5つの視点でLLM/GPTの進化の方向性を探る

1. はじめに
2017年に"Attention is All You Need" 論文が発表され、Transformerアーキテクチャが登場。これにより、RNNやCNNに代わる新たな自然言語処理の基本構造が確立されました。その後、GPT-1、GPT-2、GPT-3と基本言語モデルが強化され続け、強化学習とファインチューニングにより訓練されたInstructGPT、それを会話用に洗練したchatGPT、今年のはじめには、GPT-4が発表され、世間を席巻していますね。私自身もGPT-2あたりから動向を軽く探っていましたが、今年になってからの業界の速さには目が回ってしまいます。そこで今後、どのように技術が進化していくのか、5つの視点で見ていきたいと思います。
2. GPTの技術遷移
GPTの性能を決めるおおきな要因の一つがパラメータ数です。GPT1のパラメータ数は1.7億個だったのに対して、GPT4のパラメータ数は文献によると100兆個ともされています。GPT1と比較すると相当な数のパラメータ数が追加されています。開発段階でパラメータ数と計算量を上げて行くとともに推論能力は徐々に上がっていきましたが、あるところを境に劇的に性能向上が見られたということで、言語モデルの「スケーリング則」が適用されるとされました。つまり、ひたすらパラメータ数と計算量をつぎ込むと、高度な推論能力が得られるとわかったのです。

とはいえ、現在のところ、パラメータ数を上げていく方向性については限界が見えているようです。GPT1からのパラメータ数の増加を見ていると指数関数的な増加をしているので、さらなる性能向上には、パラメータ数の増加にともない膨大な計算量が必要となりそれに伴う消費電力コストがすごいことになりそうです。計算資源は限られるため、この限界は物理的な限界によるものだと思います。量子コンピューターなどで計算されると人智を超えた存在ができるかもですね。
3. パラメータ数とは?
さっきから話しているパラメータ数とは、そもそも何なのかですが、脳にあるニューロンそれぞれが別のニューロンと連携しますが、その連携の重み付けがパラメータ数です。よく見かける深層学習の図ですが、この一つ一つの線に重みがあり、この重みがパラメータ数です。厳密には、バイアス項や入出力にともなうパラメータ数があるのですが、ざっくりと説明するとそうなります。
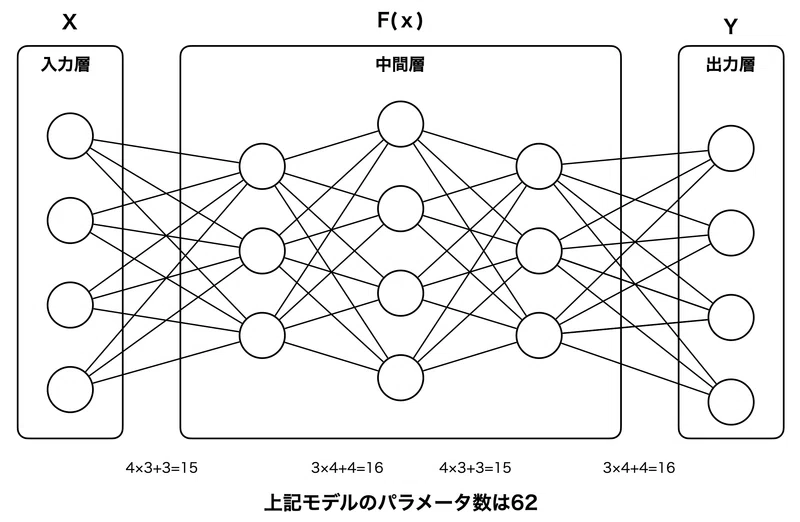
4. Attention is All your need 論文
自然言語処理(NLP)の分野で大きな影響を与えた研究です。この論文では、Transformerという新しいモデルアーキテクチャが紹介されています。

「へぇ」って感じですね。パラメータ数のところで深層学習にニューロン連携がありました。パラメータ数を増加すれば推論能力が増大するという考えがあって、それでも単純に増加しても推論能力は頭打ちになっていたのですが、重要な部分に注目するというAttention機構というのが論文で発表されて、これはすごいということになって、言語モデルに採用となりました。
5. LLM/GPTの進化の方向性
さて、やっと本題にはいりました。ここまでくどい説明が続きました。2023年になってから毎日GPT関連の話題をキャッチしていますが、少し目を話すと途端に引き離されてしまいます。本当に目まぐるしい。。

僕の視点で大きく5つの視点に分けました。異論は認めます😂
言語モデルの改善
トークン量の拡張
学習方法の改善
マルチモーダル化
プロンプトエンジニアリング
その帰結として、今後、自律型エージェントの開発競争に突入すると考えているというか、もうすでにそうなっていますね。
6. 言語モデルの改善
これは今まで説明してきたところですが、シンプルにパラメータ数の増加とそれに伴う計算量の増大で性能が上がっていきます。それに加えて、現在、chatGPTの他に様々なモデルがgoogleやMeta、その他、研究機関などから、続々と開発されています。
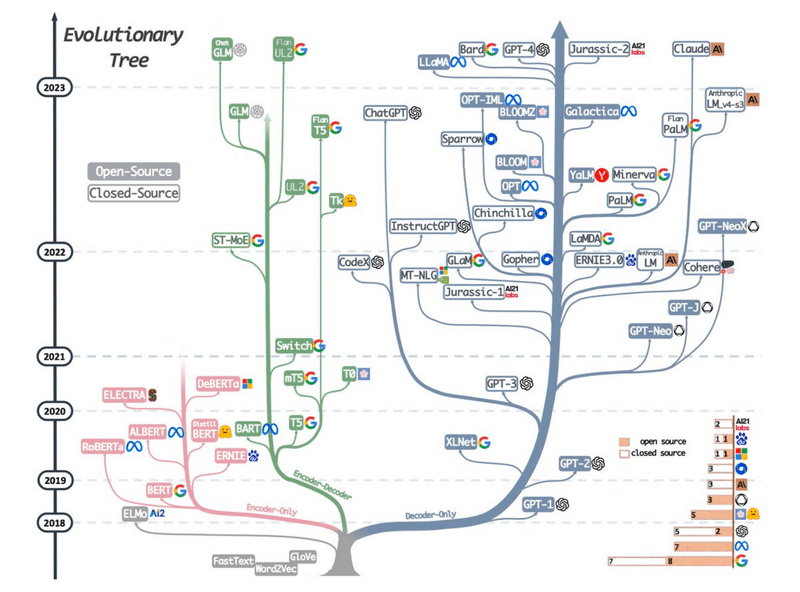
この図は、Transformer系の言語モデルの技術進化樹形図ですが、Encorderモデル、Decorderモデル、Encorder-Decorderモデルをおおきな流派として、様々な言語モデルが開発されています。chatGPTは、Decorderモデルで大きく発展しています。Encorder-Decorderモデルというのは、簡単に行ってしまえば、Encorderは情報の圧縮で、Decorderは情報の展開なのですが、詳しいことは、昔ならググってくださいというところですが、今ならchatGPTに聞いてみると詳しく説明してくれます。^^;
ここでは、GPTも言語モデルとしての基礎は確立されたと言ってもいいと思いますが、改善する点はあるので、その改善に取り組むために各社、各研究機関が心血を注いでいます。
言語モデルの改善の動きは、高度な人材や研究機関、企業を中心に取り組まれています。
7. トークン量の拡張
次にプロンプトによる指示の文字数と返答に使用される文字数を決定づけるトークン量の拡張が今後のテーマの一つになりそうです。現在のところ、chatGPT3.5-turboでは最大トークン数が4096トークンとなっています。このトークン数は、ざっくりと考えると文字数と考えてもよいですが、厳密には、learningなどの単語だとlearnとingがわかれて2トークンのように数えられるような形になり、トークンの数は文字数とは異なることが多いです。
GTP4では、この最大トークン量が32,768となっており、3万語近いトークンの処理ができるようです。今後もこのトークン量の増大は続きます。

論文「Scaling Transformer to 1M tokens and beyond with RMT」では、Recurrent Memory Transformer が最大 200 万トークンにわたって情報を保持できるようにする方法を見つけることができました。簡単に言えば、以前よりもはるかに多くの膨大な量のデータを処理および記憶できます。
これにより、ビジネスのあり方やサービスのあり方も劇的に変化する可能性があります。たとえば、AI はブログ投稿だけでなく、小説全体を書くことができる用になります。また、膨大な量のデータを分析することで、複雑な科学研究を支援ます。何年にもわたるやり取りの履歴を保持することで、顧客サービスを強化したり、人生経験の保存の分析など、これまででは考えられなかったようなサービスを展開することが可能になります。
8. 学習方法の改善
GPTの学習方法としては、人間のフィードバックを用いて強化学習(RLHF)が有名です。この学習方法は、chatGPTでも利用されています。GPTモデルは、プリトレーニングとファインチューニングのパラダイムに基づいており、プリトレーニングされた言語モデル(GPT3,4など)をいかに賢く学習させるかというのが課題の一つです。

大規模データセットは、様々な情報を包含しており、それによりモデルは多様なトピックや文脈、表現方法について学習します。プリトレーニングの過程で、モデルは大規模なデータセットからパターンを学び、テキスト生成の基本的なスキルを獲得します。パラメータのそれぞれの重み付けを調整して、入力に対する出力を調整します。プリトレーニングの後に特定の入力に対して、特定の出力を出すように機械に学習させるのがファインチューニングです。強化学習と人間フィードバック(RLHF)では、言語モデルが適切な出力を行うと報酬が得られるという強化学習の枠組みを使いますが、モデルはこの報酬を最大化するように行動します。このプロセスを通じてchatGPTは、人の意図を理解しているかのような振る舞いをします。
学習方法については、RLHFの他にも様々な手法があり、研究が活発に行われている分野です。PPOは比較的古い手法ですが、その他にRRHF, RAFT, ILQL など(私もよくわからないのですが)の手法が考案されています。そのインセンティブは、RLHFは、人がその学習方法に人が介在するため莫大なコストがかかってしまうということが挙げられるようです。特定の分野で効率的に学習ができれば、特定の分野でよりコストの低い性能の高いモデルが出てくることが予想されます。次に貼り付けたのはこの分野をまとめてくれています。
9. マルチモーダル化
テキストを入力としてテキストを出力するテキスト生成系AIは、すでに過去のものとなってしまいました。。いやぁ、ほんとに激動の数ヶ月です。言語モデルの特徴は次単語予測です。文脈が提示されたら次の単語の予測をするということですが、このモデルがやっていることは予測や推論といったものです。これって画像や音声、動画でも可能だよねってことで、なんでも使えるということがすでに実証されていています。すでに視覚的(画像やビデオ)や音声、音楽、あるいは、触覚的なものまで理解し、情報を統合して、行動を決定してしまいます。
このように人の五感に近い情報を理解し、情報処理出来ることをマルチモーダルといいますが、今後この分野が発達していくことが予測されます。ビジネスの世界が一気に広がりそうです。今は、Copilotなど、既存のサービスやツールにAIアシスタントとして、機能拡張が行われていますが、これが実現して、精度がたかいものになっていけば、その応用分野は広がりを見せると思います。
AIはよりリッチで直感的なインターフェースを提供できるようになります。これは、AIアシスタントがより自然な形で人間と対話できるようになることを意味します。
ヘルスケア:AIは、患者の病歴や検査結果を分析し、診断や治療の推奨を行うことができます。また、音声認識や画像認識を活用して、患者の健康状態をリアルタイムでモニタリングするツールも考えられます。
教育:AIは、学習者の進行状況とニーズに基づいて個別の学習経験を提供することができます。また、音声や視覚情報を用いて、よりリッチで没入感のある教育体験を作り出すことも可能です。
小売業:AIは、消費者の購買履歴や好みを理解し、パーソナライズされた推奨を提供することができます。また、音声や画像認識を使用して、物理的な店舗での購買体験を強化することも可能です。
エンターテイメント:AIは、視聴者の好みに基づいて個別のエンターテイメント体験を作成することができます。また、視覚や音声の情報を用いて、映画や音楽の制作を補助するツールも考えられます。
交通:AIは、道路の状況を理解し、より安全で効率的な運転を支援することができます。また、自動運転車の開発においても、マルチモーダルAIは重要な役割を果たすでしょう。
10. プロンプトエンジニアリング
プロンプトにより言語モデルの出力精度が劇的に向上するということがわかっています。有名な例では、プロンプトの後に「ステップ・バイ・ステップで説明して」のような言葉を付け足すと、回答の精度が向上します。この手法は、思考連鎖 (CoT) プロンプトと呼ばれていて、段階的に推論し回答までの精度を向上させます。この他にも様々な手法が考案されています。プロンプトエンジニアリングに関しては、様々な論文が出ていますが、親切にもまとめてくれているので、そのリンクを貼り付けておきます。
プロンプトエンジニアリングは、言語モデルから効果的な回答を得るための手法です。人にものを頼むとき、雑な頼み方をすると雑な答えしか返ってこないですが、詳細にお願いすると想定以上の答えが返ってきたります。基本的には、要は質問の仕方だろ?と思うかもしれませんが、その状況に応じて適切なプロンプトというものがあり、曖昧に理解してしまうと、プロンプトエンジニアリングの可能性を見誤る恐れもあるくらい重要な論点です。
11. 自律型エージェント
これまで、5つの観点である、①言語モデルの改善、②トークン量の拡張、③学習方法の改善、④マルチモーダル化、⑤プロンプトエンジニアリングで、LLM/GPTを見てきました。これらの進化の先に自律型エージェントが見えてきます。
自律型エージェントは独立して環境を観察し、その観察に基づいて自分で意思決定を行い、環境に対して行動する能力を持つソフトウェアやロボットを指します。自律型エージェントは自分自身の目標を達成するために環境と相互作用します。
chatGPTの挙動を見ていると、「こいつ完全に人の言葉を理解しているな」と思うフシがあり、深層学習も人の脳を模倣しているため、そのニューロン数が多くなると人に近づくというのは有り得る話です。そこに意思があるのかは議論の余地がありますが、意思と理解は別物なのかもしれません。
自律型エージェントには、意思が必要になります。人間的な意味の意思と異なるかもしれませんが、少なくとも、強化学習のような枠組みで目標と報酬、環境を設定するこで、目標に向かってひたすら行動する自律エージェントが誕生します。
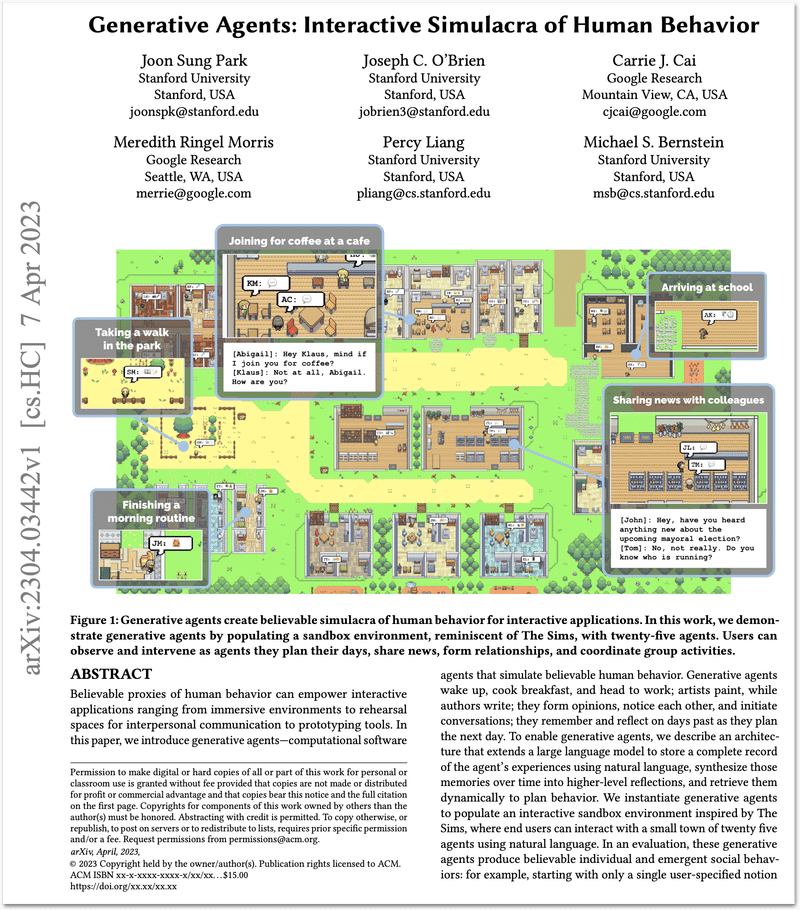
少し前の例では、論文「Generative Agents: Interactive Simulacra of Human Behavior」が有名です。ここでは、村のような環境を作り、そこに家や教室、カフェなどを配置し、それぞれに個性や役割をもたせたNPCを配置しています。すると、その中で、自律的にエージェントが他のNPCと会話し、行動するということが観測されたそうです。あるNPCは、テーパーティーを開くことを決定し、その招待状を他のエージェントに送り、その期日に実際にパーティーを開いたとか。
最近ではマインクラフトの環境内で自律的にゲームするエージェントを開発した例がありました。このVoygerプロジェクトでは、Minecraft内で人間の介入なしに世界を探索し、多様なスキルを習得し、新たな発見をする、最初の大規模言語モデル(LLM)による実体化された生涯学習エージェントです。
以下の3つの主要な要素で成り立っています。オープンワールでかつ自由度の高いというのがマインクラフトの特徴ですが、この世界のなかで、自律的に学習し、スキルを獲得し、自己問答しながら探索し続けるのは驚くべきものだと思います。
1. 自動カリキュラム:これは探索を最大化するためのもので、VoyagerがMinecraftの世界を広範に探索するのを助けます。
2. 成長し続けるスキルライブラリ:このライブラリは実行可能コードを保存し、複雑な行動を取り出すためのものです。これにより、Voyagerは習得したスキルを再利用し、新しいタスクを効率的に達成できます。
3. 反復プロンプトメカニズム:この新たなメカニズムは環境フィードバック、実行エラー、自己検証を取り入れ、プログラムの改善を可能にします。これにより、Voyagerはスキルの品質を改善し、時間の経過とともにより高度なタスクを達成できます。
今後、自律型エージェントは、開発競争時代に突入し、様々な場面で活用されていくことになるはずです。マインクラフトのような世界で手足を獲得したエージェントが自由に動き回り自己改善を繰り返していく、この世界の先を考えると、例えば、企業などで活用されれば、比較的単純な作業など簡単に置き換わってしまうかもしれませんね。怖い話ですが、これらは、近い将来、高い確率で実現するため、これらに備えようという話でもあります。
12. おわりに
ここまで読んでくださってありがとうございました。2022年の末にchatGPTと対話しまくって、すごいという感嘆の感情とともに、怖いという感情が相当芽生えました。シンギュラリティーが2030年という話もあったので、楽しみにしていましたが、もうすでに来てしまいましたね。未来に備えなくてはなりません。本当に。今後、生産性が劇的に上がり、雇用は下がる未来を想像しています。そうなるとベーシックインカムが実現され、何もしなくても生きていけるユートピアか、やることなくなって、無気力なデストピアな世界になるのか。人の欲は付きませんが、人智を超える存在を目の前にしたとき、どうなるんでしょうか。先のことを考えても仕方ないので、この関連の開発に少なからず携わる身として、今起こったサイエンスフィクションを楽しみたいと思います。