
頑張ってRを使えるようになるぞ!!|23冊目『RとPythonで学ぶ 実践的データサイエンス&機械学習』

野村総合研究所 有賀 友紀 大橋 俊介(2019 , 技術評論社)
総務省の「社会人のためのデータサイエンス演習」
gaccoで総務省統計局が「社会人のためのデータサイエンス演習」という講座を無料で開講していたので履修しました。
仕事ではそれほど頻繁にデータを分析する機会があるわけではないのですが、まったくないわけでもありません。
個人的な研究でもアンケート調査などをすることがあり、たいていはエクセルで分析を実施するのですが、先日はSPSSを使ったりもしました。
でも本当はRを使えるようになりたいなあ、と常々思っています。

総務省の講座以外にも、データサイエンスを取り扱った講座はたくさんあります
この社会人のためのデータサイエンス演習は演習なのでエクセルを使った分析の方法を動画で教えてくれます。
第5週まであって、動画の講義を受けて、動画をみながら、サンプルをダウンロードして演習で実際に分析を行い、確認テストがあります。
講座は第5週までなのですが、特別週として、RとR Studioの基本的な使い方講座がありました。
R、どうやって始めていいかわからなかったので、本当に役に立ちました。
講座では、基本統計量の計算をして、散布図を描いて、回帰直線を引いて、ヒストグラムを描いてという感じです。
これくらいならばエクセルの方が簡単だし、わざわざRでやらなくても、と思うくらいの理解度なのでまだまだだなあと自覚しています。
さらには、Rを使ったクラスター分析や決定木分析もありました。
自分はt検定や分散分析、多重比較とかをすることが多いのでそのやり方もあれば良いなと思いましたが今回はありませんでした。
おかげさまで基本な操作の仕方がわかったので、あとは本を読もう、関数やコードのガイドブック的なものがあると便利だな、と思ってWEBで購入する本を探してみたのですが、どれを選んだら良いかわからなくて、とりあえず、図書館にある本を借りてみることにしました。
この手の本はどうやって読もう?
そして、この本にたどり着きました。
データサイエンスの基本から書かれていて、そこはまあいいかな、と飛ばして、実際のRの使い方の部分を探して拾い読みをしました。
Excelによる統計入門(縄田 和満, 1996, 朝倉書店)とか、家にあったりしますが、この手の本は通勤時に電車の中で読んで理解できるような本ではないですね。
なんで理解できないかといえば、まずは用語がわからない。
わからない用語は抜き出して、調べて、簡単にまとめておく必要があるなと思いました。
「データフレーム」とか「ボックスプロット」とか「オーバーフィッティング」とかね。
横文字が多いですが、横文字は日本語にしないでそのまま覚えておいた方が、コードを書くときには良いと思います。
それから、どういうときにこの分析をする必要があるのか事例を読み、その事例にピンとくれば理解しやすいです。
さらに、その事例は自分のしている仕事だったらどういうことかと置き換えてみます。
そしてやっぱり最終的には、実際にR Studioを立ち上げて、本にある通りにコードをなぞってみないとダメだなと思いました。
データサイエンスのプロセスとタスク
データサイエンスのプロセスとタスクについては、いくつかのフレームワークが提唱されていて、その代表的なものはCRISP-DM(Cross-Industry Standard Process for Data Mining)というのだそうです。
CRISP-DMでは全体のプロセスを6つのフェーズに分けて、それぞれのフェーズで行う内容を定義しています。
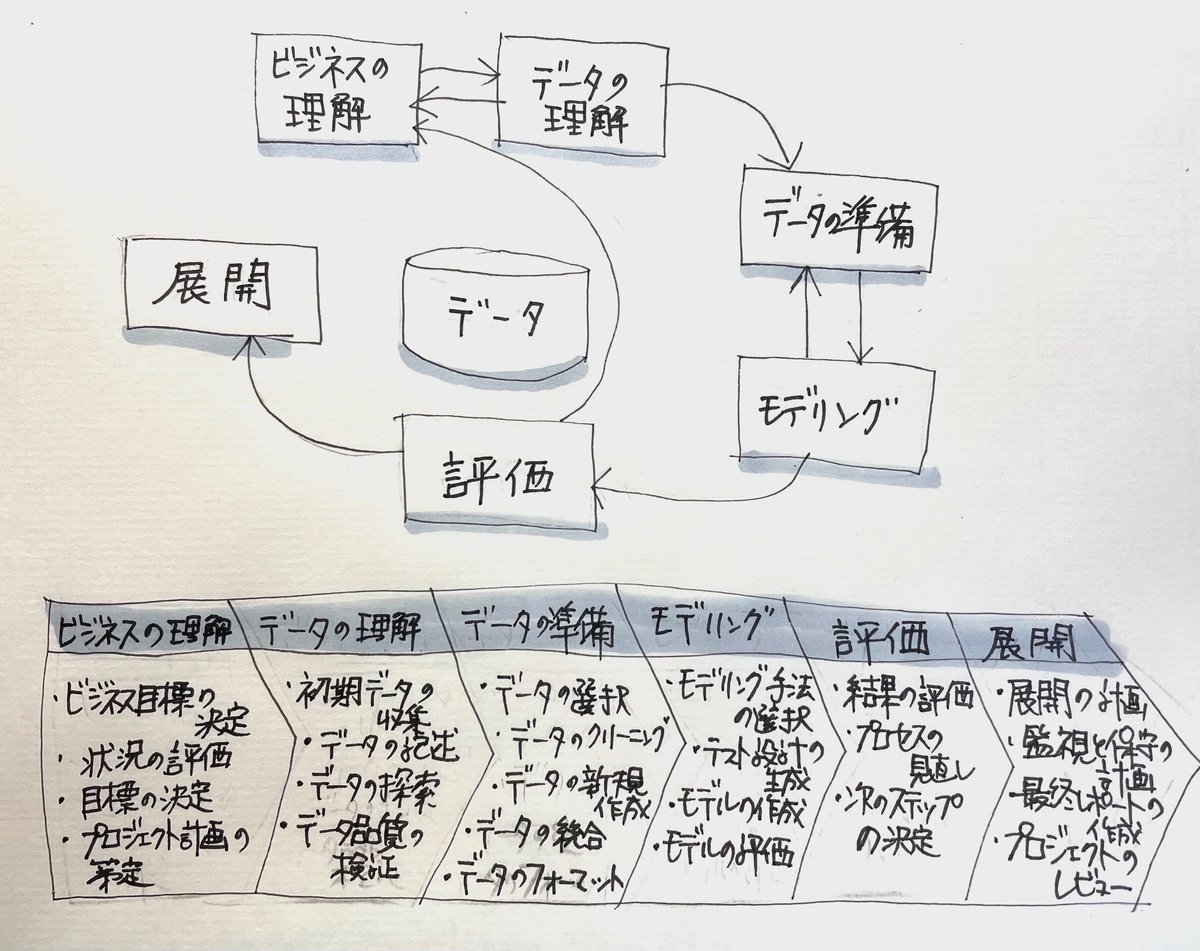
モデリング手法
モデリングの手法には、相関分析(関連性の分析)、クラスタリング(グループ化)、因子分析、主成分分析(次元の削減)、線形回帰、ロジスティック回帰、決定木(現象の説明、要因の分析、予測)などがあります。
予測、機械学習を目的としたものには、ベイズ統計モデリングとかベイジリアンネットワーク、ランダムフォレスト、ニューラルネットワークという分析手法があるらしいのですが、理解するのが難しいので今回はスルーしました。
分布の形を変える 対数変換、ロジット変換
先にも書きましたが、自分の研究では、属性などでグループ分けをしてグループの平均の差の検定とかをする機会が多いです。
今までに実施したアンケートでは、質問に対して5段階スケールで回答してもらっていますが、アンケート結果の分布を検証してみると、質問によって高い方や低い方に偏っていて、正規分布になっていないことが多かったです。
そのためノンパラメトリック検定という手法を取りました。
しかし、この本を読んで。分布の形を正規分布の形に近づけるには、対数変換やロジット変換という方法があることがわかりました。
どちらが良いんでしょうね。
何はともかく、Rの勉強はようやくはじめたばかりです。
いつかこのnoteを読み返して、「むかしの俺ってバカだったなあ」と笑う日がくることを夢に見ていたりします。
最後までおつきあいいただきありがとうございました。
スキ♡の応援よろしくお願いいたします。
この記事が気に入ったらサポートをしてみませんか?