文系でも分かる!Pythonプログラミング - {set} / sequence / set_operator(集合演算子)

← preview
next →
< class 'set' >

set
>> set ( セット )
= セット。 組、集合。
{波括弧}で囲っているため
見た目が dict型 に似ているのですが、
keyとvalueをペアにする
「 : (コロン) 」がないデータ型があります。
それは、「 set(セット)型 」というものです。
set_obj = {1,2,3,4,5}list型やtuple型にも似ています。
set型の最大の特徴は、
「 値の重複を許さない 」というところです。
なぜ値の重複を許さないのか。
それはこれが「集合」を扱うための
データ型だからです。
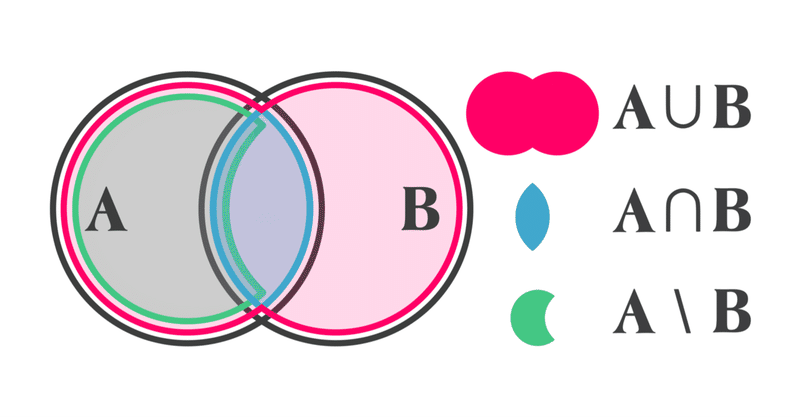
Venn diagram
「集合」や「ベン図」というものについて
学んだ事はありますでしょうか?
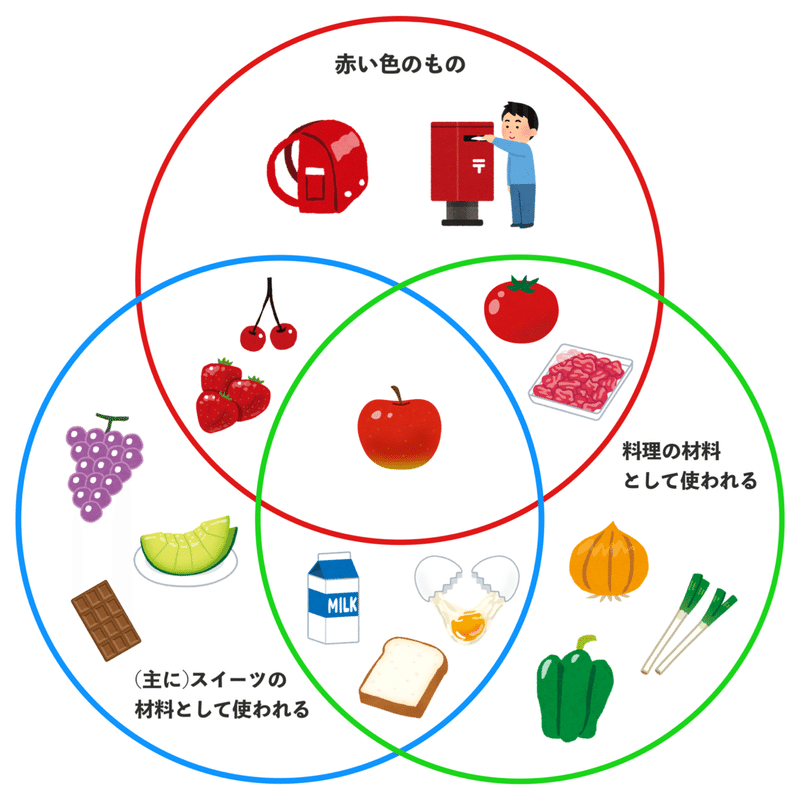
👆これがいわゆる「ベン図」です。
(イギリスの論理学者、ジョン・ベンの名が由来)
「赤い色のもの」の集合
「料理の材料として使われるもの」の集合
「(主に)スイーツの材料として使われるもの」の集合
この3つの共通点を全て持った要素が
中央にある「リンゴ」なわけですね。
値の重複
この図を書く時に、
「リンゴ」だとか「パン」だとかを
いくつもいくつも書く必要はあるでしょうか?
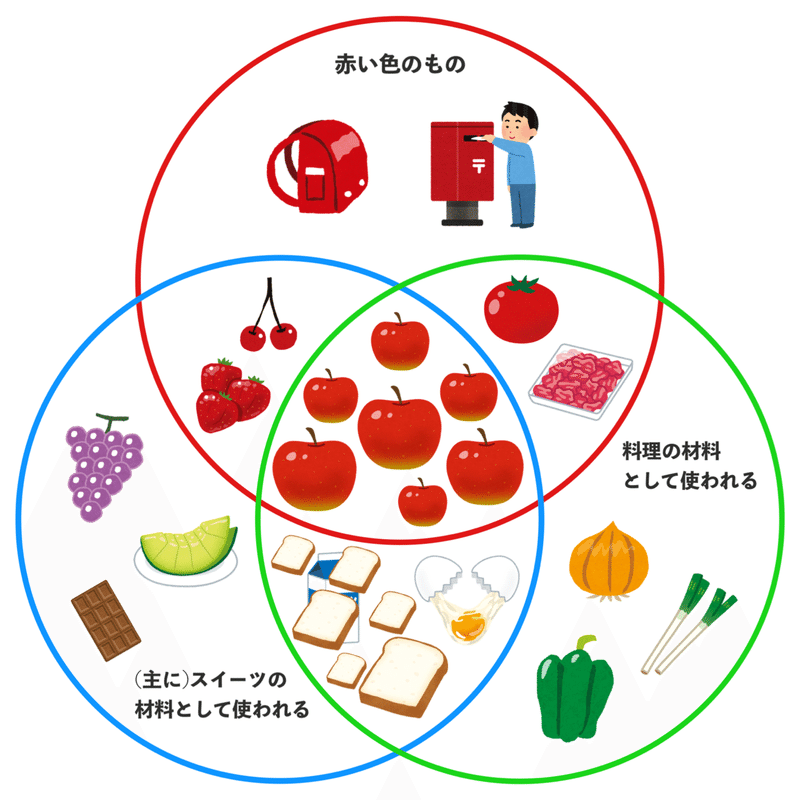
書きませんよね普通。
数量は関係ないわけですよ。
つまり、
集合を表す時には
重複した値を表示する必要がない。
set_obj = {1,1,1,2,2,2,2,3,3,3,4,4,4,5,5,5,5,5,5}
print(set_obj)
# >>> {1, 2, 3, 4, 5}👆 ほら、コンソール出力しただけで
重複した値が消えてる。
本当に消えてしまっているか確認しましょう。
set型 は、[iterable_object] です。
つまり、
for文を使ったりlist関数(他)を使ったり
len関数を使ったりin演算子で値の検索をする事ができるので
格納されてる値の数を数えることができる。
set_obj = {1,1,1,2,2,2,2,3,3,3,4,4,4,5,5,5,5,5,5,5}
#--------------------------------#
# for文で値を一個ずつ取り出してみる。
for i in set_obj:
print(i)
# >>> 1
# >>> 2
# >>> 3
# >>> 4
# >>> 5
#--------------------------------#
# list()でリスト化してみる。
print(list(set_obj))
# >>> [1, 2, 3, 4, 5]
#--------------------------------#
# len()で値の数を数えてみる。
print(len(set_obj))
# >>> 5
#--------------------------------#
# in演算子で探してみる。
if 3 in set_obj:
print(True)
else:
print(False)
# >>> True「set型」と認識された時点で、
重複した値は無かった事にされてしまうようです。
dict型でも「key(キー)が重複してはいけない」
というルールがありました。
{波括弧}を使っているデータ型は、
共通して「重複させてはいけない」と
覚えればいいのですね。
sequence

順序
>> sequence ( シーケンス / シークエンス )
= 順序。ひと続きのもの。相次いで起こること。
set型 の特徴はもう一つあります。
それは、「順 序 を 持 た な い」という点です。
どういうことか先に見てみましょう。
set_obj = {"A","B","C","D","E"}
print(set_obj)
# >>> {'C', 'B', 'A', 'E', 'D'}なんと、
"A"→"B"→"C"→"D"→"E"の順番で書いたのに
順番がめちゃくちゃになって
出力されてしまいました。
あれ?でもさっき
set_obj = {1,1,1,2,2,2,2,3,3,3,4,4,4,5,5,5,5,5,5}
print(set_obj)
# >>> {1, 2, 3, 4, 5}重複した値は消えたけど、
順番はめちゃくちゃになってなかったぞ?
って思いませんか?
月咬の調査データによると、
「0.0,1.0, 2.0, 3.0, 2*2.0, ...」のように
「0,1,2,3,4, ...」と一緒やん って数に関しては
順番をバラバラにしても
「0.0, 1, 2.0, 3.0, 4.0, 5, 6...」のように
キチンとした順番に並び替えられるようです。👇
set_obj = {2*2.0, 6, 2.0, 0, "B", 1, 3.0, "C", 3, "A", 5, 0.0, 4, 2, 1.0}
print(set_obj)
# >>> {0.0, 1, 2.0, 3.0, 4.0, 5, 6, 'C', 'B', 'A'}str型は順番が「"A"→"B"→"C"」
のようにはなっていませんね。
しかし、「0,1,2,3,4...」と一緒やんって数...
ちゃんと書くと、
「0を含む正の整数(自然数)」と
同値になる数(オブジェクト)については
昇順(小さい順)にソート(並び替え)されています。
小数点以下に何も無い事を証明するために
「2」よりも「2.0」、「3」よりも「3.0」が
生き残っているようですが
「1」だけは「True」を
表現するために使われていたりするので
「1.0」よりも
「1」が優先されるようですねえ。
set_obj = {4, True, 2, 1.0, 0.0, False, 3, 1, 0}
print(set_obj)
# >>> {0.0, True, 2, 3, 4}「False」は「0」で表現されるものだから
「False」か「0」が生き残るのかと思いきや、
なぜか「0.0」が優先されています。
まあ、この辺は仕様ってことで
片付けてしまいましょうか。話が進まんから。
とにかく何の値であっても
「(勝手に)並び替えられる」ということは
「順序が無い」という事。
それは間違いありません。
シーケンス型 / 非シーケンス型

[ list型 ], ( tuple型 ), " str型 "
👆この3タイプのオブジェクトは、
「シーケンス(sequence)型」と言います。
シーケンス型には
「値の順序」があります。
順序があるってことはコンソール出力した時に、
元の順番が 並 び 替 え ら れ る 事 な く 保 た れ る
という事です。
一方、
それ以外のオブジェクトは
「非シーケンス型」と呼ばれます。
順番がバラバラになってしまうオブジェクト型ですね。
set型 は順序が無いため
「非シーケンス型」だと言えます。
※僕独自の表現で「 -> sequence >> 」のように
「 -> >> 」を付けて記述するようにします。
「順序があるよ」という意味です。
-> sequence >>
なぜ「-> sequence 型 >>」なんてものがあるのでしょうか。
それは、
特定の値を index[n]番号で呼び出すため です。
index[n]番号を割り当てるためには
順序が必要だって事です。
index[n]で値を呼び出せるか確認しましょう。
[ list ] 型
list_obj = ["A","B","C","D","E"]
print(list_obj[3])
# >>> D( tuple ) 型
tuple_obj = ("A","B","C","D","E")
print(tuple_obj[3])
# >>> D" str " 型
str_obj = "ABCDE"
print(str_obj[3])
# >>> D{ di:ct } 型
dict_obj = {"a":"A","b":"B","c":"C","d":"D","e":"E"}
print(dict_obj[3])
# >>> KeyError : 3dict型 は index[n] ではなく
[key] を使って value(値) を呼び出すのでした。
[key] があればいいので
順序が無くても困らないわけです。
list( )やtuple( )に変換すれば、
index[n]を使う事も可能ではあります。👇
(面倒なので1行で書きました。)
dict_obj = {"a":"A", "b":"B", "c":"C"}
print(tuple(dict_obj.items())[0])
# >>> ('a', 'A'){ set } 型
set_obj = {"A","B","C","D","E"}
print(set_obj[3])
# >>> TypeError : 'set' object does not support indexing「集合において、重複した値は必要ない」
という事は説明しましたね。
さらにこう考えて下さい。
「何らかの集合を目の前にした時
私たちは順序を気にしているだろうか?」と。
例えば、
大勢で一斉にやる○×クイズ。
正解者を知ることは大事だけれど、
オールスター感謝祭じゃあないんだから
その順番はどうだっていいはずですよね。
あとは通販におけるセット。
ご当地ラーメンセットとかね。
大事なのは箱に詰める商品の
順番が合っているかどうかよりも
何が入っているのかという
「セット内容」ですよね。
set型に格納できない値
前回の記事で
mutable / *immutable*
#hashable / unhashable の話をしましたが、
set型に格納する値は
重複した値を消すために
値同士を高速で比較する必要があります。
dict型の[key]と同じですね。
つまり、
オブジェクトをハッシュ化して、
同じハッシュ値のものを消すわけです。
だから set型 に格納する値は
#hashable である必要があります!
#hashable である必要があるということは、
*immutable(変更不可)* でなきゃならない
ということでしたね。
mutableなオブジェクトである
[list型], {dict:型}, {set型},
(bytearray型, ユーザー定義クラス) は
set型に
格納する事が で き ま せ ん 。
list_in_set = {[1,2,3],[4,5,6]}
print(list_in_set)
# TypeError : unhashable type : 'list'dict_in_set = {{"A":"あ","B":"い"},{"C":"う"}}
print(dict_in_set)
# >>> TypeError : unhashable type : 'dict'set_in_set = {{1,2,3},{4,5,6}}
print(set_in_set)
# >>> TypeError : unhashable type : 'set'集合演算子 ( |, &, ^, - )
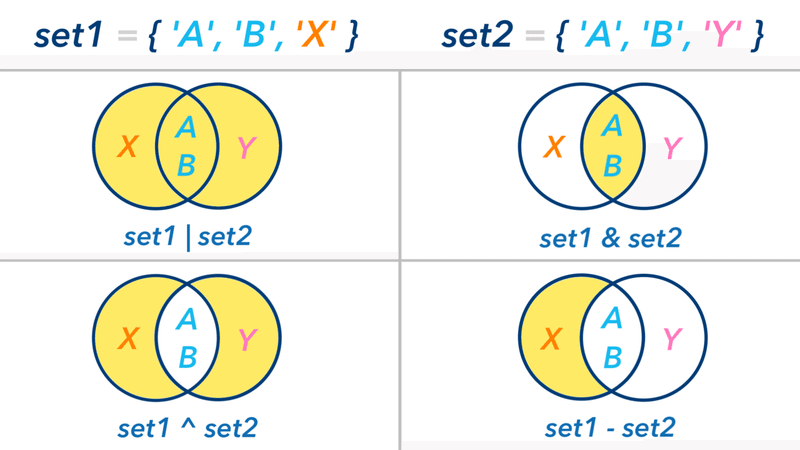
set型に使える演算子
演算子(operator)の記事で
集合演算子(set_operator)について紹介しましたが、
改めてキチンと説明したいと思います。
和集合 ( set1 | set2 )
「 和集合 ( わ-しゅうごう ) 」とは、
集合① と 集合② を 合体させた集合 です。
set1 = {"A","B","X"}
set2 = {"A","B","Y"}
print(set1 | set2)
# >>> {'Y', 'X', 'B', 'A'}カブった値は消えていますし、
順序も保たれていません。
2つの集合を合体させて、カブった値を消している
と捉えると分かりやすいですね。
積集合 ( set1 & set2 )
「 積集合 ( せき-しゅうごう ) 」とは、
集合① と 集合② との間で 共通する値の集合 です。
set1 = {"A","B","X"}
set2 = {"A","B","Y"}
print(set1 & set2)
# >>> {'B', 'A'}2つの集合を合体させて、
共通している値だけの集合をつくり、
カブった値を消している
と捉えると分かりやすいですね。
排他的論理和 ( set1 ^ set2 )
「 排他的論理和 ( はいた-てき-ろんり-わ ) 」とは、
集合① と 集合② を比べて、共通していない値の集合 です。
set1 = {"A","B","X"}
set2 = {"A","B","Y"}
print(set1 ^ set2)
# >>> {'X', 'Y'}「共通していない値の集合」ってことは
「カブってない値しか集まらない」って事なので、
集合を作った時に
カブった値を消す必要はないですね。
差集合 ( set1 - set2 )
「 差集合 ( さ-しゅうごう ) 」とは、
集合① と 集合② を比べた時に共通している値を
集合① から取り除いた集合 です。
set1 = {"A","B","X"}
set2 = {"A","B","Y"}
print(set1 - set2)
# >>> {'X'}ちょっと難しく書いてますけど、
やってる事は引き算と同じなので
分かりやすいですね。
ただし、「 set2 - set1 」 と書くと
「 {'Y'} 」という集合が出来上がります。
どちらの集合を先に書くべきなのかだけは
ちゃんと考えましょう。
月咬式の覚え方
別に参考にしなくていいですが、
月咬はこのようなイメージで集合演算子を覚えています。
● 和集合 ( | )
= 心の友というイメージ。
別に自分は好きではない趣味の部分も含めて
お互いの事を認め合っている仲の人
というイメージを持っている。

「 | 」に該当するわけですよ。
ここに全部で何人いるかを数える時に
おっぱい派 | おしり派
👆このように複数の集合を
「ひとまとまりの集合」と捉えているのが
和集合 だよと覚えています。
おしり好きだけど
おっぱいに興味ないって人はおらんだろ。
● 積集合 ( & )
= 趣味が合うものだけで繋がっている
ヲタク友達というイメージ。
元々「○○ & △△ 」は
「 ○○ と △△」という意味ですから、
○○ と △△ 両者に共通するもの
ってことで、
特に覚える為に苦労はしないでしょう。
自分が好きじゃない趣味について話されると
何も喋ることができないが、
自分も好きな趣味(共通の趣味)の事となると
「堰(セキ)を切ったように喋り出すヲタク」
それが「積(セキ)集合」と覚えています。
● 排他的論理和 ( ^ )
= 同担拒否の厄介ヲタクのイメージ。
同じアイドルを推してる人とは仲が悪くなる。
嫉妬がすごい。だから「排他的」なわけだ。
また、マニアックなものやマイナーなものが好きで、
自分にしか良さが分からないものだけを求めている。
推してた人がメジャーになってしまうと興味がなくなる。
そんなイメージ。

● 差集合 ( - )
= 相手の隠している趣味を
探ろうとしている人のイメージ。
減算の演算子と同じなので
覚えるのには困らないと思いますけれど、
一応書いておきます。
あなたの身近にいる誰かの事をイメージしてください。
お互い趣味が合って仲良くしているけれど、
自分が知らないその人の隠れた趣味ってものが
あるんじゃないだろうか?
...って考えた時、
自然と差集合的な
考え方をしているのですよ。
集合演算子は
比較演算子や論理演算子とは異なります。
if 条件式① and 条件式②:
👆論理演算子である and( 論理積 ) と混同して
if 条件式① & 条件式②:
👆 このように書かないように注意しましょう。
次の記事へ。
この記事が気に入ったらサポートをしてみませんか?