
創作に用いられる生成モデル発展の4段階と、ChatGPTに見る現在と今後

ChatGPTやStable Diffusionを代表として、知性や経験を持つ人間かのように画像やテキストを生成する「生成モデル」が注目されています。Gartnerの2022年のレポートでは、これまで人間が経験や思考に基づき行っていたアウトプットを、それらなしに生成できる破壊的なテクノロジーと定義されています。本記事では、こうした創作に用いられる生成モデルの発展を4段階で定義し、ChatGPTを先端とし現在と今後の在り方を展望します。
創作に用いられる生成モデルの発展段階
本記事では、Gartnerが提唱するような人間の創作を模倣する用途で使われる生成モデルについて議論します。人間がアウトプットを行うプロセスを次図のように企画、調査、設計、制作、推敲の5段階で定義します。

「制作」から「推敲」に使える生成モデルを1.0、「設計」から「制作」、場合によって推敲まで使える生成モデルを2.0と定義します。3.0は「調査」から、4.0は「企画」からになります。いくつかの検証から、ChatGPTやStable Diffusion は単純なテキスト/画像の生成に留まらず3.0、4.0に相当する能力があるとみています。次節より1.0から順にみていきます。
生成モデル 1.0: 変換
生成モデル1.0は、付加価値を付与する「変換」を行います。pix2pixは画像の変換を行う代表的な手法で、論文のタイトルはまさに「Image-to-Image Translation with Conditional Adversarial Nets」です。

pix2pixを応用した自動着色を試した方もいるかもしれません。下書きの絵に色という付加価値を付与しています。
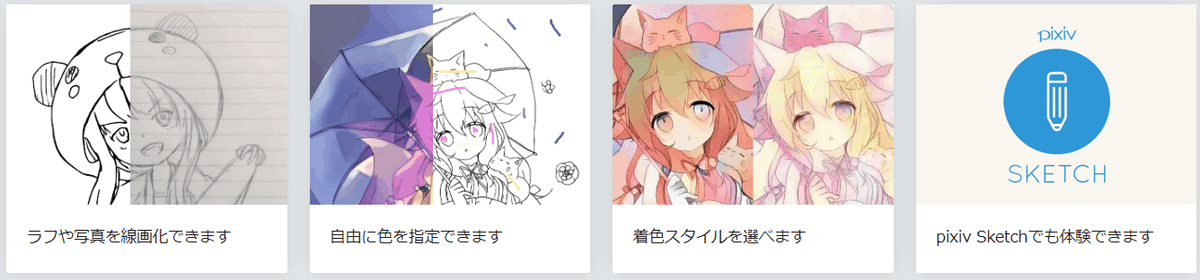
翻訳はテキスト変換の代表例です。元の文書に他の言語でも読める付加価値を付与します。生成モデル1.0は入力に対して「付加」価値を与えるもので、価値自体を作り出すことはありません。イラストに着色はしてもイラスト自体は描かないですし、翻訳しても文自体を生成することはありません。
生成モデル 2.0: 生成
生成モデル2.0は、設計から価値を生成します。次の画像は、Stable Diffusion 2.1 というモデルに「the japanese kemono with the umbrella」という自然言語による「設計」を入力した結果得られた画像です。

技術的かつ画像的に怖いですが、たった1フレーズの設計から概ね意図に沿った画像を生成しています。真っ白なキャンバスにゼロからこの画像を描画するのは大変です。どのような「設計」が良い「制作」、「推敲」に繋がるのか日夜呪文が編み出されています。「Stable Diffusion入門-美少女アニメ画」によれば、次の呪文によりイラストレーターが描いたようなイラストを生成できます。
japanese anime of a beaultiful girl,
fantasy costume,
fantasy background,
beautiful composition,
cinematic lighting,
pixiv,
light novel,
digital painting,
extremely detailed,
sharp focus,
ray tracing,
8k,
cinematic postprocessing

次の例は、You.comのYouChatに実装されている対話型の機械学習モデルです。「Write Python code to read the csv file」と入力するだけで、Pythonのコードが実際に生成されました。

生成モデル2.0は、付加価値を付与するベースとなる「制作」が必要な1.0と異なり、わずかな「設計」から「制作」を行うことができます。場合によってはすでに「推敲」が済んでいるかのような出力ができます。仮に不十分でも、1.0と組み合わせることで設計から推敲までの工程の補助、自動化が期待できます。
生成モデル2.0を可能にした技術
生成モデル2.0はなぜこんなことが可能なのでしょう? これは完全にやっちゃってる、錬金術における等価交換の原則を無視していると感じないでしょうか?(私は感じます)。鋼の錬金術師で「賢者の石」が原則を無視した交換を内在する人間の魂により補填していたように、近年の生成モデルは「大規模な事前学習済みモデル」に内在するパラメーターの重みが原則を無視した交換を可能にしています。人間が(心身を賭して)制作・推敲したデータを学習して生み出されると見るならば、ある意味まんま魂を内在した賢者の石ということもできるかもしれません。
「大規模」とはどれぐらいでしょうか。厳密な境界線は明確ではありませんが、100億~1000億の間ぐらいに境界線がありそうです。110億パラメータのGoogleのT5では論文中に"we focus on transfer learning rather than zero-shot learning"との記述がある点、172億パラメーターのMicrosoftのTuring-NLPではzero-shotに言及しているもののまだ転移学習が前提に読めるためです。
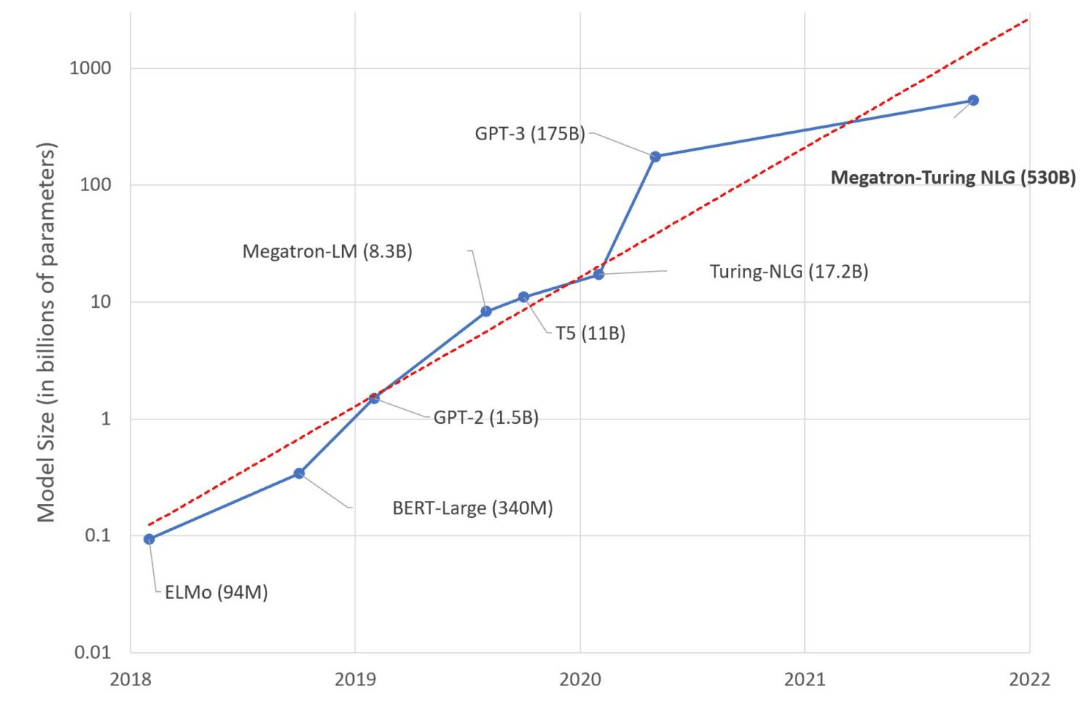
GPT-3をはじめとした1000億パラメーターを超える大規模な事前学習済みモデルは、転移学習をすることなく入力(プロンプト)を変えることで所望のタスクの回答を得られる性質があります。次の図はGPT-3の論文から引用しています。"Translate English to French: cheese=>"と指示することでチーズのフランス語訳を出力させています。通常は翻訳というタスクに特化するため英語/フランス語のコーパスを使った転移学習が必要にもかかわらずです。

テキストからの画像生成も、事前学習したモデルを利用しています。OpenAIのCLIPは、テキストと画像のペアを対応させるよう学習します。これにより画像に意味づけられたテキスト表現を得ることができます。

OpenAIのDALL-EはCLIPの「画像に意味づけられたテキストの表現」が得られるEncoderを使用し画像を生成しています。Stable DiffusionもCLIPのEncoderを使用しています。今後もCLIPに代わる事前学習の方法や、DALLE-E/Stable Diffusionで使用されているDiffusion Modelに代わる生成手法が発表されると思います。

生成モデル3.0: 比較
生成モデル3.0は「調査」から開始するためアウトプットを「比較」できる必要があります。調査は、一定範囲の情報を収集しその中から比較のうえよりよいものを選ぶのが一つのゴールであるためです。例えば、キャラクターは同じでスタイルを変えて比較する、スタイルは同じでキャラクターを変えて比較する、などです。コンテンツを維持してスタイルを変換する試みは生成モデル1.0の時点でStyle Transferとして取り組まれていました。そのため、同様の発展をする可能性はあると考えています。生成モデル3.0で使用される2.0は、渡された「設計」のうち何がコンテンツを指示していて、何がスタイルを指示しているのか、識別できるようになる必要があるでしょう。
ChatGPTは生成モデル3.0に欠かせないスタイルの維持ができるでしょうか。次の会話は、「猫のようにふるまってください」という指示のあと後続の会話でも(苦しいところもありつつ)ちゃんと「にゃん」をつけています。

「犬のようにふるまってください」とスタイルを変えると、同じ指示に対して異なるスタイルで応答します。

同じテキストであっても、スタイルを変えることでどのように見えるか「比較」することができます。その意味では、生成モデル3.0の性質を帯びているといえます。Stable Diffusionも、先ほど紹介した呪文の中に「pixiv」「8k」などが含まれていたように、特定の単語を指定することでスタイルをキープできる性質があるように見えます。
生成モデル4.0: 創作
生成モデル4.0は「企画」を含むため自然言語による指示を受け付けられる必要があるでしょう。企画はターゲットと課題を含むと考えられます。例えば「夜遅くオフィスから電車で帰る小腹が空いている人に、駅中の蕎麦屋に立ち寄ってもらうための広告ポスター(とコピー)」とかでしょうか。これを入力したらいくつかそのまま使えそうなバリエーションが出てきて修正すればOKとなったら・・・すごいですね。企画はふわふわしているので、対話で明確にするようなインタフェースになるのではないかと考えました。なので、ChatGPT+生成モデル3.0のような感じになるのではないかと思います。
ChatGPTは4.0のターゲットと課題から創作する性質をもつでしょうか。さきほどの企画案をそのまま入れてみると、現時点のChatGPTに入れてもそれなりの答えを返してくれました。これはかなり驚きました。ただ、「犬のようにふるまってください。」というスタイルは無視されました。
他のでも試してみましたが、ちゃんと創作してきました。
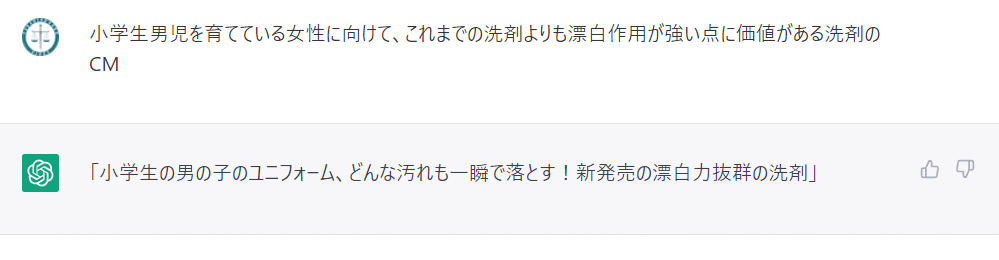
コピーとしては一般的で、本職の方からすると「推敲」が必要なレベルかもしれません。ただ、それは1.0を組み合わせればより高めることができると思います。
創作に用いられる生成モデルの今後の発展
人間の創作活動を支えている既存のツールにアドオンされる形で、生成モデルが組み込まれていくと考えています。Adobeはすでにその取り組みを始めています。設計からの制作を可能にした生成モデル2.0が、アプリケーションへの組み込みにとって大きなマイルストンだったと考えています。それまでは、仮にツールに実装されても目的に応じた用途で使うにはユーザーがFine Tuningする必要があり、GANなど安定した学習が難しいモデルの場合Fine Tuningが上手くいくかはお祈りモードだったためです。生成モデル2.0は、入力文を変えることで出力をコントロールすることができます。
BtoBとして企業が自前で生成モデルの活用を始めるかは予測がつきません。Grand View Researchのレポートによれば、米国において2021年80億ドル規模のGenerative AI市場は、2022年から2030年まで年平均成長率34.4%で推移すると予想されています。自前かどうかは別として、活用自体は進むと見られています。

この中で、生成モデルが活用される市場は、Media & Entertainment、Automotive & Transportation、IT & Telecommunication、Healthcase、BFSI(=Banking, financial services and insurance)、と予想されています。

こうした業界で生成モデルがどのように業務を変えるのか、は別の記事で検討していきたいと思います。AWSではプロダクトで機械学習を活用するためのワークショップを実施しており、資料をすべてGitHubで公開しています。生成モデルのプロダクトへの活用についても現在検討を進めており、資料の更新が気になる方はぜひリポジトリのWatchとStarを頂ければと思います。
BtoCとして個人の創作の量が増えることは間違いないと思います。今まで画力がなくて漫画が描けなかった人、ゲームが作れなかった人は一定品質のイラストなどを容易に得ることができます。生成モデル1.0はプロのため、2.0以降はアマチュアの裾野を広げてプロへの階段を上る人を増やすのに有用だと考えています。日本のようなアニメーションやゲームが盛んな国で、裾野を広げる技術が普及することでより面白い作品が生まれる土壌ができるとするなら、生成モデルは日本にとって大きなチャンスではないかと思います。
企業でも個人でも、生成モデルという革新的な技術がより良い仕事につながることを期待したいです。期待するだけでなく、AWSのDeveloper Relations Engineerとしてプロダクト開発チームの支援を通じ実現にむけて取り組んでいく所存です。
この記事が気に入ったらサポートをしてみませんか?