
財務分析に欠かせない、XBRLを読む: タクソノミ文書編

本記事ではXBRLのデータをタクソノミ文書の定義を利用し読み取ります。インスタンス文書編では、情報を取得するのに事前にタグ名などを知っている必要がありました。文書の構造を定義するタクソノミ文書を使用することで、文書構造(財務諸表だと勘定の体系など)に基づいた情報抽出、情報整理が可能です。
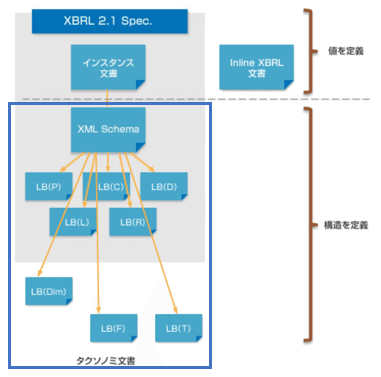
XBRL文書の構成
本記事では、以下の流れで解説を行っていきます。
タクソノミ文書の構造
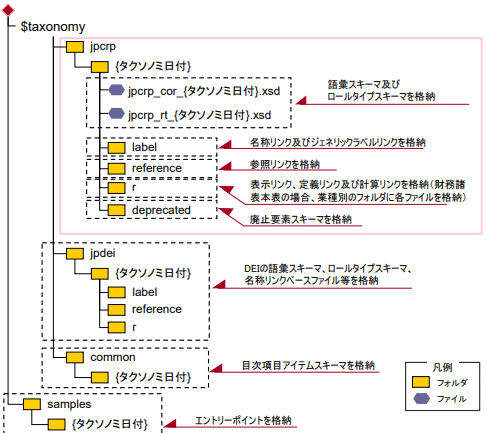
「提出者別タクソノミ作成ガイドライン 図表 2–1–18 EDINET タクソノミのフォルダ構成(1)」より引用
語彙スキーマ
文書で使うタグの定義などを行っています(要素名、貸借区分など)。
代替グループ(substitutionGroup)の設定を見ることで、目次項目(identifierItem)かどうか判別可能です。
ロールタイプスキーマ
文書で使うリンク(拡張リンクロール)の定義を行います。
名称リンク
タグと名前のリンクを定義します。
参照リンク
法令や内閣府令規則、業法等の根拠となる条文へのリンクを定義します。
表示リンク
文書の目次である「様式ツリー」、目次内の詳細構造を定義する「詳細ツリー」を定義します。
定義リンク
ディメンション、勘定の構造を表す「科目一覧ツリー」、文書情報を表すDEI のツリーを定義します。
計算リンク
科目間の計算関係を定義します。
図中では”jpcrp”のみですが、これ以外にもたくさんあります。2019年度のタクソノミは、以下のようにたくさんの定義があります。

2019年度のタクソノミ文書一覧
タクソノミ文書、それに含まれるスキーマ定義などは以下のように命名規則が決まっています(EDINETタクソノミの設定規約書より)。

「EDINETタクソノミの設定規約書 図表3–2–1 語彙スキーマ」より引用
“jpcrp”なら”crp”が府令略号で、「企業内容等の開示に関する内閣府令」に相当します。以下が府令と報告書の略号(コード)です。
府令略号
報告書略号
jpcrp-esrなら「企業内容等の開示に関する内閣府令」に基づく「臨時報告書」のタクソノミ文書となります。EDINETで公開されている文書は基本的に「府令」・「勘定」・「文書定義(DEI)」の3種で構成されるため、決算書分析では以下のタクソノミを押さえておけばとりあえず問題ないと思います。
府令: jpcrp
jpcrpは「企業内容等の開示に関する内閣府令」のタクソノミです。これは、有価証券報告書などの提出根拠となる府令です。
勘定: jppfs , jpigp
jppfs は日本基準の勘定科目、jpigp は国際会計基準(IFRS)の勘定科目を定義するタクソノミです。
文書定義: jpdei
提出文書のメタデータ(提出日付やタイトルなど)を定義するタクソノミです。
提出者のタクソノミ定義(xsdファイル)を見れば、どんなタクソノミを使っているか判別できます。特に勘定は日本基準かIFRSかを事前に知ることが難しいため、スキーマファイルからたどるとよいと思います(ここからXPathの処理に必要なnamespaceも取れます)。

「提出者別タクソノミ作成ガイドライン 図表4–1–1」より引用
タクソノミの構造についての解説は以上です。では、実際にタクソノミ文書を使用して情報抽出を行ってみましょう。
タクソノミを活用した情報抽出
タクソノミ文書で最初に注目すべきなのは、リンクの情報です。そもそも報告書を作る際も、まず最初に使用するリンクを選択します。以下の「様式ツリー」は、文書の目次を定義する表示リンクです。

「提出者別タクソノミ作成ガイドライン 図表 3–1–1」より引用。
リンクの情報が記載されているのは、表示リンクファイル(_pre.xml)と定義リンクファイル(_def.xml )です。2つのファイルの関係を表したものが、以下の図になります。

「提出者別タクソノミ作成ガイドライン 図表 2–1–5/2–1–6」より引用。
表示リンクは、定義リンクを参照する形で作成されます(上記の「関連付け」)。定義リンクの必要な箇所をコピー(ミラー)して表示リンクを作成するイメージです。なんにせよ、表示リンクに文書全体の構造が定義されていると思って頂いて良いです。
では、表示リンクの情報を取得してみましょう。実装は以下になります。
まず、インスタンス文書で使用されている表示リンクを一覧表示してみます。これは、link:roleRef を見てみればわかります。
実行結果は以下のようになります。

インスタンス文書で使用されているリンクの一覧
このうち、メインどころの「貸借対照表」を読んでみます。表示リンク定義(.pre)ファイルではツリー構造で階層が定義されています。 arc 系のタグはparent/childを、link:loc はリンクされる要素を定義します。表示リンクに限らず、他のリンク系ファイルも大体この通りに定義されています。 arc を読んでからリンク先の要素をたどる必要があるので、ちょっと面倒です。
実装では、ツリー構造を扱うために Nodeというクラスを作成しています。とはいえ、ツリー構造のままではデータとして扱いずらいので、テーブル型に落としてみます。以下が、親をカラムにして展開した表になります。

ツリー構造のテーブル化
この表には科目の名前がついています。名前は名称リンクから取得しています。リンクを使用することで、名称をはじめとしてインスタンス文書からだけではわからない定義情報を取得することができます。その方法について、次のセクションで見ていきましょう。
タクソノミを活用した情報抽出: 定義情報の取得
XBRL中のタグは、名称空間も合わせた完全名称を持っています(イメージ的には、絶対パスに相当します)。例えば、以下のような名称です。
http://disclosure.edinet-fsa.go.jp/taxonomy/jppfs/2018-02-28/jppfs_cor_2018-02-28.xsd#jppfs_cor_BalanceSheetHeading
これが、各種リンクをたどる時の手掛かりになります。大半は定義の大本であるxsd ファイルへのリンクになっています。この完全名称を通じて、様々なリンクファイル(名称リンク、定義リンクなど)から情報を取得できます。例えば、名称リンクは以下のようになっています。
<link:loc xlink:type="locator"
xlink:href="../jppfs_cor_2018-02-28.xsd#jppfs_cor_TreasuryStockMember"
xlink:label="TreasuryStockMember"/>
<link:label xlink:type="resource"
xlink:label="label_TreasuryStockMember"
xlink:role="http://www.xbrl.org/2003/role/label"
xml:lang="ja" id="label_TreasuryStockMember">
自己株式
</link:label>
<link:labelArc xlink:type="arc" xlink:arcrole="http://www.xbrl.org/2003/arcrole/concept-label" xlink:from="TreasuryStockMember" xlink:to="label_TreasuryStockMember"/>link:loc が要素の定義です。この要素の xlink:href を見ることで、完全名称からこの要素にたどり着けます(御覧の通り相対パスに変換しないといけないですが・・・)。
link:loc にたどり着けると、完全名称のこのファイル内での別名xlink:label が取得できます。xlink:fromが別名と等しいlink:labelArc を探し、link:labelArcの xlink:to が指し示す link:label を取得する、という流れになります。
名称は日本語・英語以外に一般名称?(要は英語?)があり、それごとにファイルが分かれています(ファイルの末尾が、英語は lab-en.xml、一般名称は lab-gla.xmlになっています)。参照先ファイルを切り替えることで、取得する名称を切り替えることができます。
これで、タクソノミ文書の定義が取得できました。この定義にのっとり、インスタンス文書から情報を抽出してみましょう。
タクソノミを活用した情報抽出: インスタンス文書からの情報取得
タクソノミという文書定義から情報を抽出することで、必要な情報のタグ名をいちいち調べる手間から解放されます。早速、抽出してみましょう。定義(data)のうち、実際インスタンス文書に値があるものを取得して xbrl_data に格納していきます。
ちなみに、表示リンクに定義されているけどインスタンス文書に値がないものは結構あります。「拡張」リンクロールという仕様上、足りなければ追加をするけれど必要ないものをあえて削除したりしないためと思います(提出者別タクソノミ 作成ガイドライン 3–3 拡張リンクロールの選択と決定)。
値に加えて、インスタンス文書編で学んだコンテキスト情報(時期や単位)を付与することで、以下のように集計できます。

タクソノミをもとにインスタンス文書から読み込んだ値を集計した表
実際の文書と近い形でデータが取れていることがわかります。
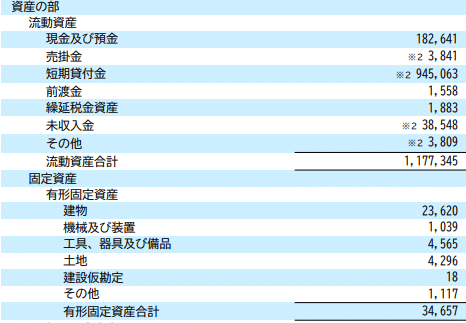
実際のデータ
合計項目が含まれているため、これがいらないという場合は計算方法を定義している .cal ファイルを見る必要があります(面倒ですが・・・)。
いずれにしても、タクソノミ文書を使用することで要素の構造や定義に基づいた情報抽出ができました。次回は、読み取ったデータの可視化かより細かいデータの取得についてみていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?