
YouTube 研究しちゃいなよ。(仮題)

仮題 YouTube についての研究
YouTube data API とか使わないもの。単純で明解に。もっとフルスクラッチ。 これは、けっこう長いハナシになります。シンプルな考え方なので、むずかしくはない How to です。
プログラムから YouTube を検索
python で使う標準ライブラリ以外のインストールが必要なプログラム
BeautifulSoup4
> pip install beautifulsoup4
python プログラムで import します。
コードを書くファイルは、youtube_jsontest.py にします。
youtube_jsontest.py
import urllib.request
import urllib.parse
import re
import json
import pprint
from bs4 import BeautifulSoup
▲ <code :001>
はい。では、まず、YouTube の web サイトでキーワード検索をします。
キーワード検索とは、"無頼派" という言葉で関連する動画を探したい場合に、なんだか形容しにくい枠 ( webサイトの上の方にあります ) に、無頼派 とタイプして、なんだか形容しにくいマーク ( 形容しにくい枠の右側の何か ) をクリックする、あのことを指します。
▼ あのことのイメージ。
<画像リンク>
https://i.postimg.cc/rF1zbsz9/Screenshot-20231115-004844-kindlephoto-82007459.png
これを python でコードにします。コードを書くファイルは、`youtube_jsontest.py` です。
import urllib.request
import urllib.parse
import re
import json
import pprint
from bs4 import BeautifulSoup
# search key words
words = "無頼派"
keywords = urllib.parse.quote(words)
target_url = "https://www.youtube.com/results?search_query=" + keywords
html = urllib.request.urlopen(target_url).read()
html_strings = html.decode()
del(html)
▲ <code :002>
△さっきの、ライブラリの import のコードと合わせるとこうなります。
html_strings
プログラムを実行してキーワード検索して、html_strings というのが、検索したあとに結果が web ブラウザに戻ってきたときの html ファイルと同じテキストになります。
このテキストの中を見ていけば、いいということになります。
つづけていくと
json_strings = ""
soup = BeautifulSoup(html_strings, 'html.parser')
for ind,script_tag in enumerate(soup.find_all('script')):
if (jsonscript := re.search('ytInitialData',str(script_tag))):
#print(ind)
#print(jsonscript.group())
#print(str(script_tag)[0:200])
json_strings = str(script_tag)[58:-10]
break
del(soup)
json_dict = json.loads(json_strings)▲ <code :003>
△ BeautifulSoup4 を使い、html_strings の実態である HTML の中を探索します。まず、見つけたいのは <script から始まる、<script> タグになります。<script></script> で挟まれたものは javascript で書かれたプログラムコードですが、このコードの中に、YouTube がレスポンスした動画の情報が全て含まれている JSON 形式のデータがあるからです。
YouTube は、検索結果を JSON 形式のデータにして、それを javascript で変数に入れているという HTML をレスポンスするというわけです。
re.search('ytInitialData',str(script_tag))
▲ これは、レスポンスの HTML の <script></script> タグのの中にあるだろうと思われる "ytInitialData" という文字列を探します。レスポンスの HTMLには、<script></script> タグがかなりありますが、現段階でここでは "ytInitialData" が含まれるものは、2つあるだろうと想定していて、そのうちの HTML の上から下へサーチして最初に見つかる1つ目の<script></script> タグの内に目的の JSON 形式のデータがあります(と現段階で想定しています。)。JSON 形式のデータを含む <script></script> タグを見つけると、その文字列からJSON 形式のデータだけスライスして json_strings という文字列として変数に入れます。
▼ <script></script>の中の JSON データ部分を string( python の文字列型データ)で取り出して、dict ( python の辞書型データ)に変換したものを JSON ぽくプリントアウトして見るには、json.dumps を使います。( json.dump ではないことに注意してください。)
pprint でインデント付きでプリントアウトします。
pprint.pprint(json.dumps(json_dict, indent=2)▲ <code :004>
とても長い。そして、とてもじゃないけど、見てられないと思う量のテクストが流し込まれている事実に気がつきます。
これを見ていきます。
構造がわからない深い、深いネストの JSON データを初見で見るのは、python ではとても辛いです。心が折れます。
しかし、もともと javascript の基本的なデータ構造ですから、 javascript で扱うには全く辛くないというものが JSON データです。でも、python, Ruby だと辛いです。( Go 言語だと辛くはないと思いました。)
▶ Cf. node.js ( javascript ) https://hastebin.com/share/yalelexiga.javascript
まず、データの構造を把握してから、その後になら扱えます。ということを事実として先に把握しておかないと、パッと見て、こんなのは無理だと心が折れるバイアスが相当にあります。
でも、データの構造を把握できます。これは見やすくできます。
JSON の恐ろしく長い一行を Linux ターミナルで見るのは、流れる川をみつめるような感じではないでしょうか。
「あるな」ということはわかっても、どこに何があったか上へいったり、下へいったりしても何千行かに相当する一行だとタイヘン。
ということで見るのを止めてしまうことでしょう。
まずどうなっているのか見たい、こう思います。思え。
簡単には、Jupyter Notebook では、JSON が折り畳まれて表示されます。おそらくデフォルトでそうなっています。「折り畳まれて」というのは、Tree 表示というものです。
VSCode でもそうなっているとおもいます。
つまり、JSON ファイルをTree 表示させると見やすい わけですね。
実際見てみないとわかりません。そのためにまず、 <code :004> を実行 することで、絶望感をまず味わう、その後に「これをどうするんだ」という気持ちになったという経験を解決していきます。
まず、JSON データをファイルに出力します。
#print(json.dumps(json_dict, indent=2))
with open("testjson.json", "w") as f:
json.dump(json_dict, f)
exit()▲ <code :005>
こんどは、json.dump です。
s が付かないことに気をつけてください。
<code :004> の時は、json.dumps でしたが、<code :005> では、json.dump です。
ここまでの全体のコードはこうなります。▶ https://hastebin.com/share/wevoqikaxo.python

<code :005> を実行すると testjson.json というJSONファイルができました。
これを、jsoneditoronline.org というところにアップロードしました。
▼ testjson.json
https://jsoneditoronline.org/#left=cloud.7e0964eb463546ff8aa5cbe2112982c4
URL をクリックして、見るとこのようになっています。Tree 表示で折り畳まれていて、見やすいですよね。 見やすくないはずがない。これは Jupyter Notebook でも VSCode でもない方法としてオンラインの JSON エディターをつかうというものです。
( Jupyter Notebook や VSCode よりすぐれているという意味ではないです。それらが無い場合に使えます。)
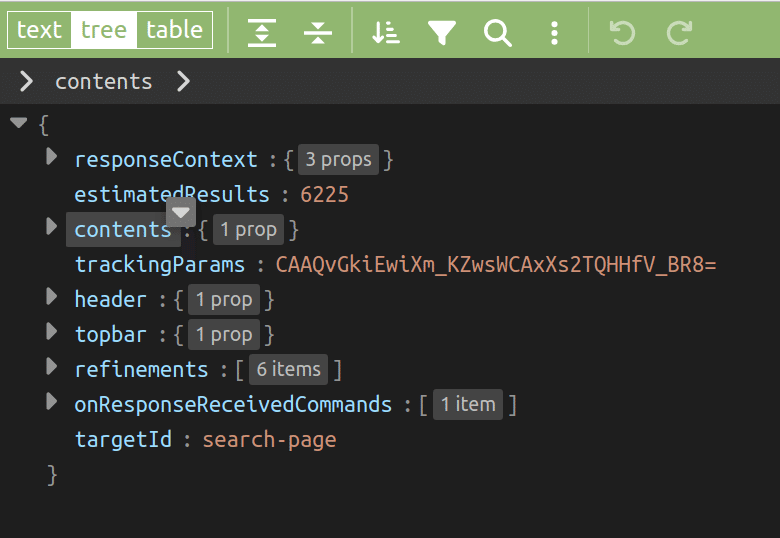
▲ <testjson.json>
さて、とても見やすい Tree 表示で見ると、


検索結果のYouTube動画の情報はどこに入っているかというと、
Path:
contents.twoColumnSearchResultsRenderer.primaryContents.sectionListRenderer.contents[0].itemSectionRenderer.contents
上から2番目の▶ contents を▼開いて、どんどん開いていくんですね。
▼ contents
▼ twoColumnSearchResultsRenderer
▼ primaryContents
▼ sectionListRenderer
▼ contents[0]
▼ itemSectionRenderer
▼ contents : [ 22 items]
で、そこに 22 コありますね。何かが。22 items となっています。

一つ一つ、開いたり閉じたりしてみる。

よく見ると、この 1 コづつが、ブラウザでの検索結果に現れる動画への情報と結び付いています。
"無頼派" という言葉で YouTube 検索すると、関連する動画として、まずいくつか表示されます。それが、22 コあるわけですね。
それを確認するには、videoId と title に注目します。
videoId とは、YouTube の動画ひとつひとつに割り振られている 11 文字です。

具体例 をあげると、YouTube 動画の URL である
https://www.youtube.com/watch?v=KuiRKInwl10
の最後の 11コの文字列
KuiRKInwl10
これが videoid でありvideoId です。
では、jsoneditoronline.org で確認しながら、それを参照しつつ、レスポンスで得た JSON を python で構造を見ていきます。
<code :003> まで戻って、そのつづきに書き足します。もしくは <code :005> の最後の 3 行をコメントアウトしてから、つづきに書きます。
[print("key:", k) for k in json_dict.keys()]▲ <code :006>
全体のコードはこうなります
▶https://hastebin.com/share/piyuruhewi.python
<code :006> を実行すると以下のようにプリントアウトされます。
key: responseContext
key: estimatedResults
key: contents
key: trackingParams
key: header
key: topbar
key: targetId
さっきから見ていたのは、contents の中ですから、当然、そこには、なにかイッパイ入っているわけです。
contents.twoColumnSearchResultsRenderer.primaryContents.sectionListRenderer.contents[0].itemSectionRenderer.contents
testjson.json
という JSON の path は、python の dict 型で表現するとこうなります。
json_dict['contents']['twoColumnSearchResultsRenderer']['primaryContents']['sectionListRenderer']['contents'][0]['itemSectionRenderer']['contents']▲ <code :007>

では、videoId を抽出したいならば、['twoColumnSearchResultsRenderer']['primaryContents']['sectionListRenderer']['contents'][0]['itemSectionRenderer']['contents'] のあとに、 [0] から [20] まで個々にあるデータから、それぞれの videoId の値を抽出するようにすればいいわけです。

title も抽出したとすると、

主要なパラメーターをみたい場合は、

この記事が気に入ったらサポートをしてみませんか?