
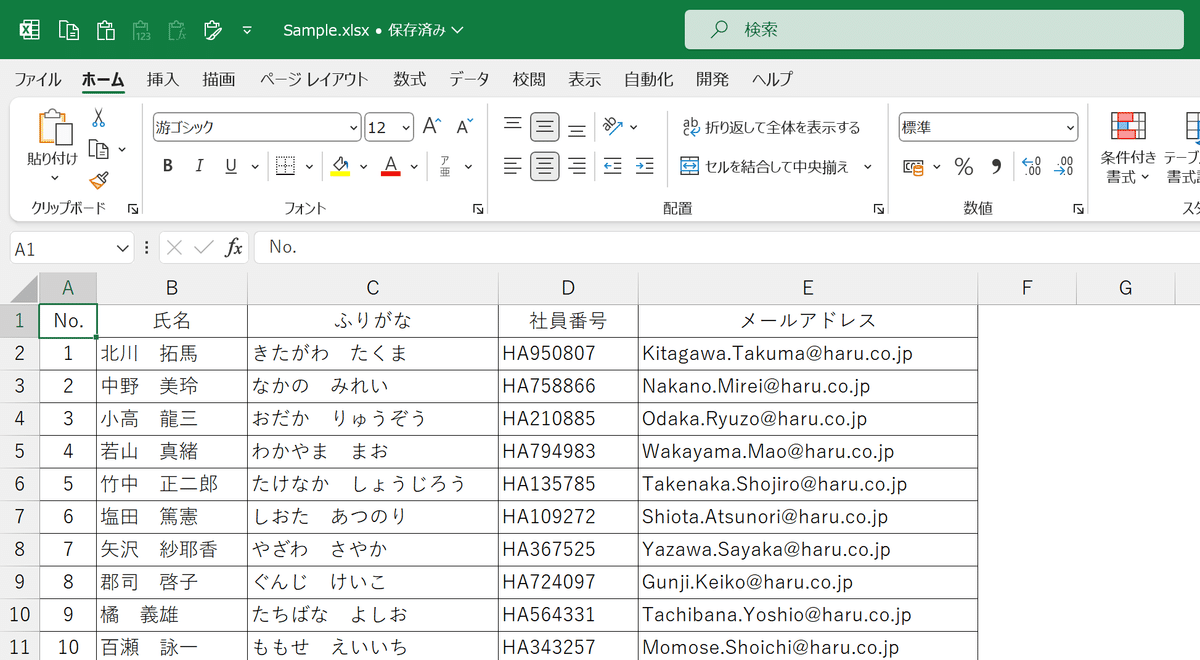
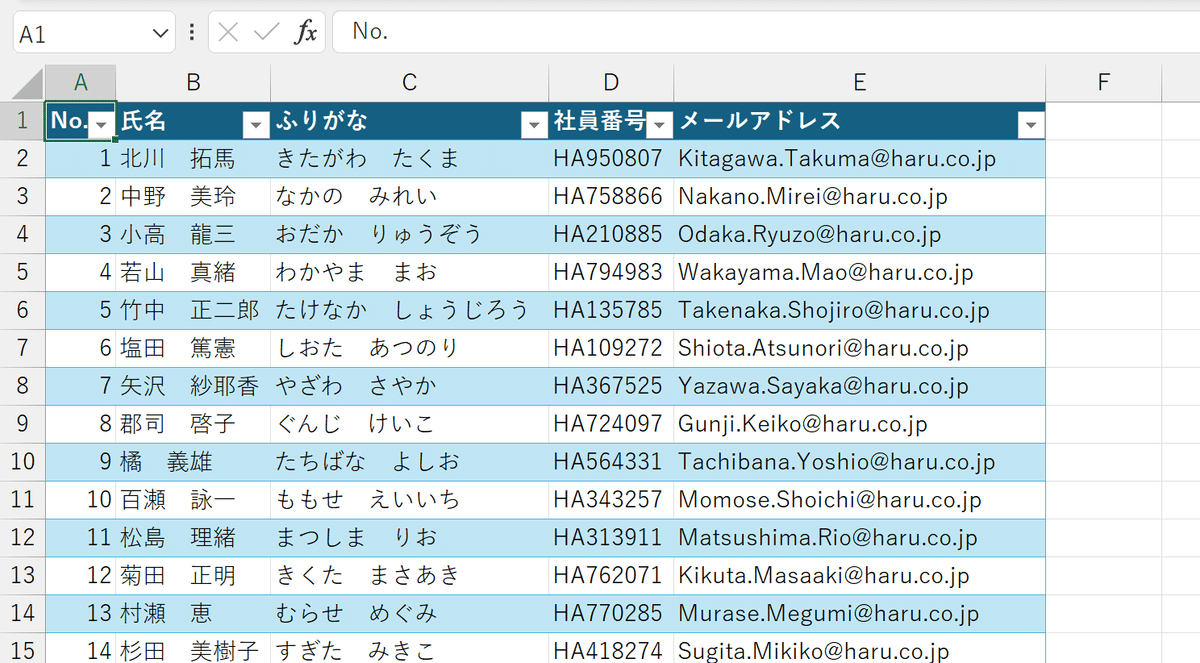
【Excel】紙の表をスキャンしてExcelに変換する方法★

こんにちは、HARUです!
今回は、PDFファイルのデータをExcelに書き出す方法をご紹介します。
実務においてはPDF形式でダウンロードした外部データや、過去の社内資料を、Excelに取り込んで加工したいことがよくありますよね。
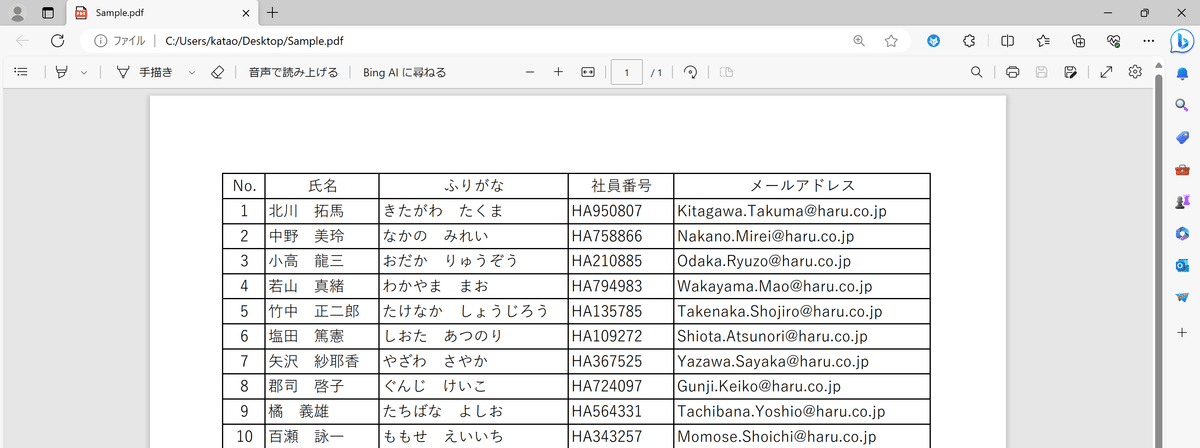
ただ、PDFからストレートにExcelに書き出す機能を使うには、往々にして専用ソフトの有料ライセンスが必要です。
PDFからExcelに直接コピー&ペーストしようとしても、すべてのデータが一つのセルにインプットされてしまいます。
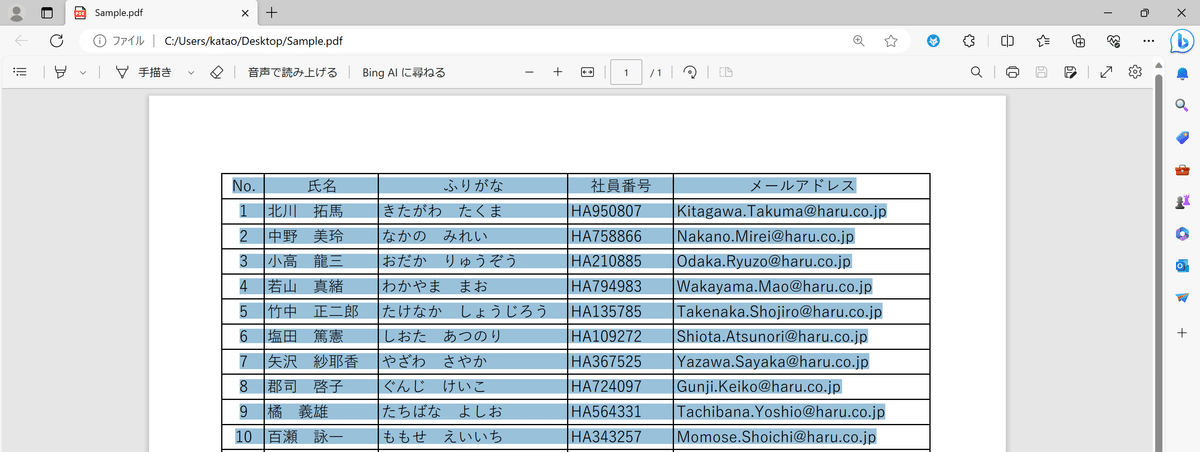
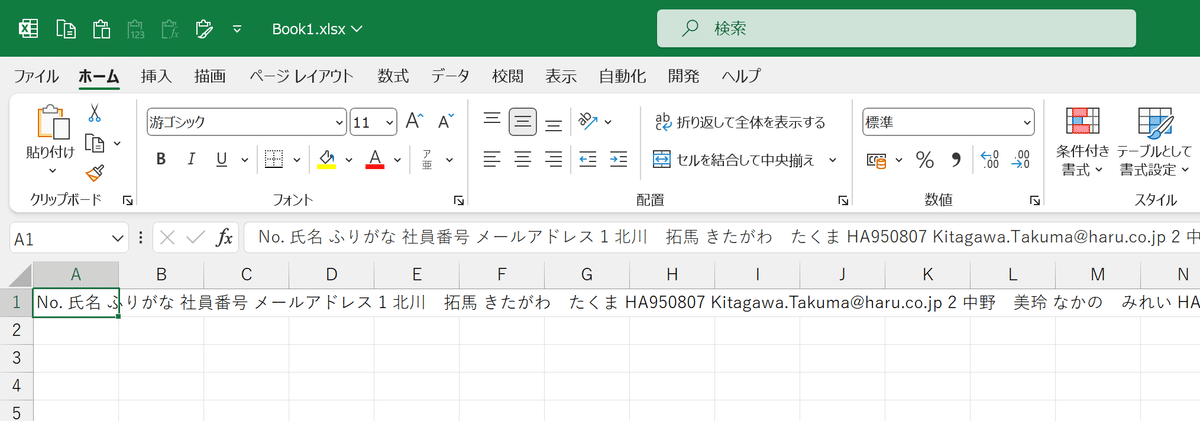
そのため、結局一つ一つ貼り付けていったり、元のデータをみながら手入力したりする手間がかかります。
また、一概にPDFといっても、PDFに変換されたそのフローによって、PDF内で認識される形式が変わってきます。
どういうことかというと、例えばExcelで作成した表をPDFに変換する場合、ファイルタブを開いて、次にエクスポートを選択します。

「PDF/XPSの作成」というアイコンをクリックすると、変換後のファイル名とその保存先を指定できます。
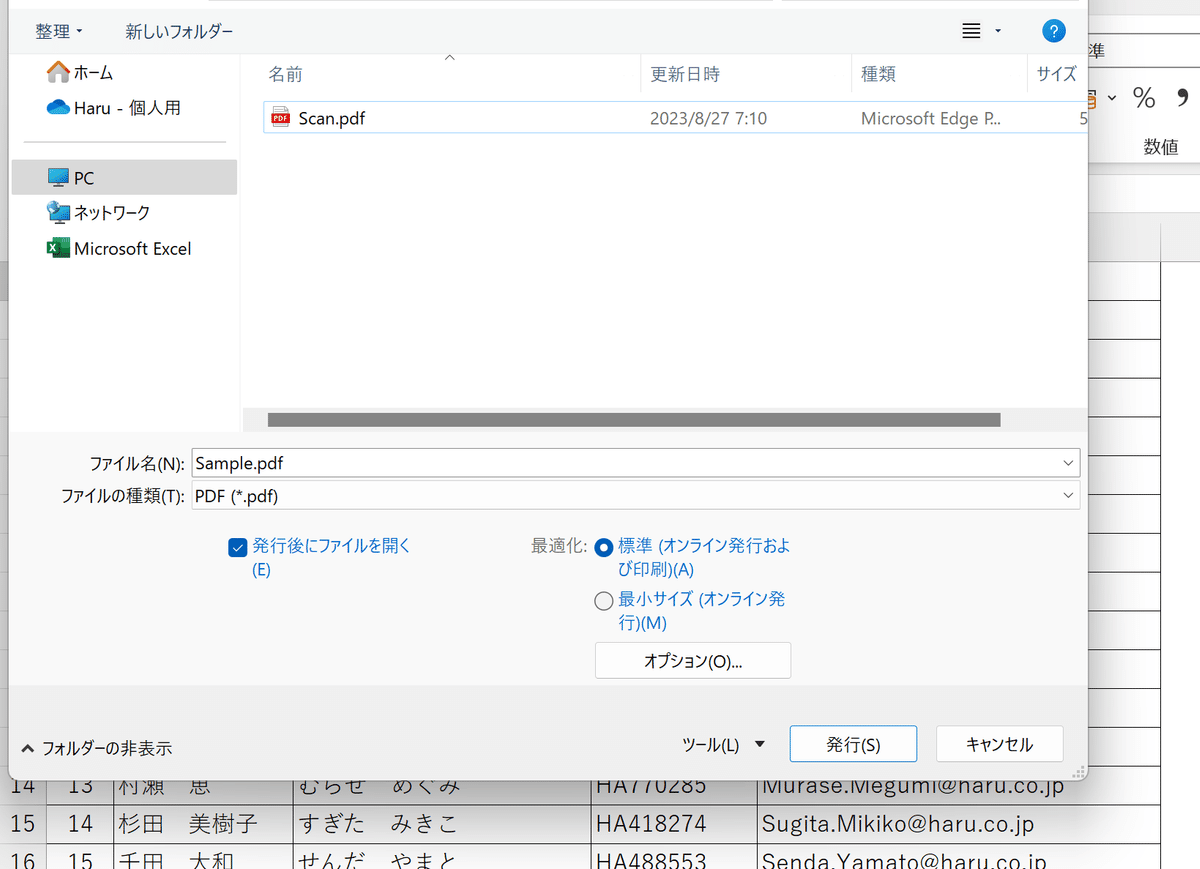
最後に発行を押せば、PDFファイルが生成されます。
この手順で作成したPDFは、元のExcelから取り込んだ値や文字、配列の情報も一緒に記憶しているので、Excelへの書き出しも比較的スムーズですが、実務で扱うPDFには、たまにこんなものもありますよね。

先ほどのPDFよりも解像度が粗く見える、オフィスの複合機などで書類をスキャンして保存されたPDFファイルです。
この場合は、データ全体が一つの画像として識別されているので、範囲選択やコピー&ペーストもできずに、Excelへの変換も容易ではありません。
そこで今回は、PDFファイルのデータをExcelに取り込む方法とあわせて、書類をスキャンして生成されたPDFをExcelに書き出す処理についても解説していきます。
実務における様々なシーンで効力を発揮してくれるテクニックですので、ぜひ最後までご視聴ください。
PDF→Excel
まずは、もともとExcelからエクスポートされたPDFファイルからデータを取得する方法を大きく3つご紹介します。
いずれの手順でも、デスクトップに置いたサンプルを使っていきます。

あらかじめ、データを取り出すExcelのブックも開いておきます。
手順①Wordを経由する
1つ目の手順ではWordを経由します。
まずはWordのアプリケーションをサクッと立ち上げましょう。
①キーボードの[Windows]キー、アルファベットの[W]、そして[Enter]を順に押します。
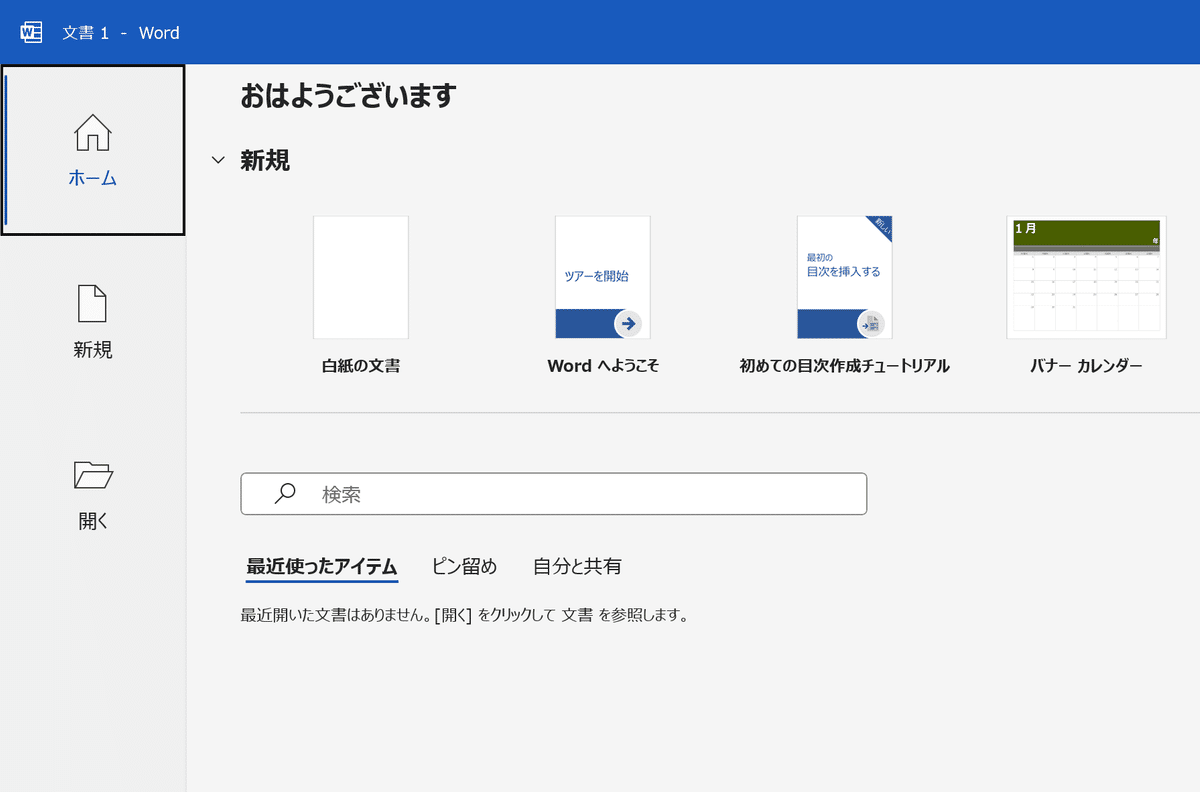
②スタートメニューが表示されたら、左にある「開く」を選択します。
※この項目は、もしすでに文書を開いている状態でも、リボンのファイルタブに切り替えれば出てきます。
③「参照」をクリックしてPDFファイルが格納されたフォルダ(今回の場合はデスクトップ)にアクセスします。

④対象のファイルをダブルクリックする、またはアクティブにした状態で右下の「開く」を押します。
パソコンの性能や取り込む情報量によっては変換処理に時間がかかること、もとのPDFとまったく同じ状態にはならない可能性があることを知らせるポップアップが表示されます。

⑤「OK」を押します。
(Wordへの書き出しが実行されます)
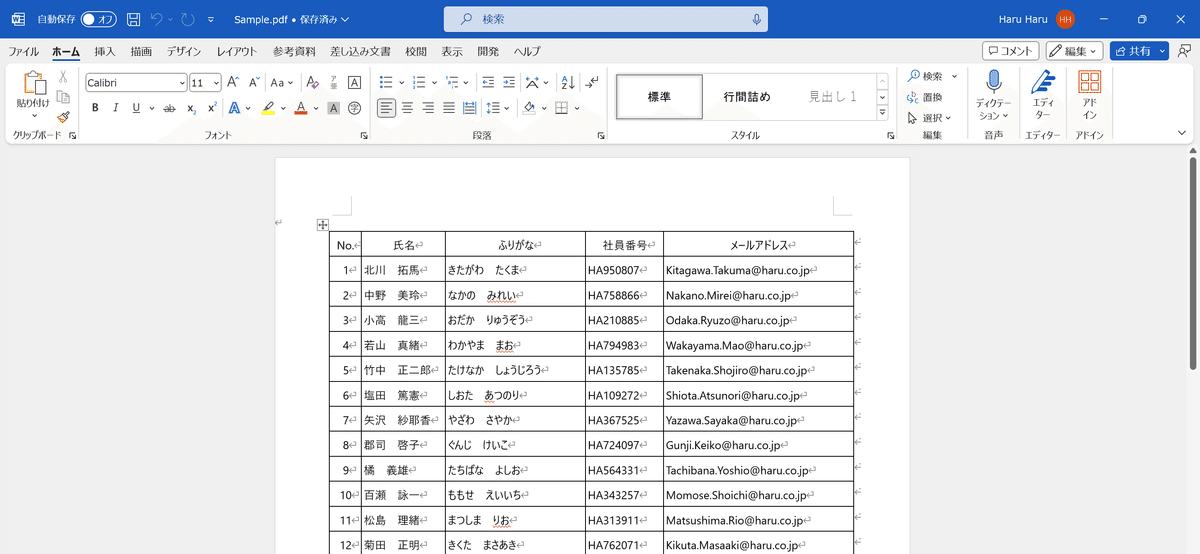
⑥[Ctrl]+[A]で全選択して、[Ctrl]+[C]でコピーします。
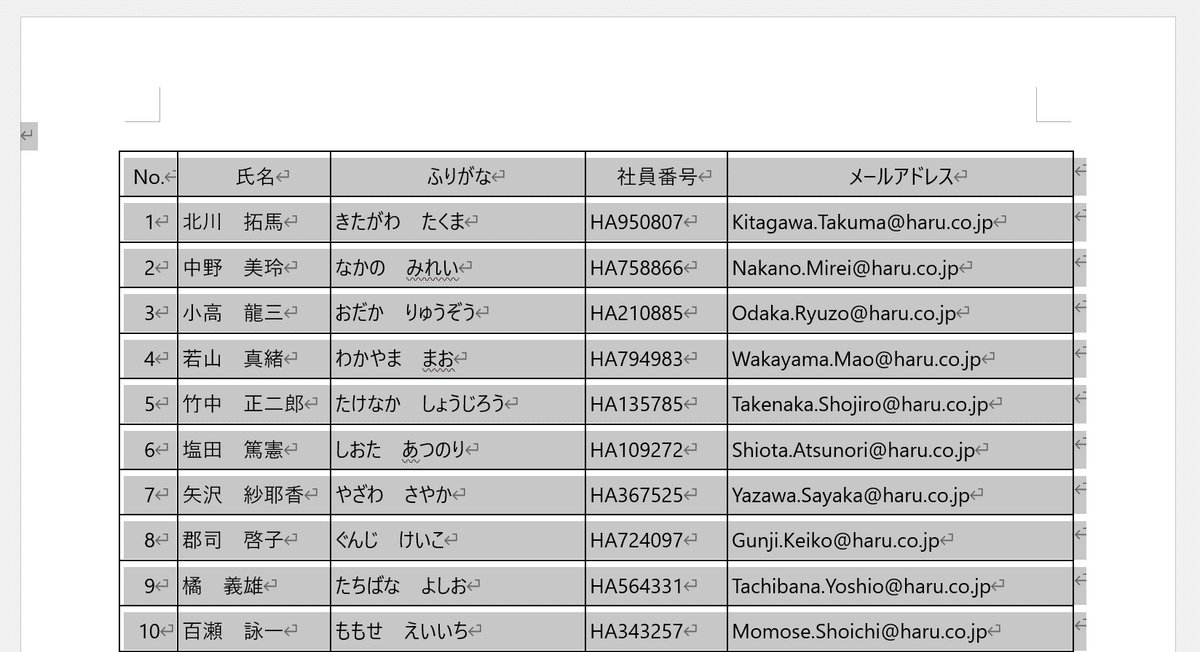
Excelに切り替えて[Ctrl]+[V]で貼り付け……ても良いですが、
⑦右クリックを押して、貼り付けのオプションから「貼り付け先の書式にあわせる」を実行すると、編集しやすい状態でペーストされます。

あとは列幅を調整したりテーブル化したりと、お好みでアレンジしていくだけですね。
手順②メモ帳を経由する
2つ目の手順ではメモ帳を経由します。
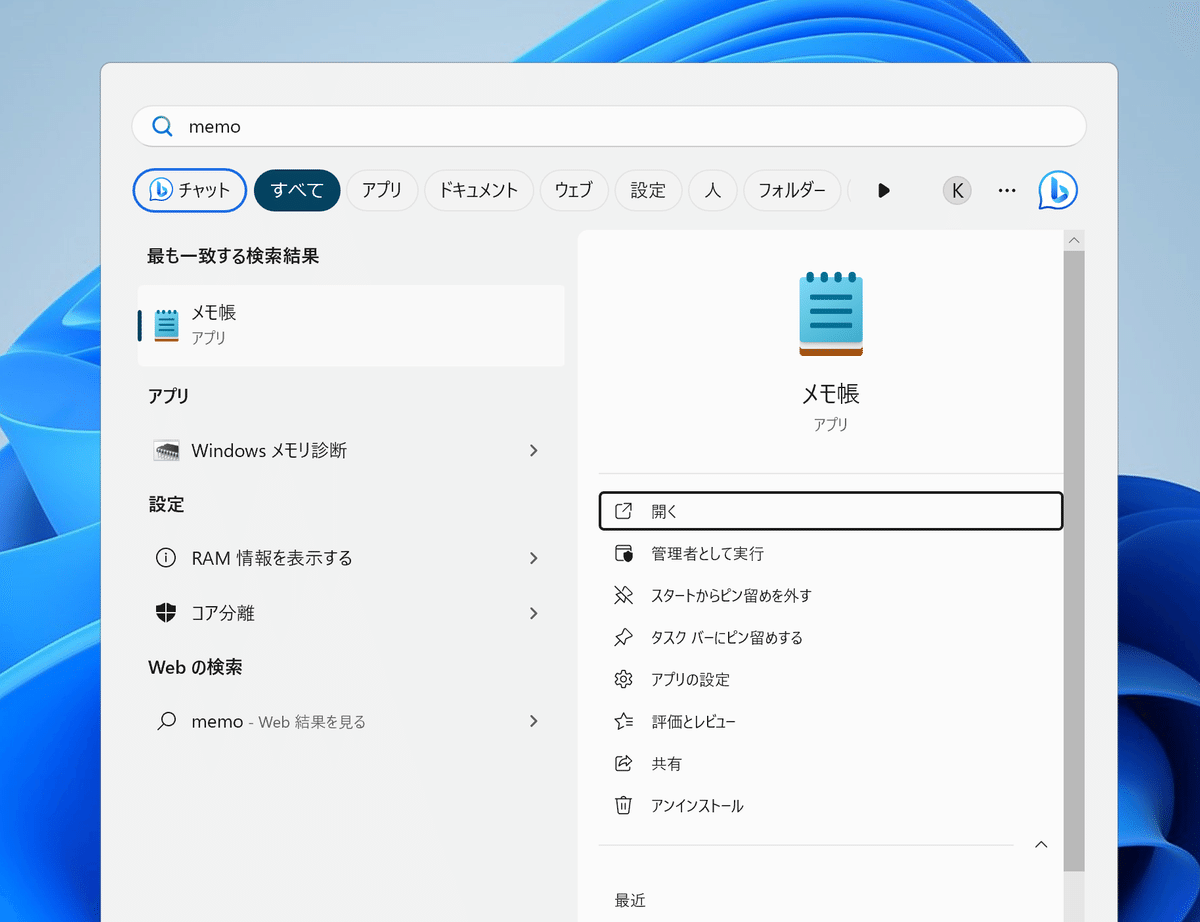
①[Windows]キーを押して「memo」と検索し、メモ帳アプリが候補として選択されたら[Enter]で立ち上げます。
②PDFに切り替え、対象のデータをすべて選択してコピーします。
③メモ帳に戻り、[Ctrl]+[V]で貼り付けます。
結果、メモ帳では以下のようなレイアウトで並びます。
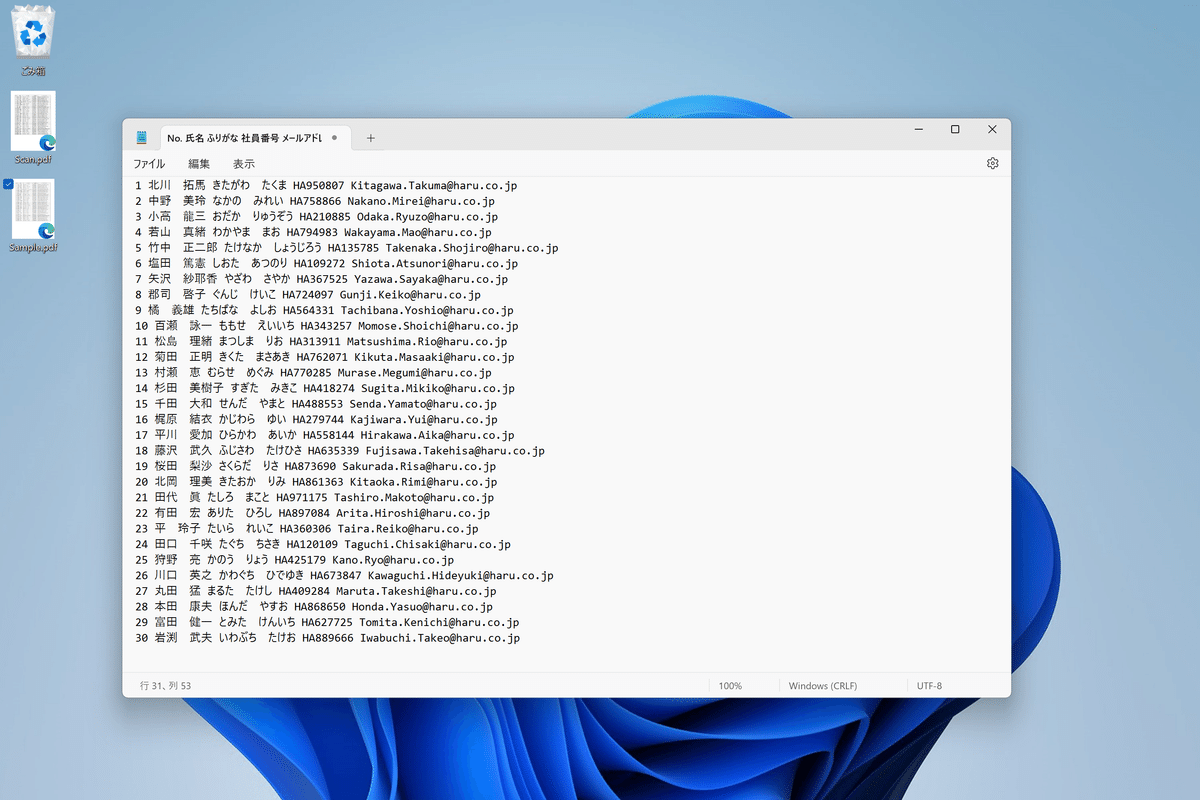
④このデータをすべて選択してコピーします。

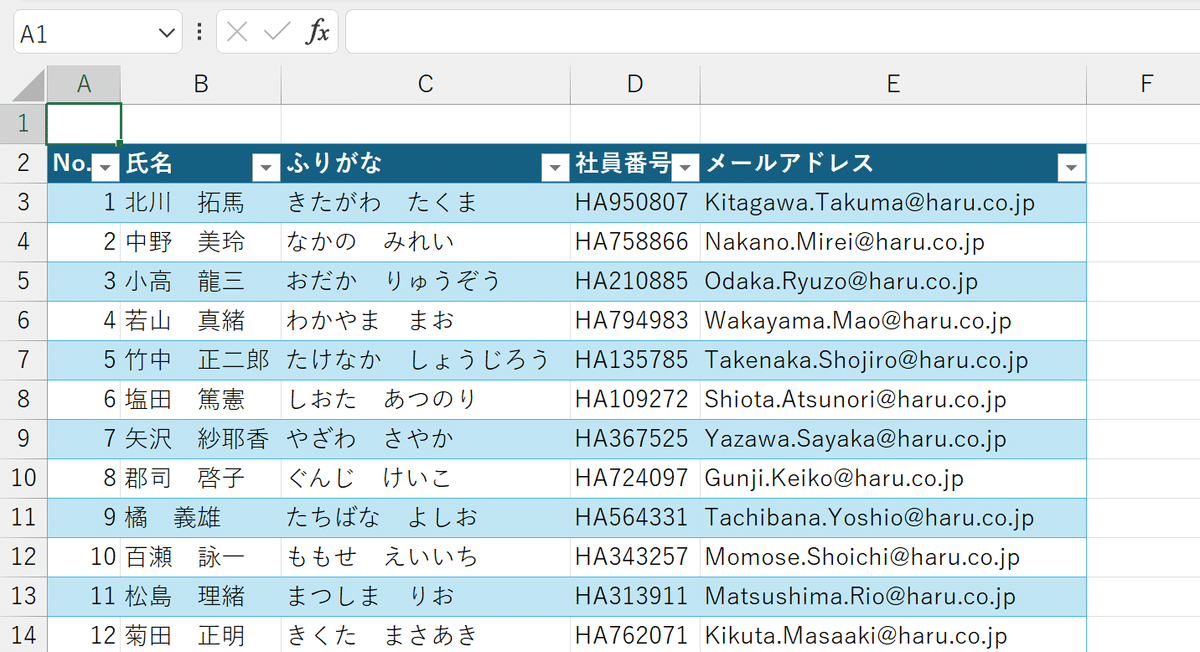
⑥Excelに切り替えて、Ctrl+Vで貼り付けます。
この段階で「行」ごとには分かれましたが、各レコードが1列にインプットされます。それぞれの項目は半角スペースで連結しています。
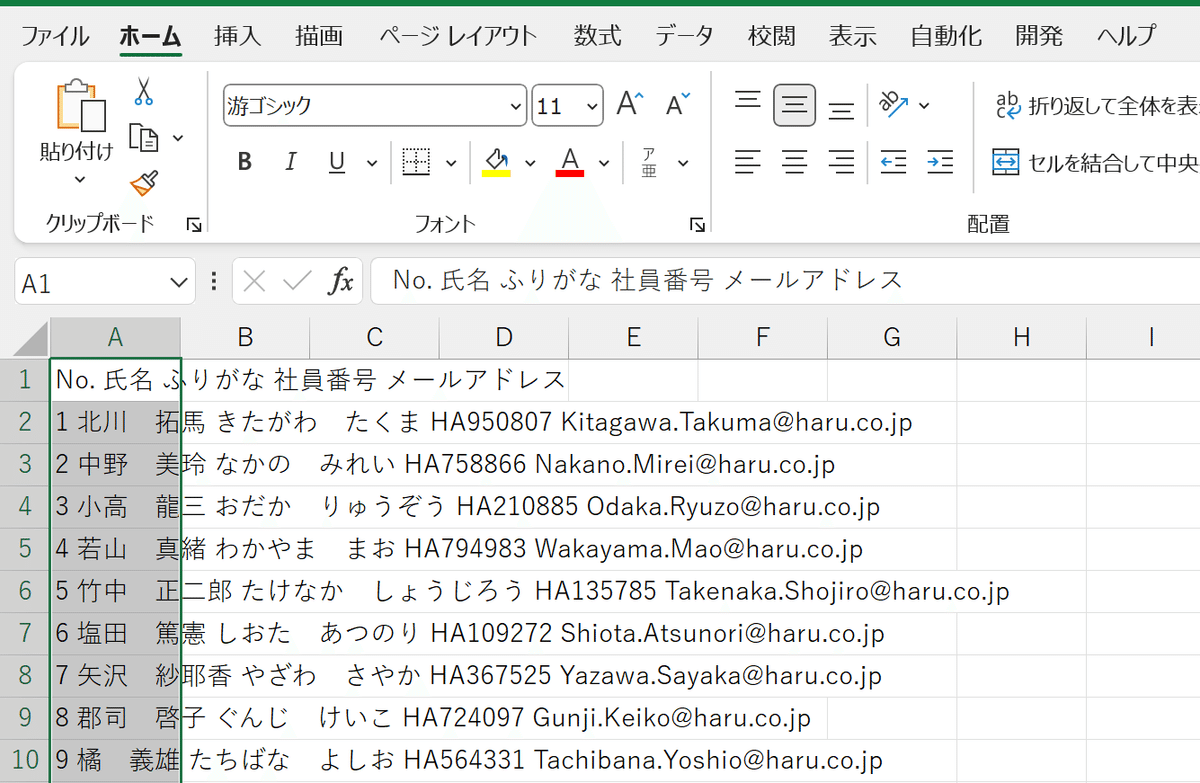
これのデータを、Excelの「区切り位置」という機能を使って、B列、C列、D列と分割していきます。
⑦対象のデータを選択して、「データ」タブ→「区切り位置」のアイコンをクリックします。

ここでいくつか必要な設定をしていきます。
最初のページでは元データの形式を指定します。
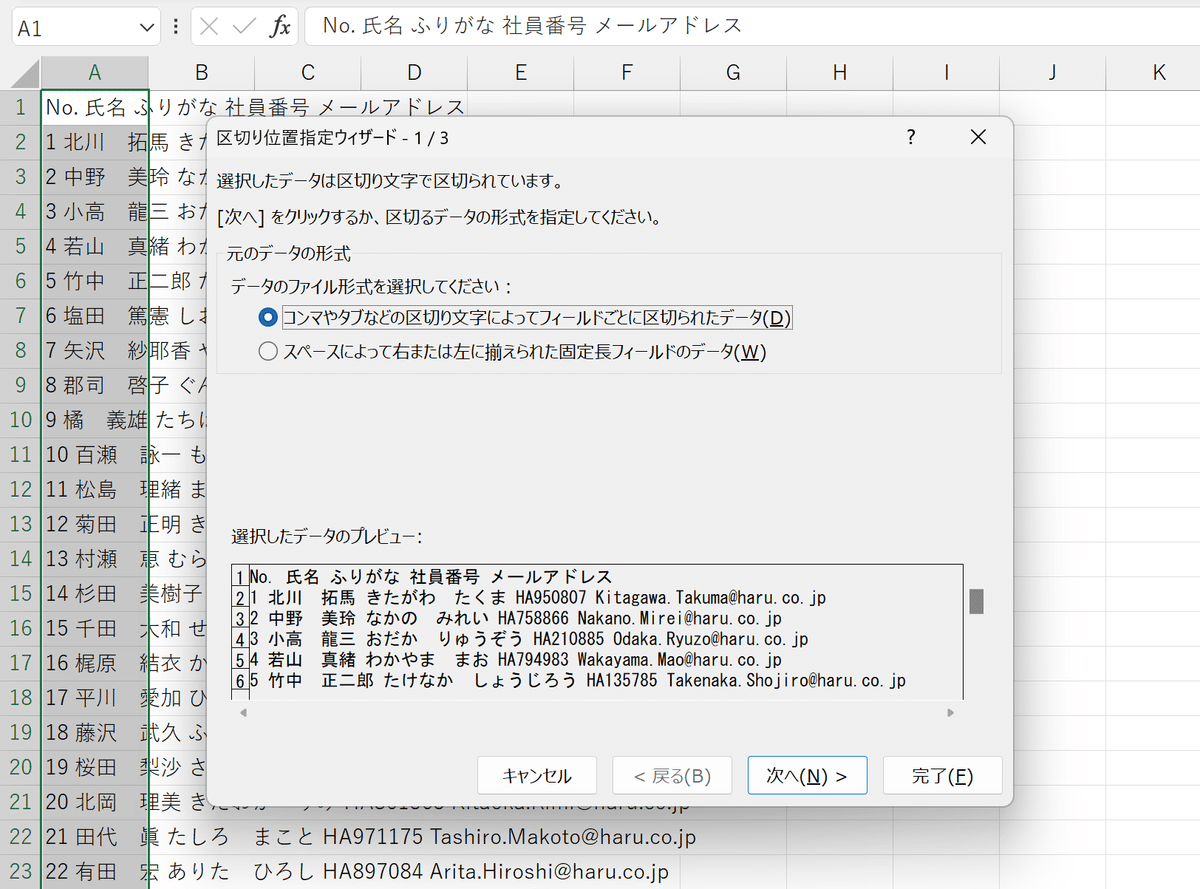
⑧デフォルトで選択されている「コンマやタブなどの区切り文字によってフィールドごとに区切られたデータ」のまま、右下の「次へ」をクリックします。
2つ目のページでは、区切り文字を指示します。
試しに、デフォルトで選択されている「タブ」から「スペース」に切り替えてプレビューを確認すると、苗字と名前の間にある全角のスペースも区切りの対象となります。
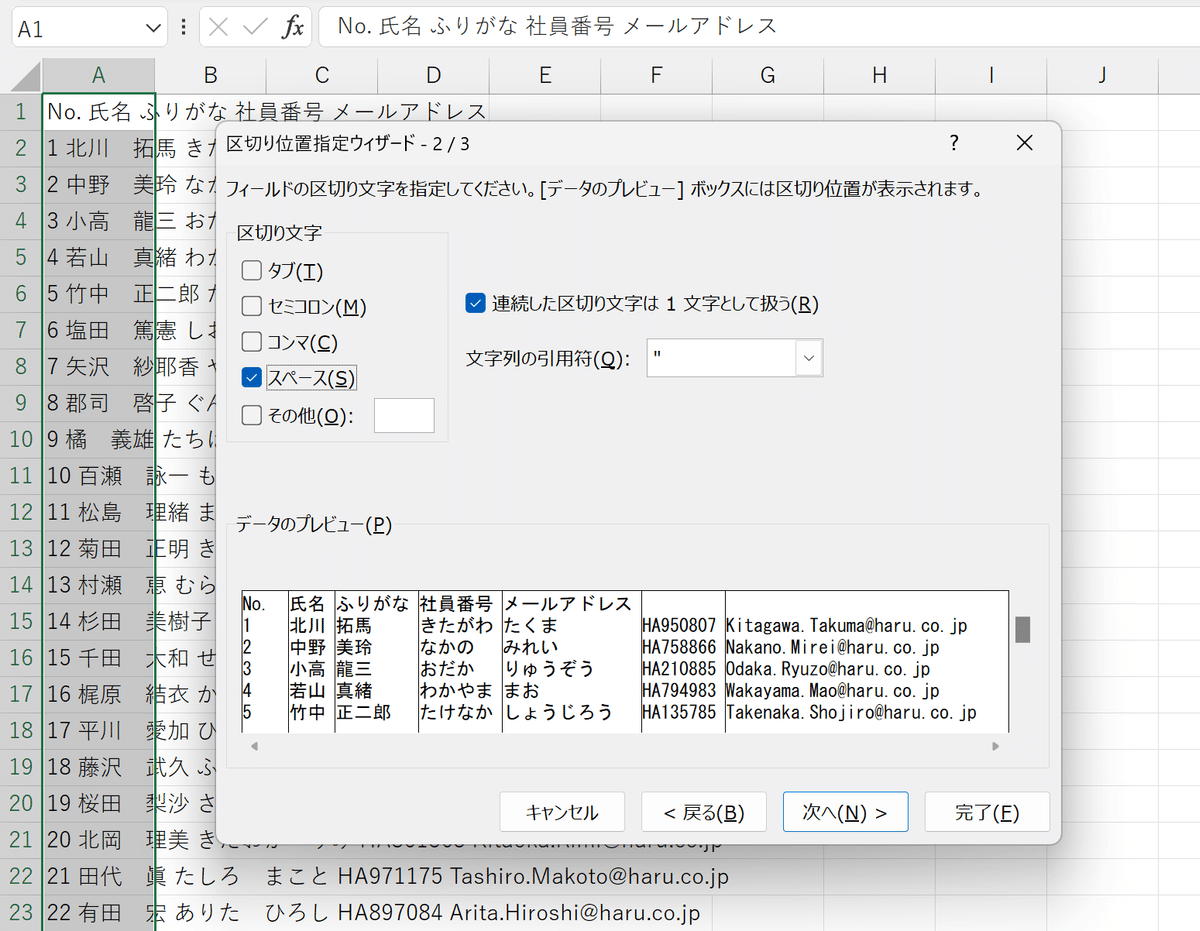
⑨全角スペースで姓名が分割された氏名とふりがなを1つのセルにおさめるには、「スペース」ではなく「その他」にチェックし、右の入力欄に半角スペースをインプットします。

ここまで設定できたら、次に進みます。
3つ目の画面では特に設定は変更しなくてOKです。
⑩「完了」をクリックします。

結果、半角スペースで区切られていた各項目を分割できます。
あとはこちらもお好みで書式を仕上げていきます。

なおこの手順の場合、元のPDFに結合セルや空白セルがあるとその部分はメモ帳に転記した段階でデータが詰めて表示されます。
区切り位置で分割したあとに手直ししましょう。
また、お使いの PDFアプリによっては、メモ帳に貼り付けたときの配列が変ったり、そもそもコピー&ペーストができなかったりします。
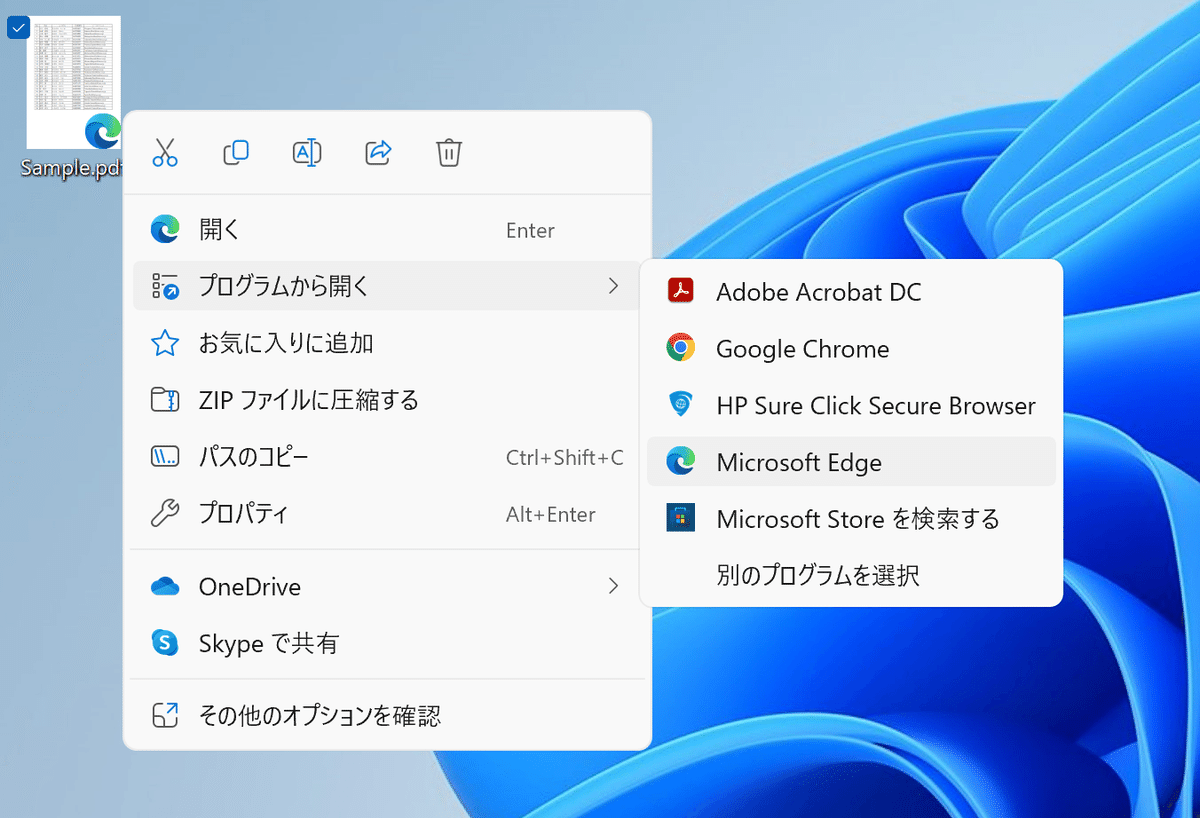
メモ帳を経由する場合は「Microsoft Edge」や「Google Chrome」といったブラウザ系のプログラムで開かれることをおすすめします。
手順③Excelでデータを取得する
もしお使いのExcelが「Microsoft 365」の最新バージョンであれば、PDFから直接データを取得できます。
(あらかじめOfficeのバージョンを確認しておきましょう)
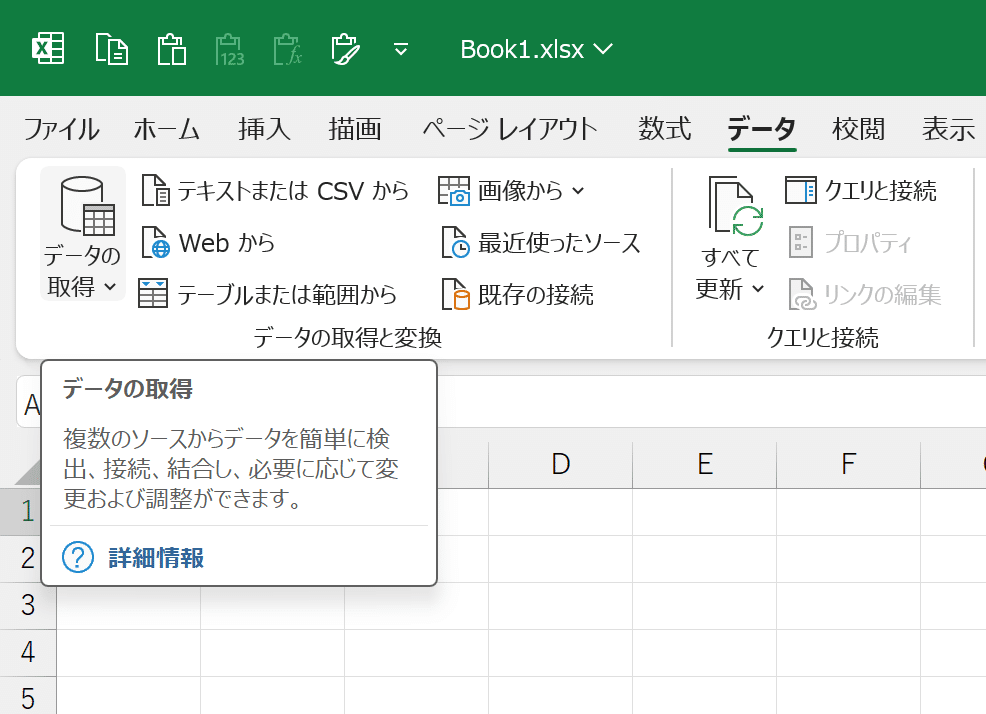
①リボンの「データ」タブを開き、「データの取得と変換」グループにある「データの取得」をクリックします。
②「ファイルから」→「PDFから」を選択します。

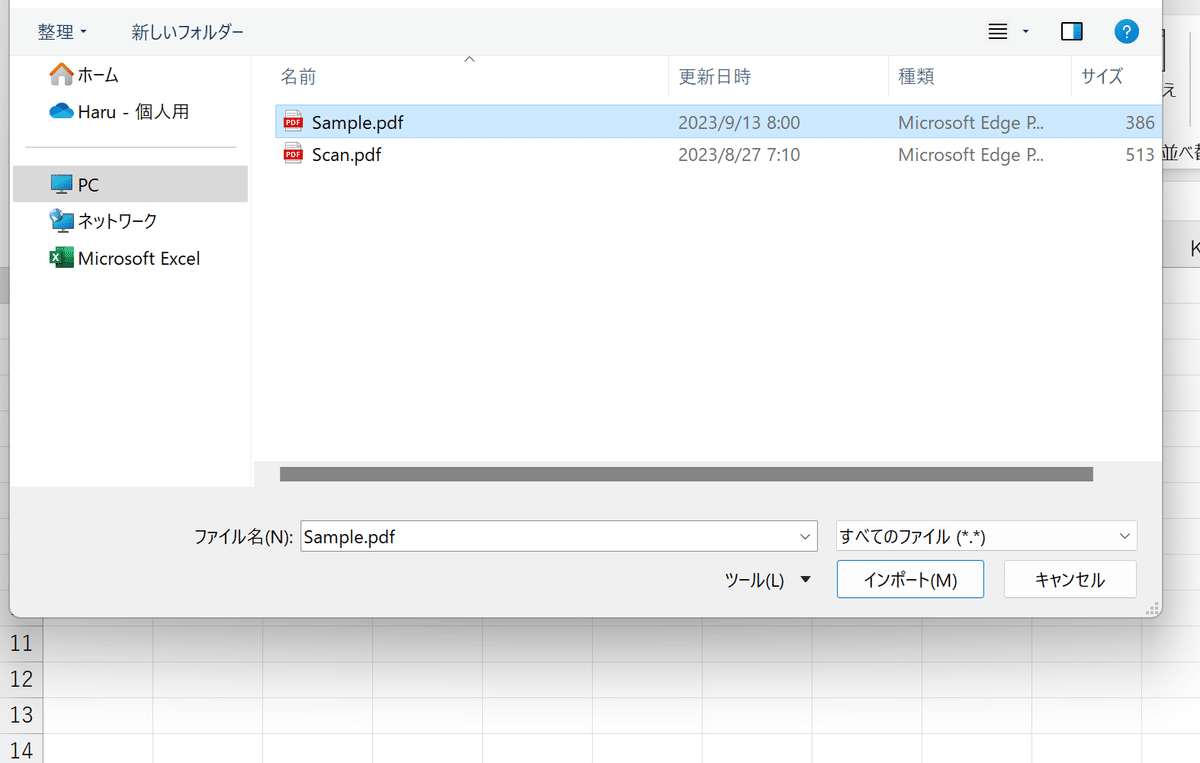
③対象のPDFが格納されているフォルダにアクセスして、ファイルをダブルクリック、またはアクティブにした状態で右下の「インポート」を押します。
④ナビゲーターが現れたら、Table形式を選択します。
(読み込んだ後のイメージがプレビュー表示されます)

もし読み込む前に表を加工したい場合は「データの変換」をクリックしてPowerQueryエディターで編集します。
⑤特に手直しする必要がなければ、「読み込み」を実行します。
結果、デフォルトで列幅の調整もテーブルの適用もなされた状態でデータを取得できます。非常に便利ですよね。
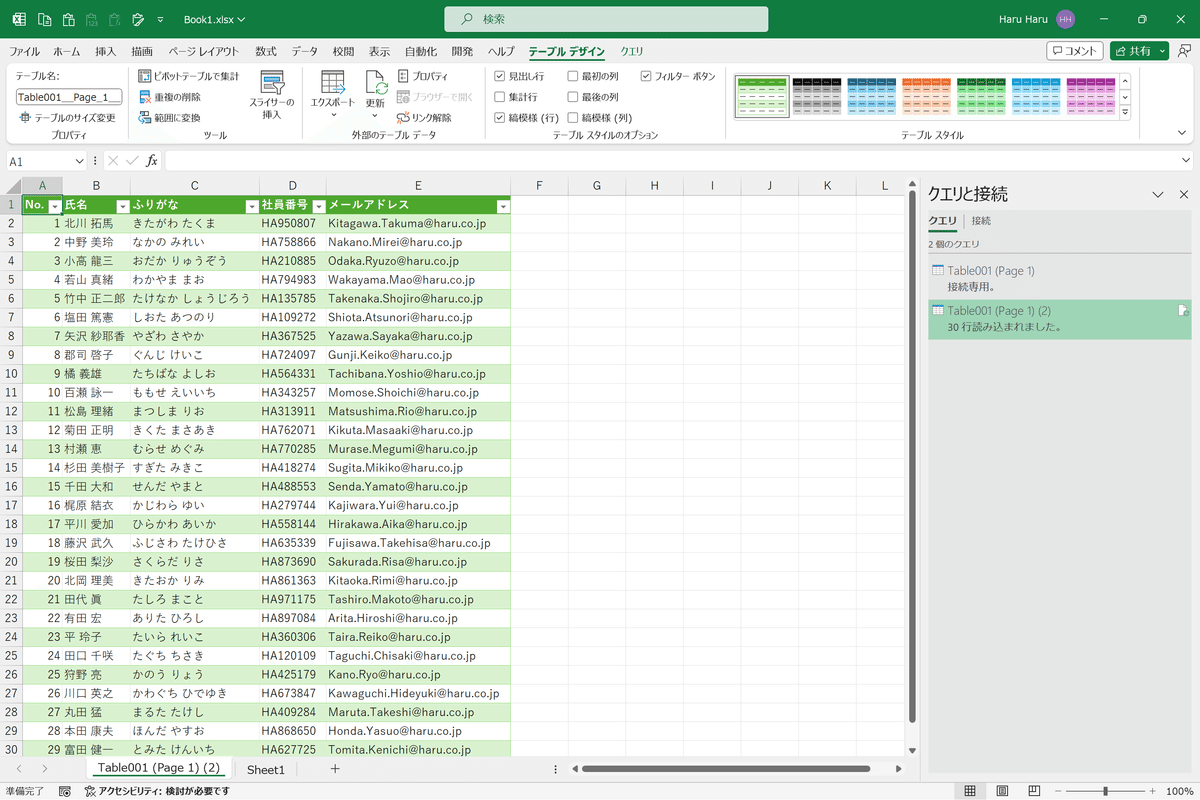
スキャンデータの取得
ここまで解説した3つの手順が、はたして書類をスキャンしたPDFでも使えるかを検証してみます。
①Wordを経由した場合
こちらは該当のファイルをWordで開いた状態です。

データのヌケモレがあったり、文字化けがひどかったりします。
PDFの解像度がさらに低いともっとごちゃごちゃしそうですね。
②メモ帳を経由した場合
メモ帳を経由しようとしても、そもそもスキャンしたPDFのデータは選択したりコピーしたりできる状態になっていないため、NGです。
③Excelでデータを取得した場合
ExcelにPDFから直接データを取得しようとしても、ナビゲーターに「Table」形式が表示されず、データを読み込めないことがわかります。

OCRとは?
こうしたデータを文字や配列として認識させるには、適切な処理が求められます。これを、OCRといいます。
「OCR=Optical Character Recognition(Reader):光学的文字認識」

画像として存在する活字や手書きのテキストを読み込み、デジタルの世界で加工したり編集したりできる文字コードに変換するソフトウェアのことを指します。
身近なものでは、交換した名刺を撮影して電子データとして保存しておけるアプリなどをイメージしていただくとわかりやすいかもしれません。

「PDF OCR」などと検索すると、様々な変換ソフトがヒットします。
こうしたフリーソフトをお勤め先のデバイスで使う場合は、セキュリティやウイルス対策の観点から、必ず情報システムの担当セクションに相談してからインストールしましょう。
一般・個人の使用環境でも、お使いのパソコンに適切なセキュリティ対策、ウイルス対策が施されていることが前提です。
おすすめの変換ソフト
今回は買い切り型のライセンスが安価な、Wondershare 社「PDFelement」というソフトで検証してみます。
▼CD-ROMからインストール▼
▼WEBからインストール▼
変換ソフトを入手する(WEBから)
①「購入する」または「今すぐ購入」にアクセスして、OCR処理に対応した「プロ版」の購入手続きに進みます。

※製品のバージョンや価格は本記事執筆時点の情報です。予告なく変更される場合があります。
インストールとセットアップをガイダンス通りに行っていくと、PDFファイルを右クリックして出てくる「プログラムから開く」に、入手したソフトが追加されます。
②Scanデータを「Wondershare PDFelement」で開きます。
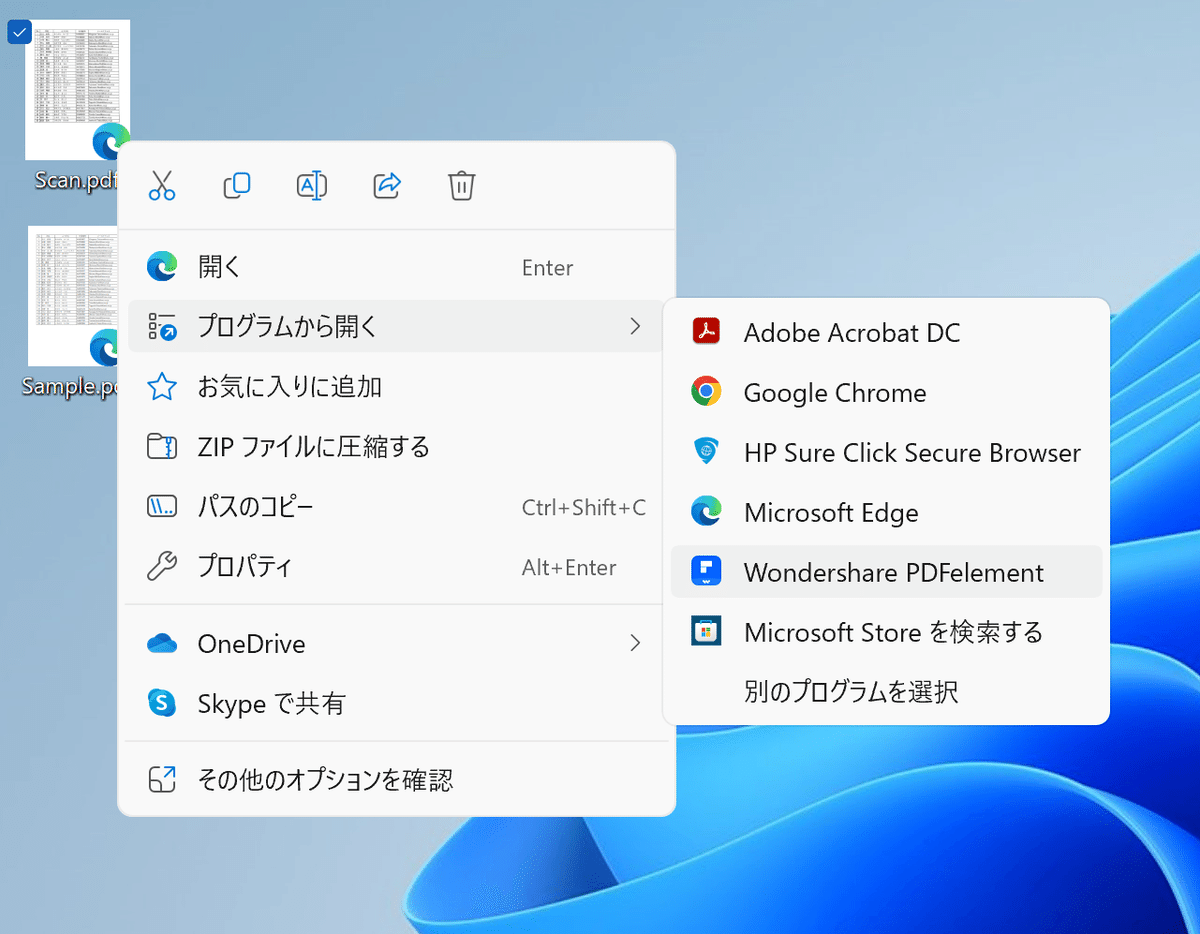
こちらがホーム画面です。
スキャンされたPDFファイルであることがすでに認識されています。

初めて「OCR処理」を行ったり、「変換」タブから各ソフトに変換したりする際は、OCRシステムのダウンロードが要求されます。
追加の費用はかかりませんでしたので、案内に従って実行しましょう。
データをExcelに変換する
実際にデータを変換していきます。
①「変換」タブから、「Excelへ」を選択します。

②出力フォーマット、ファイル名、出力先フォルダを確認し、「OK」で実行します。
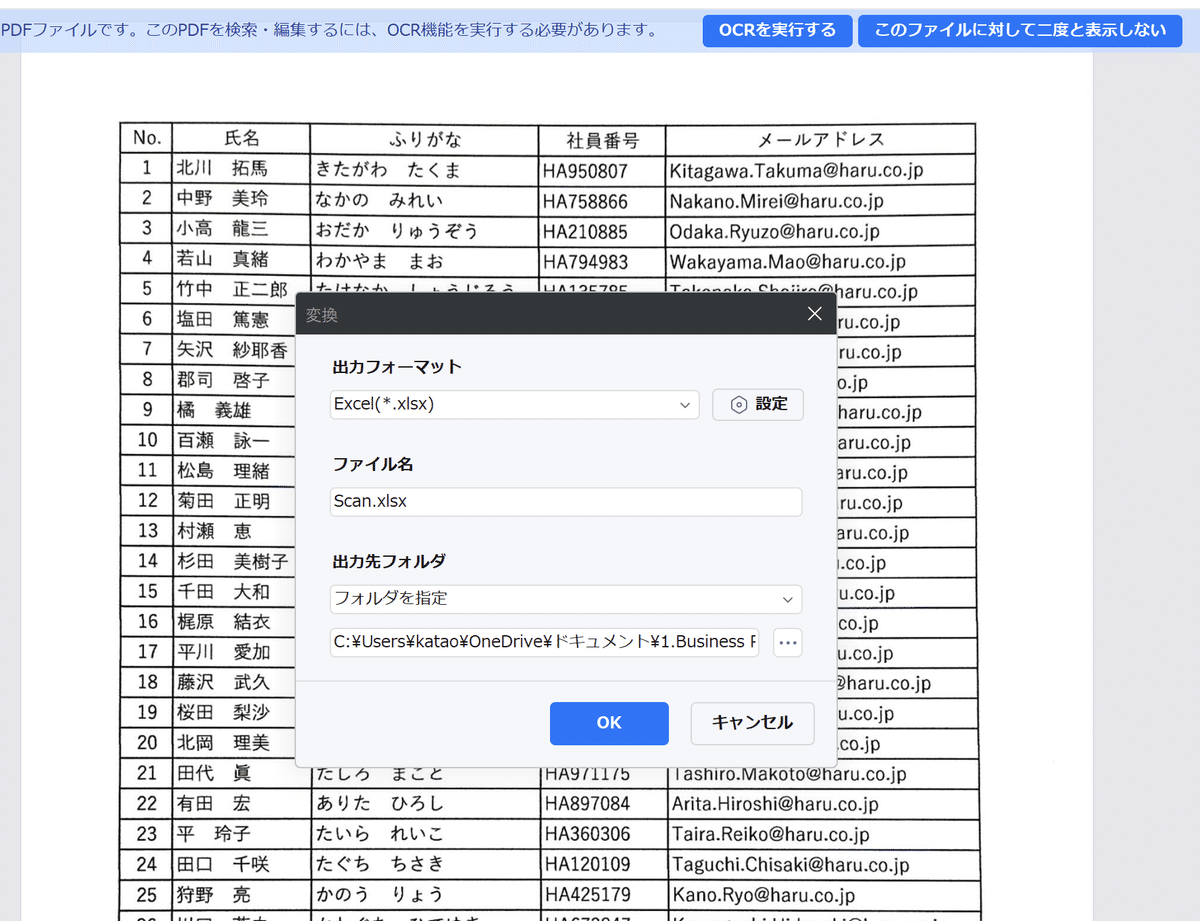
処理が始まり、正常に変換されると出力先のフォルダにすぐアクセスできます。

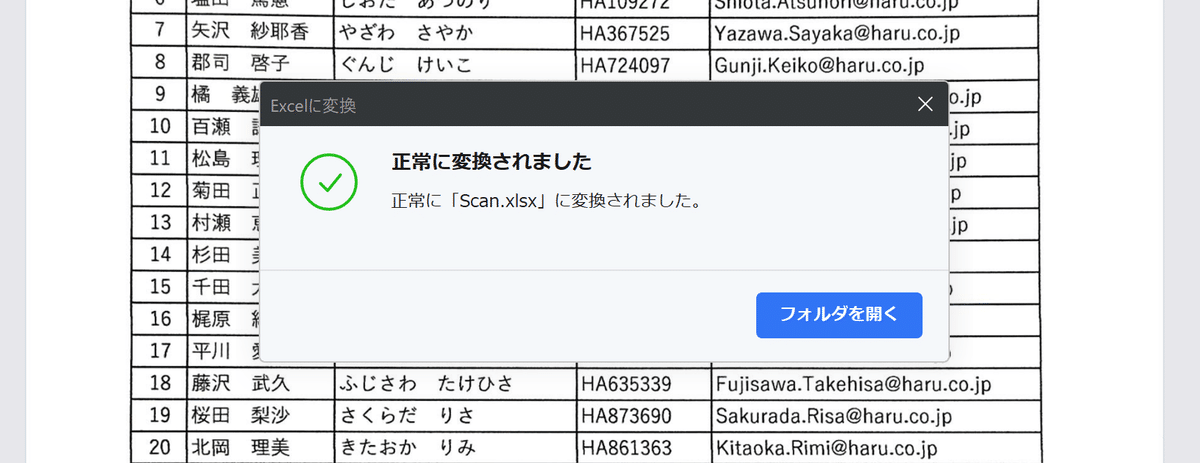
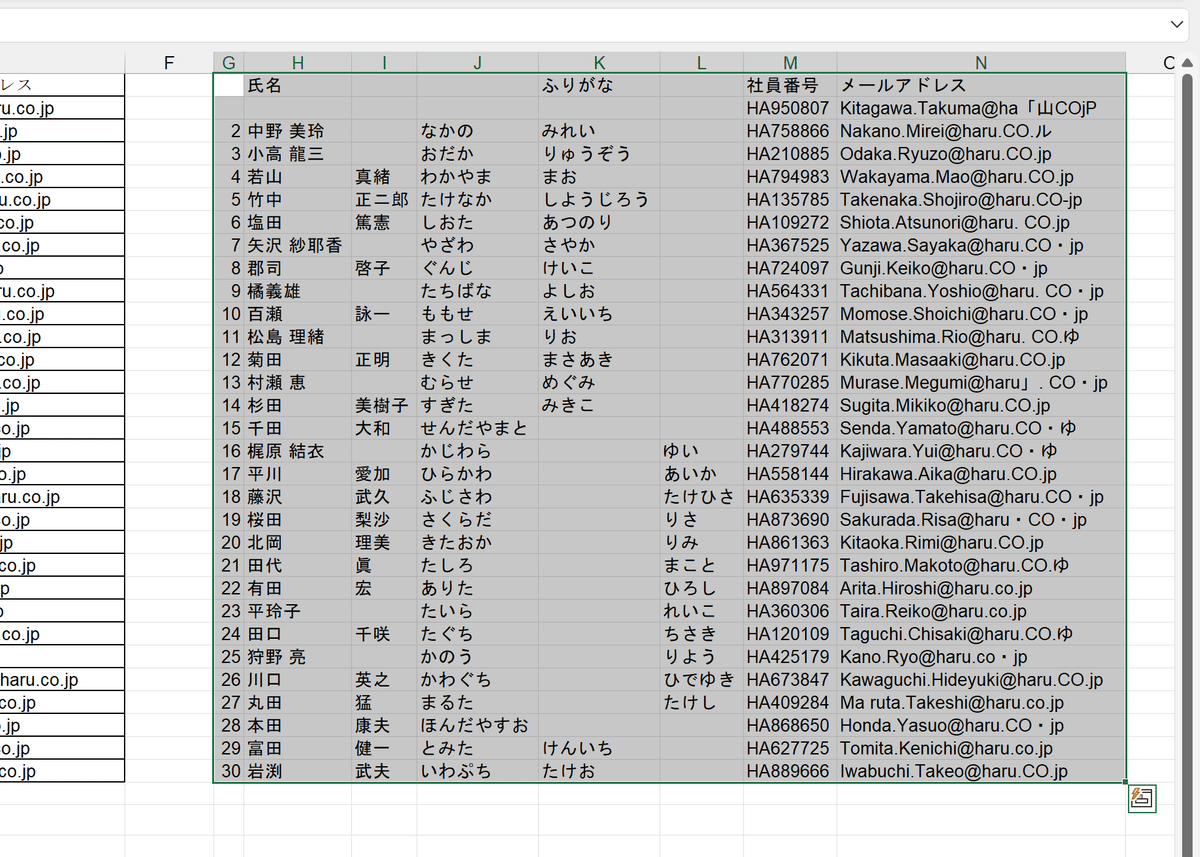
③変換後のファイルを開きます。

元のPDFデータからフォントが変っていたり、苗字と名前のスペースが詰められていたりしますが、とても綺麗に変換できています。
いちから手入力するよりも圧倒的に効率的ですよね!
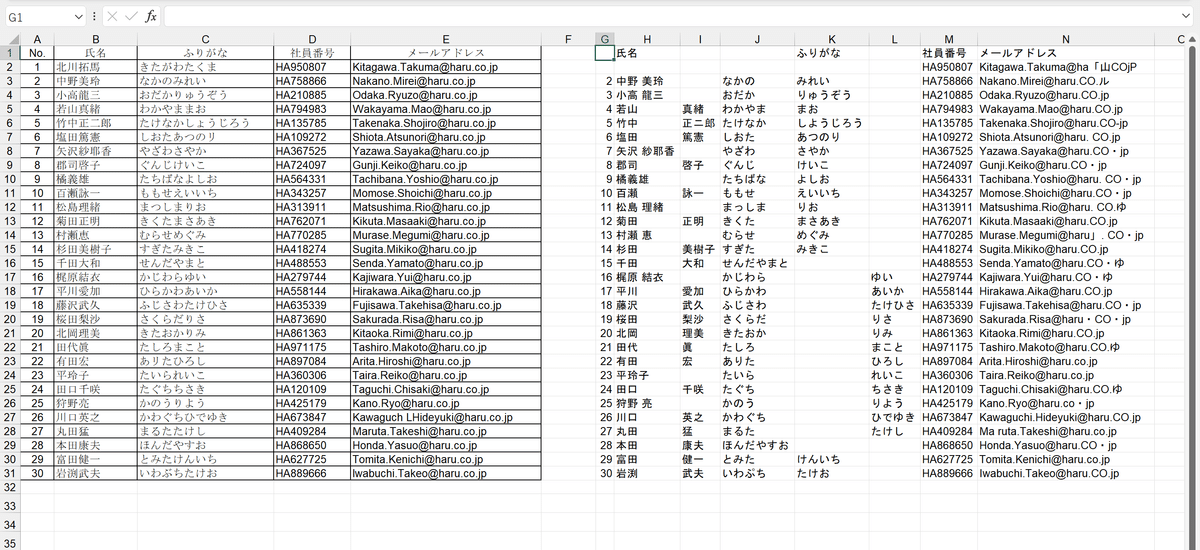
ちなみに元のデータがPDFではなく画像形式で保存されていれば、Microsoft365の「画像から」データの変換機能が使えます。

ただし解析結果をそのまま取得してみると、ヌケモレがあったり、苗字と名前の区分けがまちまちだったり、メールアドレスに文字化けが見られたりします。
「PDFelement」の解析能力が非常に高いことがわかりますね。
まとめ
以上のように今回は、PDFファイルのデータをExcelに変換する方法をご紹介しました。
スキャンデータの処理では比較的シンプルでくっきりした紙面をサンプルにしたので、読み取ったあとにほぼ無加工で済みましたが、印字がにじんでいたり、手書きの文字を読み込んだり、ファイルの解像度が低かったりすると、多くのデータが文字化けしてしまう可能性があります。
OCRの解析処理もまだまだ発展途上ですので、Excelに取り込んだあと、必要に応じて手直ししていきましょう!
↓↓記事の内容を動画で解説しています↓↓
※本記事の委細が動画収録当時のバージョン・解説内容と異なる場合があります。
↓↓Excel操作をとにかく高速化したい方へ↓↓
↓↓実務直結の関数活用術を網羅的に学びたい方へ↓↓
この記事が気に入ったらサポートをしてみませんか?