KarasuとQarasu:最先端の日本語LLMオープンソースチャットボット


このブログ記事では、最先端のオープンソース日本語LLMであるKarasuとQarasuを紹介します。
こちらでLightblueが公開している最も精度の高いQarasuを試してみてください!
ベースモデル
私たちは、2つのモデルをベースとして学習を実施しました。
1つ目はAugmxntが提供するShisa(augmxnt/shisa-7b-v1)モデルで、日本語MT-Benchベンチマークで高いパフォーマンスを示し、日本語特有のトークナイザーを持っているため、トークン化と推論が他のオープンソースモデルよりも何倍も効率的(そして速い)になるという特徴を持ちます。2つ目は同様に日本語MT-Benchベンチマークで非常に高いパフォーマンスを示すQwen(Qwen/Qwen-14B-Chat)モデルです。この2つをベースとした学習を実施しました。
非構造化トレーニングデータ
私たちは、主に非構造化された日本語テキストからなる約70億トークンを使ってShisaモデルをトレーニングしました。事前学習フェーズで使用するデータソースとして、以下を選択しました。
CulturaXの日本語サブセットの中で.lg.jp、.go.jp、.ac.jpドメインのウェブスクレイピングから取得したデータ
※モデルが既に学習した英語でのチャット能力を忘却しないように、Ultrachatデータセットを含めています。このフェーズでのトレーニングトークンに占める割合は10%未満でした。
70億パラメータのShisaを70億トークンでトレーニングするのに、Deepspeed(ステージ3設定)を活用し、16台のA100(40GB)GPUを搭載した1つのインスタンスで約60時間かかりました。使いやすさとDeepspeedのようなマルチGPUトレーニングフレームワークのサポートで知られるAxolotlを学習時のツールとして使用しました。
これにより、私たちは事前学習モデルであるKarasu-7Bを生成しました。
構造化トレーニングデータ
Augmxntがそのリポジトリで議論しているように、利用可能な多くの日本語ファインチューニングデータセット(例えばDolly)と比較して、英語や中国語のLLMをトレーニングする際には、より優れたデータセットが登場しています。これらを参考に、LLMの能力を向上させることができる独自のデータセットを作成することにしました。
データセットは以下の3つの基準で作成しました。
トピックの関連性 - 日本語話者(主に日本人)に関連するトピックを多く含むデータセットでトレーニングしたいと考えました。目視で確認すると、多くのオープンソースの日本語ファインチューニングデータセットには、米国やヨーロッパに関連するトピックのプロンプトと回答が含まれています。米国南部のジム・クロウ法に関するプロンプトは間違いなく重要なトピックですが、日本語話者の日常体験に近いデータでトレーニングする方が、より有用な日本語LLMにつながると仮定しました。したがって、より日本語話者に関連したトピックに焦点を当ててデータセットを作成しました。
言語の忠実度 - 多くのオープンソースの日本語ファインチューニングデータセットは、翻訳されたデータや翻訳タスクで構成されています。例えばHH-RLHF、Dolly、OASSTなどのデータセットは、英語から日本語に翻訳されたデータで大部分が構成されています。これらはしばしば奇妙な日本語を生み出すことがあります(例えば、ネイティブの日本語話者はプロンプトの始めに「私はあなたに」とはほとんど使わないでしょう)し、結果としてLLMの日本語能力を制限するかもしれません。したがって、私たちは翻訳なしでデータを生成し、できるだけ自然な日本語データセットを生成することを目指しました。
データ量- 日本語話者に関連し、日本語からネイティブに生成されたオープンソースのデータセットはデータ数が少ないです。例えばOASSTデータセットには48のネイティブな日本語の会話で構成されていますが、合計で363の往復メッセージしか含まれていません。このままトレーニングにこのデータを使用すると、多様なトピックをカバーできず、幅広い範囲を学習できないことを意味します。したがって、私たちは数十万サンプルのデータセットを生成するという目標を設定しました。
これらの基準で以下の3つのデータセットを生成しました。
RAGベースの質問応答データセット(約25万例)
カテゴリーベースのプロンプト応答データセット(約25万例)
Chain-of-Thought Orcaスタイルのデータセット(約4万例)
※これらのデータセットを公開する予定はございません。
またこれらを補完するべく以下のオープンソースデータセットを追加しました。
OASST(日本語の会話のみ)
ShareGPT(日本語の会話のみ)
Augmxnt(airoboros、slimorca、ultrafeedback、airoboros_ja_newのみ)
これらのデータセットは、学習に使用するものよりはるかに大きなパラメーターを持つLLMの出力を使用して生成されているため、プロンプト応答データセットの中の一部が回答を拒否するものでした。(例:申し訳ございませんが、LLMとしてその質問に対応できません)。これらの回答を拒否するものを含むパターンと含まないパターンで学習を実施し、拒否を含まないパターンで学習されたモデルは「unleashed」の接尾辞で示されます。
また、Chain-of-Thoughtデータセットを含むパターンと含まないパターンでの学習も実施しました。学習の結果。このデータセットはモデルの出力に大きな影響を与えないことがわかりました。Chain-of-Thoughtデータセットがトレーニングに含まれているモデルは、「plus」接尾辞で示されます。
合計して、私たちは上記のデータセットで事前学習されたKarasu-7Bをファインチューニングして、以下のモデルを作成しました。
karasu-7B-chat - オープンソースのデータセット + 質問応答データセット + プロンプト応答データセット
lightblue/karasu-7B-chat-plus - オープンソースのデータセット + 質問応答データセット + プロンプト応答データセット + Chain-of-Thoughtデータセット
lightblue/karasu-7B-chat-plus-unleashed - オープンソースのデータセット + 質問応答データセット + プロンプト応答データセット(回答拒否を除く)+ Chain-of-Thoughtデータセット
同様にQwen/Qwen-14B-Chatモデルをベースとしてファインチューニングを実施し、これらのモデルをQarasuと名付けました。
lightblue/qarasu-14B-chat-plus-unleashed - Qwenをオープンソースのデータセット + 質問応答データセット + プロンプト応答データセット(拒否応答を除く)+ Chain-of-Thoughtデータセットでトレーニングされたもの
評価
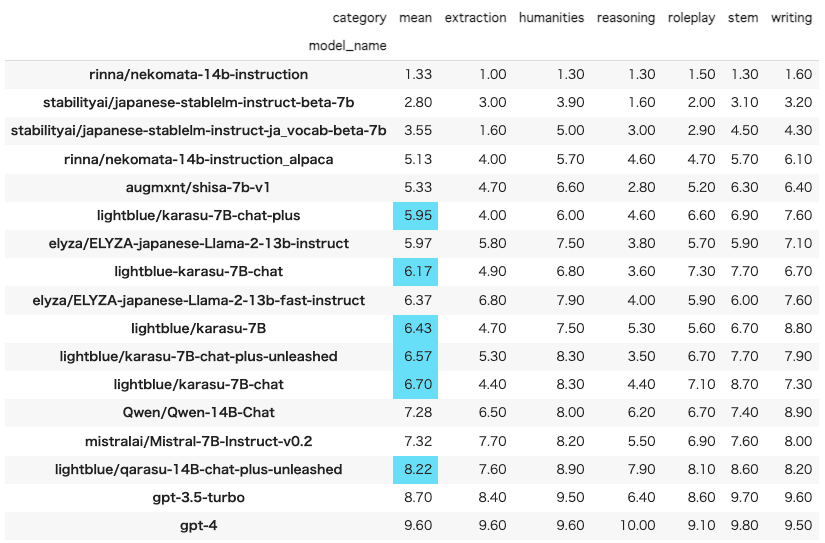
日本語 MT-Benchベンチマークで学習したモデルを評価し、最も人気のあるオープンソースおよびOpenAIモデルのいくつかとの比較を実施しました。
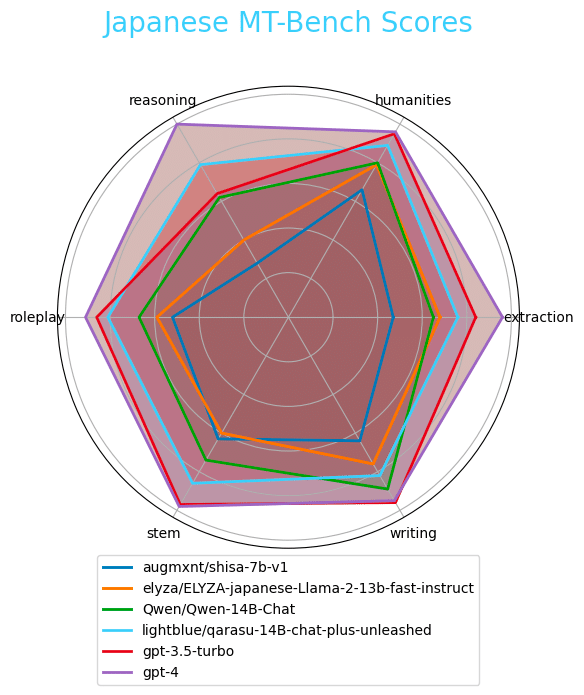
全結果:
LLMの実際の性能はこちらのデモ(https://lightblue-qarasu.serveo.net)からぜひお試しください!
開発チーム
このモデルは、東京にあるLightblue KKの自然言語処理チームによって作成されました。
このモデルの開発者に連絡を取りたい場合や質問がある場合は、peter [at] lightblue-tech.comまでPeter Devineにお気軽にご連絡ください。