
ICCV2019発表予定論文を読んで再現してみた / "SoftTriple Loss: Deep Metric Learning Without Triplet Sampling"
この10月末~11月初頭に韓国で開催されるコンピュータビジョンに関する国際会議・ICCV 2019 (International Conference of Computer Vision)で発表される論文である"SoftTriple Loss: Deep Metric Learning Without Triplet Sampling"に興味があったので、論文で提案されている手法の実装と再現実験を行いました。
近年は機械学習分野の注目度と進展の速さに論文のレビューと発表のサイクルの速度が追いついていないため、会議で発表される前に論文を公開してしまうことが多くなっています。この論文も丁度一ヶ月ほど前に公開されており、実際に発表される前にその内容を詳しく知ることができました。
論文の内容
※別の方の日本語スライドでの解説がありました。こちらの方がわかりやすいかもしれません
この論文は距離学習という分野のものです。以前の記事でも説明しましたが、距離学習では似ていると分かっているアイテム同士を近くに、似ていないと分かっているアイテム同士を遠くにマッピングするようなニューラルネットを訓練することを目指します。
画像をもとに商品を似ている順にソートして表示したい場合など、「似ている・似ていない」を抽象的に表現したい時に利用される技術です。
従来は、Tripletと呼ばれる三つ一組のデータ単位を利用するのがメジャーな方法でした。具体的には、三つのデータの中で中心となるものが決められていて、残り二つのデータは中心データと相対的に似ている・似ていないものをそれぞれあてがいます。ニューラルネットは中心のデータと残り二つのデータの「距離」を計算し、実際に似ているもの同士の距離を似ていないもの同士の距離よりも大きくするように更新されていきます。

コンセプトはいたって単純ですが、実際の訓練を成功させるのは簡単ではないと言われています。
その大きな原因はTriplet選びの難しさにあります。三つ一組のデータを愚直に選ぶとその選択肢は(データの数)^3のオーダで存在します。例えば画像が10000枚あったらTripletの組み合わせは大体数億~数百億通り考えられ、とてもじゃないですが扱いきれない量になります。
NNの訓練にとってはデータは多ければ多いほど良いとはいわれますが、この場合元となるデータはTripletの数に対して圧倒的に少ないことがポイントです。大半の場合、明らかに似ているペア・明らかに似ていないペアが多量含まれており、そういったTripletは簡単に当てることができてしまう(=訓練データとして情報量に欠ける)ものになります。したがって、効率的にTripletを選ばない限り計算リソースは無駄に消費され訓練はなかなか進んでくれないということになってしまいます。その選び方に関する工夫は数多く存在していますが、どのような場合にも上手く行く手法が存在するわけではないようです。
この論文では、このTripletによる訓練と同様の効果をより簡単な問題設定で得られることを指摘しています。具体的には、いわゆる識別問題を解く際に与えるペナルティであるSoftmax Lossの派生系が、Tripletの与えるペナルティと等しいことを証明しています。2012年以来擦られ続けている識別の問題設定を工夫することによって距離学習ができてしまうということです。
この時点でシンプルかつ有用な手法の提案になっているのですが、Softmaxによる損失にさらに一工夫加えることによる、より表現力に富むモデルの訓練方法も紹介しています。
Softmaxでは一つのカテゴリにつき一つの代表点が存在することを仮定しています。しかし実際のデータでは、同じカテゴリに属するもの同士でも見た目・形状が全く異なる場合も考えられます。一つのカテゴリにつき複数の代表点を用意することによって、そのようなデータのばらつきにも対応することができるようになると主張しています。

こちらの手法は、実際に公開データセットでの検索性能において既存手法を大きく上回るスコアを一部指標で記録しました。評価値として論文内では様々なものが報告されていますが、この記事ではもっともわかりやすいR@1スコアを用いて比較を行うことにします。R@1スコアは要するにデータの中で一番似ているものが、同じ分類クラスに属するものである確率です。
訓練・評価に使われているCUB-2011は200カテゴリからなる野鳥のデータセットです。そのうち100カテゴリを訓練に使用し、NNにとっては全く未知の残り100カテゴリのデータのなかで類似度を判定します。
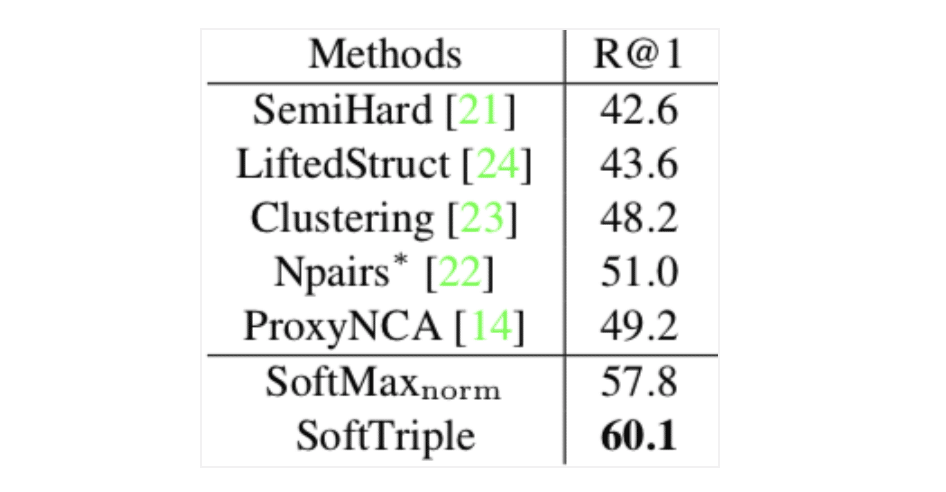
下図が論文内で紹介されたCUB-2011での評価値の既存手法との比較です
(下二段が提案手法)。
驚くことに、普通のSoftmaxを少し工夫した手法であるSoftmax_normが、すでに既存手法の評価値を上回っています。最終的な提案であるSoftTripleは、既存手法の最良の評価値を9.1%も上回っています。
再現実験
コンセプト・結果ともに印象的な論文にもかかわらず、私が読んだ当時インターネット上に実装が存在していなかったため、論文で提案されている通りに実装を行い、CUB-2011での再現実験をしました。
Githubのレポジトリはこちら
訓練では論文に報告されたパラメータとそれに近しい数字を試しました。
データ:
- 200カテゴリあるうち、前半100カテゴリを訓練に使用。残りの100カテゴリで評価
- 訓練データにはランダムにhorizontal flip / random cropを適用
- バッチサイズ=32
モデル:
- inception_v1(入力はRGBx224x224px, Batch Normalizationを使用)
- 64次元の潜在空間で類似度を計算
- 各カテゴリごとに5個の中心点を用意
学習設定
- エポック数: 50
- オプティマイザ: Adam
- 学習率:
- 0.01(backbone), 0.0001(中心点)
- 20epochごとに学習率を1/10
その他ハイパーパラメータ(それぞれの意味は論文を読んでください):
- τ=0.2
- γ=0.1
- δ=0.01
- λ=30
以上の設定で、我々の手元では52.6%のR@1スコアを記録することができました。既存手法でもっともスコアの良いNpairsという手法に対しては、この評価手法ではより良い成績を収めることが確認できます。

optuna等駆使して色々な訓練設定を試してみましたが、結果として論文で報告されているR@1スコアである60.1%には大きく届きませんでした。。実装に不具合があったり、論文で報告されていない委細がどこか存在するのかもしれません。(マサカリ・追実験等歓迎いたします)
それでも簡単な訓練設定で、比較手法のSOTA以上のスコアを手元で記録できたということで、十分使いどころのある手法なのではないかと思います。
この記事が気に入ったらサポートをしてみませんか?