LLMファインチューニングのためのNLPと深層学習入門 #7 位置符号化

このシリーズを始めてちょうど1週間が経過しました。
今回は、CVMLエキスパートガイドの『位置符号化(Positional Encoding)[Transformerの部品』を勉強していきます。
1. 位置符号化とは
位置符号化(Positional Encoding, 位置エンコーディング)とは、各トークンが「系列中の何番目の位置にあるか」を一意に区別するための位置情報を、符号化関数を用いて高次元ベクトルへ変換することです。
この位置情報は、言語モデルが文章を理解するうえで非常に重要です。
なぜなら、たとえば「犬が猫を追いかける」と「猫が犬を追いかける」とでは文の意味がしばしば単語の順序に依存するからです。
この位置情報を符号化するために高次元ベクトルを用います。
「高次元」という用語は、情報を表現するために多くの特徴を持つベクトルを指します。
高次元ベクトルは、多くの情報を同時に保存でき、それぞれの次元は特定の特徴を表現することができます。
Transformerモデルでは、トークンの意味的情報(単語埋め込みベクトル)と位置符号化のベクトルを組み合わせることで、文章内での単語の位置と意味を同時に考慮します。
しかし、アテンション機構は位置情報を考慮しないので、各トークン表現に自身の位置情報の表現を加えるための仕組みが必要であり、それが位置符号化や位置埋め込み層です。
なお、従来のseq2seq with attentionによる系列対系列変換では、RNNの再帰などがトークンの位置情報を予測に組み込む機能を提供していたので、(アテンション部分以外は)位置情報の埋め込みが不要でした。
ちなみに、他の情報と組み合わせて使うために、各トークンがもつ意味的な情報と位置情報は、同じ次元数を持つように設計されています。
2. Transformerにおける位置符号化
位置符号化の中でも、Transformer向けに提案された「三角関数ベースの周期的関数による位置符号化」が広く使用されるようになったこともあり、「位置符号化」とは「Transformerで提案された、サイン関数型のトークン位置符号化」を実質的に指すことが多いです。
系列対系列変換においては、Transformer直前の最先端モデルであったConSeq2seqでは、学習可能な位置埋め込み層を使用していました。
しかし、Transformer原論文が提案した位置符号化を用いると、位置埋め込み層を学習しておらずとも、十分な系列変換精度を達成できるようになりました。
よってそれ以降、Transformer系モデルを中心に、位置埋め込み層の代わりにTransformer式の位置符号化が良く用いられるようになりました。
NLPに限らず、画像や音のアテンションにおいても、Transformer式のトークン位置符号化がよく用いられています。
3. 位置符号化に用いる関数
Transformerでは、系列長Lの入力系列に対して、各トークンの位置posを入力として、D次元ベクトルを作成する位置符号化が提案されました。
各トークンは、系列中のトークンの位置$${pos}$$をもとにした数学的な関数$${PE(pos, 2d), PE(pos, 2d + 1)}$$により位置符号化されます。
(1.1)式:
$$
PE(pos, 2d) = sin(\frac{pos}{10000^{2d/D}})
$$
$$
PE(pos, 2d + 1) = cos(\frac{pos}{10000^{2d/D}})
$$
ここで、パラメータは以下の3つです。
pos : 系列中のトークンの登場位置番号
D:トークン埋め込み後のベクトル次元数
(元論文の$${d_{model}}$$に相当)d: トークン埋め込み後のベクトルにおける各次元のインデックス
($${d = 1, 2, …, D}$$)
この関数はトークン埋め込み後のベクトルにおける、各次元のインデックス値$${d}$$で周期が変化するのがポイントです。
位置符号の値をposだけを用いた通常の三角関数による出力にしてしまうと、周期ごとに同じ値が出力されていまい、お互いに独立した位置符号値を与えることができません。
そこで、$${d}$$の値によって周期を変化させます。
$${d}$$の値が増えると、関数の周期も増えるので、各トークンの位置が他のすべての位置と区別できる独自の符号化が可能になります。
この仕組みによって、長い文章でも、トークン位置ごとに固有の符号を与えることができます。
そのため、各トークンの位置関係がうまく表現でき、Transformerが文の構造を解釈するのに役立ちます。
また、これらの位置符号化はトークンの元の埋め込みベクトルに加算され、その結果がTransformerの入力となります。
なお、この式は学習されるものではなく、定義されてからは変わりません。
また、分母の10000という数値はハイパーパラメータであり、ユーザが自由に設定することができます。
この数値は位置符号化関数の出力の周期、つまり波長を調節します。
この値が小さければ波長は短くなり、大きくなれば、波長は長くなります。

系列の前半部分では各トークンが異なる値を示しますが、系列の後半部分では、隣接するトークン位置間の符号化結果がほとんど同じ値を示すようになります。
したがって、この方法では長期のトークン位置関係は符号化できないという欠点があります。
しかしこの問題は後続のモデル改良、例えばTransformer-XLなどで改善案が提案されています。
また、符号化後ベクトルの各$${d}$$次元の値は、先ほどの周期的な関数によって決まるので、学習データで与えられた系列長$${L}$$以降の「学習データでは見えていない、先のトークン位置」での符号化位置も、Transformerが学習できるという利点があります。
これにより、Transformerでは学習データで与えた以上の系列長の文を翻訳してトークンを予測する際にも、学習した各トークン位置の情報が有効に使えます。
Transformer界隈では、"Attention is all you need"で(1.1)式が提案されて以降、この「(絶対)トークン位置符号化」を代替するよりよい手法が永らく現れておらず、標準的なTransformer構成の位置符号化にはずっと(1.1)式が用いられています。
4. Transformerでの使用
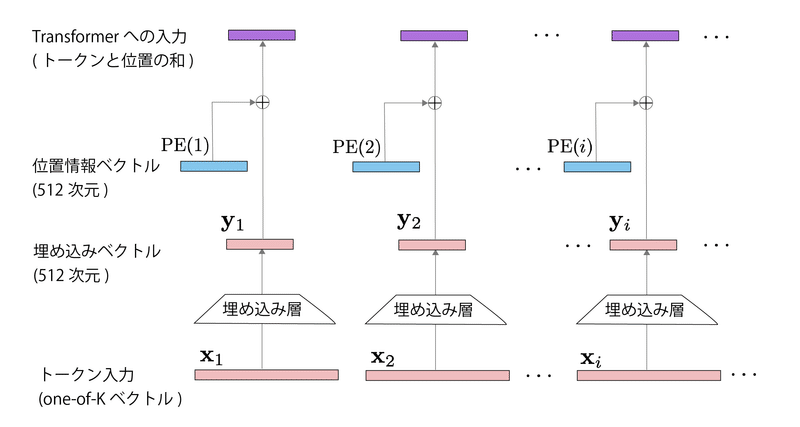
CVMLエキスパートガイドより
図2はTransformerの入力トークンの位置符号ベクトルを作成する過程を、トークン系列中の各フレーム$${i}$$ごとに分解して図示したものです。
図2中の$${PE(i)}$$が、3節で説明した位置符号化関数により作成した位置情報ベクトル$${p_i = PE(i)}$$です。
$${PE(i)}$$に、各トークンを埋め込み層で変換したトークン埋め込みベクトル$${y_i}$$を加算した$${PE(i)+y_i}$$が、最終的な「位置(符号)情報も足されたトークン埋め込みベクトル」となります。
軽く"I love to play football"を例として処理のイメージも書いておきます。
確かに、まずD次元の埋め込みベクトルについて示しましょう。各トークンがD次元のベクトルに埋め込まれる場合、トークン "I"、"love"、"to"、"play"、"football" のそれぞれの埋め込みベクトルは次のように表現できます:
$$
\textbf{I} = \begin{bmatrix} x_{I1} \\ x_{I2} \\ \vdots \\ x_{ID} \end{bmatrix}, \quad
\textbf{love} = \begin{bmatrix} x_{\text{love}1} \\ x_{\text{love}2} \\ \vdots \\ x_{\text{love}D} \end{bmatrix}, \quad
\textbf{to} = \begin{bmatrix} x_{\text{to}1} \\ x_{\text{to}2} \\ \vdots \\ x_{\text{to}D} \end{bmatrix}, \quad
\textbf{play} = \begin{bmatrix} x_{\text{play}1} \\ x_{\text{play}2} \\ \vdots \\ x_{\text{play}D} \end{bmatrix}, \quad
\textbf{football} = \begin{bmatrix} x_{\text{football}1} \\ x_{\text{football}2} \\ \vdots \\ x_{\text{football}D} \end{bmatrix}
$$
ここで、各$${x_{id}}$$は埋め込みベクトルの各成分を表しています。
これらのベクトルは学習中に更新され、その値はモデルの学習状況によります。
次に、各位置に対する位置情報ベクトルを示します。前述のように、位置情報は以下の関数を使用して生成されます。
$$
PE(pos, 2d) = \sin\left(\frac{pos}{10000^{2d/D}}\right) \quad
PE(pos, 2d + 1) = \cos\left(\frac{pos}{10000^{2d/D}}\right)
$$
これにより、各位置pos(ここでは1から5)に対応する位置情報ベクトルは次のようになります。
$$
\textbf{PE}_{1} = \begin{bmatrix} PE(1, 2\cdot1) \\ PE(1, 2\cdot1 + 1) \\ \vdots \\ PE(1, 2D) \end{bmatrix}, \quad
\textbf{PE}_{2} = \begin{bmatrix} PE(2, 2\cdot1) \\ PE(2, 2\cdot1 + 1) \\ \vdots \\ PE(2, 2D) \end{bmatrix}, \quad
\textbf{PE}_{3} = \begin{bmatrix} PE(3, 2\cdot1) \\ PE(3, 2\cdot1 + 1) \\ \vdots \\ PE(3, 2D) \end{bmatrix}, \quad
\textbf{PE}_{4} = \begin{bmatrix} PE(4, 2\cdot1) \\ PE(4, 2\cdot1 + 1) \\ \vdots \\ PE(4, 2D) \end{bmatrix}, \quad
\textbf{PE}_{5} = \begin{bmatrix} PE(5, 2\cdot1) \\ PE(5, 2\cdot1 + 1) \\ \vdots \\ PE(5, 2D) \end{bmatrix}
$$
各トークンの最終的な表現は、これらの埋め込みベクトルと位置情報ベクトルの和となります。
例えば、トークン "I" の最終的な表現は次のようになります:
$$
\textbf{I}_{\text{final}} = \textbf{I} + \textbf{PE}_{1} = \begin{bmatrix} x_{I1} \\ x_{I2} \\ \vdots \\ x_{ID} \end{bmatrix} + \begin{bmatrix} PE(1, 2\cdot1) \\ PE(1, 2\cdot1 + 1) \\ \vdots \\ PE(1, 2D) \end{bmatrix}
$$
同様に、他のトークン "love", "to", "play", "football" の最終的な表現も計算できます:
$$
\textbf{love}_{\text{final}} = \textbf{love} + \textbf{PE}_{2}, \quad
\textbf{to}_{\text{final}} = \textbf{to} + \textbf{PE}_{3}, \quad
\textbf{play}_{\text{final}} = \textbf{play} + \textbf{PE}_{4}, \quad
\textbf{football}_{\text{final}} = \textbf{football} + \textbf{PE}_{5}
$$
これにより、各トークンは、それぞれの語彙表現と位置情報を組み合わせた形で表現されます。
Transformer系モデルでは、PE(i)で位置情報ベクトルを計算する代わりに、埋め込み層を用意して、位置埋め込みベクトルを学習することも多いです。
5. 位置符号化 v.s 位置埋め込み
Transformerはマルチヘッドアテンションによる「系列全体のトークン群の一括処理」が主要な処理です。
よって、埋め込み層で得られるD次元トークン表現列をマルチヘッドアテンションで処理するだけでは「系列内の位置情報」が埋め込まれません。
そして、NLP分野にはWord2VecやGloveのような「単語同士の(相対)位置関係」の埋め込みの知見は以前からあったので、Transformerでも同じようにトークンの位置情報もコーディングしたい、ということとなりました。
そこで、"Attention is all you need" では、位置符号化を提案し、(1.1)式によって各トークン位置をD次元ベクトル表現に符号化することを提案しました。
論文内の実験の節でも、学習可能な位置埋め込み層を用意したものよりも、位置符号化の方が性能で勝った、もしくは同等なので位置符号化で良いと主張しています。
その理由として「学習データよりも長い系列に対しても、関数による位置符号化だと外挿したトークン位置情報をつくりやすいはずなので、位置埋め込みではなく、位置符号化をファーストチョイスして選んだ」と述べています。
しかし、後続のTransformerモデルやTransformer-EncoderやTransformer-Decoderを使用した大規模言語モデル(BERT、GPTなど)では、位置情報を学習する位置埋め込み層を採用するケースも増えています。
位置符号化と位置埋め込みのどちらが優れているかは、ネットワーク構造やタスクなどにより異なるため「両者はどちらが良いとは言えず、どちらも使われる」(CVMLエキスパートガイド著者より)とのことです。
6. おわりに
今回はTransformerの位置符号化について勉強しました。
データの形式や流れがなかなか想像できず、イメージをつかむまで苦労しました。
一応色々調べてみて、最も分かりやすかった例を4節に記載してあります。
参考になったら幸いです。
気づいた点や間違っている点などありましたら、お気軽にお伝えください。
次回は残差接続・・・と思っていたのですが、もうちょっと表層の部分から攻めていくのがやりやすいので、「層 (layers) : ディープラーニングの層の種類まとめ」について勉強していく予定です。
それでは。
進捗上げてます
「#AIアイネス」で日々の作業内容を更新しています。
ぜひ覗いてみて下さい。
参考
この記事が気に入ったらサポートをしてみませんか?