
MediaPipe 入門 (1) - Pose

以下の記事を参考にして書いてます。
1. MediaPipe Pose
「MediaPipe Pose」は、動画から人間の姿勢を推論するライブラリです。動画から全身の33個のランドマーク位置または上半身の25個のランドマーク位置を予測できます。
2. モデル
◎ Person/pose Detection Model (BlazePose Detector)
「Person/pose Detection Model 」は、人体の中心、回転、スケールを示す2つのキーポイントを予測するモデルです。
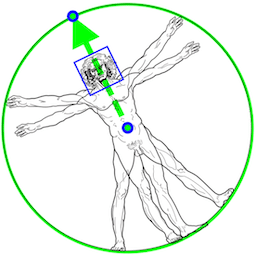
◎ Pose Landmark Model (BlazePose GHUM 3D)
「Pose Landmark Model 」は、ランドマーク位置を予測するモデルです。33個の全身のランドマーク位置を予測する「全身モデル」と、25個の上半身のランドーマーク位置を予測する「上半身モデル」があります。
詳しくは、BlazePose Google AIブログ、論文、モデルカード、以下の「ランドマーク属性」を参照してください。

3. ソリューションAPI
◎ オプション
・STATIC_IMAGE_MODE : 静止画かどうか。(true:静止画,false:動画, デフォルト:false)
・UPPER_BODY_ONLY : 上半身のみかどうか(false:上半身のみ,true: 全身, デフォルト:false)
・SMOOTH_LANDMARKS : ジッターを減らすかどうか。静止画では無処理。 (デフォルト:true)
・MIN_DETECTION_CONFIDENCE : ランドマーク検出成功とみなす最小信頼値。([0.0、1.0], デフォルト:0.5)
・MIN_TRACKING_CONFIDENCE : ランドマーク追跡成功とみなす最小信頼値。([0.0、1.0], デフォルト:0.5)
◎ 出力
・POSE_LANDMARKS
ランドマークのリスト。
各ランドマークは、以下で構成されている。
- x : ランドマークのX座標。([0.0、1.0])
- y : ランドマークのY座標。([0.0、1.0])
- z : ランドマークの深度。腰の中点を原点として、値が小さいほどカメラに近くなる。全身モードでのみ予測される。([0.0、1.0])
- visibility : 画像表示(存在し遮られていない)の可能性。([0.0、1.0])
4. Python ソリューションAPI
◎ サポートオプション
・static_image_mode
・upper_body_only
・smooth_landmarks
・min_detection_confidence
・min_tracking_confidence
◎ コード
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_pose = mp.solutions.pose
# 静止画像の場合:
with mp_pose.Pose(
static_image_mode=True, min_detection_confidence=0.5) as pose:
for idx, file in enumerate(file_list):
image = cv2.imread(file)
image_height, image_width, _ = image.shape
# 処理する前にBGR画像をRGBに変換
results = pose.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].y * image_height})'
)
# 画像にポーズのランドマークを描画
annotated_image = image.copy()
# upper_body_onlyがTrueの時
# 以下の描画にはmp_pose.UPPER_BODY_POSE_CONNECTIONSを使用
mp_drawing.draw_landmarks(
annotated_image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
# Webカメラ入力の場合:
cap = cv2.VideoCapture(0)
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as pose:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# ビデオをロードする場合は、「continue」ではなく「break」を使用してください
continue
# 後で自分撮りビューを表示するために画像を水平方向に反転し、BGR画像をRGBに変換
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
# パフォーマンスを向上させるには、オプションで、参照渡しのためにイメージを書き込み不可としてマーク
image.flags.writeable = False
results = pose.process(image)
# 画像にポーズアノテーションを描画
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
cv2.imshow('MediaPipe Pose', image)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()5. JavaScript Solution API
◎ サポートオプション
・upperBodyOnly
・smoothLandmarks
・minDetectionConfidence
・minTrackingConfidence
◎ コード
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/camera_utils/camera_utils.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/control_utils/control_utils.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/drawing_utils/drawing_utils.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/pose/pose.js" crossorigin="anonymous"></script>
</head>
<body>
<div class="container">
<video class="input_video"></video>
<canvas class="output_canvas" width="1280px" height="720px"></canvas>
</div>
</body>
</html><script type="module">
const videoElement = document.getElementsByClassName('input_video')[0];
const canvasElement = document.getElementsByClassName('output_canvas')[0];
const canvasCtx = canvasElement.getContext('2d');
function onResults(results) {
canvasCtx.save();
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
canvasCtx.drawImage(
results.image, 0, 0, canvasElement.width, canvasElement.height);
drawConnectors(canvasCtx, results.poseLandmarks, POSE_CONNECTIONS,
{color: '#00FF00', lineWidth: 4});
drawLandmarks(canvasCtx, results.poseLandmarks,
{color: '#FF0000', lineWidth: 2});
canvasCtx.restore();
}
const pose = new Pose({locateFile: (file) => {
return `https://cdn.jsdelivr.net/npm/@mediapipe/pose/${file}`;
}});
pose.setOptions({
upperBodyOnly: false,
smoothLandmarks: true,
minDetectionConfidence: 0.5,
minTrackingConfidence: 0.5
});
pose.onResults(onResults);
const camera = new Camera(videoElement, {
onFrame: async () => {
await pose.send({image: videoElement});
},
width: 1280,
height: 720
});
camera.start();
</script>【おまけ】 npmによる実行
◎ インストール
$ npm i -S @mediapipe/camera_utils
$ npm i -S @mediapipe/control_utils
$ npm i -S @mediapipe/drawing_utils
$ npm i -S @mediapipe/pose@0.2◎ コード
<!DOCTYPE html>
<html>
<body>
<div class="container">
<video class="input_video"></video>
<canvas class="output_canvas" width="1280px" height="720px"></canvas>
</div>
<script type="text/javascript" src="main.js"></script>
</body>
</html>import { drawConnectors, drawLandmarks } from '@mediapipe/drawing_utils/drawing_utils';
import { Camera } from '@mediapipe/camera_utils/camera_utils';
import { Pose, POSE_CONNECTIONS } from '@mediapipe/pose/pose';
// 参照
const videoElement = document.getElementsByClassName('input_video')[0];
const canvasElement = document.getElementsByClassName('output_canvas')[0];
const canvasCtx = canvasElement.getContext('2d');
// 結果取得時に呼ばれる
function onResults(results) {
canvasCtx.save();
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
canvasCtx.drawImage(results.image, 0, 0, canvasElement.width, canvasElement.height);
drawConnectors(canvasCtx, results.poseLandmarks, POSE_CONNECTIONS, {color: '#00FF00', lineWidth: 4});
drawLandmarks(canvasCtx, results.poseLandmarks, {color: '#FF0000', lineWidth: 2});
canvasCtx.restore();
}
// Poseの生成
const pose = new Pose({locateFile: (file) => {
return `https://cdn.jsdelivr.net/npm/@mediapipe/pose@0.2/${file}`;
}});
pose.setOptions({
upperBodyOnly: false,
smoothLandmarks: true,
minDetectionConfidence: 0.5,
minTrackingConfidence: 0.5
});
pose.onResults(onResults);
// カメラの生成
const camera = new Camera(videoElement, {
onFrame: async () => {
await pose.send({image: videoElement});
},
width: 1280,
height: 720
});
camera.start();次回
この記事が気に入ったらサポートをしてみませんか?