Machine Learning × Horse Racing #2

前回#1の内容は、Black指数なるものを作り、馬の点数化をしたというところまででした。今回は機械学習を使った予想の準備をします。
まず駄弁
前回Targetから引っ張ってきた出走データからCSVを作って、再度Targetに指数を格納したことには触れました。Black指数はそもそも過小評価されがちな馬を探すというコンセプトで作り始めたものですが、最終的にはBlack指数以外に、レース条件ごとの結果の傾向(荒れるor荒れない)を数値化したもの、能力評価寄りのデータを数値化したものを組み合わせ、Targetの馬券シミュレーションを使って長期回収率が100%を超える条件を探していました。
馬券シミュレーションによる予想は非常に単純でExcel上で条件をフィルターしていくだけなのでここではやりません。ですが、この単純で途方もない作業を何とか自動化できないかという意識が、AI導入を意識させることになります。初期の特徴量がまだ少なかったときは、気合で何通りもフィルターを試してメモして試してメモしてで頑張れましたが、特徴量が多くなるにつれ、くまなく可能性を潰していくことが時間的に不可能になりました。
そしてPythonです。
print("Hello World")
それまでプログラミングに興味はあったものの、触ったのはPythonが最初でした。最初の印象は、VBAをかじったときと似たようなものでした。つまり、これはいけるなと。なんとかなりそうだなと。先ずはExcelのフィルター作業を自動化するプログラムを書く事をモチベーションに基礎を勉強しました。なぜPythonを選んだのかといえば、もちろんDeepLearningすげー!というミーハーなものからでした。とにかくこうして1日中Pythonの事を考える日々がスタートしました。そして基礎勉強の最中に息抜きで始めた機械学習が、その後の競馬ライフに大きな変化をプレゼントしてくれました。
機械学習のデータ集め
さて、ここからAI機械学習の準備にかかります。学習に使用するデータは、再現性を考えJRA-VANが提供しているマイニングと対戦型マイニングのみを使っていきます。(From TARGET frontier JV)
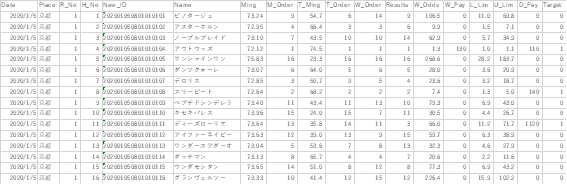
画像は1レースだけですが、2020年1年分のマイニング、対戦型マイニングを含めたテキトーなものを引っ張ってきました。1行目(カラム名)が日本語じゃないのは、機械学習のアルゴリズムによってはエラーになってしまうのを防ぐためで、決して調子ブッこいてるわけではありません。カラム名Targetの値は複勝前提でResultsが1~3の時には1、それ以外は0です。そしてこれが機械学習で学習させる答えの部分です。この答えとマイニング、Tマイニングとの因果関係を学習させるというのを目的にします。
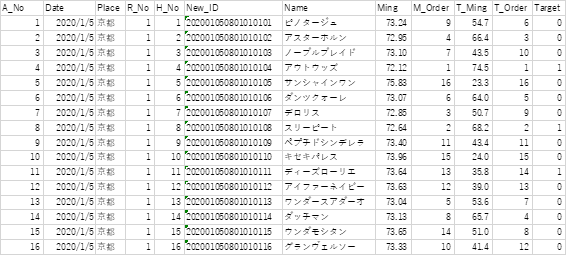
学習時には不要ですが、検証時に使うオッズなどのカラムを一旦省きsheet2にでも保管。管理しやすいように通し番号を付けます。Date~Nameは学習データを読み込ませるときに省きます。まぁ指数が一個とTargetの値あれば、それだけで学習自体は出来ますが、なんかこう~見た目地味過ぎるじゃないですか。なので使わないデータも引っ張って飾りを付けてありますので後で学習前にコードで省きます。
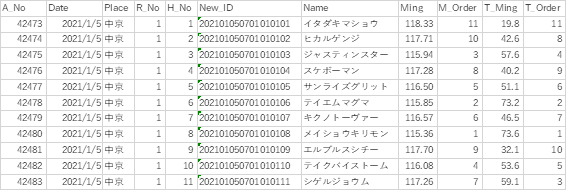
テストデータは2021年1月から6月までです。テスト用なのでTargetのカラムも一旦省きます。機械学習は、既知のデータを使って未来を予測させるので、答えを見せたらカンニングです。答えに直接つながるようなデータをテストデータに入れてしまうのはリークと呼ばれています。
チラッと沼が見えた
ここまでサクッと学習データとテストデータを作ってきましたが、実はすでに中身に手を加えてあります。競馬のデータというのはとても綺麗です。ですが欠損値になっている事があります。基本的に欠損値があると機械学習はできません。上の飾り付きのテストデータの元はこんな感じでした。
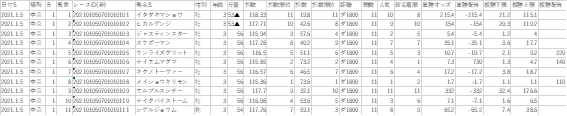
ぱっと見で複勝配当に欠損値があります。その他に斤量が減量マークと一緒になっていて、距離と馬場が一緒になってます。1月まで遡れば、除外による単勝オッズ、複勝オッズ、人気、確定順位が欠損しているものがあります。それらをゴニョゴニョとデータ加工していくことになります(学習時に使わなくても検証で使うので)。今回は先述の通り細かいことは無視してマイニングと対戦型マイニングの2つの特徴量だけで学習していきますので、欠損値に全て0を入れて万事解決!!
で学習してしまえばそれで終わりなんですが、実は機械学習において最も重要であり、センスや技や知識が表現出来る作業がこれだけなような気がします。除外になった馬の欠損値の処理をちょっとだけ考えてみます。
・その馬走ってないけど学習に使っちゃうの?
・7頭立て以下の時は複勝2着までだよね?
・7頭立て以下の時だけ検索してTargetの値だけ調整すればokじゃん!
・複勝云々より3着以内に入るか入らないかを予測させるんだからそのままでok!などなど
本来の学習の目的は何だったでしょうか。過去の因果関係から未来の結果を予測をする事でしたよね。そこには不純なデータがあっては望む精度は出ないと私は思っています。なので様々な角度で検証し、自分なりに納得できる学習データにしていく沼が見えてきました。
データクレンジングの沼は深く人それぞれ妥協ラインも違います。くれぐれもここで立ち止まらずに一度0で埋めてGO!GO! 一旦動くモデルを作ってから精度を上げるために戻ってきてゴニョゴニョという風に意識したほうがいいんじゃないかと思います。
競馬のデータは綺麗なほう
私がここでデータクレンジングの手法を全て解説などとても出来ませんし、逆に人それぞれの感性を表現できる部分でもあります。人と違う視点に立ち、人と違う予想論を構築する。ここに歓びがあると私は思っています。
今回はここまでです。次こそAIの中身に入れるはず。