
「AI Challenge day」に参加してきました!
こんにちは、ソフトクリエイトのKです。
2024年4月18日-4月19日にかけて神戸で行われた「AI Challenge day」というハッカソンに株式会社ソフトクリエイトと株式会社ecbeingの2社合同チームで参加してきました。
事前情報は限られていて、「RAG アーキテクチャの実装を特定題材にコンテスト形式で競い、学びあう」ということくらい。。
そのため、具体的な内容や課題は、参加するまで謎に包まれていました。
準備と初日の夜
事前準備としては、「RAGの回答精度」が競われるポイントと見込み、
RAG精度向上のためのアプローチを複数用意して挑みました。
前日に神戸に到着したので、夜にはチームメンバーで集まり、
美味しくてお勧めという中華店に行き、餃子と煮干しラーメンを食べました。味噌だれをつけて食べる餃子、めちゃめちゃ美味しかったです。。

また、翌日のお題について想像を巡らせ、マルチモーダルRAGが必要となる場合は、全員未経験のため一筋縄ではいかないだろうという話をしていました。
ハッカソンDay1:お題の発表・構成検討
そして迎えたハッカソン当日、
お題のテーマは「世界遺産トラベルアシスタント」でした。
具体的には、事前に開催者さんが準備した
「世界遺産に関するデータセット」+「実際には存在しない仮想遺産のデータセット」
をもとに、RAGアーキテクチャーの精度を競うという内容でした。
さらに、予想(フラグ)通り、お題にはマルチモーダル要素がしっかり盛り込まれていました。
お題発表後は、早々とメンバー全員で会議室に移動し、アーキテクチャーやフロー、検索用インデックスの構成について検討を開始しました。
具体的には、今思い出すと下記のような内容を話し合っていました。
・文章入力・画像入力時のフロー
・アーキテクチャーの検討
・検索用インデックスの構成
・検索用インデックス作成フロー
・文章入力・画像入力時の検索方法
・画像のベクトル化(Vectorize Image API)
・画像の説明文の作成(GPT-4 Turbo with Vision)
・インデックス化時の文章と画像の位置情報紐づけ
・PDFからの文章と画像の抽出
・WordやPowerPointの文章抽出
・フロント・API周りの話
ここまでで既にDay1の夕方ぐらいになっていたかと思います。
Day2のお昼には成果物を提出する必要があるため、
Day1中にはある程度完成していないと厳しいというのもあり、
会議室が18時まで利用可能との話でしたが、20時まで延長可能とのことで、お言葉に甘えて延長させていただきました。
ハッカソンDay1:製造
ここから2名ずつ分担して作業を行うこととなり、
私は、データ周り(文章・画像インデックスの作成)を担当しました。
課題の各種データセットから、文章と画像で分割し、データ加工や必要データの生成を実施し、文章インデックスと画像インデックスを作成します。
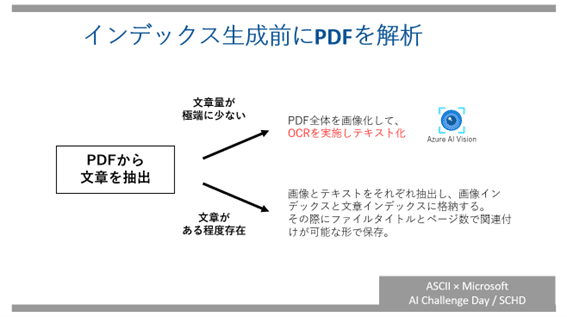
PDFのような文章と画像が両方存在するデータについては、それぞれ抽出を行い、文章は文章インデックス、画像は画像インデックスに分けて格納します。
また、文章と画像の紐づけを行うために、出現するページ番号も一緒に取得します。

最終的なインデックスを作成するために必要な、
以下の処理をPythonでゴリゴリ作成していきます。
・PDFからの文章とそのページ数抽出
・PDFからの画像とそのページ数抽出
・文章のベクトル化(text-embedding-3-large)
・画像のベクトル化(Vectorize Image API)
・画像の説明文生成(GPT-4 Turbo with Vision)
・文章インデックス用のデータフレーム作成
・画像インデックス用のデータフレーム作成
対応していく中で、PDFの文章と画像の抽出を行う際に、
以下の課題が出てきました。
・スキャンデータのPDFが存在し、文章・画像が抽出できない
・大量の画像で構成されたPDFが存在し、文章が抽出できない
(データセットも一筋縄ではいかないように色々と工夫されているように感じる…)
そのため、以下のようにPDFの処理を分岐させ、文章量が少ないPDFについては、OCR(Computer Vision API)を利用することにしました。
また、Vectorize Image API や Computer Vision API は初めて利用するため、ドキュメントを確認しデータセットを元に検証しながら進めていきます。
細かい仕様を全員で確認し詰めつつ、引き続きデータ加工処理の作成をしていくと、あっという間に20時となってしまいました。
ただ、会議室はさらに22時まで延長可能とのこと。
再度お言葉に甘えて、22時まで延長させていただきました。
22時時点、GPT-4 Turbo with Visionでの説明文生成や、OCR処理部分、検索用インデックス作成等、まだまだ必要な作業は残っていました。
一旦、オフィスでの作業は終了で各自ホテルの自室で作業を対応することとし、コンビニで夜ご飯を買って帰宅。
その後、たまたま隣の部屋だった同期のM君と一緒に集まり、
OCR処理部分や文章インデックスの作成・画像インデックスに必要なデータ整備の部分までひたすら対応しました。
そして後はGGPT-4 Turbo with Visionでの画像の説明文生成し、
画像インデックスを作成すれば完了というところまで来ました。
画像は数百枚あり、説明文生成が完了するまで時間がかかるというのもあり、予期しないエラーで中断されないことを祈りながら、実行中に睡眠をとることにしました。
ハッカソンDay2
朝起きると数百枚分の画像説明文生成が完了しており(一安心...)、
画像インデックスを自室で早速作成してから、オフィスに朝8時頃に向かいました。
メンバーで集まり、アプリケーションに組み込み、評価スクリプトを流すと前日より5点ほど高い「18.525点」。

スコアが高いのか低いのか分からなかったですが、マルチモーダルのRAGが出来たということで個人的にはかなり嬉しかったです。
感想
お題に対する構成を考え、新たなサービスに触れながら開発していくのは楽しかったですし、多くを学ぶことができました。
また、他社様の発表からは、それぞれ異なる視点があり、そこからも学びがありました。
事前に準備していた「精度向上のアプローチ」が一つも試せなかったことは悔しかったですが、多くの学びと発見からRAGの可能性改めて感じました。
そしてなにより、実際にマルチモーダルRAGが機能するものが完成した時は、達成感と喜びがとても大きかったです。
濃密な2日間「AI Challenge day」に参加できてよかったです。
全ての関係者の皆様、ありがとうございました!
参考
当日の発表は YouTube Live で配信されました。
アーカイブも残ってますので是非ご覧ください。
■放送情報
放送日:2024年4月19日(金)
番組 :生成 AI はどこまで乗りこなせるのか!?
ASCII×マイクロソフト生成 AI コンテスト中継
*ソフトクリエイトのプレゼン開始時間:1:11:45‐ (YouTubeアーカイブ)
https://youtu.be/AzhOi14CLTA
▼ASCII記事
https://ascii.jp/elem/000/004/194/4194225/?_fsi=QXjj7fhZ&_fsi=w7ZTNBrM&_fsi=IDSKphbY
この記事が気に入ったらサポートをしてみませんか?