
『売上』構造把握から戦略を導く教科書

株式会社秤の小川と申します。このnoteでは、みなさんが行うマーケティング戦略の意思決定を、客観的な数字から導くための方法を共有します。高度な分析を咀嚼し、30分読めばおおよそ分かる教科書を目指して執筆しました。
私は、広告会社で消費者にまつわるデータ分析やそれを元にしたコミュニケーション戦略立案に注力してきました。その後、デジタルマーケティング会社、PR会社での戦略立案に伴うリサーチやコンサルティングの経験を経て、2019年12月に株式会社秤という法人を設立し、アドバイザーやエバンジェリストなど複数の役割(業務委託)で活動しています。社名は、日本を代表するマーケター森岡毅氏が代表を務める株式会社刀から着想を得たものです。
「刀」社に憧れて、意思決定をするために必要な知識を「秤」として浸透させていくための会社を立ち上げました。2020年は企業と個人向け、合計800人に有料講義をして研修プラットフォームのストアカで新人先生賞を頂くこともできました。オンライン講義の内容を磨きながら、企業と個人に向き合ってきました。これまでの活動の総括として2つのnoteにまとめます。テーマは戦略を導くための市場構造把握です。このnoteは、「売上」構造把握です。対になるのは「購買」構造把握のnoteです。
マーケティングの意思決定として誰(WHO)にどんな価値を伝えるか?(WHAT)どんな方法で伝えるか?(HOW)。何に注力するかを決めて、何を捨てるかを決めること、そうした意思決定が戦略です。人、モノ、お金、企業のリソースには上限があります。何かにリソースを使うと決めたら、その分、何かを諦めなければなりません。経営学者のマイケル・ポーターは(つまるところ)「戦略とは捨てること」と言及しています。
大胆な戦略を導くことができる組織は、言い換えると大きな何かを捨てることができる組織です。経営者の鶴の一声で決めることで、それができている企業もありますがデータを元に組織で決めることができる企業のほうが長期的には勝つ確率が高いと思います。経営、現場、それぞれのレイヤーの膨大な数の意思決定の精度が上がるからです。その点では、徹底した全社研修、エクセル経営で社員全体のデータリテラシーの底上げに成功しているワークマン社は模範となる企業です。
データ分析を一部のデータサイエンティストのものとせず、全社の血肉とするエクセル経営は、同社躍進の下支えとなっています。同社の成功とエクセル研修について上記のnoteにまとめています。
全社戦略としての注力領域、すなわち戦略を決めることこそデータドリブンであるべきですが、そうした重要な意思決定ほど、経営者や声が大きい方の鶴の一声がないと決まらない、そんな組織もあるかもしれません。現場からデータドリブンなカルチャーをボトムアップさせることと、経営者の意識変革の双方があればカルチャーは変えられるはずです。
50万部を超える大ヒットシリーズとなった西内啓氏の「統計学が最強の学問である」シリーズや、
USJをV字回復させた日本を代表するマーケター、刀の森岡毅氏と今西聖貴氏が消費者の購買行動をつかさどる数式など確率モデルの活用やリサーチに必要なリテラシーについてまとめた「確率思考の戦略論」、
その他の書籍や論文など、データサイエンス手法を駆使または研究をしてきた先人が公開してくれた知見は沢山あります。しかし、そうした文献を読んでも実務に活かせていない方も多いと思います。西内氏や森岡氏の話はおもしろかったし勉強になった。でもうちの会社はデータ分析の素養がある人がいないし・・・」「理想はマーケティング戦略の意思決定をデータドリブンにすべきだけど、自分の業務は担当外なので・・・」など、何をどうすれば実践に活かせるか分からない、または現状とのギャップから現実味を帯びないと感じている方も多いのではないでしょうか?かつての私がそうでした。
今回、このnoteを読んで実践に活かしてほしいと願うのは2種類の方たちです。
最も読んでいただきたい方はマーケティングやデータ分析の勉強や情報収集をしているが、ビジネスで活用できていない方です。情報収集されていても、具体的に活かせていないのであれば、もう一歩踏み込むことをオススメします。それがリターンを得るための入り口となるはずです。
次に読んでいただきたい方は、ご自身が重要な意思決定をする立場にあり、ご自身のリソースを分析に割けないため、スタッフにノウハウを身につけてほしいと考えるマネジメントの方です。率先して学び、実践するプレイヤーを育てたいと考えている方です。
私の特技はデータ分析の学びを咀嚼することです。今はお教えする仕事も行っていますが、もともと高校の数学も覚えていませんでした。1,000時間は勉強して、なんとか1冊の書籍を出すに至りました。勉強の途中で様々な挫折や無駄がありましたが、学びの筋肉がついた気がします。私は周り道をしましたが、みなさんがそんな時間を費やす必要は一切ないと思っています。そこで、私が費やした時間をぎゅっと凝縮し、みなさんに私の数十倍~数百倍のスピードで追体験をしていただき、ご自身のマーケティング意思決定に自信を持って頂きたい、その想いで書きあげたのが本noteと、『購買』構造把握から戦略を導く解説書の2作です。
2020年からブラッシュアップしてきたオンライン講義内容の多くを本noteで再構成しました。さらに詳しく学びたい方には、ストアカ講義を開催中です。本noteの最後でご紹介します。
2つのnoteの共通テーマは市場構造をモデル化し「マーケティング戦略の意思決定を確かなものにする」ことです。
本noteは売上構造の把握です。数理モデルを用いて、売上を構造的に把握することで、その施策は効いている効いていないなど、無駄な議論によるリソース浪費を回避するためのものです。何に注力し、何を捨てるのか?データドリブンに「戦略」を導くものです。
対となる上記noteでは、購買構造の把握についてまとめました。森岡氏らが公開してくださった確率モデルのノウハウを咀嚼した活用例を紹介します。
『売上』構造を把握
みなさんはご自身が関わるブランドが実施しているマーケティング施策をもし、行わなかったらどれだけ売上が減るか数値を把握されていますか?○○がなかったら?これを反事実と言います。因果推論の考え方の根幹となります。差分の差分法や傾向スコア分析など、いくつかの因果推論の分析のデザインがあります。わかりやすく書かれた書籍「原因と結果の経済学」をオススメしています。
因果推論の分析の傾向スコアマッチングを用いた効果測定についてGoogleの方が書かれた記事もオススメです。
「広告の効果測定は、広告がきちんと機能していることを証明する「アカウンタビリティ(説明責任)」だけではありません。ここから、その広告の純増効果である「インクリメンタリティ」を計測し、ビジネスを成長させる必要があります。」
以上は記事からの引用です。広告などマーケティング施策の純増効果を定量化する分析を知ることでインクリメンタリティを計測してまいりましょう。
ここでは、マーケティング施策のうち広告や販促は売上にどれだけ寄与しているか?数理モデルから構造的に把握し効果を定量化する方法を紹介します。
私は、広告会社で働いていた時にその方法を知って勉強し、2018年11月に「Excelでできるデータドリブン・マーケティング」を出版しました。数理モデルによる効果検証法となるマーケティング・ミックス・モデリングを体系化して共有する書籍です。因果推論にも触れています。統計学が最強の学問であるシリーズ著者の西内啓氏より「これからのマーケターはグラフの見た目より『因果推論』に注意すべきである」という推薦コメントを頂けました。
このnoteではマーケティング・ミックス・モデリングのやり方と活用視点を共有します。
書籍では「エクセル統計(体験版)による演習でExcel標準機能では対応できない分析手法を体験できます(Macには対応していません※エクセル統計の製品版も同様です)」Amazon書籍紹介ページの「出版社より」(直下右部より引用)
マーケティング・ミックス・モデリング(MMM)とは?
マーケティング・ミックス・モデリングとは?同時に複数実施されているマーケティング施策やその他の要因を用いて(数式などの)モデルを作って売上などを説明し、施策毎の影響を定量化するアプローチのことです。MMMと略します。MMMは主に時系列データ解析を用いる場合が多いですが欧米では、人間や社会のふるまいをシミュレーションするより高度な分析となるエージェント・ベース・モデルも使われています。

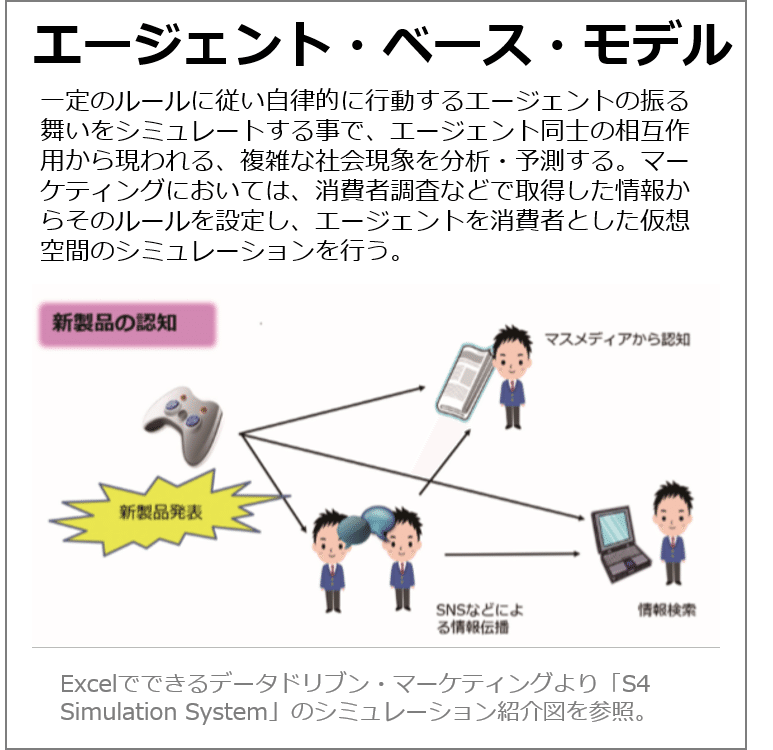
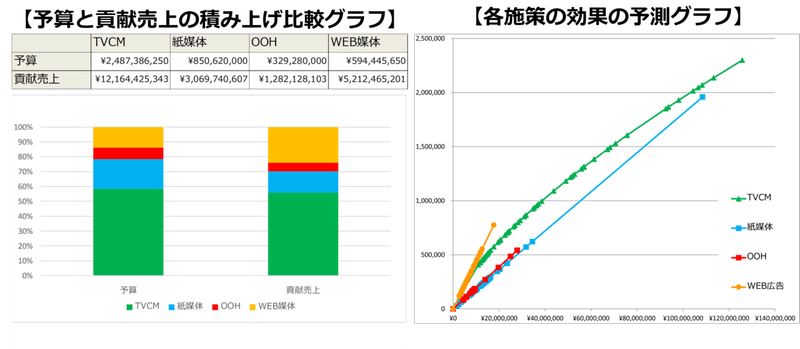
ここではExcelで回帰分析と構造法定式モデリングを行う方法を紹介します。拙書Excelでできるデータドリブン・マーケティングではオリジナルのマクロを組んだExcelを使って、TVCMなどマーケティング施策の残存効果や、投下量が増えるほど効果が減衰する非線形な影響を加味して予測精度を向上するMMMを体系化しました。どんなことが分かるのか?書籍の演習用に作成したダミーのアルコール飲料のデータ解析の結果から作成したアウトプット例を紹介します。
Excelでできるデータドリブン・マーケティングの演習用に作成したアルコール飲料の2年強の時系列データ(デモデータ)の分析例です。TVCM、紙媒体(新聞や雑誌広告など)OOH(アウト・オブ・ホームメディア)とWEB広告の予算配分の最適化による効果向上をテーマにした演習データです。
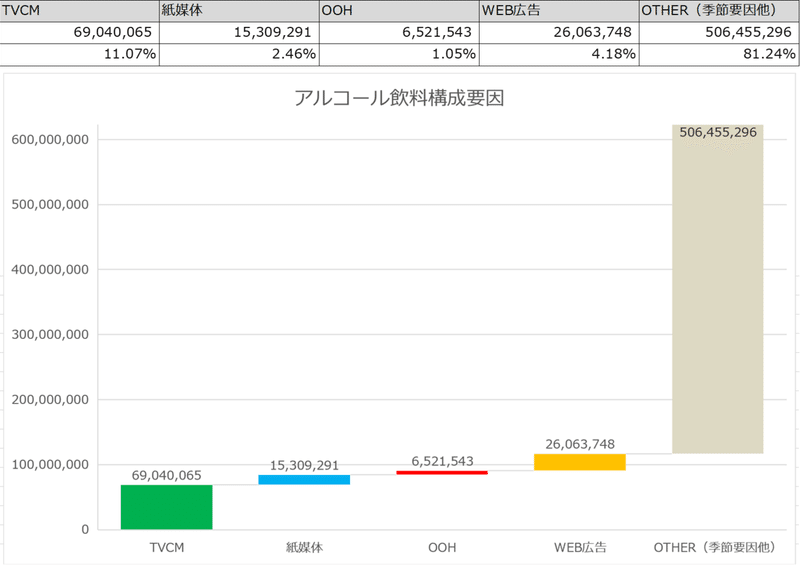
【KGIまたはKPIを構成している要因のウォーターフォールチャート】
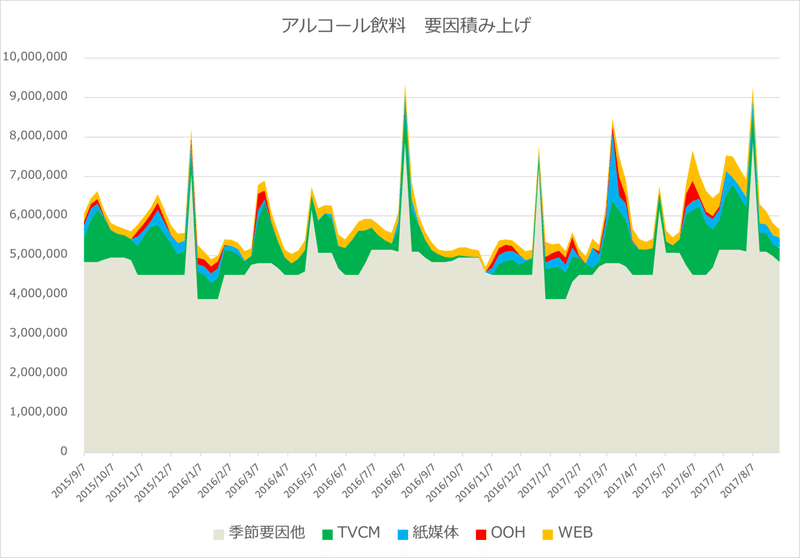
【KGIまたはKPIを構成している要因の積み上げ時系列グラフ】
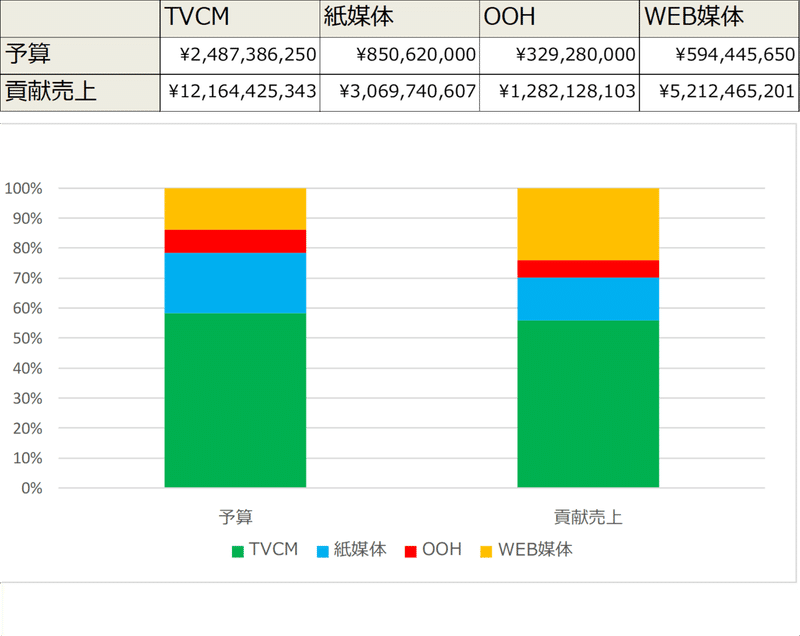
【予算と貢献売上の積み上げ比較グラフ】
【各施策の効果の予測グラフ】※横軸は期ごとの投下金額。縦軸は売上数
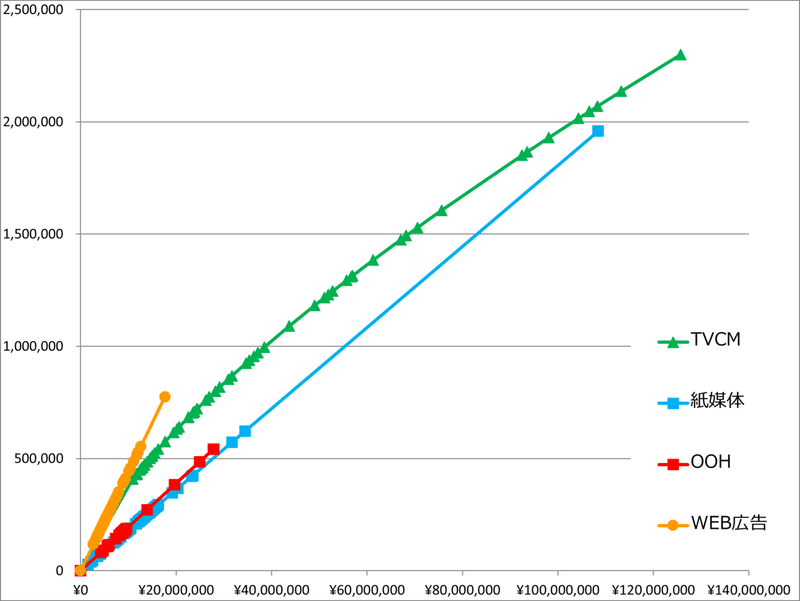
横軸が週あたりの投下金額、縦軸が各施策がアルコール飲料の売上を増やす本数です。傾きが最も急なWEB広告が最も効率よく売上を増やすことになります。TVCMは横軸の投下量が増えると縦軸の効果数の増加量が逓減していく非線形な影響が考慮されています。
どのようにしてこれらの分析結果を導くのか?まずは回帰分析からご説明します。
回帰分析とは?
簡単に言うと、説明変数x(たとえば広告)によって、目的変数y(例えば売上)をどれだけ説明できるか分析する方法です。説明変数xは複数あっても構いませんが、ここでは説明変数xひとつの例で説明します。夏に売れるアイスのような商品だとします。
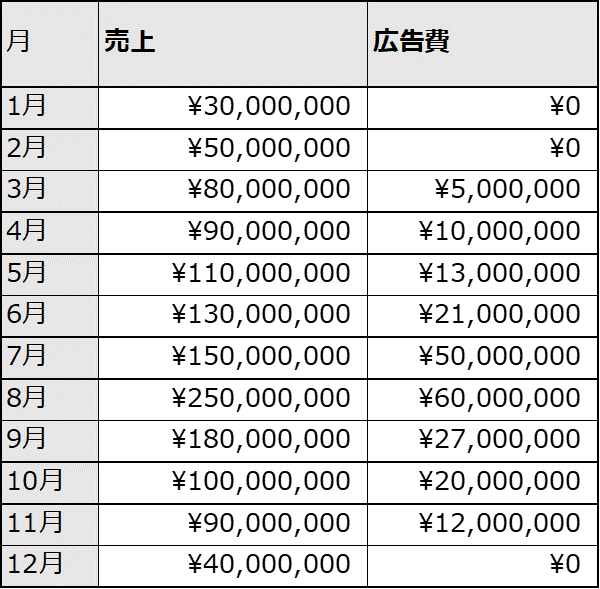
上記のデータを用いて目的変数yを売上として、説明変数xを広告費として、yを説明する式を作ってみます。以下のグラフは上記のデータをプロットしたものです。横軸がxの広告費、縦軸のyが売上金額です。一番右上にある点が、8月のデータです。(売上2.5億円、広告費6,000万円)ぱっと見で、広告費xが多くなるほど、売上yも多くなると関係に見えます。
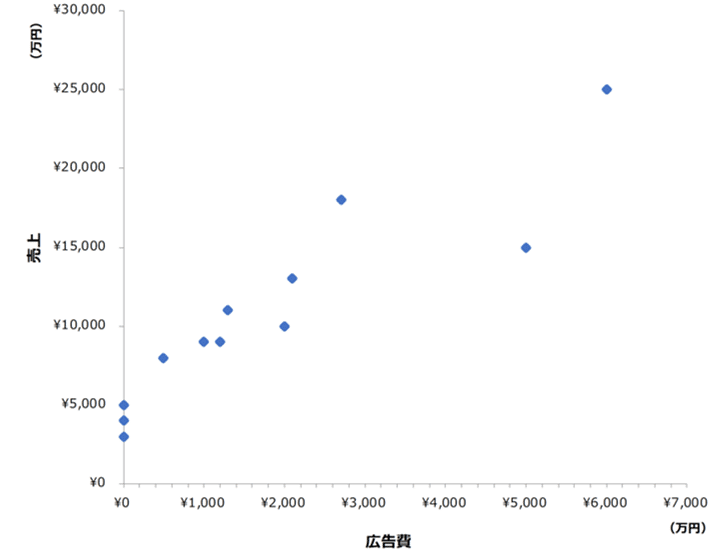
回帰分析は、xによってyを説明または予測する式を作るものです。
※説明(または推定)と予測は近しいようで違うものです。どちらに主眼を置くかで変数選択の仕方など、分析のデザインが変わります。このnoteでは、以降、予測で統一します。
xでyを予測する式を作ります。直線を1本引っ張ります。「えいっ」
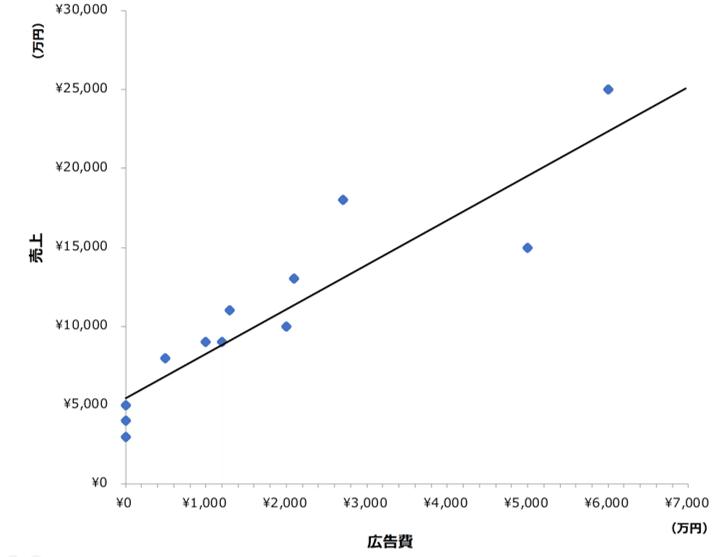
できました!この直線が回帰分析によって導いた予測式です。これは、以下グラフの上下の緑色の矢印、予測した値(直線上の値)と実際の値の差(「残差」といいます)を最小化する計算から導かれたものです。残差はプラスのものとマイナスのものがあります。これをすべて足すと0になってしまうので、残差を2乗して(すべてプラスの値にして)合計値を最小化する計算から導きます。
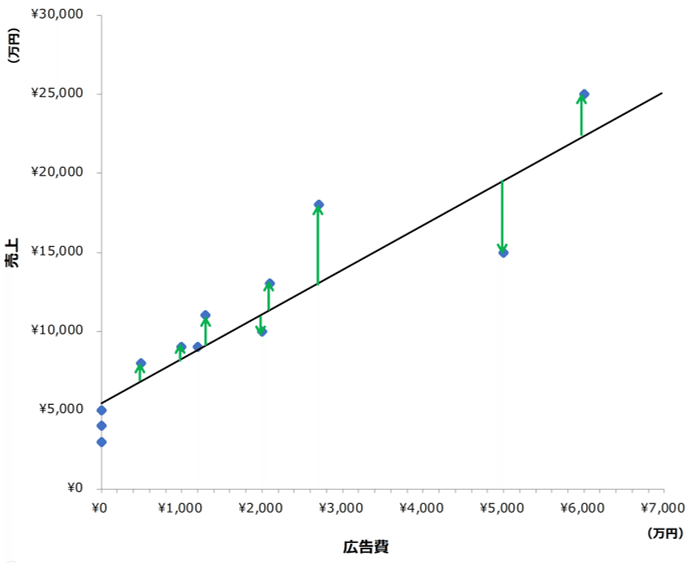
予測式はxが増えると、yも増える関係を示しています。どれだけ増えるのでしょうか?青い矢印をご覧ください。横軸の広告費xが1,000万円増えると縦軸の売上Yは2,961万円増える関係です。これは予測線の傾きを示すものです。この傾き広告費xが1円増えると売上yが2.961円増える関係を示しています。
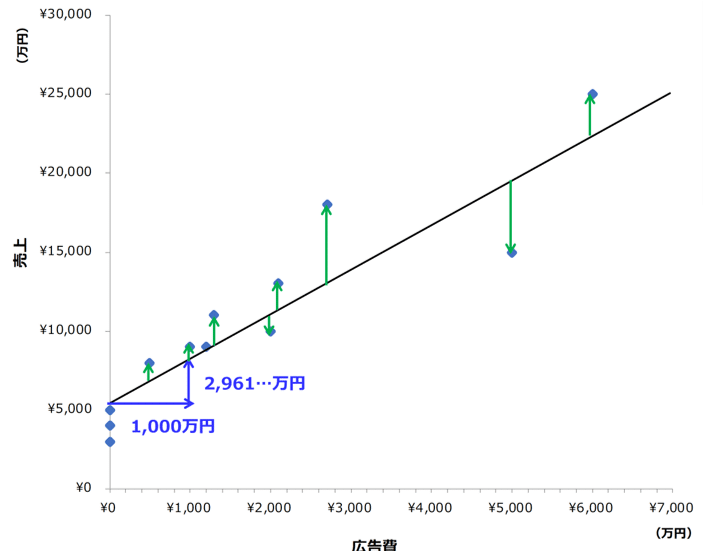
回帰分析によってマーケティング施策の効果を把握するために知りたいのは、この傾き(a)の値です。
仮に、このアイスの商材が広告によってのみ売上が増えるとしましょう。その場合、もし、広告費xを投じないとしたらいくら売上があるでしょうか?これに対応する値が以下グラフの赤い矢印です。
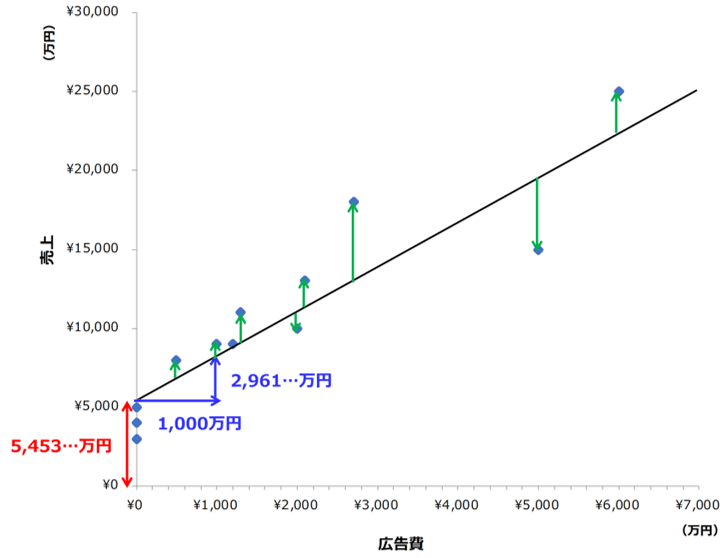
赤い矢印が「切片(b)」です。残差の二乗の合計値を最小化する目的で引っ張った予測線は、以下の式に対応します。
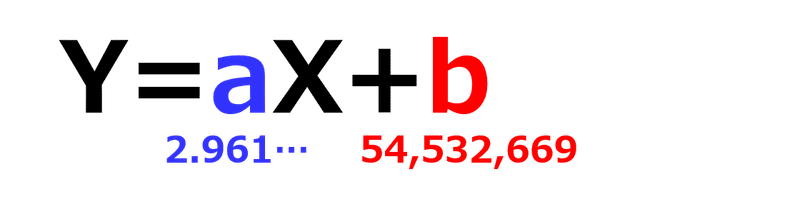
これが回帰分析です。実際は複数の説明変数を使うことがほとんどです。1年間で100万個売れた商品があるとします。マーケティング予算は年間10億円です。以下のような数式でx1(TVCM)~x4(WEB広告)までの複数の各説明変数ごとの係数(a)を求める回帰分析でそれぞれの施策の効果を把握できます。
y(100万)=
x1 (TVCM5億円)×0.0003=15万個
+
x2(紙媒体1億円)×0.0002=2万個
+
x3(OOH1億円)×0.0003=3万個
+
X4(WEB広告3億円)×0.0004=12万個
+
切片など
【補足】
説明変数が一つの場合は単回帰分析といいます。説明変数が2個以上(複数)の場合は重回帰分析といいます。説明変数が一つか複数かで呼び名は変わりますが、どちらも回帰分析です。切片などとしているのは、切片以外に残差も含みます。「もし、説明変数の事象が行われなかったら」ではなく、「すべての説明変数×係数によって説明できないもの(+残差)」というイメージです。
データを触って理解するのが近道です。
活用視点① KGIに影響がある要因を洗い出す
MMMの分析を行なっていきます。分析テーマは2019年の大ヒット映画「天気の子」です。広告とPRが映画の販売や検索数に対してどれだけ影響を与えていたか把握していきます。MMMでは、まず目的変数yの変動に影響がありそうな要因xとなりえるものを全て洗い出します。①内的要因、②外的要因、③中間変数の3つで考えます。
①【内的要因】※介入余地があるもの
■広告
■PR
■販促
■その他
内的要因は広告やPR、販促など企業が介入できる要素があるものです。
②【外的要因】※介入余地がないもの
■トレンド要因
■社会経済要因
■その他
企業がコントロールできる余地が全くない、介入余地が全くない要因です。降水量や気温、最近では感染症のマイナス影響を考慮する変数を用いて分析しています。
③【中間変数】
当該ブランドのKGIに関わるアクション数(KPI)
■検索数
■検索来訪数
■ツイート数
内的要因か外的要因かという枠にとらわれず、KGIの手前のKPIとなり得る要因です。これは後ほど、構造方程式モデリングの紹介で詳しく話しますが、効果を把握したい広告や販促によるKGIへの影響を時系列の解析では直接推定できないときに重要な役割を担うものです。
これら3つの視点で目的変数に影響すると考えられる要因を洗い出し、そのうちデータとして整形できるものを用意します。考えられる要因を出し尽くし、さらに要因同士の関係性まで仮説し尽くすことが理想です。
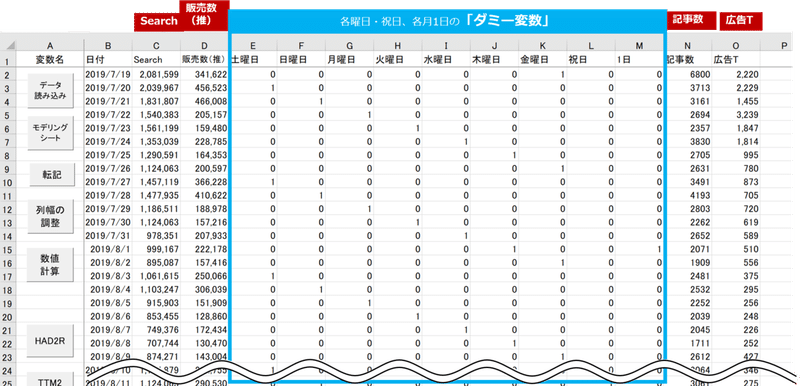
ここでは用意したデータからサクっと分析する方法として、弊社主催のZoom勉強会の演習で行う分析を紹介します。2019年7月19日の封切りから9月15日までで127億円の興収となった時点までの「天気の子」の推計データを使います。内的要因のPRと広告と、中間変数として検索数、最終的な売上となる販売数を整形しました。

オープンデータから推計したデータです。詳しい推計方法は上記noteに記載しています。広告は視聴率などのシンジケートデータ(有料で販売されている調査データ)を代替するため、広告に言及されたTweet数を用いました。(広告TのTはTweetの頭文字です)PRはWEB上で観測された記事数です。
分析の目的は、PRと広告は指名検索数、販売数にどれだけ影響があるか?回帰分析による予測モデルから定量化することです。関西学院大学社会学部 教授の清水先生が作っていただいたExcelで動くフリーの統計分析プログラムHADを用いて分析します。
外的要因として、月~日曜日までの曜日効果と祝日と毎月1日(映画の日)の影響がないかを探索するために0と1で表現するダミー変数も作りました。
まずは相関分析を行い、変数同士の関係性を見ておきます。

HADの相関分析の結果からセルの色分けをしました。
赤枠のSearchとの相関係数を見ていくと、販売数、次いで「広告T」「記事数」の相関が高いことが分かります。
まずは目的変数yを「天気の子」を含む検索数として、ある一定の基準で目的変数に影響のある変数を自動選択するステップワイズ回帰分析を行います。目的変数(y)をSearchとして、候補となる説明変数(x)を土曜日~広告Tまで11個として分析を行います。

得られた結果が下記です。
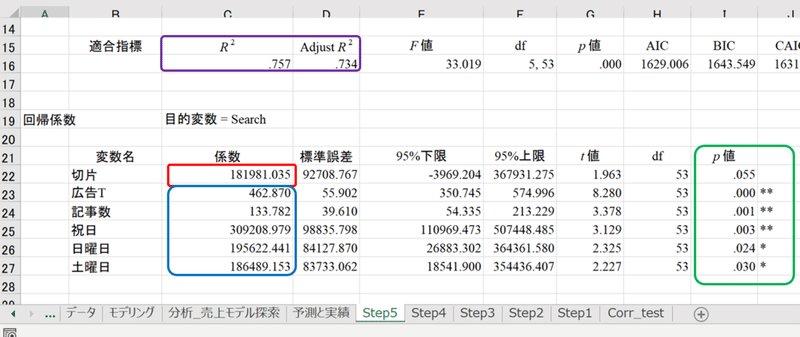
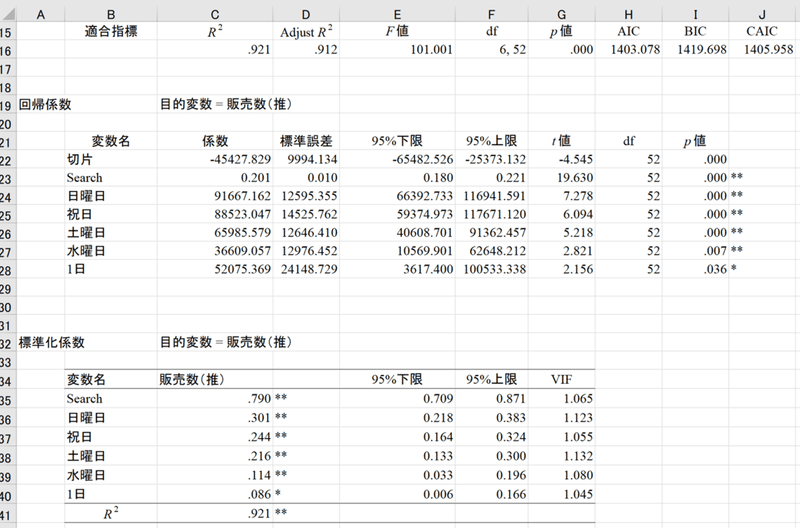
自動選択によって「広告T」「記事数」「祝日」「日曜日」「土曜日」の説明変数が選択されました。青枠の囲みの数値がそれぞれの説明変数の値1あたり、yをいくつ増やすか?回帰分析により導かれた係数(a)です。赤枠の囲みが切片(b)です。
紫色の囲みのR2は決定係数、AdjustR2は自由度調整済み係数といいます。得られた分析結果によってyの変動をどれだけ説明できているかを示すもので、予測精度の目安となります。単回帰分析のときはR2を、重回帰分析のときはAdjustR2を参照します。
説明変数は緑色の囲みのP値を基準に選択されたものです。回帰分析で導いた係数が0ではない(すなわち得られた係数には意味がある)ことを対立仮説とし、帰無仮説「係数は0である」を検定した結果です。ステップワイズの説明変数選択の際は分析者が定めた有意水準を基準とします。
切片のP値は気にしなくてよいです。有意水準は一般的に5%が用いられることが多いですが、社会科学などでは10%が使われる場合もあり、ここでは基準を10%としています。拙書でも10%を基準にしています。
係数が分かれば、各説明変数の値と係数を掛け合わせることで、それぞれの説明変数が目的変数にいくつ影響を及ぼしたか把握することができます。重回帰分析の際は、それぞれの説明変数の値の単位がバラバラとなる場合が多いです。HADでは各説明変数の目的変数への影響を横並びで評価するための標準化係数も出力します。
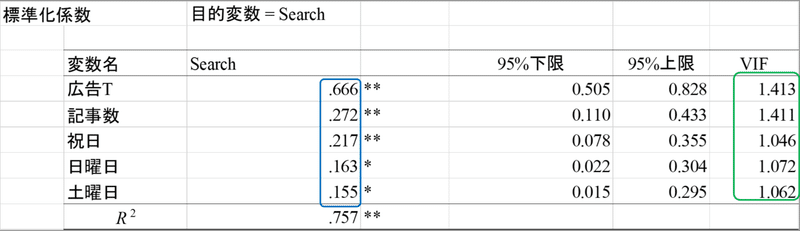
緑色の囲みのVIFという値は回帰分析の多重共線性というエラーを検定するための指標です。相関が強い説明変数同士を入れると、係数のプラスマイナスが逆転するなど不安定な結果となるエラーです。VIFが10を超えなければ多重共線性は発生していません。
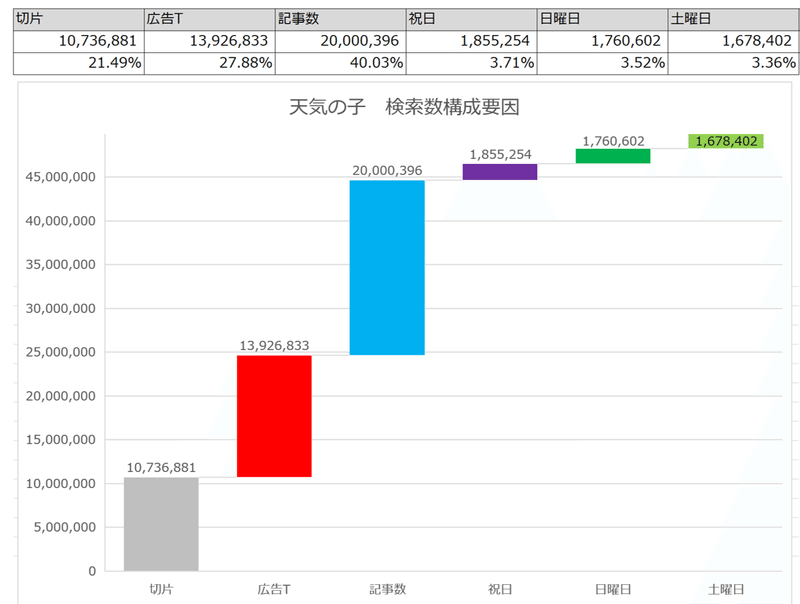
各値の合計値と係数を掛け合わせることで効果数を求めることができます。

求めた効果数をウォーターフォールチャートにすると、各要因ごとに指名検索数に影響があるか?直感的に把握できます。
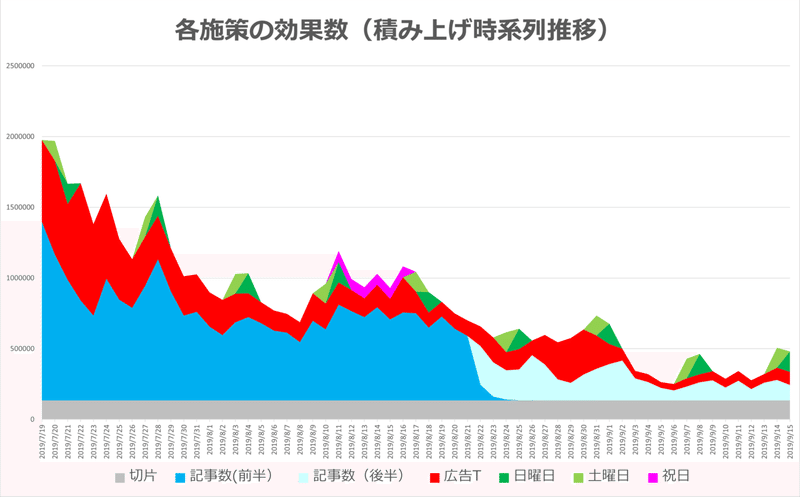
また、各説明変数の値×係数を日別で求めることで、それぞれの説明変数(と切片)によって、目的変数(検索)がいくつ増えたか分かります。積み上げ時系列推移グラフにすれば、予測式に用いた各変数が日別で指名検索数をいくつ増やしたか可視化することができます。
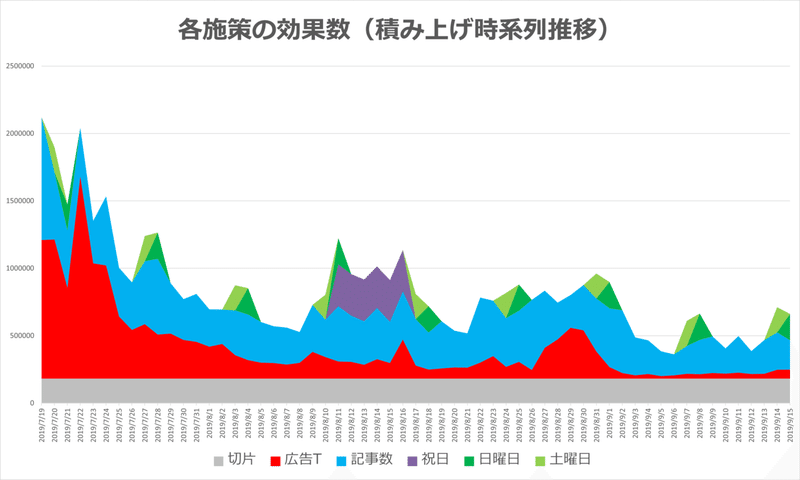
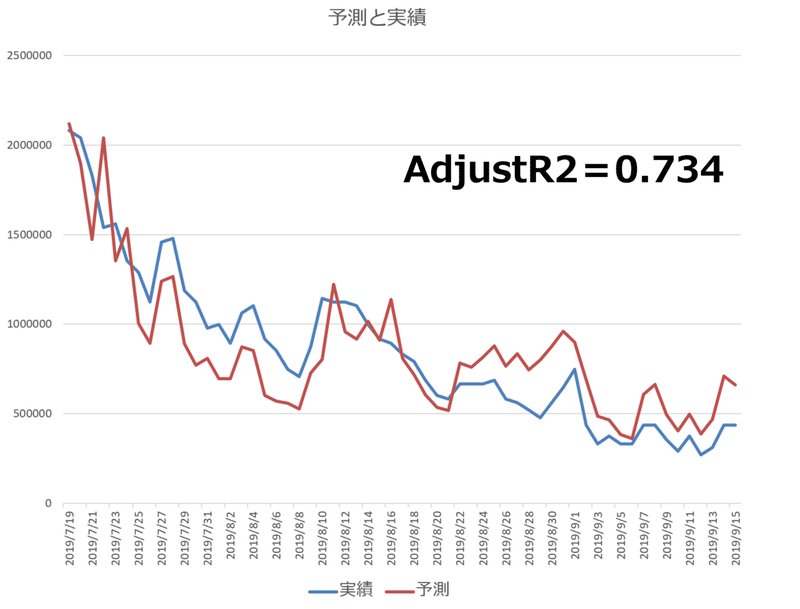
各説明変数+係数の値と切片の値を日別に合計することで、予測値を求めます。折れ線グラフにして実績値とのあてはまりを確認できます。
次に販売数を予測するモデルを作ります。目的変数を販売数として、ステップワイズ回帰分析を行った結果が下記です。
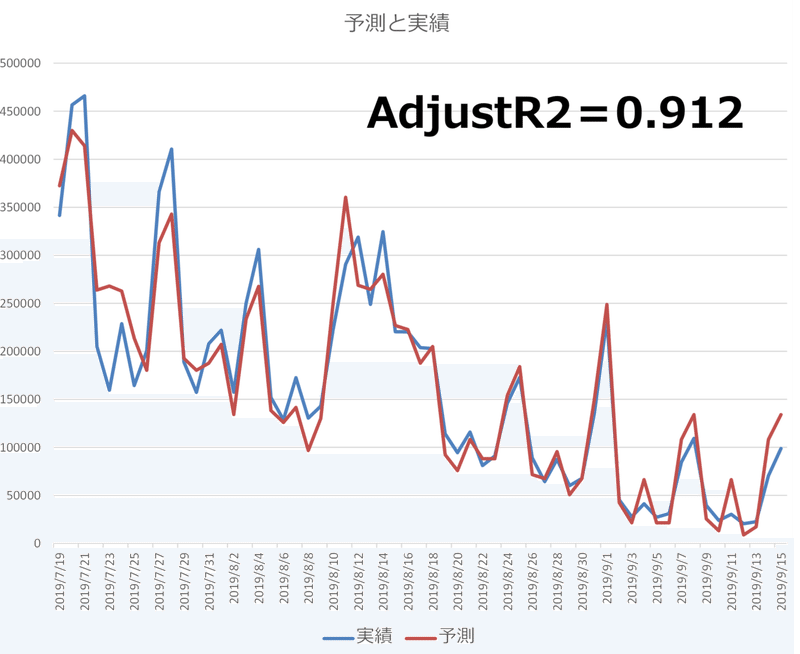
AdjustR2は目的変数を検索としたモデルより高く、0.912です。グラフにすると予測値と実績値のあてはまりが良いことが分かります。VIFの値から多重共線性が起きていません。
活用視点② 重要なKPIとなり得るツイートや検索のデータを有効活用する
回帰分析によって2つのモデルを作りました。目的変数を検索数としたモデルと、
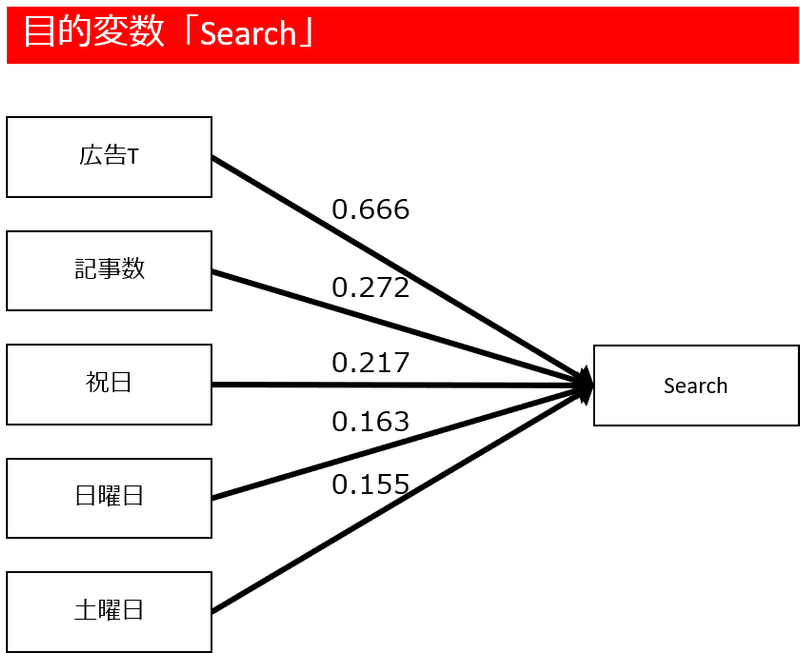
目的変数を「販売数」としたモデルです。
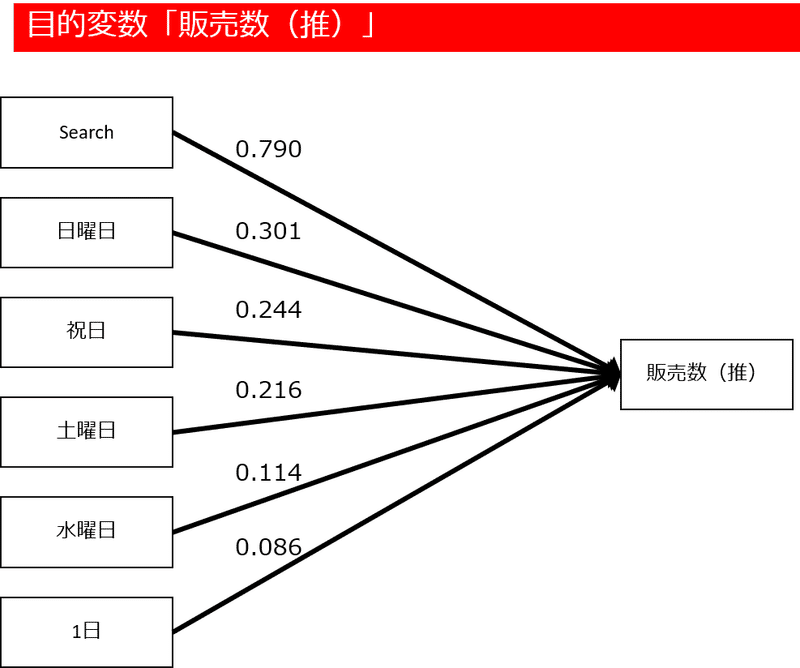
それぞれ標準化係数を記載しています。
HADでは構造方程式モデリングという分析も行うことができます。これは変数の関係を分析者が仮説したパス図を描いて、変数同士の関係の強さを把握するものです。構造的に変数の関係を把握することができます。ここでは2つの回帰分析モデルを組み合わせたパス図を作り、係数(ここでは標準化係数)を求めました。
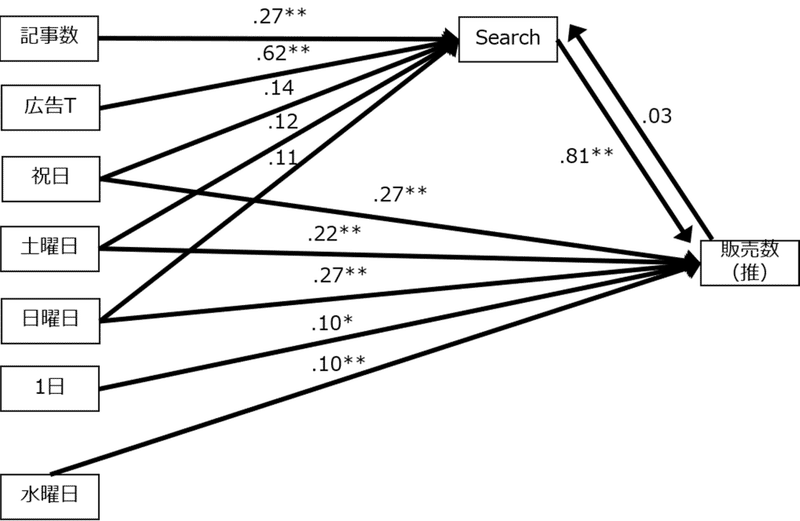
注目いただきたいのは、検索数と販売数の双方向の矢印と係数です。検索数が増えると販売数が増えるのか?販売数が増えると検索数が増えるのか?どちらの影響が強いか調べました。前者の因果の向きのほうが影響が大きいことが分かります。これは消費者行動の実証研究という書籍を参照して行なった分析です。
この書籍は消費者行動に関する理論や分析手法を整理し考察したものです。第8章「SNSが販売実績に及ぼす効果の測定とソーシャル・リスニングの意義(鶴見裕之)」では、SNSは売上にどう影響するのか?といった研究の成果と仮説が示されています。鶴見氏らの2013年の研究では、ビール系飲料の新商品を対象に、構造方程式モデリングを行なったところ、テレビ広告が当該ブランドのツイッターの書き込みを介して販売実績に与えているという仮説を導きました。販売実績が伸びるからツイートが増えるのか?ツイートが増えるから販売実績が増えるのか?双方向で検証したところ、ツイートが増えると販売実績が増える因果の向きのほうが影響が強いことが分かったのです。
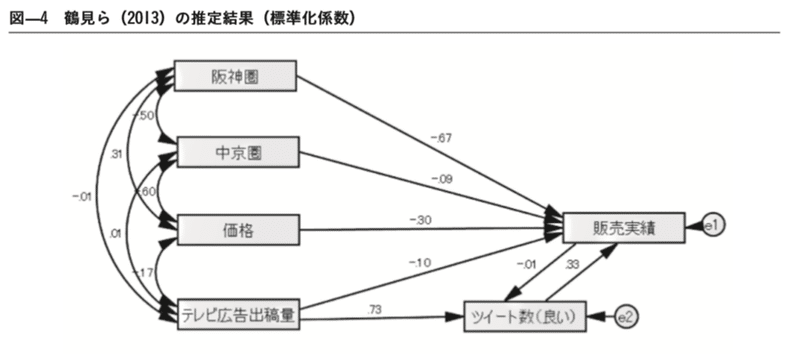
直接TV広告が売上に影響があるかを確かめるために、目的変数を販売実績とした回帰分析も行ったそうですが影響はみられなかったそうです。「天気の子」の分析でも、検索数が増えると販売数が増える因果の向きのほうが大きな係数となっていることが分かります。(パス図※再掲)
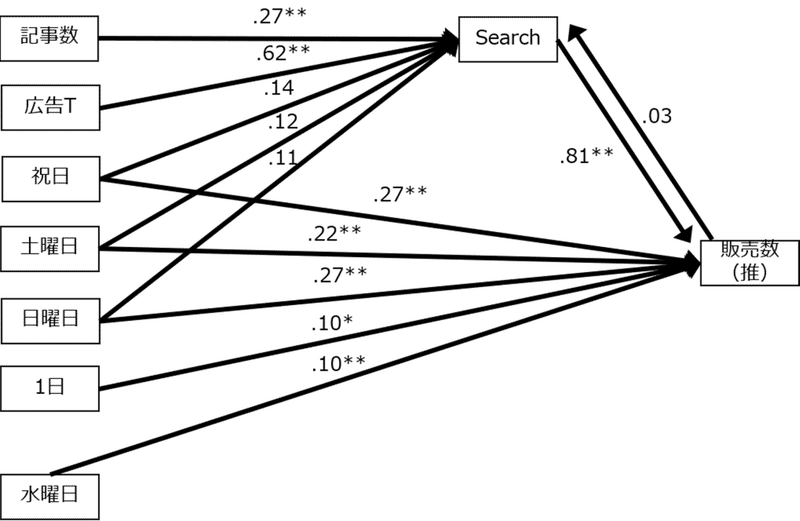
記事と広告は直接販売数に影響をしませんが、検索を介して販売数を増やしていることが分かります。時系列データ解析によるMMMでは、ブランドのツイートや検索は、マーケティング施策それぞれが売上に影響を及ぼしているかを把握するために重要な中間変数となります。
分析対象としたビール系飲料のツイートの数は多くても1か月あたり数千程度だったそうです。鶴見氏らはこうしたTwitter上のコミュニケーションは「話題性の代理指標」としてとらえるべきではないか?という仮説を提唱しています。Twitter上に現れる商品に関する書き込みは、消費者間で交わされるクチコミや評価が表面化した、いわば「話題性の氷山の一角」であるという仮説が成り立つとしています。天気の子では、映画を視聴した後に投稿したと考えられるツイート数も調べており、その数は約24.6万ツイートでした。

「天気の子」を観てきた方の人数に対して、視聴後のツイート数は2.5%です。この数字をそのまま捉えると、映画を見た人数の2.5%しかツイートがされていなかった(少ない)と捉えることもできる一方で、視聴後のツイートが一定量発生した際は、およそ40倍の販売数が発生している、すなわち視聴後のツイート 24.6万は天気の子の販売数946万回の「話題性の代理指標」と考えて「貴重な氷山の一角」として捉えることもできます。
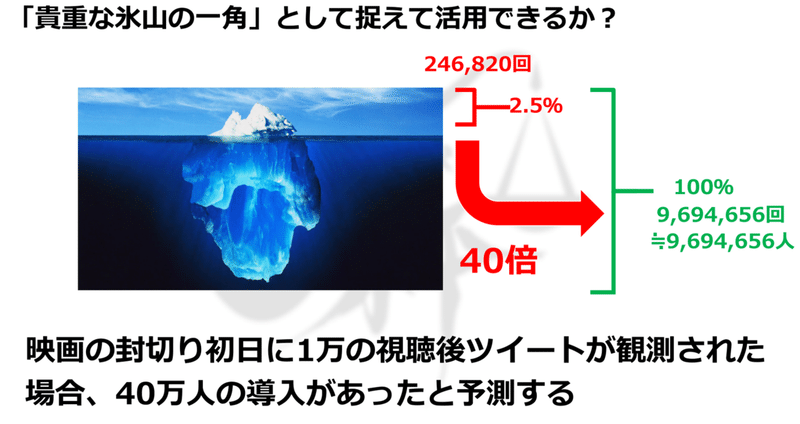
たとえば映画の封切り初日に1万の視聴後ツイートが観測された場合には、その40倍の動員があったと考え、それが事前に想定した需要を上回る場合は、広告を追加する準備を行う、想定した需要を下回る場合は広告を減らすなど、スピーディーな意思決定に活かすことができます。
ブランドにまつわるツイートは表面化したごく一部であり、水面下ではその何10倍もの消費者の態度変容が起きている、その様に捉えると、ブランドに言及されたツイートは非常に貴重なデータではないでしょうか?ブランドの検索も同様です。MMMでも中間変数として重要な役割を担います。
効果検証における検索データの有用性については上記noteにまとめています。
先進的なデータ活用を行っている企業は、需要予測や効果検証のシステムにツイートや検索のデータを活用しています。みなさんも、それを貴重な氷山の一角と捉えて活用してみませんか?
活用視点③ デジタル×リアル、クロスチャネルの効果を把握する
広告やPRなどのマーケティング施策が中間変数となるツイートや検索(KPI)を介して、売上(KGI)を押し上げており、その構造を把握して効果を推定することができることをお分かり頂けたかと思います。これは購入する前に検索して調べるアクションが発生する商品やサービスの多くにあてはまります。
一方で日常的に購入される低価格の商品やサービスは検索と購買が紐づかないことがあります。私はたまにコンビニでうまい棒を買います。買う前に10円のうまい棒を検索して調べることはしないと思います。検索が購買行動と結びつき辛い商品やサービスの場合は、マーケティング施策が直接、売上を予測するモデルが有用です。念のため、中間変数を目的変数とするモデルも作り、予測精度を見てどちらが有用か判断すると良いでしょう。また、十分な標本サイズ(分析期間)を確保できる場合は日別より週別の粒度のほうが、直接売上を予測しやすい傾向があります。
■活用例 実店舗を運営する業種の場合
実店舗もECも運営する企業ではWEB広告によりECの売上がどれだけ増えたかは把握していると思いますが、例えばWEB広告やSNS投稿のリーチによって、実店舗の売上をどれだけ増やすか把握できていない企業は多いのではないでしょうか?過去に分析したアパレル企業では、4,000万円のSNSへの投資で3億円以上の実店舗売上に貢献しており、予算配分の見直しにつながりました。オフライン広告とWEB広告とSNS投稿による効果を、実店舗の売上をどれだけ増やすか把握することで、投資すべき施策を見定めることができます。たとえばWEB広告とSNS運用に年間1億円使ってECでの売上が1.5億円発生している企業であれば、その2倍~4倍程度は実店舗の売上に貢献している場合が多いです。
また、感染症による影響を「外的要因」の変数として組み込むことで、「感染症がもしなかったら」本来いくら売上があったかを推定することも有用です。たとえば感染症の影響によって10億円の売り上げが前年対比で4億円減って6億円になった場合、感染症のマイナス影響が5億円で、広告や販促によって1億円売上を増やしていて歯止めをかけておりマイナス4億円となっていたようなケースがあります。感染症で本来減る売上のうち、どれだけの売上が広告や販促によってカバーされていたか定量的に把握すれば、本来必要なマーケティング施策の投資を減らしてしまうことを避けることができます。
活用視点④ 検索をどれだけ増やしているかを基準として施策を評価する
■活用例 検索によって購買行動が左右される業種の場合
過去、広告会社で月額億円近いWEB広告で定常的に集客を行う企業を担当していた際、行なっていた分析です。マーケティング予算規模の大小にかかわらず、「検索行動が売上につながる全ての商品やサービス」にこの方法を推奨します。
内容はシンプルです。目的変数を「検索来訪数」とした回帰分析によって、各施策を評価することです。グーグルアナリティクスなどの解析ツールによって得ることができる検索来訪数を目的変数として、みなさんが行っているコミュニケーション施策を説明変数とする回帰分析モデルを作ります。本来はブランドの単語を含む検索数を目的変数とすることが望ましいのですが、アクセス解析時に検索単語不明のデータも多いため、当該商品やサービスを紹介するホームページの検索来訪数を使うケースが多いです。説明変数は、TVCMやWEB広告だけでく、必要に応じてTwitterやフェイスブック、InstagramのアカウントのリーチやYouTubeチャンネルの再生数も使います。
WEB広告やSNSやYOUTUBEなどのデジタルコミュニケーション施策を行っている企業は、その施策の評価をコンバージョン単価(CPA)で見ている企業が多いと思いますが、回帰分析でそれぞれの施策が検索来訪をどれだけ増やしていたかで評価することは、BtoCに限らずBtoB業種においても有効な分析です。ブランド検索は最終目的の売上や申込につながるアクションであり、単価が高い商品やサービスは、時系列データを分析してもマーケティング施策の変数が売上や申込を直接予測できないことがほとんどだからです。ツイートも言及数が少ない場合が多いです。高単価の商品やサービスを増やしていくための効果検証の指標として、検索数はかなり重要な役割を担います。
また、検索数をスマホとPCで分けて分析することでも発見があります。過去、WEB申込獲得とブランド想起が重要な業種で月間1,000万再生程度の動画広告を行ない、ブランド検索来訪数とそこから得られる申込数を倍に増やすことができた時、PCよりスマホの検索のアシスト効率のほうがかなりよかった記憶があります。
■まず使ってみましょう【MMMのミニマム活用例】
まずはブランドに関わる検索数または検索来訪数を目的変数として回帰分析を行ってみましょう。マス広告、WEB広告、SNSのインプレッションやYouTube再生数などがそれぞれ検索をどれだけ増やしているか定量化して把握しましょう。多くのケースで、ブランド検索は実店舗などデジタル以外のチャネルでの売上や申込みなどを予測する重要な変数となっています。時系列データ解析によるPDCAを徹底して行なった結果、最重要KPIをブランド検索として、それを最大化する予算配分を決めることが売上の総量を最も増やすという解に行き着いた企業もいます。話題化を重視するためツイートを最重要KPIにした企業もいます。動画の再生数にした企業もいます。モデル化することでそれらのKPI、中間変数が自社の売上にどれだけ影響するかまで捉えることができると、KPIをとにかく増やすことにリソースを集中させることができる状態になります。不明瞭な効果検証による無駄な思考や議論をなくしてブランドの成長の源泉となる指標を増やす活動に集中できる状態となることがMMM活用の最大の奥義です。
また、改正個人情報保護法の施行開始やクッキー規制など、個人データの利活用に対して新たなガイドラインが整備されていくため、デジタル広告や販促において企業は新たな対応を求められる様になりますが、MMMで目的変数を検索数として各施策を評価することは、いわばノークッキーの効果検証として今後も使えるものです。
さらに、MMMは誰でも活用できます。たまに勘違いされている方がいらっしゃいますが、TVCMのように億円単位の大規模な投資をしている企業向けというわけではありません。時系列データさえあれば誰でも活用できます。町の中華料理屋さんでも使える分析です。私は中華料理を作るのが好きで、いつか町中華をやってみたいと思っています。もし仮にそれを現実とした場合は、日々の売上数またはお店の公式サイトの検索来訪数を目的変数として、商圏内に配信するインターネット広告やお店のSNSアカウントのリーチ数を説明変数として分析するMMMによって最良の集客施策を見出していこうと思います。
■(ここで紹介した)MMM活用における留意点
売上や検索を増やす要因は最大10〜20個くらいの説明変数でモデル化することが現実的です。年間マーケティング予算を構成する要因を数種類に分けて分析するくらいの粒度感です。MMMはマーケティング予算全体の配分を大枠で最適化して効果を上げるものと考えると有効に使うことができます。
■予測精度(R2又はAdjustR2)を向上させるための方策の一例 ※専門性が高い内容を含みます。
前述した、天気の子のモデルのうち、検索数を目的変数としたモデルのAdjustR2が0.73となっていて販売数を目的変数としたモデルより小さな値となっていました。
決定係数はいくつがあれば良いという決め事がありません。拙書では私の主観として0.8以上を目安にしていると書きましたが、実際の実務では0.9以上を目指しています。
再度、予測値と実績値のあてはまりを見てみます。分析期間の前半は、予測値が実績値を下回る差分が多く、後半は予測値が実績値を上回る差分が多くなっています。
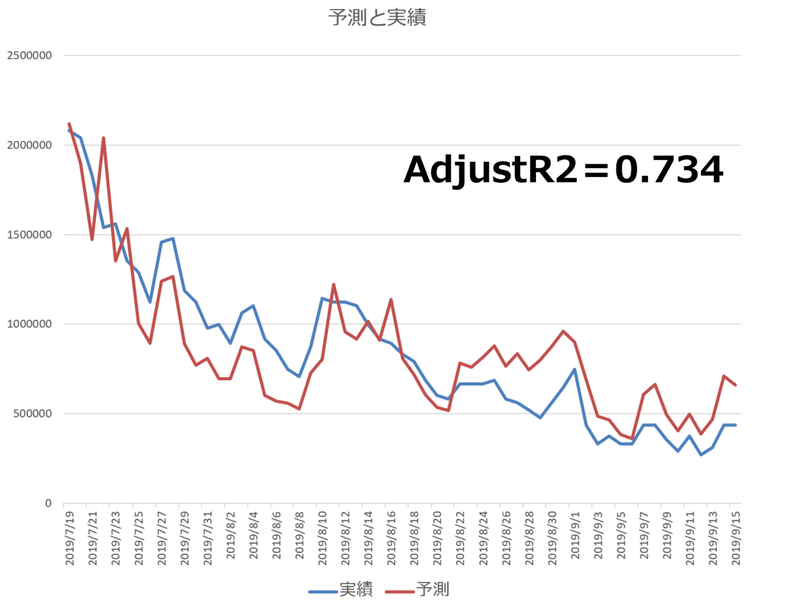
予測精度が低くあてはまりが悪い多くの場合は、欠落変数バイアスといって、目的変数を予測する要因となる変数が足りないことが多いです。足りない要因は何かを考えることからはじめます。
予測実績の差分が大きな箇所に対応するダミー変数を作って説明変数に加えていけば予測精度は上がります。しかし、やみくもに追加するのはNGです。ダミー変数に限らず、新たに追加する変数の意味を理解して追加する必要があります。このケースでは分析期間の前半と後半それぞれ対応する欠落変数がありそうでしたが、その要因は私には分かりませんでした。
説明変数を分割することで予測精度が上がる場合もあります。ここでは、記事数を8月22日を境に記事数前半と記事数後半の2つの変数に分けて分析することを実践しました。すると決定係数が0.9強まで上がりました。8月22日は興収100億円を突破したことが発表された日でした。
100億円突破したことで、天気の子の記事を書く媒体が増えた可能性があります。取り上げる媒体が増えたせいで、ニッチな媒体も増え1記事あたりのページビューが減った可能性も考えられます。今回分析に用いたデータはWEB上で観測された記事の数であり、記事のPV数ではありませんでした。さらに欲を言えば記事を見た人の数を説明変数にしたいのですが、PV数も記事を見た人数も正確に把握できる手段がないため、それを記事数で代用していました。100億円を突破した8月22日を境に、1記事あたりの平均PV数が変化している、または1記事のPV数あたり、いくつ検索数を増やすか?効果が変化していたかしれません。その双方が同時に起きていることも考えられます。このように説明変数と目的変数の関係になんらかの構造変化が起きていると仮定して、説明変数の期間を分けることで、予測精度が上げることができる場合があります。
さらに、記事数(前半と後半)と広告Tが、翌日に対して効果が〇%持続するという過程を10期まであてはめた残存効果と、投下量が増えれば増えるほど効果が減衰する非線形な影響を考慮する指数を求めることをソルバーを使って行うことで、自由度調整済み決定係数は0.948まで上がりました。予測と実績値のあてはまりも良くなっています。
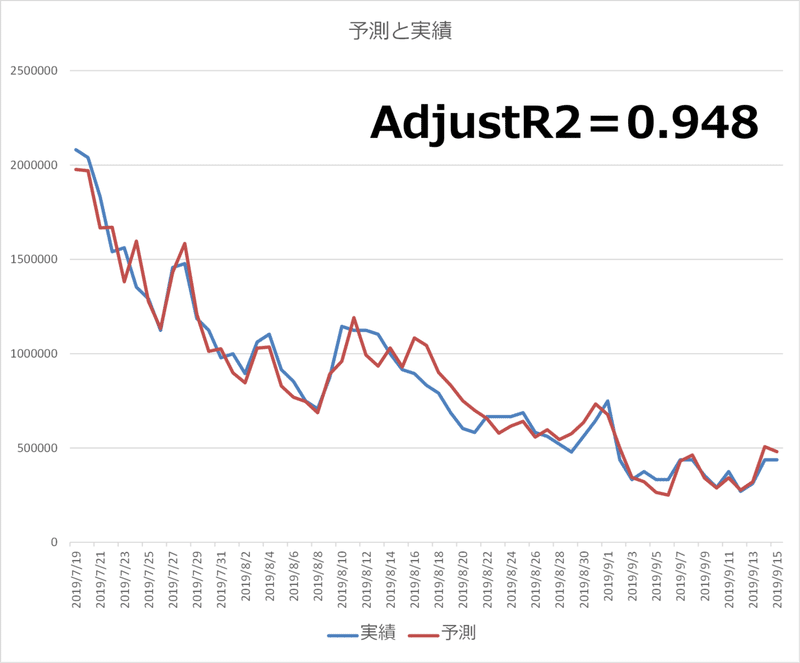
ソルバーの計算から、記事数(前半)、記事数(後半)、広告Tそれぞれに予測精度を上げるうえで最適な残存効果を考慮しています。
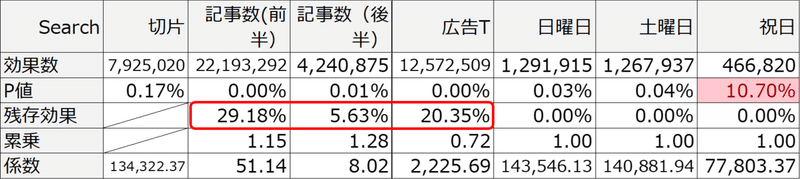
ここでは祝日のP値があらかじめ定めた水準の10%を上回っていますが残しています。予測精度を上げるための残存効果と非線形な影響を考慮するアルゴリズムは拙書Excelでできるデータドリブン・マーケティングでくわしく解説していますが、上記noteでも、ソルバーで残存効果と非線形な影響を探索する様子をアニメ付きで解説しております。
モデルから得られた結果(効果数)をウォータフォールチャートにしたものが下記です。
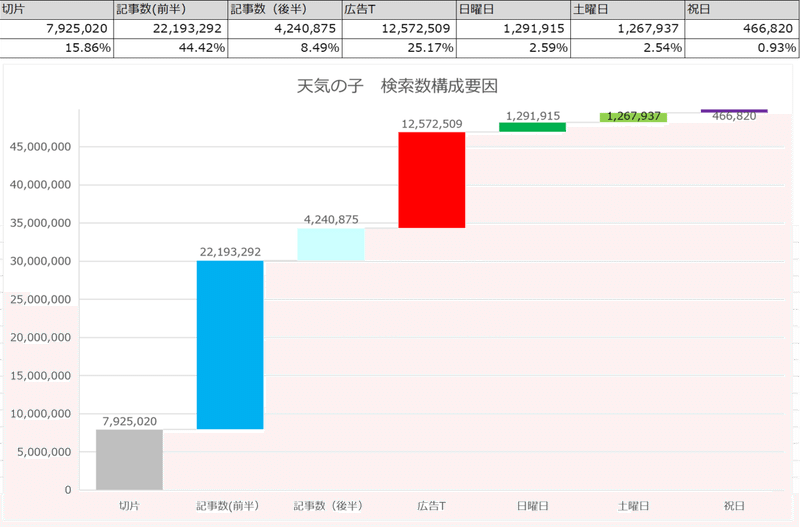
積み上げ時系列グラフは下記となります。
広告とPRに費やした金額がそれぞれ分かればアルコール飲料のデモデータで示した【予算と貢献売上の積み上げ比較グラフ】と【各施策の効果の予測グラフ】も作ることができます。
マーケティング施策の意味をよく知るマーケターのみなさんの仮説力によって予測モデルの精度を上げることができると思います。ぜひMMMにチャレンジなさってみてください!
ここで紹介したのはWEBから得られたオープン情報を使った推計データから行った分析です。WEBの記事数をPRの代理変数、広告に言及したと考えられるツイート数を広告の代理店変数として分析したものであるため、実際には、番組での露出やCMの視聴率など、シンジケートデータから取得して行う分析結果とは異なると思います。
追加情報(2023年12月18日更新)
クッキー規制で目減りする効果計測の課題を解決法をnoteにしました。無料で使えるMETA社の高機能なMMM(マーケティング・ミックス・モデリング)ツール「Robyn」を徹底解説する2時間強のYouTube講義を公開しました。