LLMファインチューニングのためのNLPと深層学習入門 #14 Transformer

今回は、CVMLエキスパートガイドより『Transformer: アテンションが主要部品の系列変換モデル [深層学習]』を勉強していきます。
1. Transformerとは
Transformerとは、アテンションを主要部品として用いた、深層学習むけの系列変換モデルです。
当初、Transformerは従来の系列変換モデルの定番だった「seq2seq with attention」の改善策として、機械翻訳むけに提案されました。
マルチヘッドアテンションを採用したことによる、Transformerの計算効率性と高性能性・スケール性が特徴で、seq2seq with attentionの後継の系列変換モデルとして登場しました。
Transformerは、これまでのNLPモデルと同様に、入力系列を単語・サブワードの単位にトークナイズして辞書化し、トークンEmbeddingの学習も、埋め込み層を用いて系列変換部分と同時に学習します。
これにより、トークン化さえ行えば、文章のみならず、画像や音声などのデータも入力できます。
現在では、TransformerはVision-Language, TTS, 音声認識など、各種の系列変換タスクで使用され、更にそのスケール性の高さやマルチモーダル処理化の容易さなどから、画像や言語、音の各パターン認識と生成分野全般で定番のネットワーク構造として使用されています。
2. Transformerの構造
Transformerは、マルチヘッドアテンションを主部品に用いた「Encoderブロック」「Decoderブロック」をそれぞれN回スタックした構造の、深いEncoder-Decoderネットワークです。
また、Transformerでは、入力トークンへの系列内での位置情報を付与するために、位置符号化を用いることを提案しました。(「#7 位置符号化」参照)
(CVMLエキスパートガイドより)
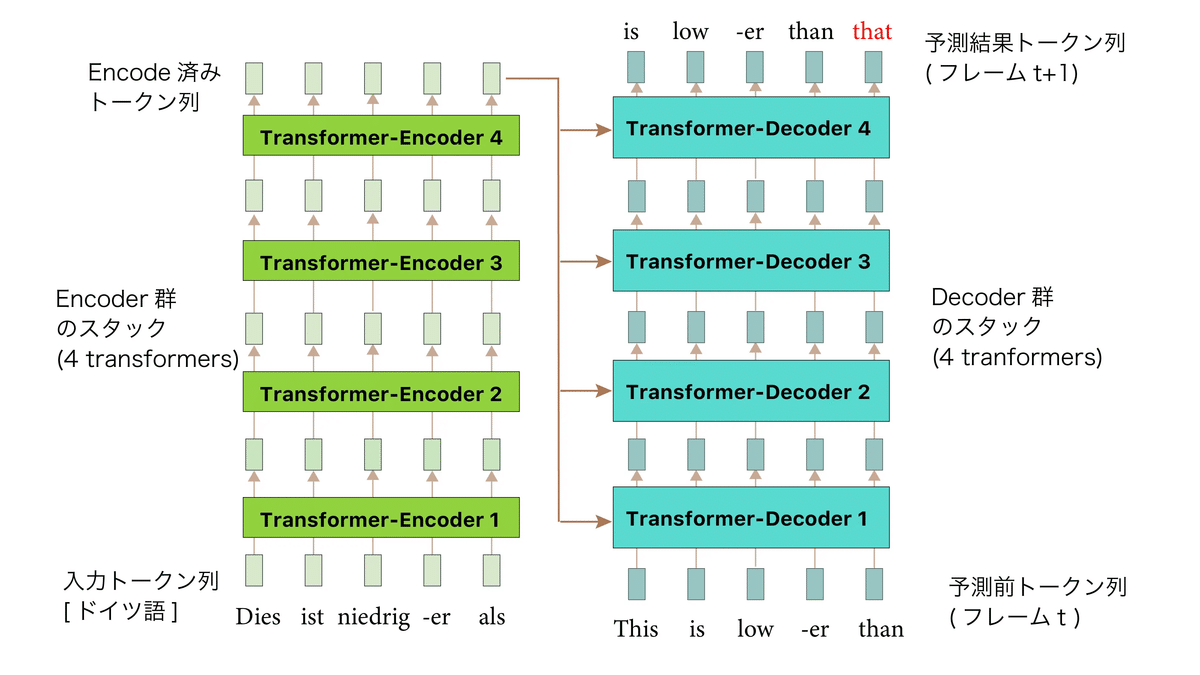
図1は、機械翻訳目的の、一番最初に提案されたTransformerにおける処理手順とネットワーク構造の概略図です。
Transformerでは、自己アテンション(#6 マルチヘッドアテンションを参照)を内部に用いたDecoder N個とEncoder M個を繰り返し使用するような処理になっています。
これらEncoderっとDecoderを用いて、トークン系列全体の各トークン(ベクトル)表現を、一気にN回→M回変換します。
Decoder側では、トークンからトークンへの変換だけでなく、以下の2つの処理も行います。
ソース系列のEncoding結果をDecoderの相互アテンションで使用する
次のトークンの予測も行う
従来の系列変換モデルとの違い
Transformerの、従来の系列変換モデルとの大きな違いは以下の2点です。
自己アテンションの導入
seq2seq with attentionは、「RNN+相互(系列間)アテンションによる、フレームごとの再帰変換」処理だったのに対し、TransformerはEncoder、DecoderそれぞれでEncoder/DecoderブロックをN回繰り返します。
マルチヘッドアテンションの導入
マルチヘッドアテンションが主役となって、トークン系列変換を行うのがTransformerの設計の一番の特徴です。
これにより、Transformerは高速かつスケールする大規模系列変換ネットワークを学習することができます。
3. 歴史的背景
登場前
■ 系列変換の状況
Transformerが登場した時代(2015~2017年ごろ)は、Sutskever氏らのseq2seqの登場で、系列対系列変換問題への敷居が一気に下がり、その応用研究が流行し始めた時期です。
アテンション機構を用いた発展版seq2seq with attentionがその後すぐ登場し、NLP・機械翻訳や、音声認識・TTS・Vision-Languageなどにおいて広く活用され、流行していました。
Transformerはそれを代替する「より高性能コンパクトで、スケールする系列対系列変換ネットワーク」として、最初は機械翻訳向けに登場しました。
その後、多くの深層学習を利用するタスクで、Transformerのネットワーク構造を活用する状況に繋がります。
■ サブワード分割の使用
Transformer登場直前のseq2seq with attentionの終盤期のころ、Google NMTなどでは、WordPieceなどのトークナイザを使用して「サブワード分割結果をトークン単位に使用する方向性」も登場していました。
それまでのNLPやニューラル言語モデルは「ワード単位」でモデリングするのが一般的でしたが、サブワード単位や文字単位、バイト単位などのように、単語をさらに分解した単位をトークンとして用いるように変化していきます。
"Attention is all you need"でもこの流れに乗り、入力・出力トークンにサブワードレベルまで分割したトークンを用います。
これにより、語彙外のトークンを含んだ文章でも、訓練データに存在するサブワードの組み合わせとして扱うことで、対応力が期待できます。
『語彙外(Out-of-Vocabulary, OOV)』
モデルの訓練データに含まれなかった未知の単語やトークンのこと。NLPモデルは一般に訓練データに含まれる語彙に基づいて学習を行い、この語彙に含まれる単語を「語彙内」の単語という。「語彙外」の単語とは、その範囲に含まれないような、人名や地名、専門用語などの訓練データには存在しない、新たに出現した単語や特定の名詞のことを指す。
Transformerの登場
機械翻訳向けの最初の提案では、トークン群の語彙を入力系列・出力系列の母集合として想定します。
そして、任意の長さのA言語の1文(入力トークン系列)を、任意の長さのB言語の1文(出力トークン系列)に変換する様子を、ほぼアテンションのみの構成で実現しています。
系列全体をグローバルなマルチヘッドアテンションで一気に変換・予測する仕組みを提案したことで、Transformerは効率性と高精度の両方を実現しました。
ただ、アテンションの多用により巨大なモデルとなってしまったので、かなりのメモリ容量が必要です。
とはいうもののseq2seq with attentionよりも大規模にスケールできるので、パターン認識界隈の全域にブレイクスルーを起こすモデルとなりました。
登場後
■ BERTとGPT
Transformerの登場後、Huggingface社のTransformersフレームワークが急速に発展・普及したことから、NLPでTransformer系モデルの利用が短期間で爆発的に広まりました。
そして、GPT-2, GPT-3, BERTなどの一般化言語モデル全体の教師なし事前学習で、Transformer-Encoder/Decoderが主要部品として使用されたことをきっかけに、Transformerの使用範囲がさらに拡大し、その後の事前学習言語モデル界隈が急速に発展する要因になりました。
例えばNLP系の、XLNet, GPT-3, T5など、多くの事前学習モデルや系列変換モデルに、Transformerが主要部品として使われています。
また、系列対系列変換に限らず、近年の巨大なディープニューラルネットワークは、Transformerやマルチヘッドアテンションを基盤構造として採用している、派生型だらけの状況になっています。
BERTやGPTだけでなく、コンピュータビジョンにおけるVision Transformer(ViT)やDETRにおいて、Transformerが基本設計として応用されたことで、Transformerが基盤構造の1つとなりつつあることが分かります。
■ クロスモーダル界隈
NLP以外でも、クロスモーダルな問題に応用が効くので、Transformerが人気となります。
今まで、クロスモーダルな問題にはseq2seq with attentionを用いていたのが、Transformerへ移行したということです。
例えば、画像キャプション生成や音声認識・TTSなどでクロスモーダルなTransformerが用いられています。
また、クロスモーダル間におけるアテンションも、元はseq2seq with attention式のシングルヘッドアテンションが使われていましたが、Transformer式のマルチヘッドアテンションをアレンジして使用するように変化していきました。
■ コンピュータビジョンでの流行
2020年以降、コンピュータビジョンでも物体検出や意味的分割など、多くのタスクの研究で、Transformerが使用される状況となりました。
Transformerを使用したVision Transformer(ViT)が物体認識バックボーンとして登場し、CNNの物体認識精度を上回り始めています。
(その後CNNが逆転しているとのことです。)
各タスクの研究でViTがバックボーンやEncoderとして使用されるようになり、これが研究コミュニティにおいて普及し始めました。
また、物体検出でもCNNとTransformerを組み合わせたDETR系モデルが台頭しています。
4. Transformerの部品構成
Transformerのおさらい
Transformerは「マルチヘッドアテンション」を主部品として採用したことにより、系列内・系列外ともにすべてのトークン同士の関係を、毎回のブロックで一括処理できるモデルとなりました。
■ トークンの埋め込み表現
Transformerの入力は、これまでの系列対系列変換と同様に「語彙化されたトークン」から構成された、トークンベクトルN個からなる系列です。
ソース言語とターゲット言語の各入力トークンは、毎回one-hotベクトルから埋め込み層で埋め込みを行い、$${d_{model}}$$次元ベクトル表現として使用します。
■ トークン位置情報
位置符号化の記事で学んだように、マルチヘッドアテンションでは、トークンのフレーム位置情報に関与しないため、word2vecやseq2seqなどの言語モデルとは異なり、位置情報を別途埋め込む必要があります。
そこで、Transformerでは、位置符号化で得られた(文章系列全体に対する)トークン位置情報を、トークン埋め込み層で得たトークン表現ベクトルに加算することで、位置情報も含んだトークン表現ベクトルを得ます。
Transformerの特徴
■ アテンションを軸にした構成
Transformerの特徴を以下に示します。
スタック化
Transformer-Encoder/Decoderを、それぞれ複数個直列にスタックしています。(=Google NMTなどの路線を踏襲)各トークンの表現
「トークンの意味的情報と符号化したトークン位置」を加算したものを使用します。マルチヘッドアテンション
系列全体のN個のトークン表現を、アテンションを考慮した表現に一括変換します。Encoder-Decoder間:マルチヘッド相互アテンション
Encoder内/Decoder内:マルチヘッド自己アテンション
Transformer-Decoderブロック内:未来部分を隠すマスク化自己アテンション(後述)
全体構成図

(CVMLエキスパートガイドより)
図2はTransformerのネットワーク構造の概要図です。
見やすさを優先して、残差接続とレイヤー正規化は省略してあります。
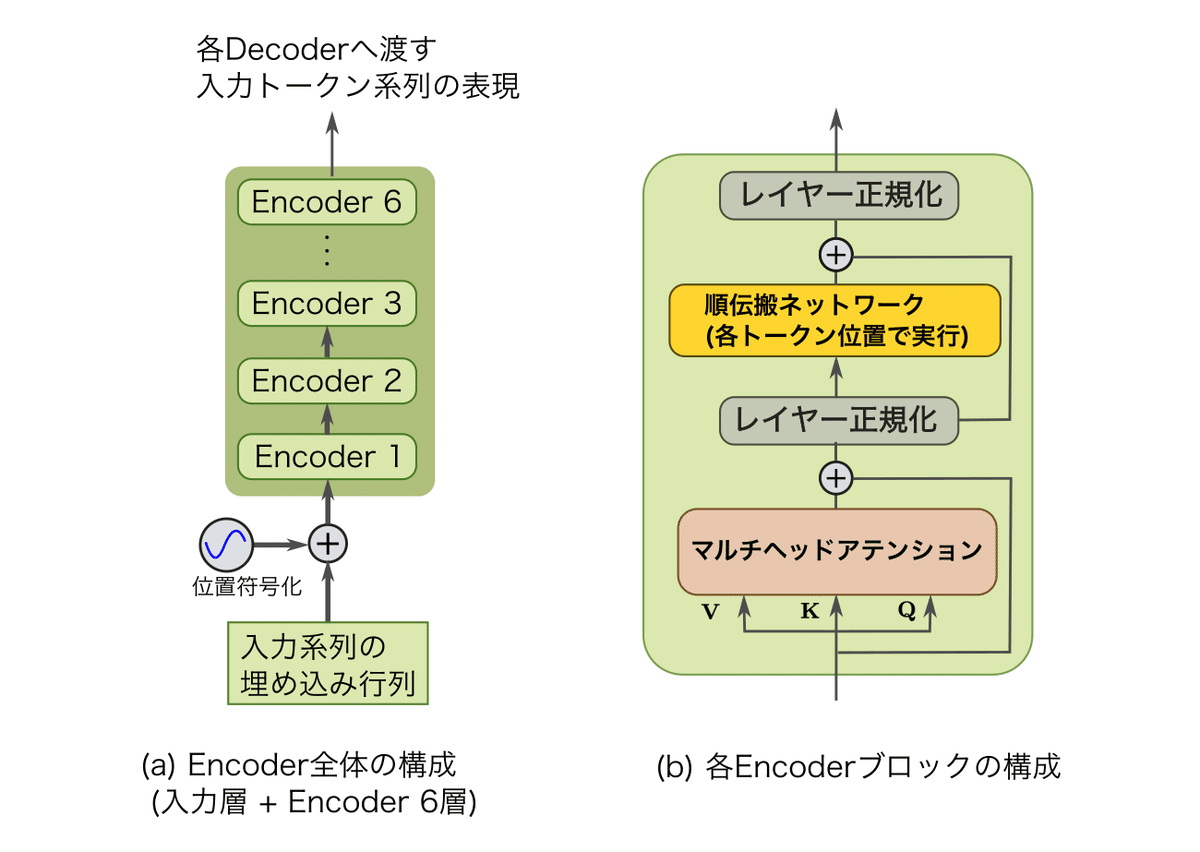
各EncoderおよびDecoderブロックは、以下の2つのサブブロックから構成されます。
マルチヘッドアテンション(薄茶色)
トークン位置ごとに個別実行する「FFN」(黄色)
Transformerは、6ブロックのEncoder(緑色)と、6ブロックのDecoder(青色)から構成されています。
系列全体を自己回帰で6回Encode/Decodeし、出力トークン系列を予測します。
Transformerは、これまでのseq2seq同様に、入力系列全体をEncodeしたのち、出力系列のone-hot表現トークンを、1フレームずつ予測していくモデルです。
つまり、Nトークン入力したら、予測文字を足して1文字だけずれたNトークンが予測されます。
また、各マルチヘッドアテンションでは、$${[シーケンス長n\times埋め込み次元d_{model}]}$$サイズの埋め込み表現を並べて作成した行列$${Q, K, V}$$を入力として受け付けます。
残差接続とレイヤー正規化
TransformerにおけるEncoder/Decoderブロック内部での残差接続と、レイヤー正規化の扱い方について説明するために、以下に図3と図4を示します。
(CVMLエキスパートガイドより)
(CVMLエキスパートガイドより)
マルチヘッドアテンションとFFNは、毎回残差接続により残差ブロック化されており、Transformer全体がResNet化されています。
そのため、深いTransformerネットワークをうまく学習しやすくなっています。
さらに、マルチヘッドアテンションとFFNの直後にレイヤー正規化が挿入されています。
自己/相互アテンションの扱い方
(CVMLエキスパートガイドより)
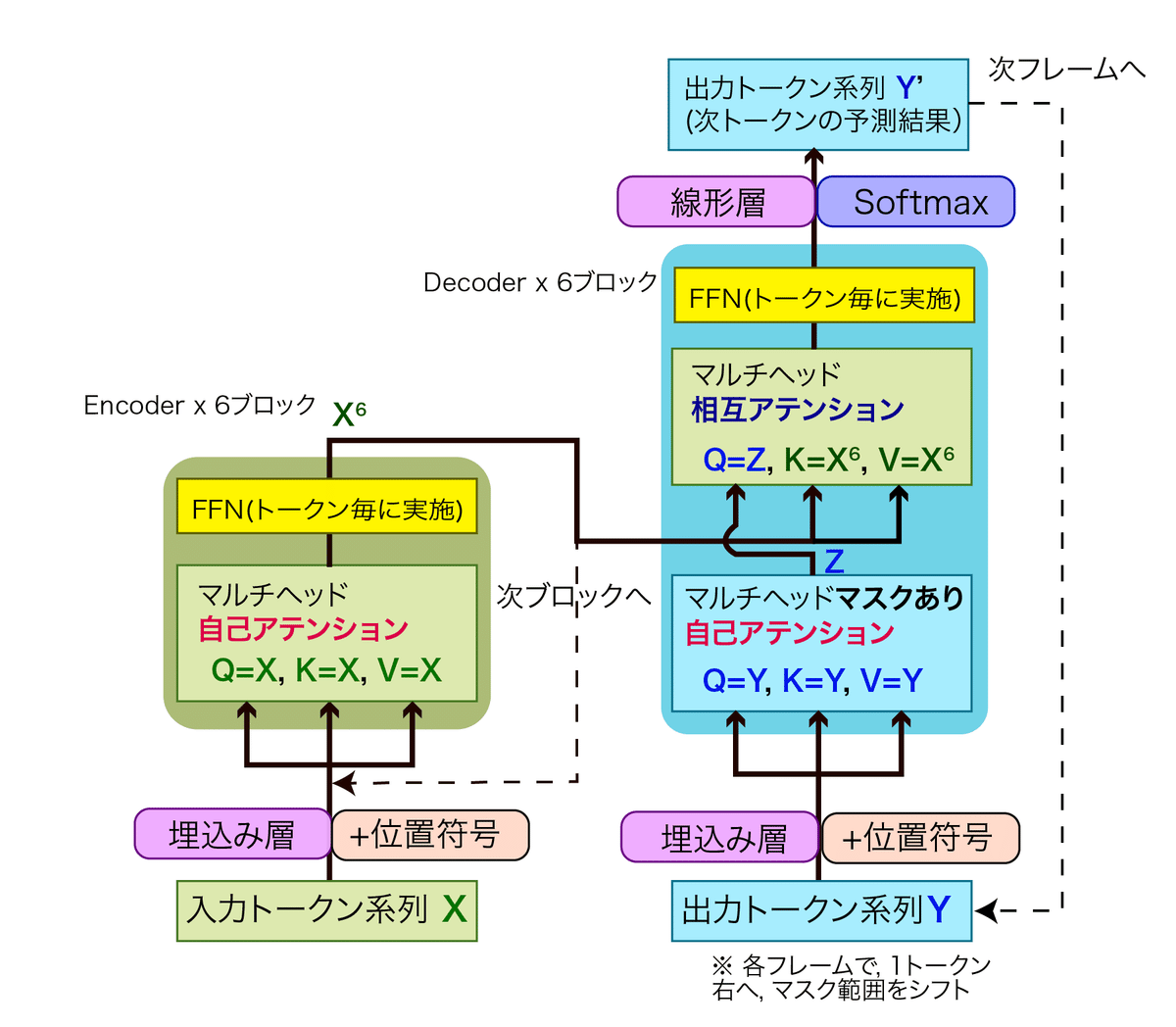
Transformerの主要ブロックである、マルチヘッドアテンションには、系列内自己アテンションまたは系列間相互アテンションの2つの役割を担当します。
Encoder内とDecoder内:
入力系列全体の全トークン間の関係を、自己アテンションで階層的に学習します。
この機能が最も重要です。Encoder - Decoder間:
相互アテンションで橋渡しを行います
seq2seq with attentionの系列間アテンションと同じ役割を担います。
(過去記事:「#5 seq2seq with attention」)
位置符号化
※参考:「#7 位置符号化」

(CVMLエキスパートガイドより)
系列中の$${pos}$$番目のトークン表現ベクトルをTransformer-Encoder/Decoderに入力する前に、以下の位置符号化の関数で計算した$${d_{model}}$$次元の位置情報ベクトルを加算します。
ここで、入力系列はサブワードも含むトークン列へ分割され、$${d_{model}}$$次元ベクトルの表現へ埋め込み変換済みであるとします。
(デフォルトでは$${d_{model} = 512}$$です。)
$$
PE(pos, 2d) = \sin\left(\frac{pos}{10000^{2d/d_{model}}}\right) \quad
$$
$$
PE(pos, 2d + 1) = \cos\left(\frac{pos}{10000^{2d/d_{model}}}\right)
$$
ここで、$${pos}$$は系列における、そのトークンの絶対的位置番号を意味し、$${d}$$は$${d_{model}}$$次元トークン埋め込みベクトルの、各次元の値のインデックスです。
この位置埋め込み層は学習せずに決め打ちの関数でトークン位置表現を符号化する点が、Transformerの論文で提案された重要なポイントです。
以前の系列対系列変換では、位置埋め込み層もseq2seq with attention内に配置して、一緒に学習する戦略が主流でした。
マルチヘッドアテンション
※参考:「#6 マルチヘッドアテンション」

(CVMLエキスパートガイドより)
マルチヘッドアテンションは、QKV方式のスケール化ドット積アテンションを構成部品として、アテンションの並列計算を行います。
複雑なスコア関数の計算・学習は行わず、単純にベクトル同士の内積で算出したスカラー類似度を$${\frac{1}{\sqrt{d_k}}}$$でスケールした値を、softmax関数により正規化したのちに、各トークンベクトル間のアテンション係数として使用します。
入力のトークン表現ベクトルであるQKVは、それぞれに対応する3つの全結合層である$${\bm{Q}, \bm{K}, \bm{V}}$$をもちいた変換によって調整します。
これにより、ベクトル同士の類似度計算前のベクトル表現、および合成語の最終出力のコンテキストベクトル表現が$${\bm{Q}, \bm{K}, \bm{V}}$$で最初に調整されることになります。
ただし、アテンションによる関係づけのみだと、線形の変換しか学習できないため、表現力に欠けます。
そこで、Transformerでは、マルチヘッドアテンションによる「アテンションヘッドの8並列化(8つの視点で重みを変える)→結果を1つに合成」や、非線形層トークン変換の使用により、全体の表現力を高める仕組みになっています。
マスク化アテンション:未来予測化
(CVMLエキスパートガイドより)
この項は、私たちがTransformerのモデルをトレーニングする際に指定する、"attention_mask"をイメージしながら読むと分かりやすいです。
■ マスク化アテンションとは
マスク化アテンションとは、Transformer-Decoderの1stブロックむけに提案された仕組みで、未来の予測単語をコンテキストベクトルに含まないようにするのが目的です。
マルチヘッドアテンションにおいて、直前のA個のトークンのみをバイナリーマスクで取り出し、未来のフレームはマスク化して使用しないというものです。
具体的には、ドット積後の行列中で、現在のフレーム以降にあたる個所の値を全て$${-\inf}$$に変更することでマスク化を行います。
このような処理により、マスク化されたトークン箇所は、softmaxの値が0になるので、未来の予測単語はコンテキストベクトルに加味されないようになります。
Transformer-Decoderでマルチヘッドアテンションのマスク化を行うと、学習中の各フレーム$${i}$$において、以下の両方のブロックが予測前の未来のトークンの情報を全て無視できます。
Decoder 入力側から2つ目のマルチヘッド(相互)アテンション
Decoder入力側から1つ目のマルチヘッド(自己)アテンション
このマスク化アテンションにより、テスト時と同じ条件である、「現在のフレームまでのトークンしか情報を知らないアテンション」をTransformer-Decoder側で学習できるようになりました。
■ 学習時のマスク化アテンション
Transformer-Decoderも、RNNと同じように系列予測モデル化したいと考えます。
しかし、TransformerのDecoderは、予測時にすべてのトークンを一度に処理するため、予測前の「未来のトークン」もすべて使用した行列計算をしてしまい、未知のはずの未来のトークンの表現もコンテキストベクトルに加味してしまいます。
このため、モデルが未来のトークンを見ることができないようにするマスク化アテンションが用いられます。
例えば、"I have a pen."という文章を正解として、"I have a"の次の単語を予測したいとします。
マスク化アテンションを用いない場合のアテンションの計算対象とモデルへの入力は以下のようになります。
アテンションの計算
"I have a pen."(入力全体)モデルへの入力
"I have a"
この場合、アテンションの計算が入力全体に対して行われているので、現在の単語の予測が容易になりすぎてしまい、実際の使用時、つまり未来の単語が道である場合に性能が低下する可能性があります。
これでは未来予測モデルにできません。
そこで、マスク化アテンションを用いることにより、アテンションの計算を制御することができます。
マスク化アテンションを用いた場合のアテンションの計算対象とモデルへの入力は以下のようになります。
アテンションの計算
"I have a"(マスクされてない範囲)モデルへの入力
"I have a"
この仕組みによって、モデルは真に現在の情報をもとに予測し、適切な損失を計算することができるようになります。
■ 推論時のマスク化アテンション
マスク化アテンションは、推論時にも重要となる場合があります。
具体的には、バッチ処理(複数のシーケンスを一度に処理すること)を行う場合や、特定のトークンを意図的に無視したい場合です。
それぞれのシーケンスが異なる長さを持つバッチ処理を行う場合、一番長いシーケンスに合わせて他のシーケンスはパディングトークンで埋められます。
このとき、マスク化アテンションを使用してパディングトークンを無視することで、シーケンスの長さの違いが結果に影響を与える(=パディングトークンがアテンションに影響する)のを防ぐことができます。
トークン位置ごとに実行するFFN(順伝搬ネットワーク)
(CVMLエキスパートガイドより)
Transformerにおいて、順伝搬ネットワーク(Feed Forward Neural Network, FFN)は、主にそれぞれのトークンの潜在表現をさらに高度な表現に変換する役割を果たしています。
FFNはマルチヘッドアテンションを実施した後のSubcoderの後半に設置され、各トークンに対して個別に適用されます。
まず、FFNは「全結合層 $${W_1}$$ - ReLU - 全結合層 $${W_2}$$」の3層で構成されます。
第1層(全結合層 $${W_1}$$)
入力として512次元のベクトル(入力トークン)を受け取り、それを2048次元の中間層に変換します。
これにより、元の情報がより高次元の空間に投影されます。活性化関数(ReLU)
中間層を活性化する役割を果たします。
ReLUは非線形性を導入し、ネットワークが複雑な関数を学習できるようにします。第2層(全結合層$${W_2}$$)
2048次元の中間層を元の512次元に戻します。
これにより、入力と同じ次元の出力が得られます。
このネットワークは、すべてのトークンに対して個別に適用されます。
つまり、入力としてN個のトークンがある場合、同一のFFNがN回適用されます。
これは重み共有が行えている設計で、モデルと計算の効率が良い設計だといえます。
また、初期のTransformerの論文ではReLUが活性化関数として使用されていましたが、BERTやGPTの頃にGELUが代わりに使われて以降、TransformerベースのネットワークではGELUの使用が一般的になりました。
ただし、GELUの代わりにSwishなどの新しいReLU型活性化関数を使用することも可能です。
5. Transformerの各モジュール
この項では、TransformerのEncoderモジュールとDecoderモジュールについての説明を行います。
基本的には前項までの内容を、EncoderとDecoderについて整理する形でもう一度振り返るような内容なので、内容の重複があります。
Transformer-Encoderモジュール
(CVMLエキスパートガイドより)
Transformer-Encoderモジュールは、入力層で入力系列の埋め込み表現に位置符号を足した表現を受け取ります。
その入力に対し、Encoderブロックを6回繰り返して、系列表現のEncodingを実行します。
各Transformer-Encoderブロックは、以下の2つのブロックを順に実行します。
マルチヘッド自己アテンション
系列全体の全トークンを一括変換します。FFN
各トークン位置で個別に実行し、トークン表現を非線形変換します。
また、これら2つのTransformer-Encoderのサブ層には、それぞれ残差接続とレイヤー正規化を挿入して、Transformer全体の深さに対する対策が取られています。
そして、マルチヘッドアテンションでは、入力系列の自己アテンションを計算します。
6ブロックあるので、「6層の階層的な自己アテンション」を通じて学習し、また毎回のマルチヘッドアテンションの直後にFFNによって異なるトークン埋め込みベクトルへ非線形変換します。
Transformer-Decoderモジュール
(CVMLエキスパートガイドより)
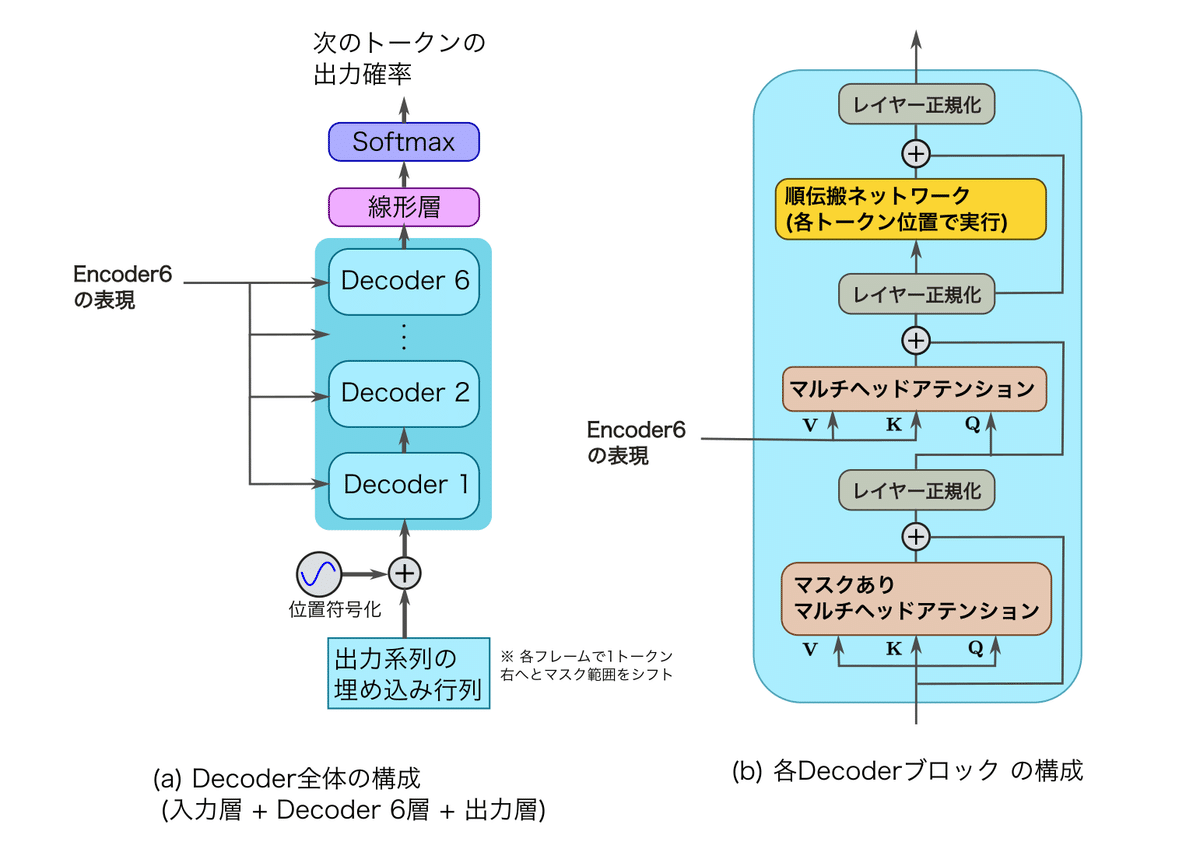
Transformerの各Decoderブロックは以下の3つのブロックから構成されます。
順伝搬ネットワーク
マルチヘッド相互アテンション
Encoder 6の表現を$${\bm{K}, \bm{V}}$$に、前のDecoderブロックの表現を$${\bm{Q}}$$に使用します。マスクありマルチヘッド自己アテンション
入力系列のうち、現フレーム意向をマスクして無効にできるアテンションです。
Transformer-Decoderでも、これらの各ブロックの後に残差接続とレイヤー正規化を毎回挿入します。
6. Transformerの学習
トークン分割
■ seq2seq登場初期の系列モデリング
seq2seq登場後の初期は、単語単位で系列をモデリングしていました。
ところが、語彙数爆発により、メモリ許容量を超過する問題や、逆に語彙に含まれない未知語(Out of Vocabulary, OOV)への対応がうまくいかない問題がありました。
『語彙数爆発』
NLPにおける問題の一つで、単語の数が非常に多くなりすぎて、それらをすべて扱うことが計算上非現実的になる現象のこと。
自然言語では新しい単語が頻繁に作成され、また言語には独自の単語が存在する。そして、同じ単語の異なる形や複数形、過去形などの、単語自体のバリエーションも含めると、語彙の数は膨大になる。これらすべてをモデルの語彙として保持しようとすると、メモリ容量を大きく超える可能性があり、またモデルの学習も困難になる。
例えば、seq2seq with attentionでは、学習データの文から単語の登場回数を計算し、上位頻出単語5万語のみに語彙を限定する対応を行っていました。
■ サブワード単位のトークン化の提案
そこで、サブワード単位までのトークン化を行うと、サブワードも用いて系列表現及び系列変換を学習できるようになります。
つまり、「未知語」や「合成語」の予測・認識が強化されるという大きな利点が得られました。
このサブワード単位でのトークン化は、名詞や動詞に形態変化があるラテン語系の言語や、動詞の活用や名詞の自由な合成がある日本語などの言語モデリングに特に有効です。
これは、サブワード単位でのトークン化によって、単語の形態的な変化や複合語を構成する部分を独立した要素として捉えることが可能になり、それによって言語の構造をより精細に理解することができるからです。
Transformerが発表された当時(2017)は、元の文章をサブワード分割モデルを用いて、"like + ed"や"new + er"などのワード+サブワードのトークン単位への分割器をソース言語とターゲット言語から学習し、そのうえでサブワードを含むトークン単位で系列変換を行うアプローチが機械翻訳などのNLP問題において標準的になりつつありました。
サブワードありのトークン分割を行っていた当時の代表例としては、バイト対符号化(byte pair encoding)を用いて、サブワードありのトークン分割を行っていた機械翻訳や、単語ごとにトークン分割を行う、Word-Pieceを用いたGoogle NMTがあります。
Transformerの実験
Transformerモデルではサブワード単位での分割法を採用し、分割された「トークン辞書」を語彙として使用した実験が行われました。
具体的には、英語-ドイツ語の翻訳実験ではWMT2014データセットからBPEを用いて37,000語のトークンに分割し、それを語彙として使用しました。
そして、さらに大規模なWMT2014の英語-フランス語データセットでは、Word-Pieceトークナイザを使い、32,000語のトークン語彙に分割しています。
これらのデータセットで機械翻訳モデルを学習したところ、当時の最先端であったConvSeq2SeqやGoogle NMTと同等、もしくは少し上回るBLEU値の精度を、他手法と比べて控えめの計算コスト量で実現できることを示しました。
『BLEU値』
BLEU (Bilingual Evaluation Understudy) 値は、機械翻訳の出力結果の品質を評価するための指標。機械翻訳による出力と人間による翻訳の間で、n-gram(連続するn個の単語)の一致度を計算することによって算出される。
BLEUスコアは0から1までの範囲の値を取り、1に近いほど機械翻訳の出力が人間による翻訳と一致している、つまり品質が高いと評価される。
ただし、BLEUスコアは文法や意味などの翻訳の品質を直接的に評価するものではなく、参照翻訳との一致度を測定するものであり、必ずしも最良の翻訳が最高のBLEUスコアを得るとは限らない。したがって、翻訳の品質を評価する際には、BLEUスコアだけでなく他の指標や人間による評価も合わせて行うことが重要である。
正則化
Transformerは巨大モデルをスクラッチからの学習で学習します。
つまり、各マルチヘッドアテンション中の8つのQKVアテンションヘッド用の重み係数は、全てランダムな初期値です。
(トークン埋め込み層も共にスクラッチから学習)
『スクラッチからの学習』
大規模なDNNの学習において、重み初期化により決めたランダムな初期値から、SGDで直接学習を最後まで行うこと。
よって、巨大なモデルであるTransformerは、過学習への対策が非常に大事であり、正則化の使用が必須となります。
これまで何度も述べたように、時系列モデル向けのバッチ正規化であるレイヤー正規化がTransformer-Encoder/Decoderには向いています。
これにより、マルチヘッドアテンションとFFNの処理が終わるごとに、レイヤー正規化で毎回正則化することができます。
さらに、各ブロックの出力に対し、ドロップアウトを使用しています。
また、ラベル平滑化も使用されています。
7. Transformerの発展型
Transformer-XL
Transformer-XLは、Transformerの改良版として提案されたもので、TransformerとRNNを混合したモデルです。
この工夫により、Transformerよりも長いトークン間での依存関係を学習することができます。
Transformerからの改善点は以下の2点にまとめられます。
クラスタリングしたセグメント単位での再帰を追加
元のTransformerでは、シーケンス全体で一度にすべてのアテンションを計算しますが、Transformer-XLでは、シーケンスを小さな部分に分けた「セグメント」をクラスタリングし、各セグメントに対してアテンションを個別に計算します。
そして、これらのセグメント間の依存関係をRNNのように再帰的に学習することにより、全体的な依存関係を見失うことなく、長期的な依存関係を学習できるようになりました位置符号化から、query-key単語間の相対位置符号化に変更
元のTransformerでは各単語の絶対位置をエンコードしていましたが、Transformer-XLでは、特定の単語(query)が他の単語(key)にどれだけ近いかについての情報がエンコードされるようになりました。
これらの変更により、Transformer-XLは、元のTransformerよりも長期のトークン間の依存関係を表現できるようになり、短文の変換モデルしか学習しづらかったオリジナルのTransformerを、長文向けに改善できました。
おわりに
今回はTransformerについて学びました。
一番本命の項目だっただけに、ちゃんと内容を理解出来て嬉しいです。
Transformerの項目を読んで理解しようとしたのですが、過去3回敗北したので、今回は記事の内容を理解するのに必要な知識を全てリストアップし、学習を進めたうえで臨みました。
おかげで内容はこれまでに学んできたことの集大成といった感じで、「これちょっと前に学んだな」「あー、これ知ってる」みたいな感じをずっと覚えながら割とスラスラと読めたと思います。
今後は、モデルの学習方法や正則化について気になった項目を読み進めていこうと思います。
毎日2,3時間程度かけて記事を一本書くといったペースだったのですが、データセットの作成などの作業もしたいので、今後は2日に1本くらいに投稿頻度を下げるかもしれません。
次回は「重み初期化」「転移学習」のどちらかになると思います。
それでは。
進捗上げてます
「#AIアイネス」で私が作成しているLLMの進捗状況を更新しています。
ぜひ覗いてみて下さい。
参考
Transformer: アテンションが主要部品の系列変換モデル [深層学習], CVMLエキスパートガイド, 林 昌希, 2022
この記事が気に入ったらサポートをしてみませんか?