
中国における生成AI普及の現状

はしがき
2023年9月27日に「自民党AIの進化と実装に関するプロジェクトチーム」による定期検討会が実施されました。
「中国における生成AI業界の現状と規制動向」が紹介されていましたので、気になった点をまとめていきたいと思います。
チップからモデルまで中国は国産できている
米国による高性能チップに輸出が制限されているため、国産チップを極力採用している
様々な企業や団体が競い合ってモデル、フレームワーク、チップの開発を行っている
データを抱えている企業や団体がそのデータ特性を活かしたモデルを開発している

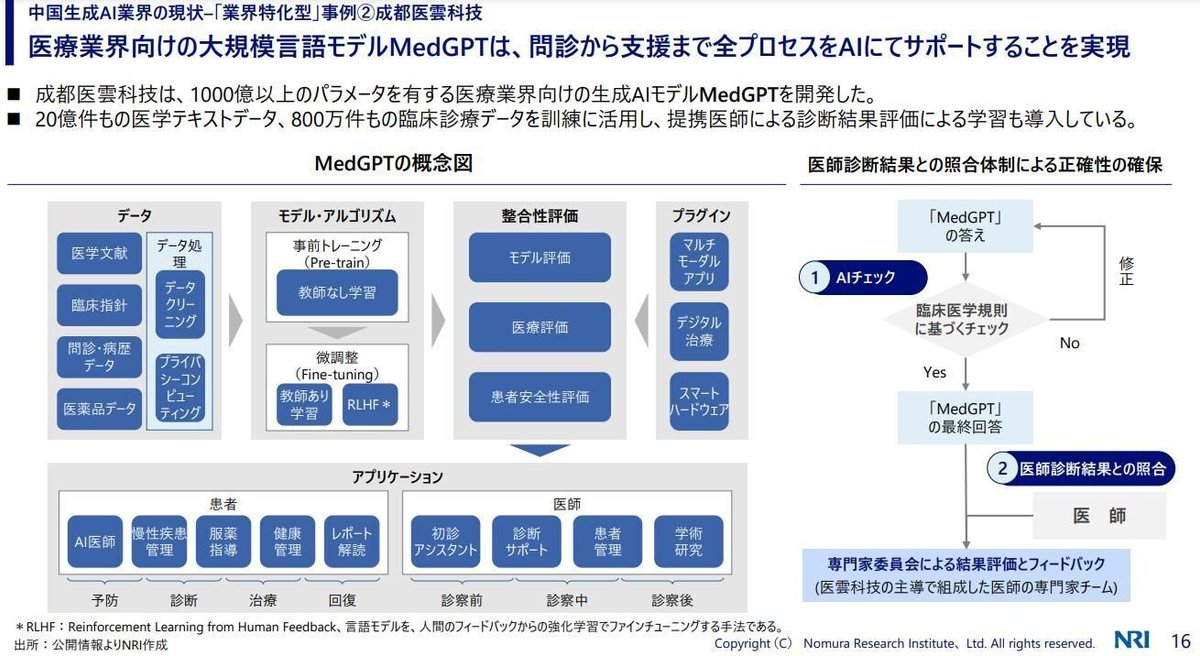
たとえば、医療業界向けのモデルとしてはMedGPTが開発されています。20億件の医学テキストデータ、800万件の臨床診療データ、提携医師によるフィードバック(強化学習)まで行われており、様々な医学用途のアプリケーションで活用されています。
中国語を学習させたモデルが充実している
各社が保有しているデータを元にモデルが開発されているため基本的に中国語がベースになっている(ChatGPT等は英語を日本語に翻訳している)
政府系機関は、世界最大の中国語テキストデータセット(3TB)、世界最大のマルチモーダルデータセット(90TB)、世界最大の中国語会話データセット(181G)を使った悟道モデルをオープンソース化している
アリババは、傘下の会社に自社開発のモデルを提供している。百度は、検索サービスで得られたデータを元に開発したモデルをクラウド基盤やAPI連携等を通じて他社へ幅広く提供している。

まとめ&感想
中国では生成AIは国家の監督下におかれており、反体制的な内容のフィルタリングが義務化されています。更に法律名(生成AIサービス管理暫定弁法)に「暫定」という言葉がついており柔軟に変更される可能性が示唆されているため中国でAIサービスを展開するにはリスクが高そうです。
今回の資料ではSNSのデータ利用については言及されていませんでしたが、バイトダンス(Tiktok)、微信 (WeChat)、微博 (Weibo)の動向も気になります。
中国のAIサービスを使ったら会話データを再学習されるはずのため、リスク評価は注視していきたいと思います。
以上
この記事が気に入ったらサポートをしてみませんか?