
【たった9行!】Python初心者でもできるWebから住所情報を入手する方法

Pythonを使ってWeb上の住所情報からテキスト抽出する方法を記載します。いわゆるWebスクレイピングというやつです。
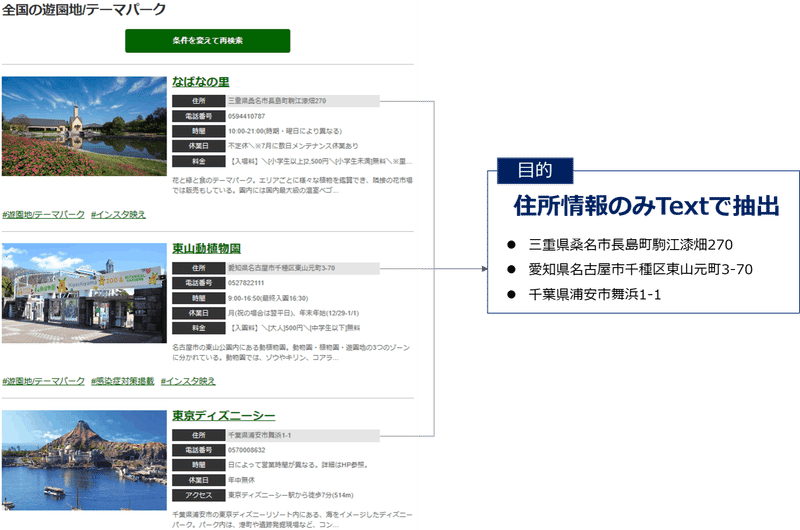
①実現イメージ
手動で住所情報をコピペするのは時間&労力コストが果てしなく掛かってしまうので、自動化してしまおうという話です。
②プログラムコード
今回はNAVITIME(ジャンルから探す - NAVITIME)を事例として記載しましたが、わずか10行程度で書けてしまったので早速記載します。
※「ジャンル:プール」の3頁目の住所を取得
※実行は自己責任でお願いします
import requests
import lxml.html
url = "https://www.navitime.co.jp/category/0101003/?page=3"
r = requests.get(url)
root = lxml.html.fromstring(r.text)
elms = root.xpath("//*[@id='spot-list']/ul/li")
for elm in elms:
dtag = elm.xpath(".//div[1]/div[2]/dl/dd[1]/dl/dd[1]/span")
print(dtag[0].text)③解説
Ⅰ.利用モジュール
import requests
import lxml.html
今回はこの2つのモジュールを使います。インストールがまだの場合は、pip等で対応ください。
Ⅱ.URLの構造
url = "https://www.navitime.co.jp/category/0101003/?page=3"
URL構造を理解すると応用が利きやすいので少し解説します。
ポイントは2つです。
ⅰ.categoryの後の「0101003」
意味のない数字の羅列のようで、これは「ジャンル=プール」を示しています。ちなみに0101001は「遊園地/テーマパーク」、0101012は「海水浴場」です。この番号の調べ方は至って簡単。対象ジャンルのページにアクセスしてアドレスをみれば一発でわかります。
ⅱ.「0101003」の後のpage
検索ヒット数が多いときにページ分割されますが、その何頁目かを表現するものです。page=1なら1頁目、page=100なら100頁目を意味しますが、存在しない場合は当然エラーが返されます。
Ⅲ.解析準備
r = requests.get(url)
root = lxml.html.fromstring(r.text)
上のコマンドはURL情報(HTML)をテキストで取得します。ただしこれだと解析しにくいので下のコマンドでHTMLを構造化します。
Ⅳ.対象箇所を抽出
elms = root.xpath("//*[@id='spot-list']/ul/li")
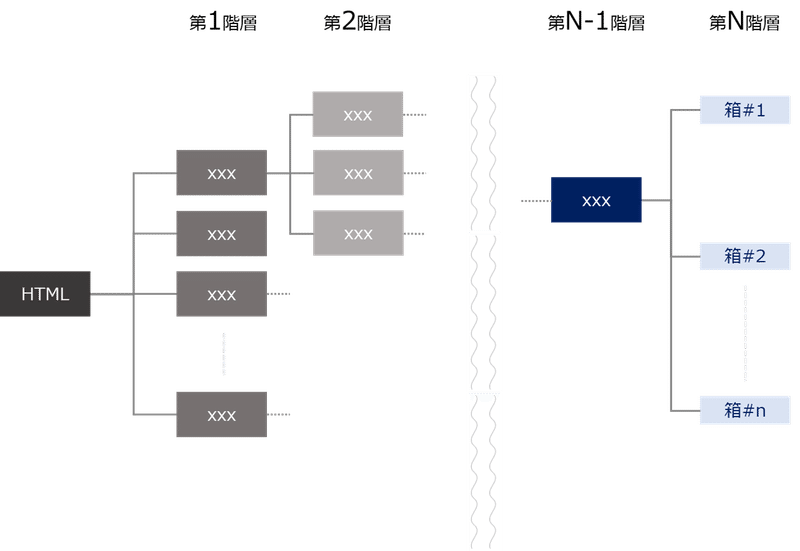
Ⅲで構造化したHTMLをXPathを用いて対象の住所情報を抽出しelemsという変数に格納します。まず最初に行いたいのは「住所が入っている箱」を探す作業です。NAVITIMEでいうと、薄い青で塗ったもの(図2)が箱に相当します。

ちなみに構造化されたHTMLとは図3のことです(コードでいうところのrootに相当します)。「住所が入っている箱」はかなり深い階層(第N層)にありますが、これを抽出するのが「//*[@id='spot-list']/ul/li」の役割です。
ではこの暗号みたいな「//*[@id='spot-list']/ul/li」はどこで入手できるのでしょうか。これはChromeの検証機能を使います。(対象ページを開いて右クリック→検証で起動可能)
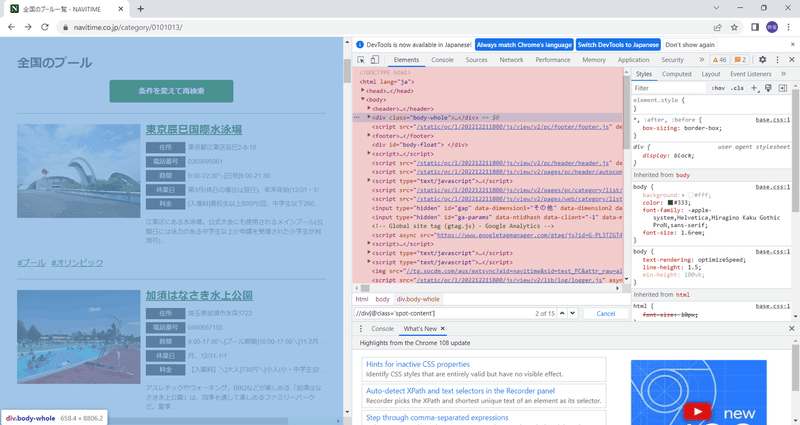
起動すると図4のような画面が出ます。この薄赤で塗ったところがHTMLの中身になります。(コードでいうところのr.textに相当します)
薄赤で塗ったところのテキストにカーソルを合わせると、該当箇所が薄青で塗られます。図4では薄赤5行目(<div class="body-whole">…</div>)にカーソルが合っていますが、これだと箱を含むすべての部分が選択されています。
今回欲しいのはあくまで箱の部分ですので該当部分を記載しているコードを探しましょう。手動で薄赤のツリーを掘り下げていっても良いですが、検索機能<Ctrl+F>を活用すると早いです。(図例であれば「東京辰巳国際水泳場」で検索してみる等)
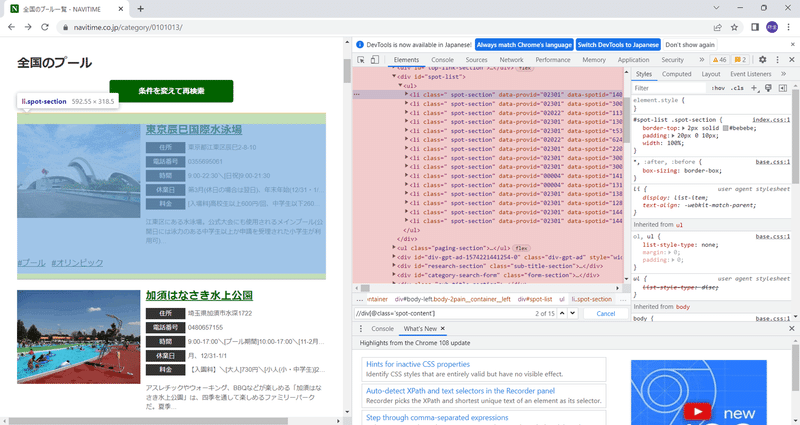
図5のように欲しい情報の箱まで分解(薄青部分)できたら、対象行(薄赤部分)で右クリックし、Copy→Copy XPathを選択。結果は下のような感じになります。
//*[@id="spot-list"]/ul/li[1]
liの後ろのカッコは何番目かを表すものになりますが、プログラムでは複数の箱を同時に取得したいのでカッコの部分は削除します。これでXPathの記載方法は完了です。
ⅴ.住所情報を抽出
for elm in elms:
dtag = elm.xpath(".//div[1]/div[2]/dl/dd[1]/dl/dd[1]/span")
print(dtag[0].text)
Ⅳでは箱(複数)をelmsという変数に格納しましたが、このfor文で1つずつ箱(elem)の中身を開けてXPathを用いて住所情報を抽出します。手法はⅣとほとんど同じですが2行目の以下の点に要注意です。
elem.xpathになっている点(root.xpathではない)
//の前に.(ドット)を用いている点
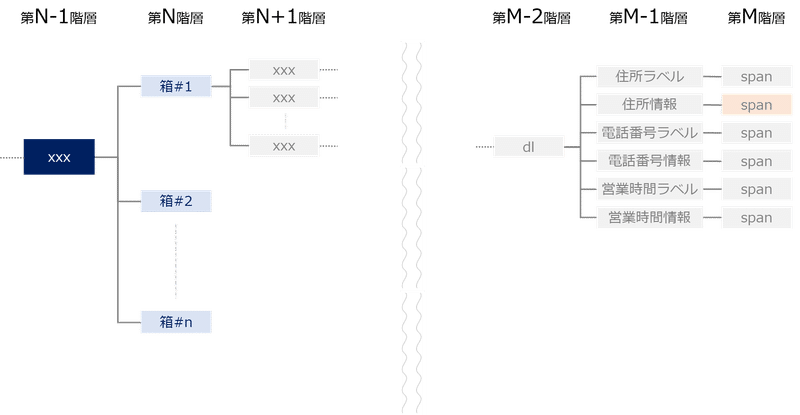
これを理解するためにはまず構造を考えましょう。ざっくり書くとこんな感じです。
Ⅳと同様に、住所情報に相当するコードを探します。そうすると図7(
薄赤部)の<span>部分が該当箇所のようなので、右クリックし、Copy→Copy XPathを選択します。
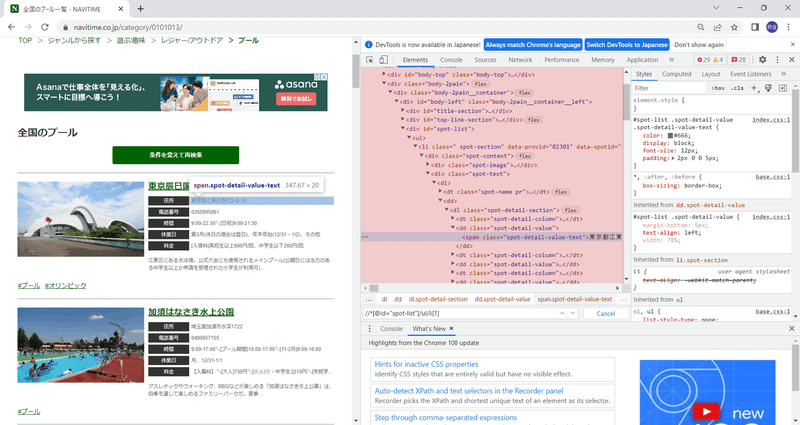
そうすると、以下のような結果が得られます。
//*[@id="spot-list"]/ul/li[1]/div[1]/div[2]/dl/dd[1]/dl/dd[1]/span
この結果のうち、前半部分(//*[@id="spot-list"]/ul/li)は箱(elem)のことを指し、後半部分(div[1]/div[2]/dl/dd[1]/dl/dd[1]/span)が箱から住所情報を取り出すXPathとなります。今回はelemを起点としている(elem.xpathとしている)ため、後半部分のみを記載しています。
ちなみに//の前の.(ドット)は、箱(elem)の下の階層のみを参照するという意味です。ドットをつけ忘れた場合、HTML全体から検索してしまうため、誤作動してしまう可能性があります。
④最後に
以上、Webから住所情報を取得する方法でした。
この記事が気に入ったらサポートをしてみませんか?