
これは第1世代の学習データとテストデータの正答率とconfusion matrixを表しています。
confusion matrixの見方について説明します。行成分が学習器の予測を表しており、列成分が正解データです。つまり対角成分が予測と正解が一致していてそれ以外が不正解です。順番はそれぞれ上、左から①前日比2%以上上昇、②前日比2%未満上昇、③前日比2%未満下降、④前日比2%以上下降です。
画像でわかる通り、全ての学習データおよびテストデータinputに対して全て②前日比2%未満上昇と予想していることがわかっています。どうやらコスト関数の谷がここにあるようで、何回試してもここの谷にまずは収束するようです。
このことから、「任意の入力層に対して、必ず出力層が2になるようなバイアスと重みが選択されている」ということがわかりました。過学習の傾向の一つでしょうか。対策を練らなくてはなりません。
5.まとめ、次回予告
このようにニューラルネットワークに触れてたった数ヶ月程度では不労所得を獲得することができませんでした。過学習め・・・。
先ほどの問題について、L2ノルム正規化という方法を使えば解放される可能性があることがわかりました。L2ノルム正規化は、コスト関数に以下のような変化を加えます。
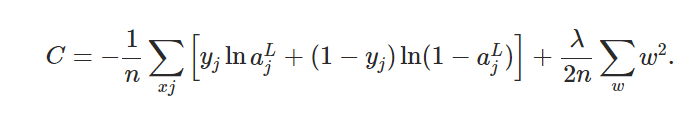
第2項に着目すると、重みのノルム項が加わっていることがわかります。この項が意味するところは「重みの値が大きいことを嫌う」です。先ほどの問題、重みやバイアスを調べてみると局所的に値が大きくなっていることが確認できました。この項を加えることで、飛びぬけて大きい値の重みを避けることができそうです。
次回はこの辺りを考慮にいれて計算してみます。以上です。ありがとうございました!
この記事が気に入ったらサポートをしてみませんか?