
財務分析に欠かせない、XBRLを読む: インスタンス文書編

XBRLは「インスタンス文書」と「タクソノミ文書」から構成されます。
インスタンス文書
文書本体。タクソノミ文書の定義に従って書かれる。
タクソノミ文書
記載すべき項目や、項目間の構造の定義。
詳細は「財務分析に欠かせない、XBRLの構造を理解する」を参照
本編ではインスタンス文書をPythonプログラムで読む方法を解説します。なお、タクソノミ文書を使用すると「書かれている内容」からでなく「書かれるべき内容」から文書を読むトップダウン的な読み込みが可能です。これは定型書式がある財務諸表を読むにはとても強力な機能です。タクソノミ文書を使用した文書の読み込みは、別の記事で解説したいと思います。
インスタンス文書の実体は.xbrlファイルになります。報告書インスタンス作成ガイドラインの流れに沿い、以下の順で読み込み方法を解説します。
要素の読み取り
実際にXBRLから要素の値を読んでみましょう。手始めに、会社名を読んでみます。

会社名を取得するには、XBRL上で会社名がどう記述されているかを知る必要があります。これを知るには、XBRLで使用されている語彙を定義してるタクソノミ文書を参照する必要があります。
実際のタクソノミ文書は.xsdファイルですが、人間に見やすい形式(Excel)でも公開されています。以下は、2018年度の報告に使用されるタクソノミです。”タクソノミ要素リスト”からExcelがダウンロードできます。
タクソノミの定義は様式ごとに分かれています。年次報告書に使われる様式は第三号様式が主なので、第三号様式を見てみます。これを見ると、表紙の会社名は名称空間 jpcrp_cor の CompanyNameCoverPage という要素名だとわかります。
実際にこのタグを指定して抽出すると、値が取れていることがわかります。

なお報告様式自体も、タグを指定して取得可能です。提出処理に関する情報の定義はDEI(Document and Entity Information)タクソノミと呼ばれます。

実装はこちらになります。
コンテキストの読み取り
要素の値だけではそれがいつの値か、どんな単位かわかりません。そこで、コンテキストの読み取りを行います。 連結経営指標上の売上高であるjpcrp_cor:NetSalesSummaryOfBusinessResults のコンテキスト情報を見てみます。
<jpcrp_cor:NetSalesSummaryOfBusinessResults
contextRef="Prior4YearDuration"
unitRef="JPY"
decimals="-6">
2455249000000
</jpcrp_cor:NetSalesSummaryOfBusinessResults>contextRef が Prior4YearDuration となっています。コンテキストのタグであるxbrli:context からidがPrior4YearDuration であるものを探すと、以下のように定義されています。
<xbrli:context id="Prior4YearDuration">
<xbrli:entity>
<xbrli:identifier scheme="http://disclosure.edinet-fsa.go.jp">E22559-000</xbrli:identifier>
</xbrli:entity>
<xbrli:period>
<xbrli:startDate>2014-01-01</xbrli:startDate>
<xbrli:endDate>2014-12-31</xbrli:endDate>
</xbrli:period>
</xbrli:context>コンテキストの定義から以下のことがわかります。
・2014/1/1から2014/12/31までの値(報告年が2018年度なので=4年前)
コンテキストの名前付けにはルールがあります。「報告書インスタンスの作成: 5–4 コンテキストの定義」に詳細なルールが記載されています。このルールから、コンテキストのidのみからでも属性の推定が可能です。
idにNonConsolidatedMemberがつく場合は個別決算で、それ以外は連結になります。Prior4YearDurationも、個別決算用にPrior4YearDuration_NonConsolidatedMemberというコンテキストが別に存在します(同上の「5–4–1 コンテキスト ID の命名規約」より)。
period の種類は、期間(startData/ endData)と時点(instant)の2種類があります(同上の「5–4–4 期間時点要素の設定」より)。
contextRefと同様に、unitRef から単位の情報が取得可能です。ただ、プラスマイナスの符号(sign)や表示単位(scale)は単位の情報には含まれず、タグに直接属性として書かれています。

「報告書インスタンス作成ガイドライン 図表 5–6–7」より引用
要素の値とコンテキストの情報双方を読み取ることで、以下のように時系列の値を取得できます。

実装はこちらになります。
ディメンジョンの読み取り
ディメンジョンは表の「軸」を表します。「軸」は横軸か縦軸かのどちらかです。以下はディメンジョンが横軸、各行要素が「表示項目」の例です。
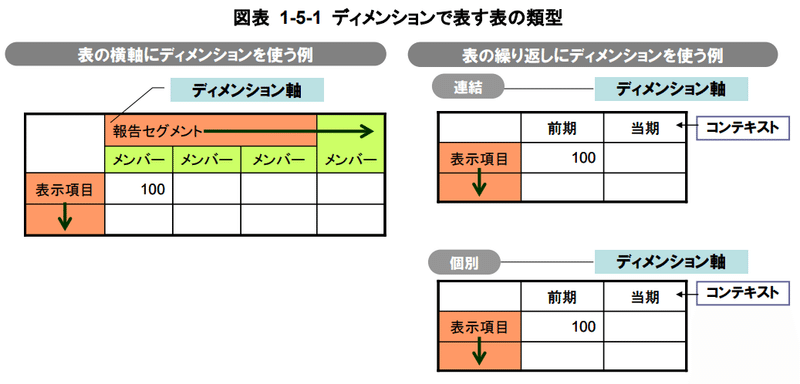
「EDINETタクソノミの概要説明 図表1–5–1」より引用
ディメンジョンが横軸の例
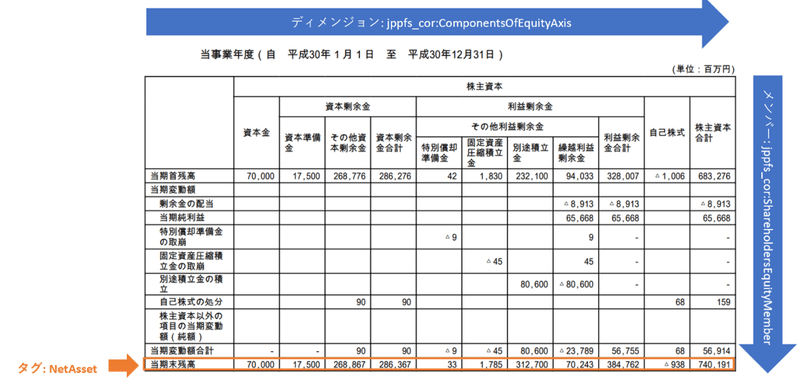
株主資本変動計算書(サントリーHD 有価証券報告書-第10期(平成30年1月1日-平成30年12月31日)より)
ディメンジョンが横軸のケースを見てみましょう。以下のタグは、要素が jppfs_cor:NetAssets(純資産)で、コンテキストとして CurrentYearInstant_NonConsolidatedMember_ShareholderEquityMemberが設定されています。
<jppfs_cor:NetAssets
contextRef="CurrentYearInstant_NonConsolidatedMember_ShareholdersEquityMember"
unitRef="JPY" decimals="-6">
740191000000
</jppfs_cor:NetAssets>CurrentYearInstant_NonConsolidatedMember_ShareholderEquityMember には、以下のようにディメンジョンが設定されています。
<xbrli:context
id="CurrentYearInstant_NonConsolidatedMember_ShareholdersEquityMember">
<xbrli:entity>
<xbrli:identifier scheme="http://disclosure.edinet-fsa.go.jp">
E22559-000
</xbrli:identifier>
</xbrli:entity>
<xbrli:period>
<xbrli:instant>2018-12-31</xbrli:instant>
</xbrli:period>
<xbrli:scenario>
<xbrldi:explicitMember
dimension="jppfs_cor:ConsolidatedOrNonConsolidatedAxis">
jppfs_cor:NonConsolidatedMember
</xbrldi:explicitMember>
<xbrldi:explicitMember
dimension="jppfs_cor:ComponentsOfEquityAxis">
jppfs_cor:ShareholdersEquityMember
</xbrldi:explicitMember>
</xbrli:scenario>
</xbrli:context>ディメンジョンはシナリオ(scenario)で定義されています。ディメンジョンとして定義されているのは以下2つです。
1. 軸 jppfs_cor:ConsolidatedOrNonConsolidatedAxis のメンバー jppfs_cor:NonConsolidatedMember である。
2. 軸jppfs_cor:ComponentsOfEquityAxis のメンバーjppfs_cor:ShareholdersEquityMember である。
1のjppfs_cor:ConsolidatedOrNonConsolidatedAxis は連結/個別を表すための特殊な軸です(表の繰り返しにディメンションを使う例に相当します)。個別財務諸表に含まれる要素には、メンバーとして NonConsolidatedMemberを指定します(報告書インスタンス作成ガイドライン 5–4–5–1より)。このタイプは実際に軸としては表示されません。
2は実際に軸として現れます。タグの値 740191000000は、jppfs_cor:ComponentsOfEquityAxis =株主資本の内訳を表す軸の、jppfs_cor:ShareholdersEquityMember =株主資本の値、と解釈できます。
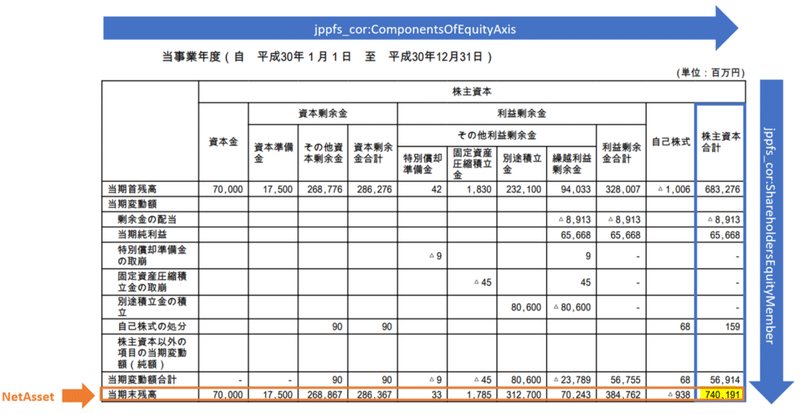
株主資本変動計算書(サントリーHD 有価証券報告書-第10期(平成30年1月1日-平成30年12月31日)より)再掲
では、軸(Axis)に沿って各列(Member)の値を抽出してみましょう。同じ軸が設定されたコンテキストを取得し、そのメンバー定義からメンバー、コンテキストが設定されたタグから値を取得します。軸(ディメンジョン)はコンテキストの子要素なので、子要素の値を指定して選択を行うことになります。これにはXPathを使うと便利です。

XPathを使用し、dimensionを指定してcontextを抽出
最終的に、以下のように値が取れます。右側の value が、上図の最下行の値と対応していることがわかると思います。
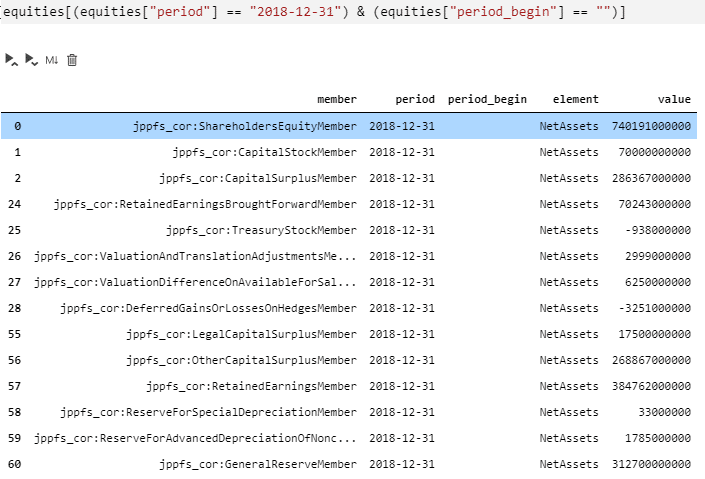
実装は以下になります。
ディメンジョンが縦軸の例

役員ごとの報酬の総額等(株式会社NTTドコモ(有価証券報告書-第28期(平成30年4月1日-平成31年3月31日)より)
ディメンジョンが縦軸の場合は、横軸と逆になります(当然ですが)。こちらもディメンジョンが同一のコンテキスト、コンテキストのメンバー、コンテキストが付与されたタグの値、という流れで値の取得が可能です。以下が実際に取得した結果ですが、右端の値が上図の値に一致していることがわかります。

役員報酬の値の取得
実装は以下になります。
ただ、タグの名前だけでは何の値なのかわかりにくいです。テキストのラベルを付けるには、Part3で扱うタクソノミ文書の情報が必要です。
注釈の読み取り
文書や数値に対しては、注釈をつけることができます(以下の※2や※7など)。
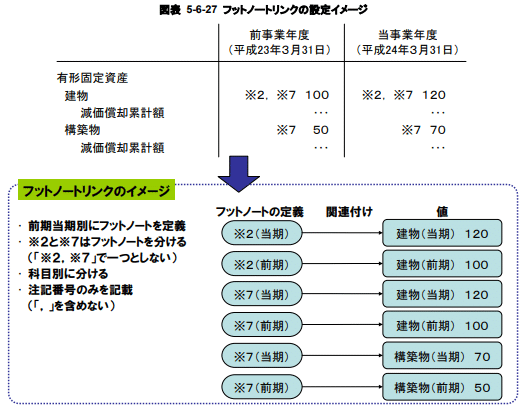
「報告書インスタンス作成ガイドライン 図表 5–6–27」より引用
注釈される側にはidをつけておきます(以下の場合、 3841000000 という数値にIdFact77552275を付与)。
<jppfs_cor:AccountsReceivableTrade
id="IdFact775522775"
contextRef="Prior1YearInstant_NonConsolidatedMember"
unitRef="JPY" decimals="-6">
3841000000
</jppfs_cor:AccountsReceivableTrade>注釈は以下のように定義します。値「3841000000」と注釈「※2」とが、 link:locで結びついていることがわかります。
<link:footnoteLink xlink:role="http://disclosure.edinet-fsa.go.jp/role/jppfs/rol_BalanceSheet" xlink:type="extended">
<link:footnote xlink:label="footnote" xlink:role="http://disclosure.edinet-fsa.go.jp/role/jppfs/role/NotesNumber" xlink:type="resource" xml:lang="ja">
※2
</link:footnote>
<link:loc xlink:label="fact" xlink:type="locator"
xlink:href="#IdFact775522775"/>
<link:footnoteArc xlink:from="fact" xlink:to="footnote" xlink:type="arc" xlink:arcrole="http://www.xbrl.org/2003/arcrole/fact-footnote"/>
</link:footnoteLink>ただ、「※2」の注釈に何が書かれているのか?はわかりません(!?)。※2がどうなっているかというと・・・

何のタグ付けもされずに浮いています。会計注記は Notes から始まるタグで定義されるので、注記のタグを全部洗ってその中にある番号を探して対応を取れば何とかなるかもしれません(苦行)。ただ、会計注記の番号は以下のように使いまわしがあるのでコンテキストを加味する必要もあります。

会計注記は勘定の明細などが書かれている重要な情報ですので、簡単に取れるようにしてほしいところです。
以上が、インスタンス文書からの情報抽出になります。インスタンス文書のみでは、情報を抽出するタグを事前に把握している必要があったり、抽出してもタグの名称がわからないといった課題がありました。どんな情報を記載すべきか、またタグの名称は何なのかはタクソノミ文書に記載されています。次回はこのタクソノミ文書を使って情報を抽出する処理を紹介します。
この記事が気に入ったらサポートをしてみませんか?