
【ノーコード中級編】記憶を持ったChatGPT製のLINEボットを40分で作ってみよう!

※本記事は5/13に最新バージョンに更新されています。変更点はこちらの記事にまとめました
今回は過去のやり取りを考慮できるLINE上で動くチャットボットをmake上に構築していきたいと思います。
ちょっと宣伝させてください
本記事は下記のように過去記事からの続き作業となっており、ゼロから今回の作業までを行うと1時間20分程度の時間がかかることが予想されます。
そんなに時間を使いたくない、という方へ向けてショートカットできる手段を用意しました。
下記の記事を購入してもらうと完成版のmake設定ファイルをダウンロードでき、これをインポートすることで今回の作業を含めた全ての作業が完成した状態にワープできます。(LINEやChatGPTのアカウント発行作業は必要なので10分程度の作業は発生します)
なお、有料でも無料でも出来上がるチャットボットの性能に一切の差はありません。最終的には全く同じものができあがりますのでこれまで作業を進めてこられた方も安心して本記事で作業を継続していただければ幸いです。
※もし前回までの作業を完了している方がここから急に面倒になったので課金ルートに移動したい、という変わり者の方は前回までのmakeシナリオは使用せず、新しいシナリオを作成する形になりますのでご注意ください
はじめに
前回こちらの記事で似たようなLINEボットを作成しました。こちらのボットは1問1答の形式で対話ができるというものでした。例えば下記の画像のようなイメージです。

このときはボットに過去のやり取りを考慮する仕組みが組み込まれていなかったので、上記の質問の後に「他に解決方法はある?」と質問しても「こんにちは!何かお困りのことはありますか?」といったチグハグなやり取りになってしまうことが予想されます。
これを今回の作業でボットに過去数回のやり取りを記憶させていき、連続したコミュニケーションができるように調整していきます。
完成後は下記のようなやり取りが可能となります。
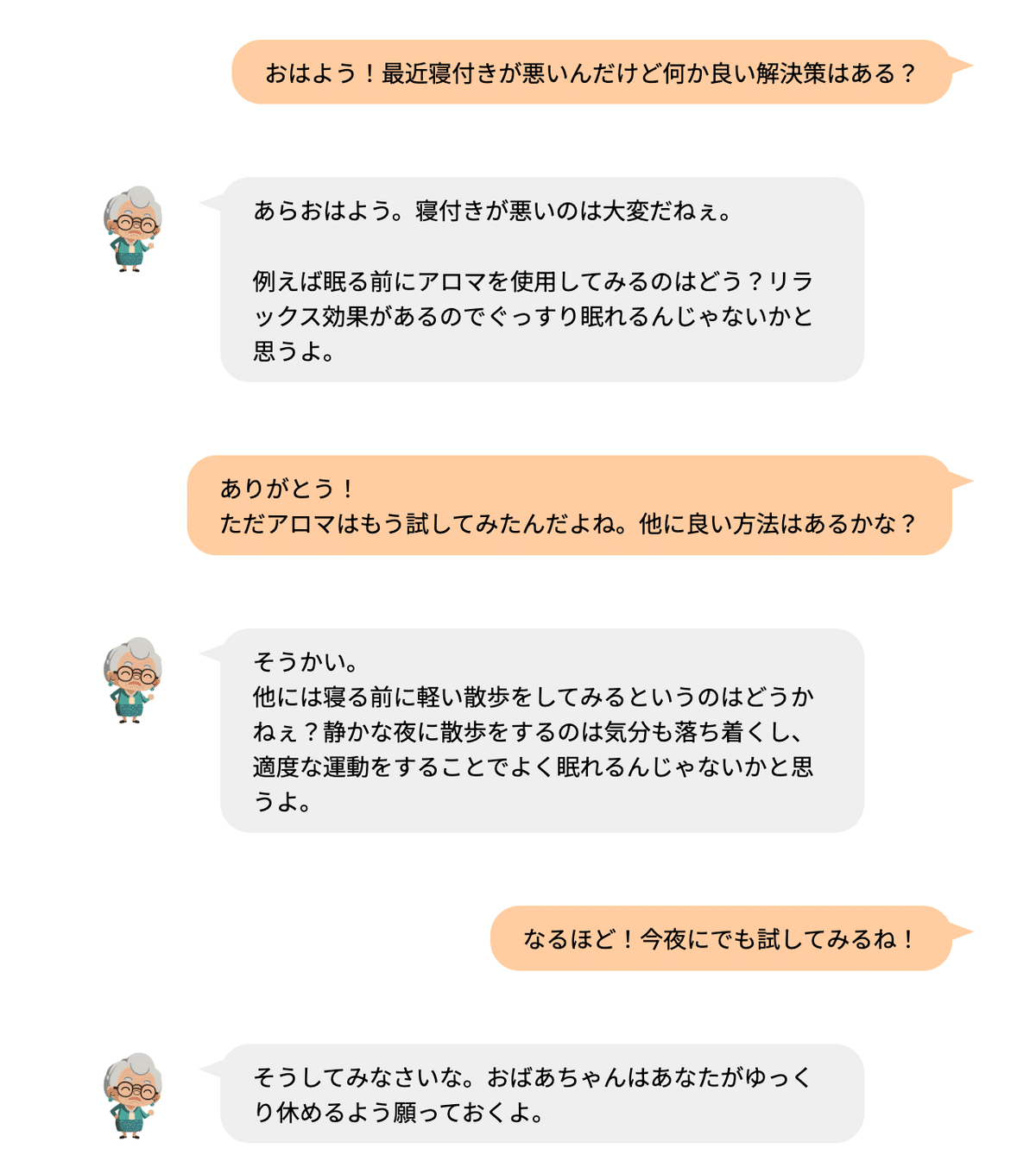
どうでしょうか?私はボットとのコミュニケーションとしてかなりうまくいっているように感じました。
ここで1点注意事項です。
ChatGPTを使って実装を行っている限り、現時点で過去すべてのやり取りを記憶させるのはかなり難しいです。これはChatGPTが一度に処理できる文字数が日本語ベースで最大約2,000文字程度に限られているという事情に関係しています。また、約2,000文字と記載しましたがかなりざっくりな数値のため参考程度にご理解ください。
今回の作業では過去3ターン(上記画像のようにユーザーのメッセージ3回+ボットの返信3回の合計6メッセージ)を記憶させる仕組みで実装を進めていきます。ご自身でボットを作成するときにこれを8メッセージや10メッセージに増やしたい、という場合は簡単に調整ができるように後ほど説明させてもらいます。
※ChatGPTでは処理する文字数が増えるほど金額が上がっていくのでご注意ください。現状、アカウント開設から3ヶ月以内であれば5ドル分までは無料で使えるようです。(18ドルと言っている人もいますが公式サイトには2023/4/27時点で5ドルと記載がありました)
相当な量を使わないとそこまでは達しないので最初は気にしなくて良さそうです。
気になる方はこちらの記事で費用のことを記載したのでご確認ください。
ちなみに私はChatGPTのコストを抑えるため&おばあちゃんの物忘れが激しい設定を活かすためにあえて3ターン(6メッセージ)に絞って実装しました。
実装前の準備
それでは作業を進めていきましょう。今回の全体像は下記のようになります。前回はアイコン3つだけでの実装でしたが、今回は21個まで増えてしまいました。
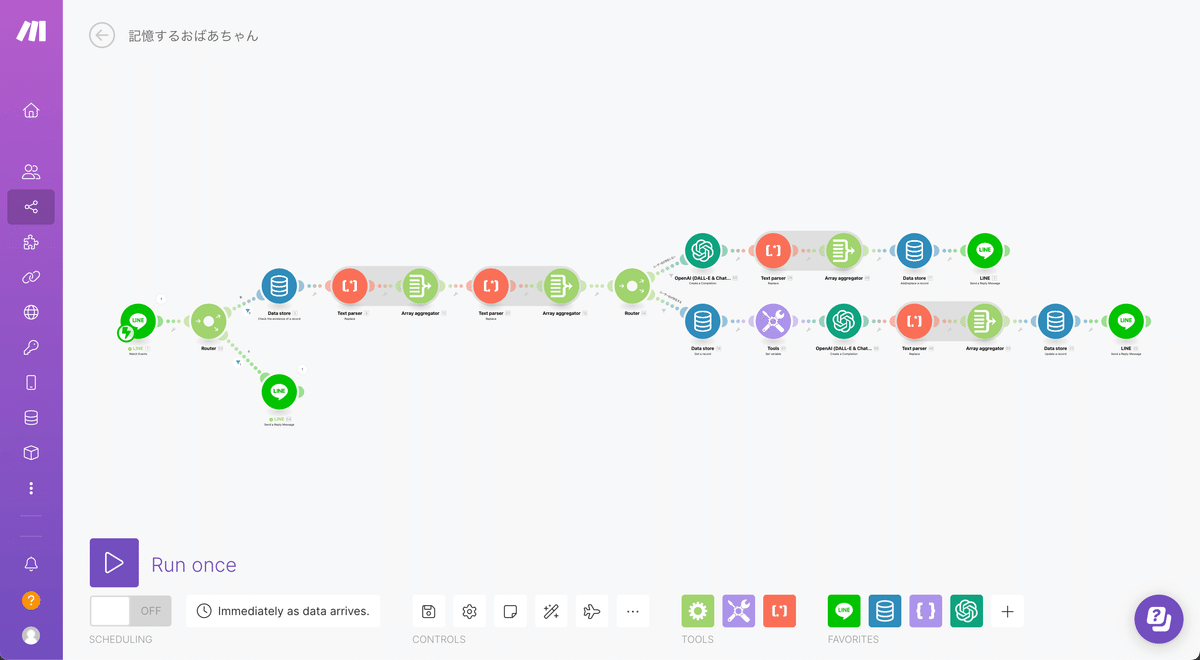
途中に条件分岐なども入ってきているのでプログラミングっぽい頭の使い方をしますが、できる限り分かりやすく説明していきます。
まずは前回の記事で作成したLINE→ChatGPT→LINEというシナリオを開いておきましょう。

LINEのエラー処理を行う
データベースを作る
次に左側のメニューからData storesというものを別タブで開きます。

このページでチャットボットとユーザーのやり取りを保存するデータベースを作成していきます。データベースなどと聞くと難しそうなイメージですが大丈夫です。コピペで終わります。
開いたら右上のボタンでAddしていきましょう。
下記のようなポップアップがでるのでまずはデータベースに名前をつけます。私はLINEチャットボットと名付けました。

次にどんなデータを保存するかを設定していきます。Addボタンを押して下記のようにポップアップを出してください。
データの構造に名前をつけられるので今回は「ChatGPT Messages」とつけておいてください。Messagesは最後にsがついていて複数形になっているのがポイントです。後から「ChatGPT Message」とう単数形のものも作成するので間違えないように注意してください。

次にGenerateボタンを押してさらにポップアップを表示し、Sample dataというテキストボックスに下記をコピペしてGenerateボタンを押してください。
{"message": [{"role": "", "content": ""}]}
これでデータ構造が自動で作成されました。次にポップアップ内にあるRequiredと書いてあるラジオボタンをすべてYesに変更しましょう全部で4つあります。
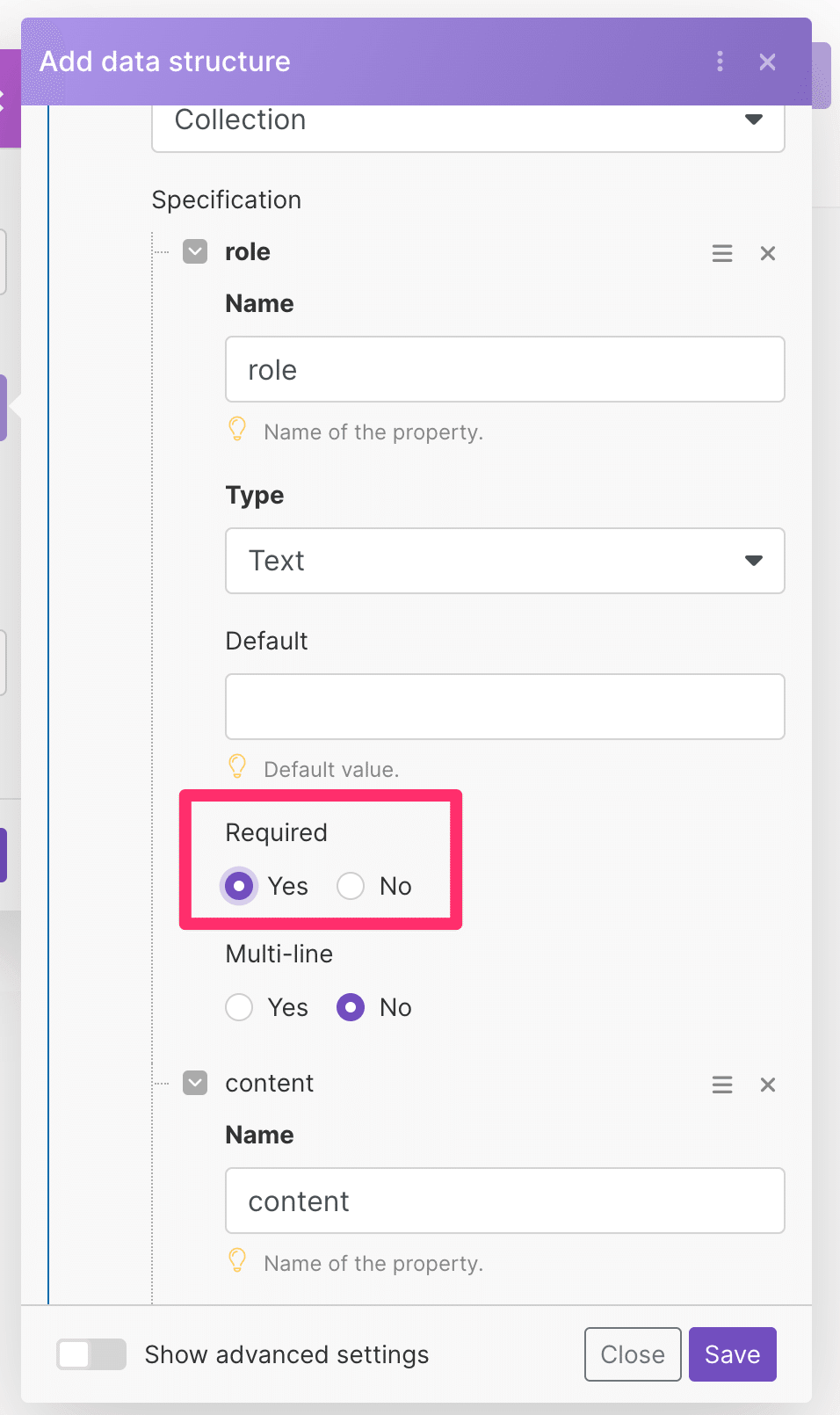
終わったらSaveボタン→Saveボタンと進んでデータベースを作成しましょう。下記の画面になったら成功です。

全体像把握と下準備
それではシナリオ画面に戻りましょう。まずは前半のこの↓部分を作っていきます。
※今回からは中級編ということで細かい部分の説明画像は省いていきますので不明点があればコメントやTwitterで質問をお願いします
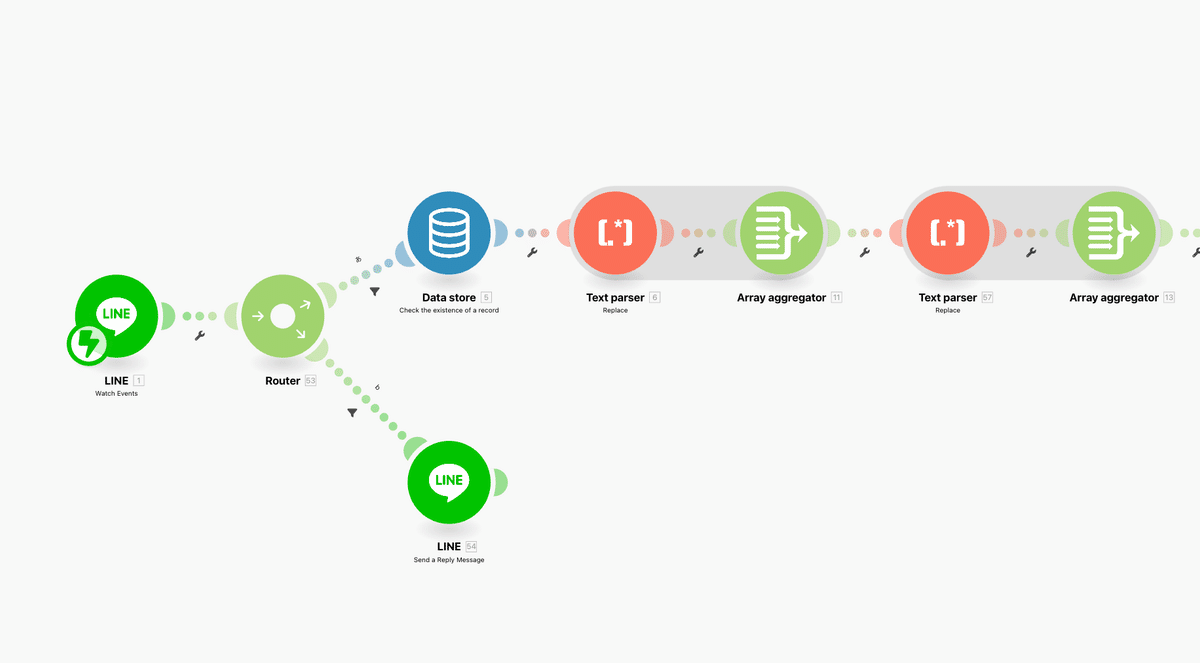
前回設定したChatGPTと右側のLINEのアイコンを削除しましょう。
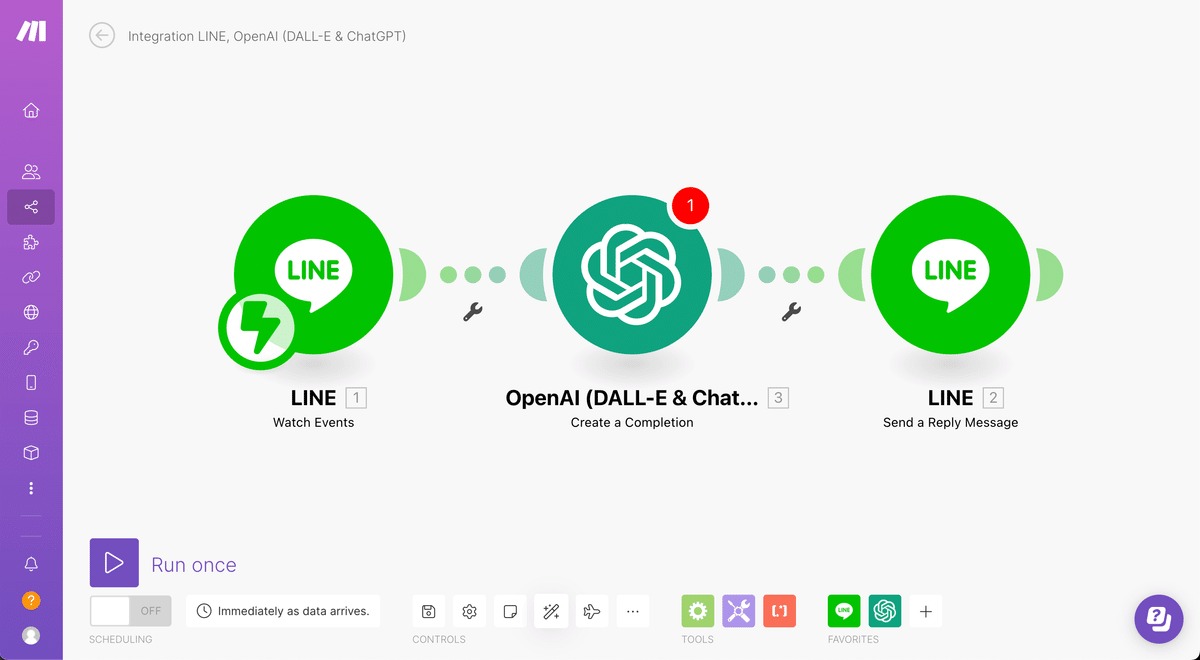
これで準備は完了です。
makeでの実装(前半)
それでは実装していきましょう。
受け取ったLINEメッセージに対するエラー処理を実装する
前回作成したボットには下記のような「LINEからスタンプや絵文字のみのメッセージ、画像などのファイル送信を行うとエラーになる」という問題がありました。エラーの原因はスタンプ・絵文字のみのメッセージ・ファイル送信などは「メッセージ(テキスト)が存在しない」と判定されるため、その後の処理に問題が出てくる、というものです。本工程ではまずメッセージが存在するかどうかを確認し、処理を分岐させることでこれに対処していきます。
まずは下部にあるTOOLSアイコンからRouterを選択してLINEの右側に接続します。次にRouterの中央をクリックして下記の状態にしましょう。

その後、表示された2つのうち下にある方のプラスアイコンをクリックしてLINEの「Send a Reply Message」を選択します。設定を開いて下記のようにReply Tokenのタグを挿入しましょう。
次にMessagesのAdd itemをクリックし、出てきた「Text」にエラーが発生した際にユーザーへ自動返信するためのメッセージを入力していきます。
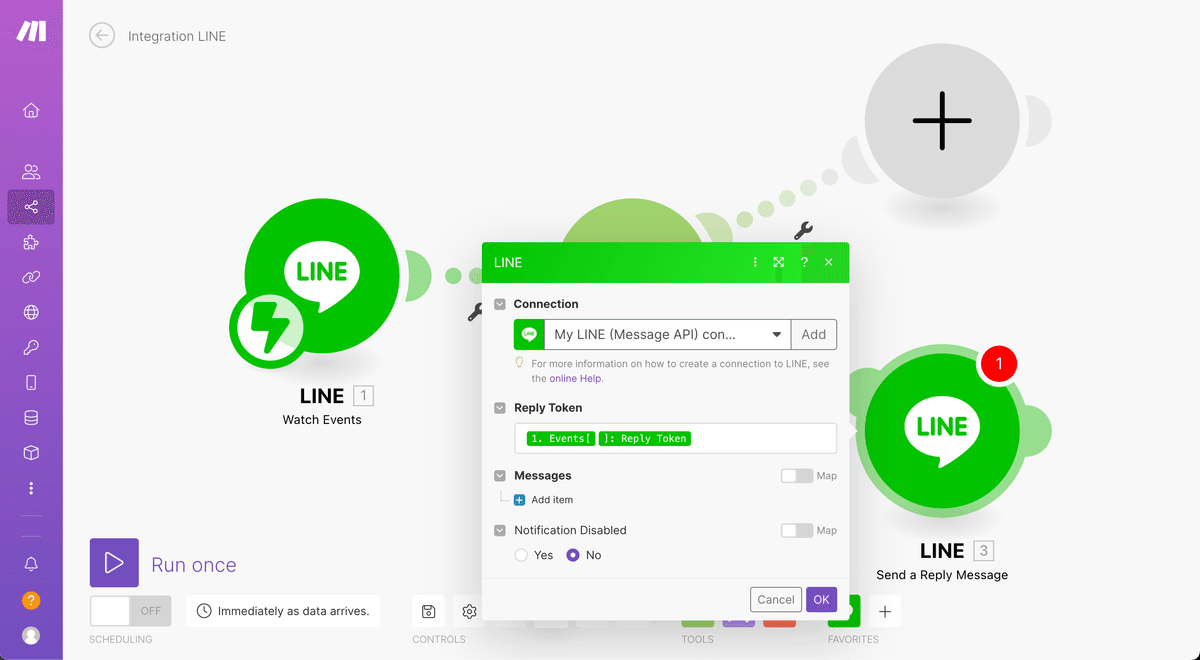
私はおばあちゃんのキャラクターを活かして下記のようなメッセージを置く設定にしました。「スタンプや絵文字のみのメッセージ、画像などのファイル送信は受け付けてないよ」ということが分かれば何でもOKなので自由に設定しましょう。

次に下記を参考にLINEの左にある半円をクリックしてポップアップを出しましょう。

その後、下記画像のように設定していきます。ConditionにEvents[]→Message→Textを挿入し、ひとつ下の選択肢を「Does not exist」にすることで「テキストメッセージが存在しない」場合にのみこちらのルートに処理が分岐するよう設定することができます。
完了したらOKを押して閉じることを忘れずに。

次にLINEと同様、上に残っている大きなプラスアイコンの左にある半円をクリックしてテキストメッセージが存在するパターンの分岐を作成していきます。下記のように設定しましょう。今回は「Exists」を選択します。

これでLINEから受け取ったメッセージに対するエラー処理は完了です。
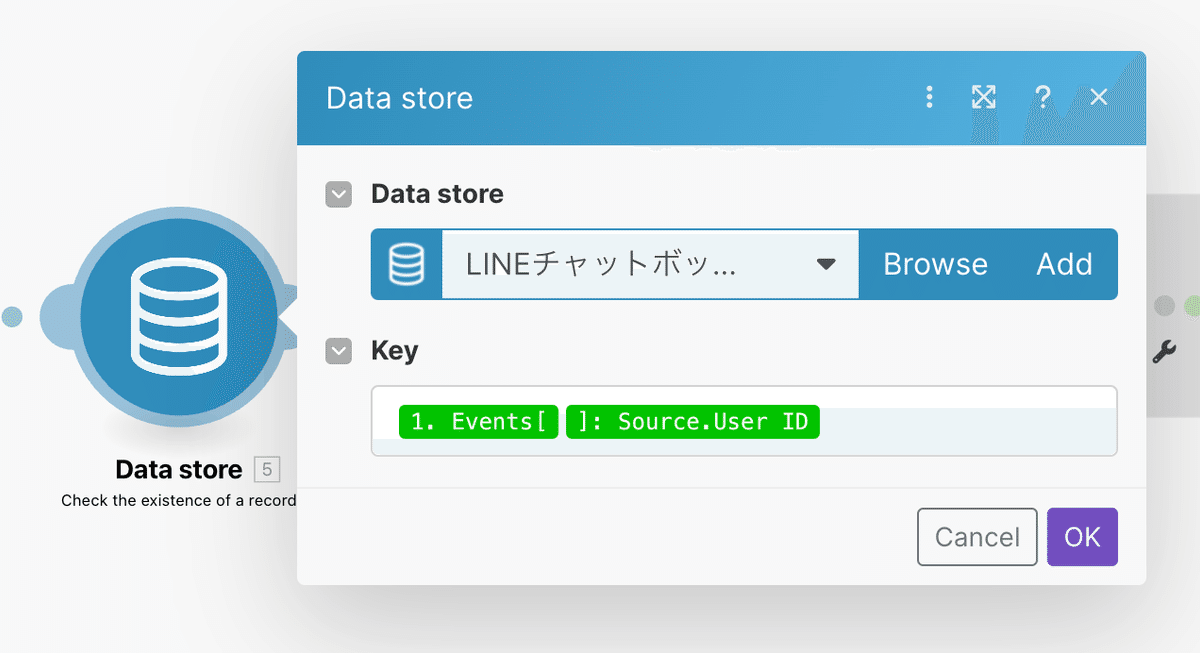
ユーザーデータの重複確認用にData storeを設置する
次にテキストメッセージが存在するルートに残っている大きなプラスアイコンを押して「Data Store」と検索し、Check the existence of a recordを選択しましょう。

小見出しの通り今回はユーザーの重複確認用の設定になるのですが、一旦今は設定だけを行い、これをどう使うのかは後ほど必要になったタイミングで解説します。
それではData storeアイコンの設定を行います。下記が完成図です。
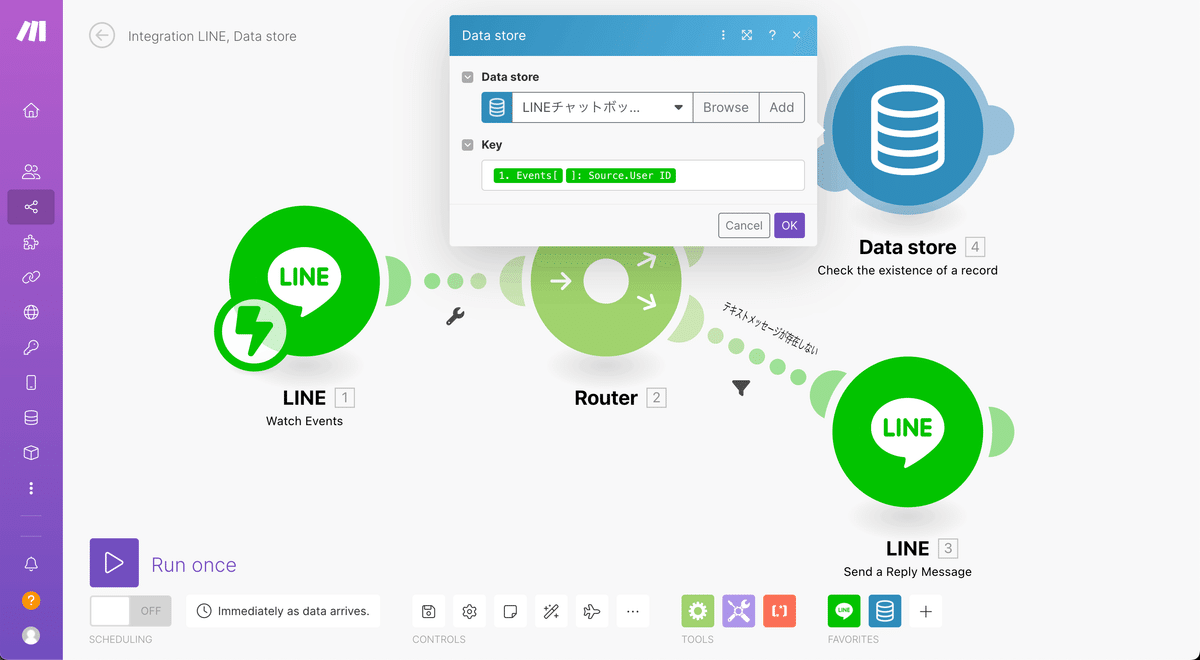
Data storeの選択は先程作成したデータベースを選択します。今後もData storeのアイコンを複数配置しますがすべて同様に先程作成したデータベースを選択しましょう。
次にKeyのところにはLINEから受け取る項目の中にある黄緑色のUser IDタグを選択していきましょう。開いていく順番はEvents→Source→User IDです。
Text parserでLINEメッセージの改行を削除する
先ほどLINEメッセージのエラー処理を実装しましたが、もう一点現状のボットには問題が残っていました。それはLINEから複数行のメッセージを送信するとエラーになる、というのものです。本工程ではこれに対処していきます。
それでは画面下の+ボタンの左にあるオレンジ色のアイコンをクリックしましょう。選択肢はReplaceを選び、Data storeの右に接続します。
このオレンジはText parserという仕組みで、受け取ったテキストを編集して次に渡すことが可能です。例えば「東京都XXX区XXX1-2-3」という住所の内、半角の数字とハイフンを「東京都XXX区XXX1−2−3」と全角に変更する、みたいなことができたりします。
今回の場合はLINE上で入力された文章の改行がChatGPT上で悪さをするので改行を削除する処理を入れていきます。(厳密には改行を空白の文字列に置換する、という作業を行います)
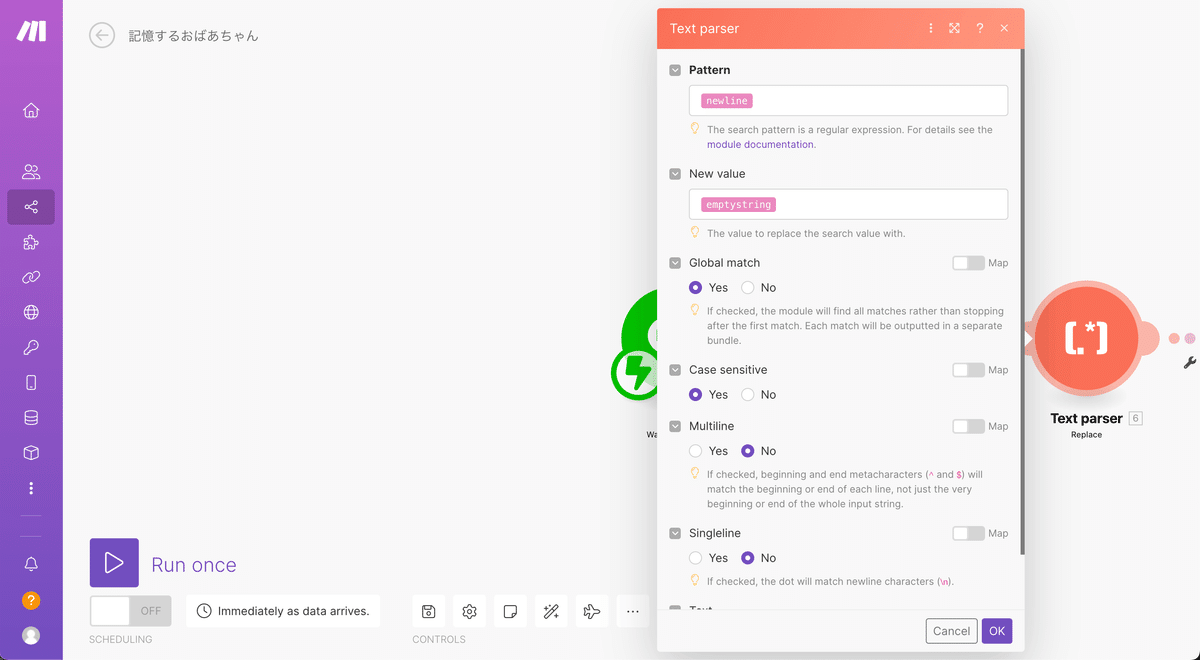
次の画像のようにPatternにフォーカスするといつものようにポップアップが出てきますが、ポップアップ上の「A」と書かれたタブをクリックして切り替えを行ってください。

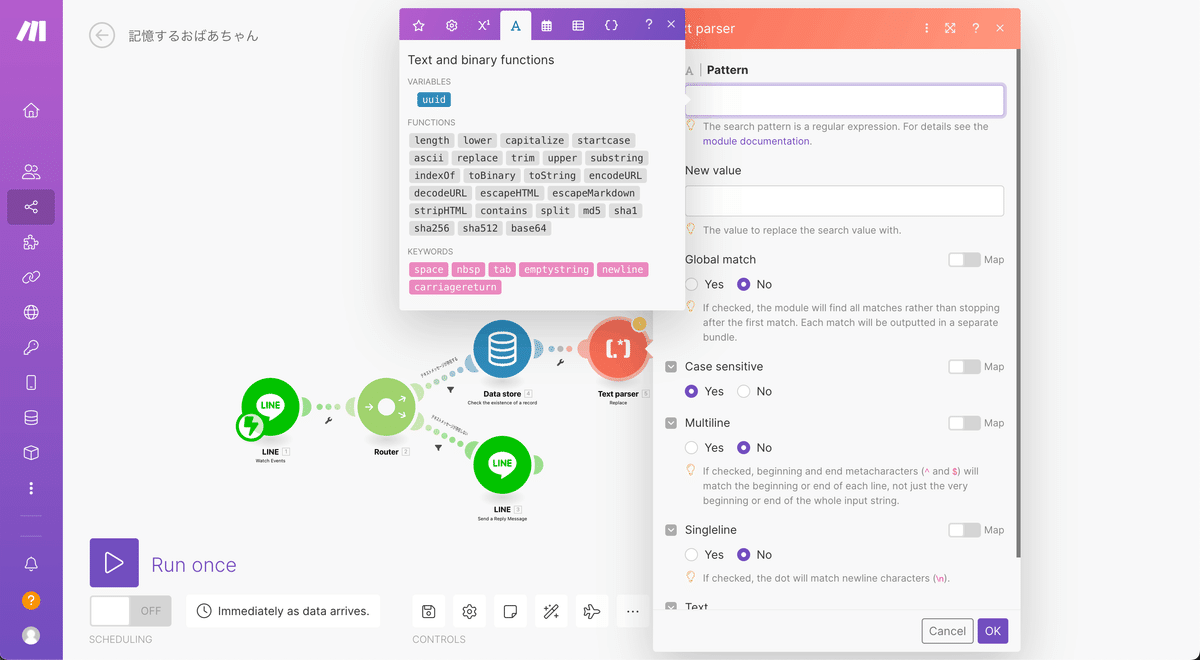
次に下記の作業をします。
ポップアップ上にある「newline」というピンクのタグを選択
New valueには「emptystring」というピンクのタグを選択
Global matchを「Yes」にする
下記のようになっていればOKです。
Global matchをYesにしないとメッセージ内で複数回の改行が行われていた場合、1つ目の改行だけが置換され他はスルーされてしまうのエラーが発生してしまいます。この後にも同様のText parser処理が発生するので忘れないようにしましょう。
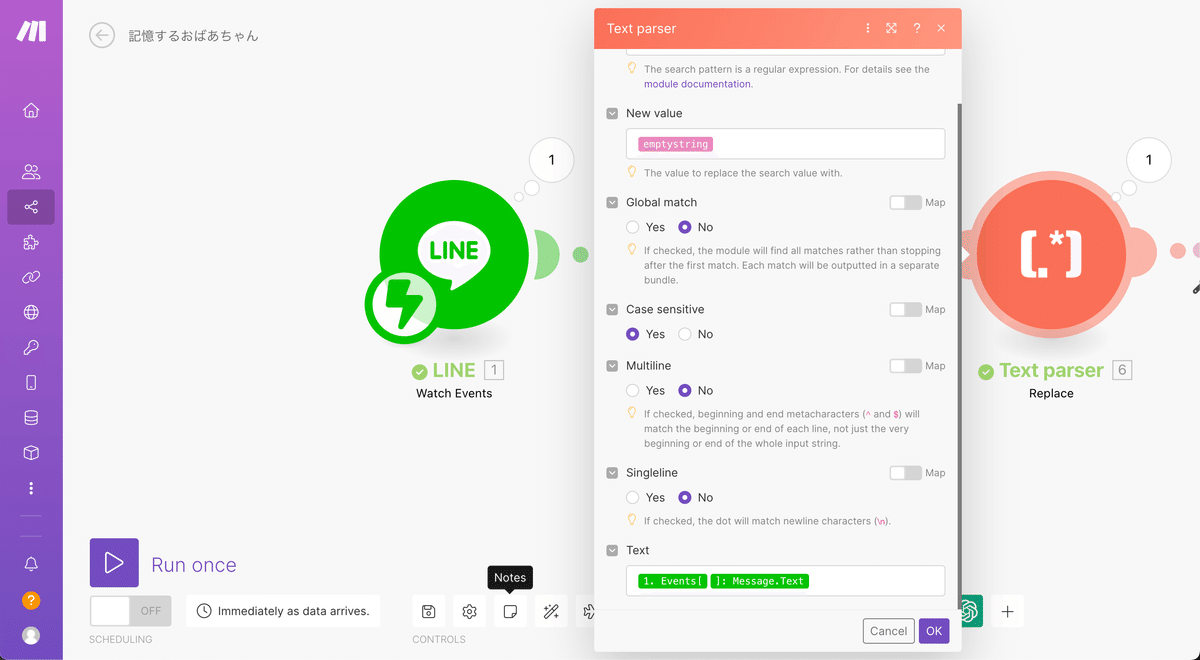
次にText parserのポップアップを一番下までスクロールするとTextというエリアが出てくるのでここにLINEから受け取ったメッセージを挿入しましょう。Events[]→Message→Text
これでText parserは完成です。OKで保存するのを忘れないようにしましょう。
ChatGPTや保存用にメッセージを成形する
まずは右下のプラスボタンからData storeの「Add/replace a record」を選択してText parserの右に接続します。
※これは本来後半に使うものですがメッセージ成形のために仮で設置しています

次にData storeの設定を下記のようにしましょう。Keyには先程と同じUserIDタグを挿入します。完了したOKを押して閉じましょう。

次に下部のTOOLSアイコンからArray aggregatorを選択して下記の位置に設置してください。

次にArray aggregatorの設定を下記のように行います。
Source Moduleは左隣のText parserを選択し、Target structure typeにはData storeのRecord: Messageを選択します。roleはuserとし、contentにはText parserのタグを設定しましょう。

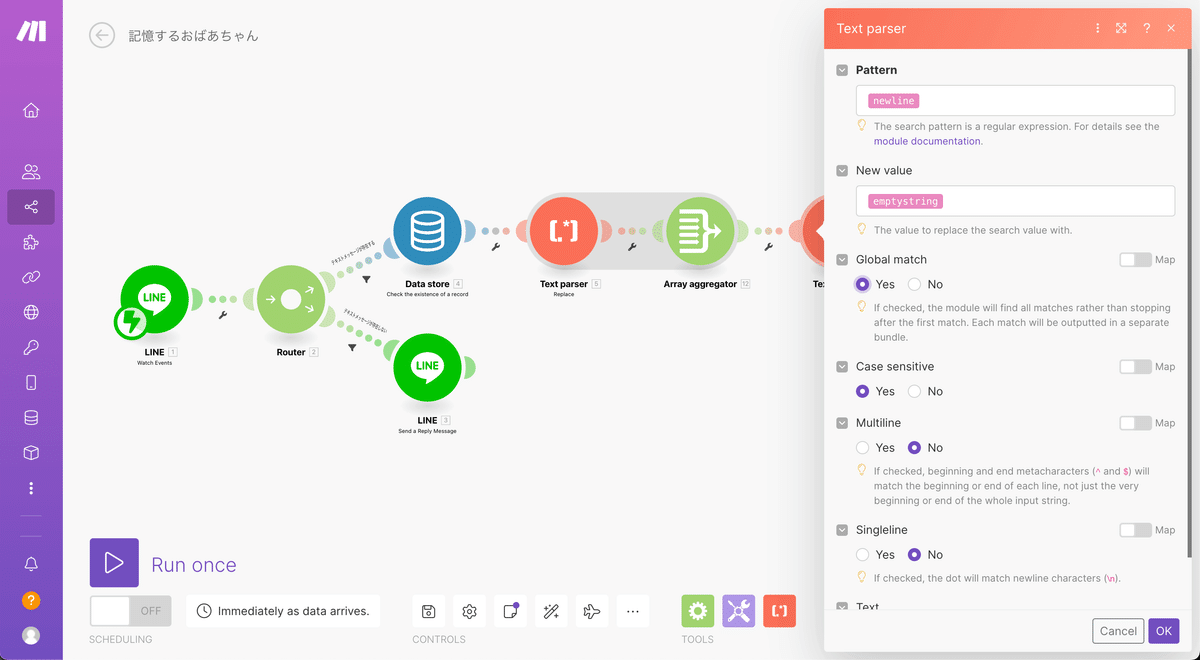
次にもう一度Text parserのReplaceとArray aggregatorを下記のように設置します。

まずはText parserの設定を行いましょう。先程と同様に下記のように進めていきます。Global matchをYesにすることをお忘れなく。
次に一番下のText部分にChatGPTへの指示を記載していきます。
※前回記事でChatGPTの設定内で簡単なキャラクター設定を行いましたがそれと同じ工程を切り出したものとなります

この指示の内容ですが、例えば私が作成したAIおばあちゃんのように特定の人格としてロールプレイをしてもらったり、「動画業界の専門化として回答をしてほしい」「会話の相手は12歳の前後の子どもを想定しているので年齢に配慮したアウトプットをしてほしい」といった回答時に考慮してほしい条件をつけたりなど、色々な使い道があります。
指示の内容はChatGPT側がいい感じに汲み取ってくれるのでとりあえず希望する内容を日本語で記載してみましょう。意図した振る舞いをしてくれないときはもっと細かく伝えてみたり、別の表現で伝えたりと工夫することが必要です。ここは専門の記事を書いている方がいる分野でもあるので別途調べてみても良さそうです。
作業に戻ります。
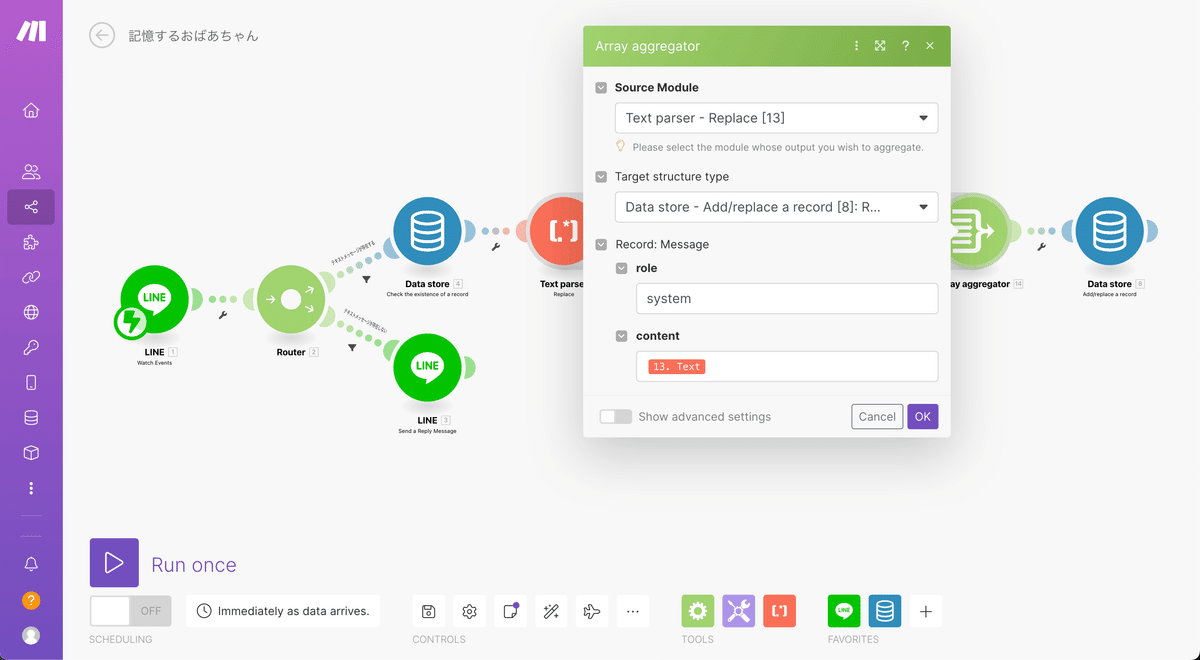
次にArray aggregatorの設定を先程のものを参考にして進めていきましょう。下記が完成した状態です。今回はroleがsystemになっているので注意が必要です。
これで前半の実装は終わりです。
makeでの実装(後半:条件分岐作成)
それではここから後半戦です。下記の部分を作成していきます。
結構ボリュームが多いですが、被っている部分を複製したりと見た目ほど大変ではないのでがんばりましょう!
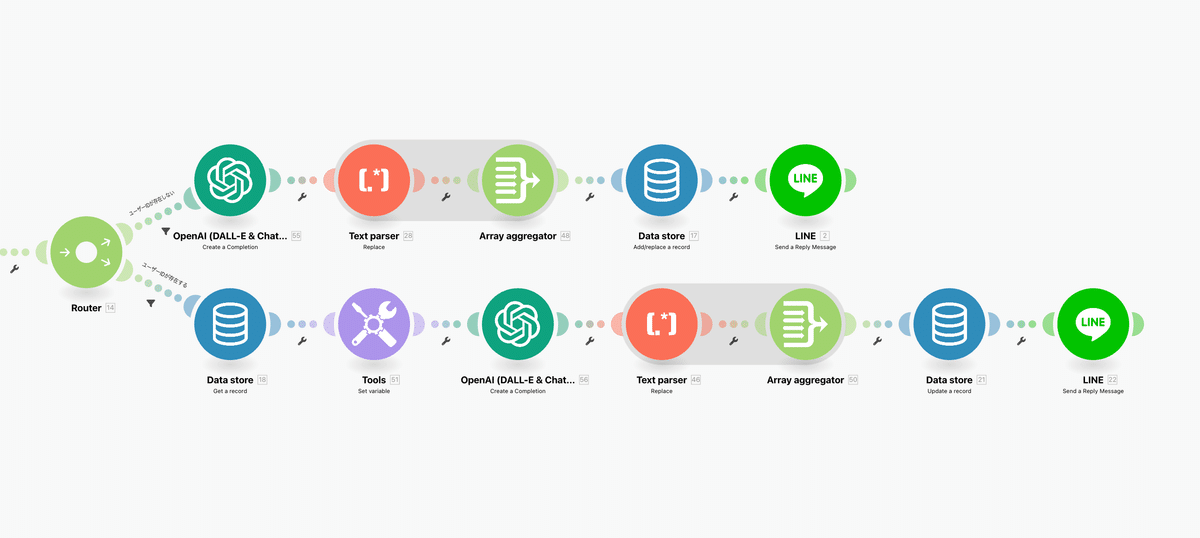
Routerで条件分岐を作る
まずは先程仮で設置していたData storeを切り離しておきましょう。点線上で右クリックをし、Unlinkを選択すると切り離すことができます。
次にLINEエラー処理のときと同様に画面下部の黄緑色のアイコン、TOOLS内にあるRouterを選択して最後に作成したArray aggregatorの右に接続しましょう。下記のようになっていればOKです。

次に上にあるプラスアイコンの左にある半円をクリックして分岐の条件を設定していきます。ポップアップが出たら下記のように入力しましょう。
ここでついに最初に設置したData storeのタグを使っていきます。青いExistsというタグを選択しましょう。

入力が終わったら忘れずにOKボタンを押して閉じてください。
次にRouterから出ているもう一方のルートの左にある半円をクリックして下記のように設定していきます。falseとtrueで先程の設定と対になる形です。こちらも終わったら忘れずにOKを押しましょう。

今回の2ルートに分かれる処理が何なのかというと、メッセージを送ってきたユーザーのIDが既にデータベースに登録されているのかいないのかを調べています。
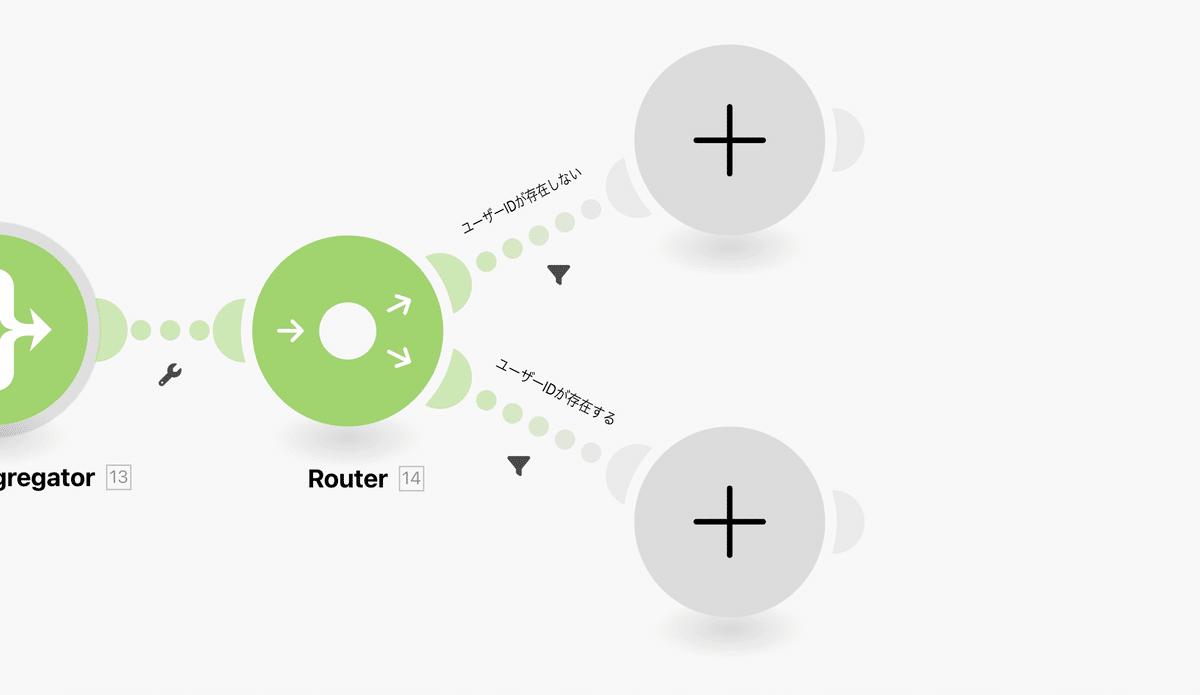
データ保存について解説
ここで理解を進めるために少し先の話をします。
今後の処理でユーザーからのメッセージとChatGPTからの返信をData storeに保存していき、直近のやり取りを管理できるように作業をしていくのですが、保存されるデータの形式としては下記のようになります。

このKeyの部分がLINEのUserIDになります。UserIDは他の人とかぶらないユニーク(一つしか存在しない)な文字がLINE側で割り当てられているのでこれを使って会話の履歴データを検索していこうというわけです。
その検索時に使用できるData storeの設定が最初に配置した下記の「Check the existence of a record」という項目です。これにKeyとしてUserIDを渡すことで今回LINEからメッセージを送ってきたユーザーの情報がすでに保存されているのかいないのかを調べることができます。
調べた結果、UserIDが存在するかしないかによって
UserIDがすでに存在するのであれば過去の会話を取得してChatGPTに渡し、最後には今回の会話を追加してデータを上書き保存する処理を行う
存在しない場合は新しくUserIDをKeyに設定した今回の会話データを新規作成する処理を行う
というようにその後の工程で別々の処理が必要になってくるので先程のRouterを配置して処理を分岐させたということになります。
makeでの実装(後半:IDなしルート)
それでは先に上のユーザーIDが存在しないルートの実装を進めていきましょう。
ChatGPTを設定する
次にユーザーIDが存在しないルートの大きなプラスアイコンをクリックしてChatGPT→Create a Completionを選択しましょう。
次に下記のように設定をしていきます。
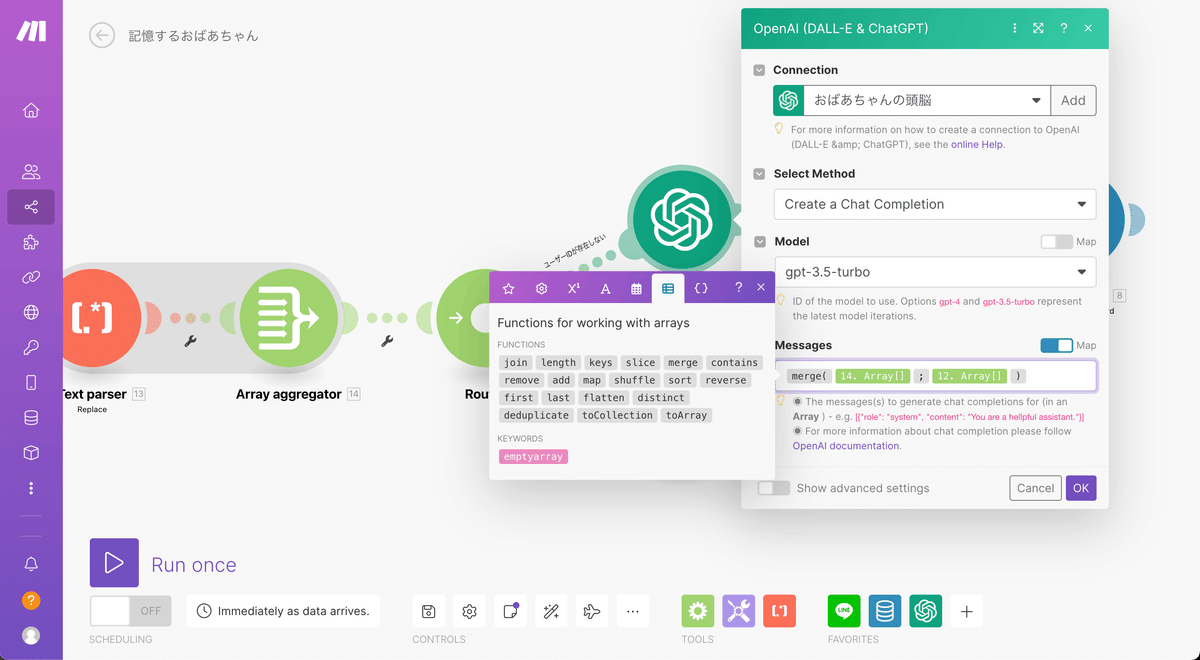
Messagesの部分は下記のように進めていきます。
MapのスイッチをONにする
テキストボックスにフォーカスする
表示されたポップアップの右から2番目のタブを選択する
mergeを選択する
セミコロン(;)を挟んで左側に前半で作成したChatGPTへの指示のArray aggregatorを挿入する
セミコロン(;)を挟んで右側に前半で作成したLINEからのメッセージのArray aggregatorを挿入する
以上です。
Array aggregatorが複数ありますが、タグ選択の際にタグにカーソルを乗せると対象の大きなアイコンが収縮するアニメーションが発生するため参考にしてみてください。
もしくは大きなアイコンの下に名称が書いてあり、その中に数値が書いているのでここを照合してもOKです。

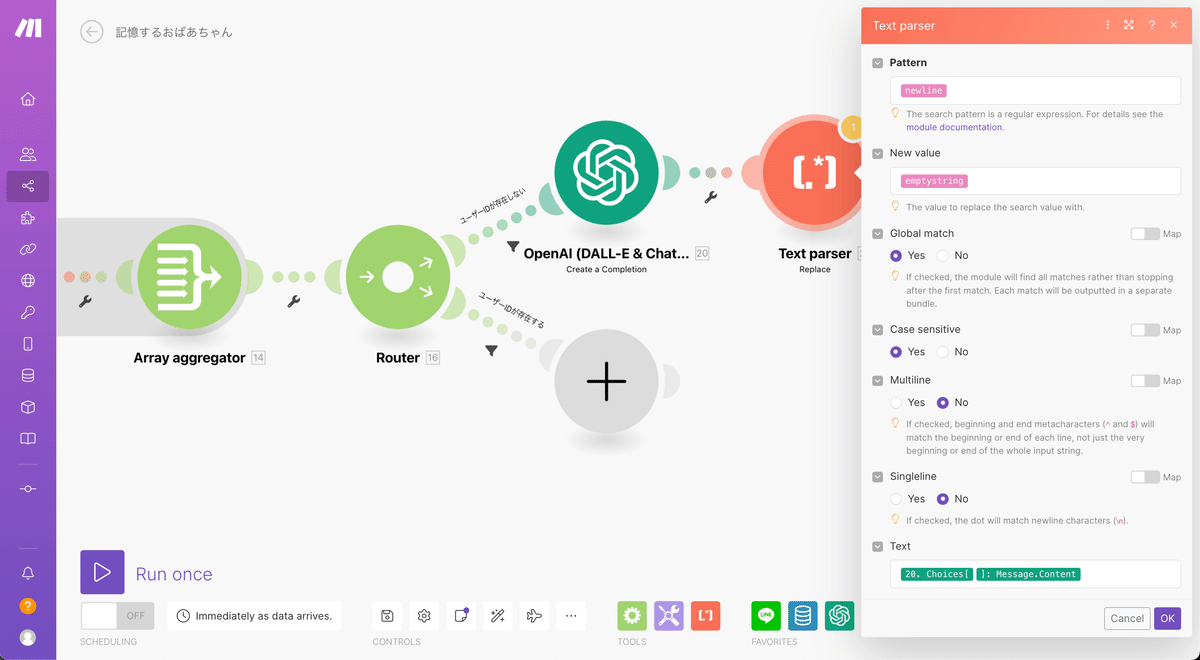
ChatGPTからの返事に含まれる改行を削除する
次にChatGPTからの返事にも改行が含まれることがあるのでText parserで処理を行いましょう。前半と同じ流れなので完成図を参考に作業をお願いします。
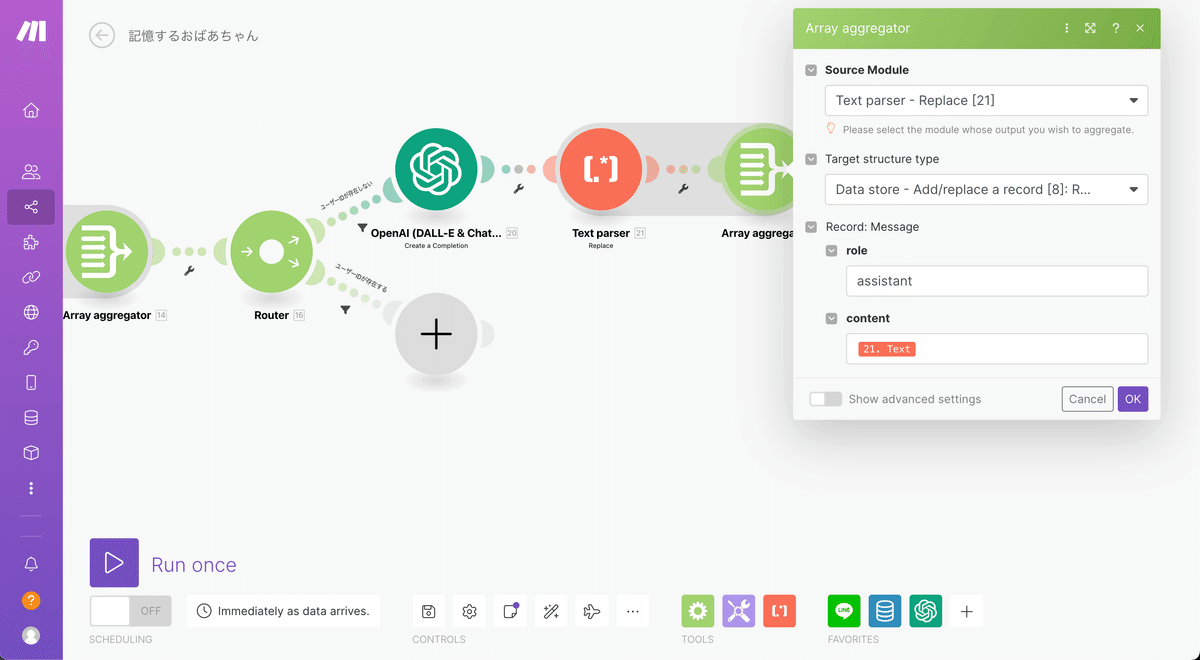
その後、Array aggregatorと切り離してあったData storeを接続します。

Array aggregatorの設定は下記の通りです。今回はroleがassistantになっているので注意しましょう。
会話データをData storeに保存する
いよいよ今回の作業の肝であるデータ保存部分に入ります。と、言っても作業は簡単なのでご安心ください。
下記のように作業をしていきます。先ほどと同じ用にまずはmergeを挿入し、左側にはLINEから受け取ったメッセージのArray aggregatorを右側には一つ前で作成したChatGPTからの返信のArray aggregatorを挿入しましょう。

これでデータ保存処理は完成です。
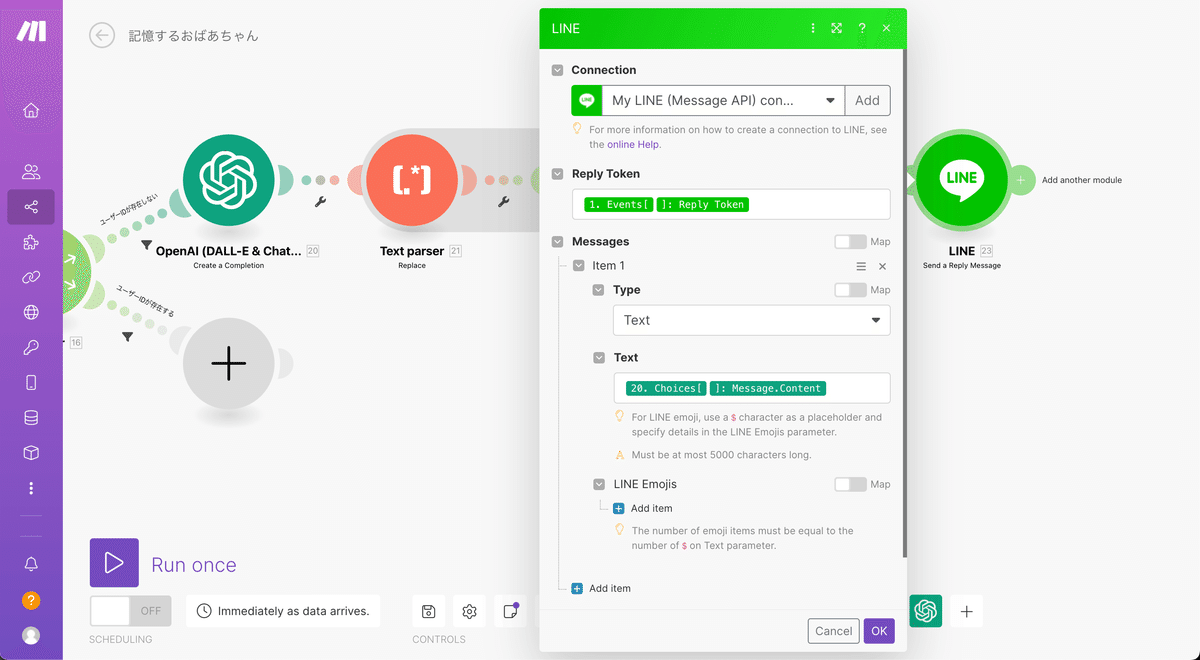
LINEを接続してテストを行う
最後にLINEのSend a Reply Messageを追加してData storeの右に接続します。ReplyTokenのタグを選択肢、TextにはChatGPTからの返事を挿入してください。
ここにはArray aggregatorで改行を削除したものではなく、ChatGPTからの返事タグをそのまま挿入しましょう。これはLINE上では人が見やすいようにメッセージを改行させたい、というのが理由です。逆にArray aggregatorで改行を削除したのはデータを保存するときには改行を削除したかったのが理由です。改行が残っているとデータの処理方法次第ではエラーになってしまいますし、保存される文字数は少なければ少ないほうがよいというのが理由です。
これでユーザーIDが存在しないパターンの実装が完了したので動作確認をしましょう。
※シナリオを保存していない場合はここで一度フロッピーディスクマークを押して保存をしておきましょう
それではRun onceを押し、LINEからメッセージを送ってください。
今回作成したルートが正しく動作し、ChatGPTからのメッセージがLINEに返ってくることを確認しましょう。
もし返事が返ってこないなど何らかのエラーが発生している場合、アイコンの白い吹き出し部分が1とならずにエラーのようなマークになっていると思います。この場合は、何らかの設定ミスがあると思うので該当する目次に戻って確認してみましょう。どうしても解決できない場合はコメントやTwitterのDMでスクショなどを送ってください。
次に左側のメニューからData storesを別タブで開いてください。データが問題なく保存されているかを確認していきます。下記の形式で保存されていれば成功です。

最後にスタンプや絵文字のみのメッセージ、画像ファイルなどが送られたパターンが正しくエラーとして処理されるかも確認していきましょう。
再度Run onceを押してスタンプなどを送信してみてください。自分で設定したテキストが返ってくれば成功です。
makeでの実装(後半:IDありルート)
それでは最後の工程です。長くなってきていますがもう一息なのでがんばりましょう!
Data storeから過去の会話履歴を取得する
今回はユーザーが存在するルートということで、同時に過去の会話履歴も存在することとなります。まずはそれを取得していきましょう。
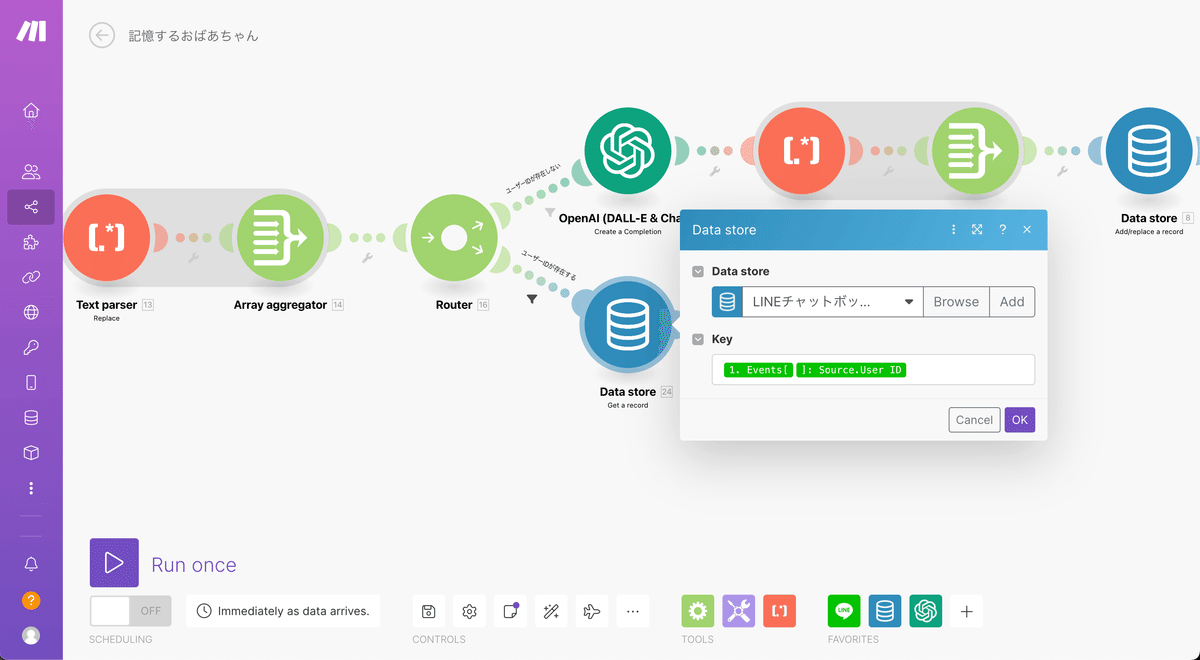
グレーの大きなプラスアイコンを押してData store→Get a recordを選択します。

入力内容は以下の通りUserIDタグを挿入します。
会話履歴として保存する件数を設定する
ここの実装は少しだけややこしくなります。
まずは新しいアイコンとして下部にある紫色のTools→Set variableを選択してData storeの右に接続します。
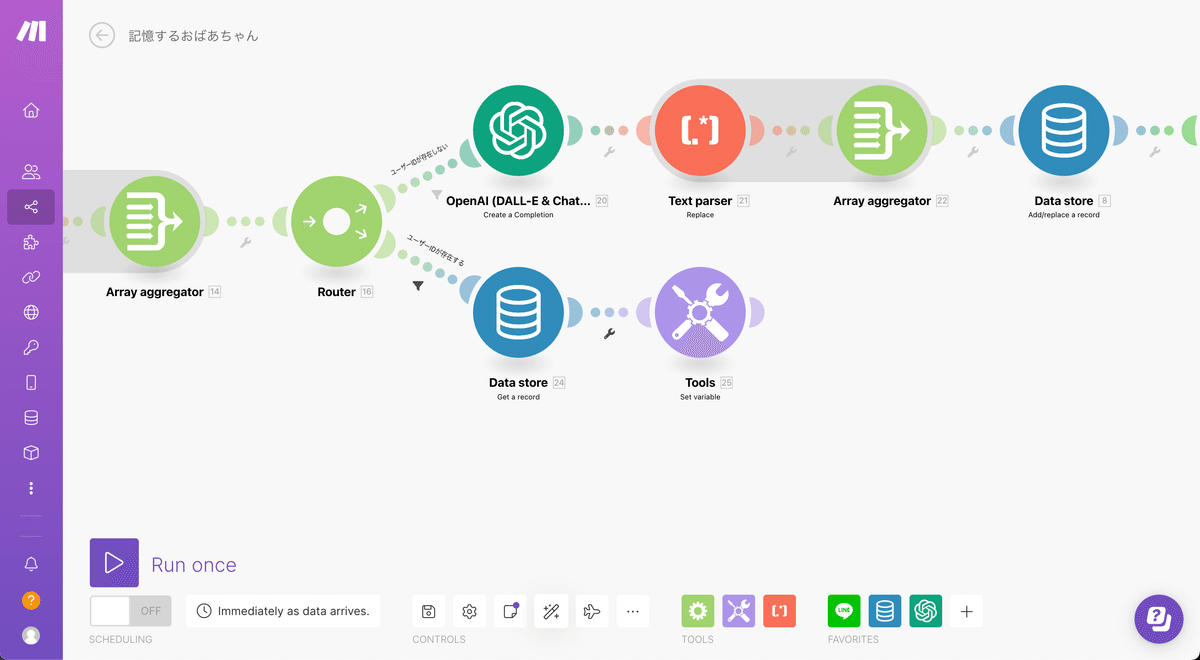
中の設定ですが、まず名前は分かりやすいように「messagesArray」とでもつけておきましょう。
次にVariable valueですがここが問題です。まずは完成図を見てください。とてもややこしそうですね。

今回、意味は理解しなくて大丈夫なので作業手順だけを説明します。
まずは一旦下記の内容をコピーし、Variable valueにペスーストしてください。
{{if(length(11.message) >= 6; merge(slice(11.message; length(11.message) - 5; length(11.message)); 35.array); merge(11.message; 35.array))}}すると下記のようになると思います。

最初にみた完成図とはタグの色が違っているかもしれませんがそれでOKです。先程コピペしたコードは私のmake画面の設定なのですが、今みなさんが実装しているシナリオ内の設定とはData store.24など大きなアイコンの数字がおそらく違っているので緑色のArrayタグが黒くなったりしています。
※偶然私の設定と数値が一致してタグの色が完成図と一致している方もいると思いますがその場合は本工程を適宜読み飛ばしてください
それでは色が変わってしまっているタグを完成図と同じ色になるように置き換えていきましょう。
まずは「11.messages」の置き換えを進めていきます。
はじめに「if(length(11.message)」内の黒い「11.messages」タグの右にカーソルを持ってきてdeleteキーによりタグを削除しましょう。下記の状態になります。
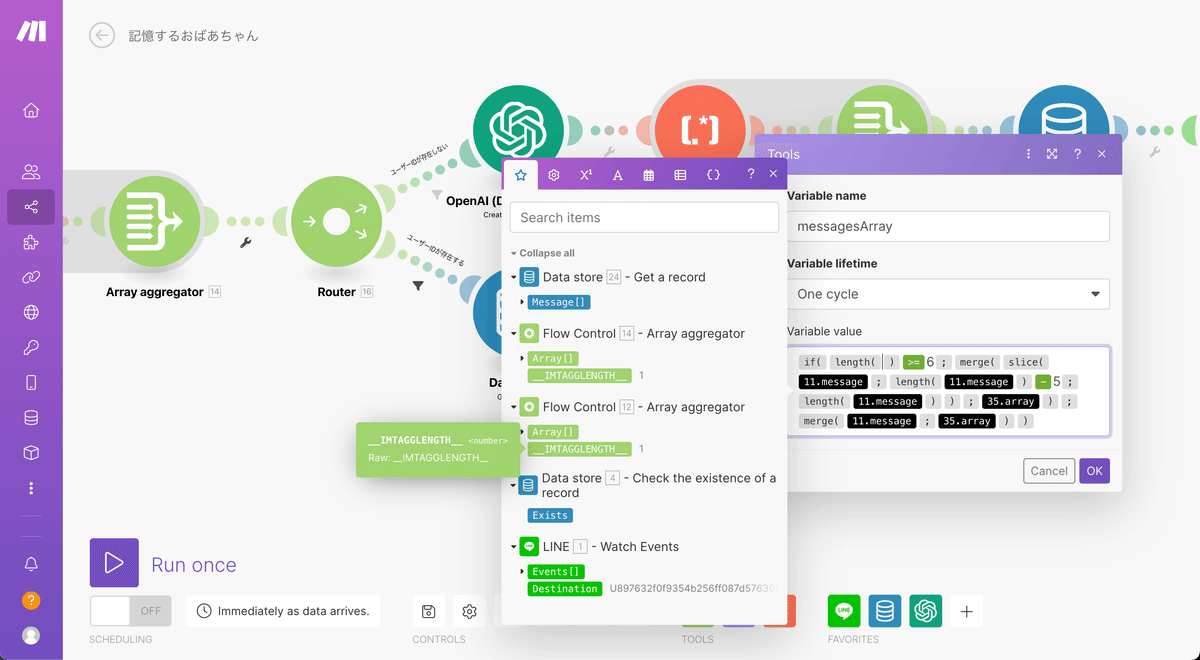
次に一つ前の工程で設置したData storeのタグである「Message[]」を選択して挿入しましょう。下記のタグです。
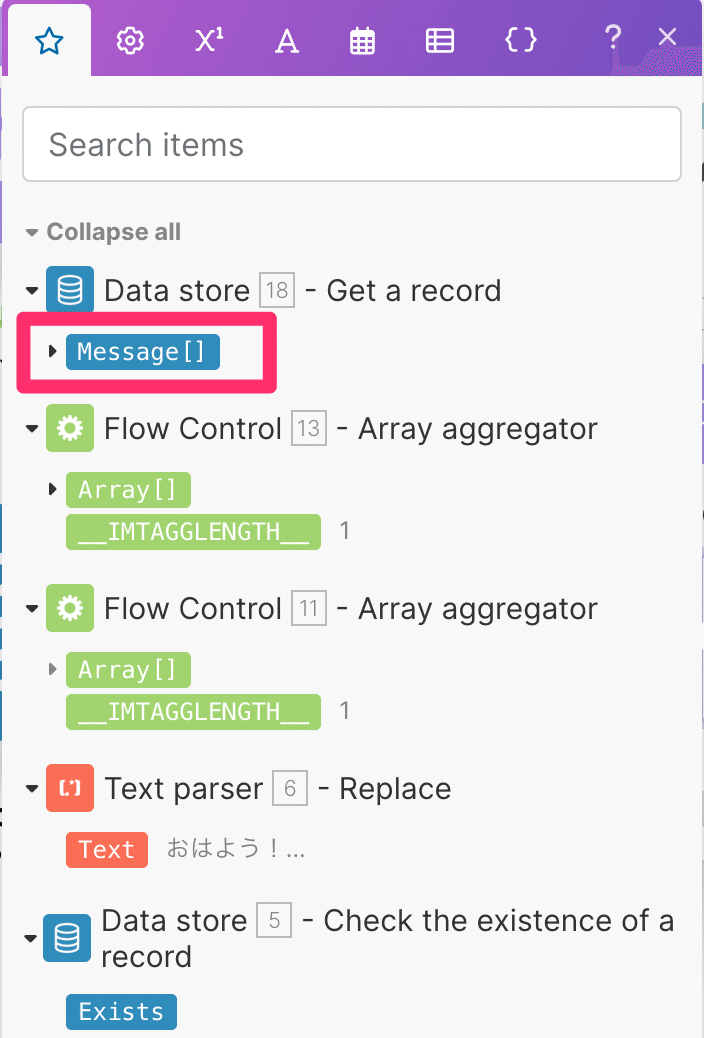
挿入されると下記のようになります。

これを他の「11.messagesタグ」にも同様に行います。合計で5個あります。
ちなみに先程挿入した青いmessageのタグはコピーすることができるので
11.messageを削除→青いmessageをペースト
という作業をすると簡単です。もちろん毎回ポップアップから青いMessage[]を選択して挿入してもOKです。
終わるとこの状態になります。黒くなっているタグには「11.array」というのものあるので間違えて一緒に置き換えないよう注意してください。
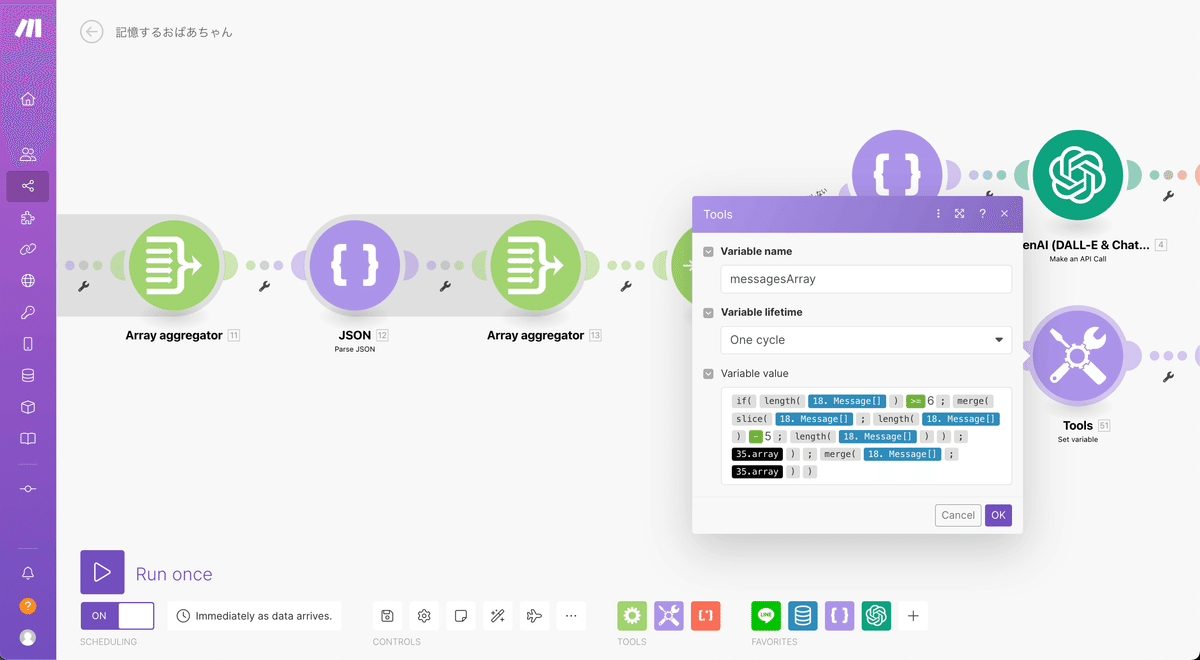
次に「35.array」を前半で「LINEからのメッセージを成形した方のArray aggregator」に置き換えましょう。これで最初の完成図と同じ状態になりました。皆さんの環境と画像では数値が違っていると思いますが色があっていればOKです。
ここで今回の処理が何を行っているのかを簡単に説明します。ちょっとだけ複雑なので読み飛ばしても作業に支障はありません。
ここではData storeに保存しておいた複数の会話履歴に対して最新から5つまでのメッセージを取り出し、それをLINEからのメッセージと合体させて新しいArray(つまりボットの記憶の塊)を作成するという処理を行っています。
※最初に出てくるifは初めてメッセージを送った方などそもそも6メッセージに満たない場合には最新から5つを取り出す処理はせずそのまま使う、という処理をしている
最終的には下記のように6メッセージ(5メッセージ以下の場合はある分全て)がChatGPTへ送られることになります。
※この後の工程で今回作成したものをChatGPTへ送る予定
取り出した会話履歴(5つ) + 今回送られてきたメッセージ(1つ) = 6つなお、コピペしたコード内の数字を変更することによって会話履歴としてChatGPTへ送る件数を自由に変更可能です。例えば8件の履歴を送りたい場合は下記のように変更しましょう。
{{if(length(11.message) >= 8; merge(slice(11.message; length(11.message) - 7; length(11.message)); 35.array); merge(11.message; 35.array))}}履歴数を変更する場合、ChatGPTが受け付けられる文字数が日本語でざっくり1,000文字〜2,000文字くらいなのでそれを最大として調整すると良さそうです。ちなみに最終的にどんなキャラにするかについて記載したArrayも一緒に送ることになりますが、その文字数も1,000〜2,000文字カウントされるのでお気をつけください。
※ChatGPTで受け付けられる文字数について、日本語の文字数のカウントの方法が開示されていないため1,000〜2,000文字という大きな幅での記載になっています。場合によっては2,000文字を超えても受け付けられることもあると思うので試しながら調整してみてください。
makeとChatGPTの料金面についてはこちらの記事で少し詳しく解説したので別途ご確認ください。
ChatGPTの接続
次に「ユーザーIDが存在しない」ルートで設定したChatGPT、Text parser、Array aggregatorの3連アイコンを複製しましょう。アイコン上で右クリックを行い、Cloneを選択すると複製可能です。

次にChatGPTのMessagesを下記の手順で設定していきます。
mergeを挿入する
前半でChatGPTの指示を記載したArray aggregatorを左に挿入
一つ前の工程で作成した紫色のmessagesArrayを挿入
最終的に下記のようになります。

次にText parser内、Textの内容を左隣のChatGPT返信タグに差し替えましょう。

そのままArray aggregatorの設定をしたいところですが、一旦置いておきます。
会話履歴を更新するためのData storeを設置する
次にData storeの設定を新たに追加します。今回は「Update a record」を選択しましょう。

KeyにはいつものUserIDを、2つの選択肢は両方ともYesを選択します。Recordは一旦空欄にしてOKを押しましょう。
このとき、もしかしたらKeyにフォーカスしたときに開かれるいつものポップアップ内にUserIDのタグが表示されていないかもしれません。これは左隣のArray aggregatorを確定していないことが原因だと思われます。このような場合にはとりあえずKeyに「a」など適当な文字列を入力し、OKボタンで確定しましょう。

次に先程置いておいたArray aggregatorの設定に戻ります。下記のように設定してOKを押しましょう。roleはassistant、contentは左隣のText parserのTextです。
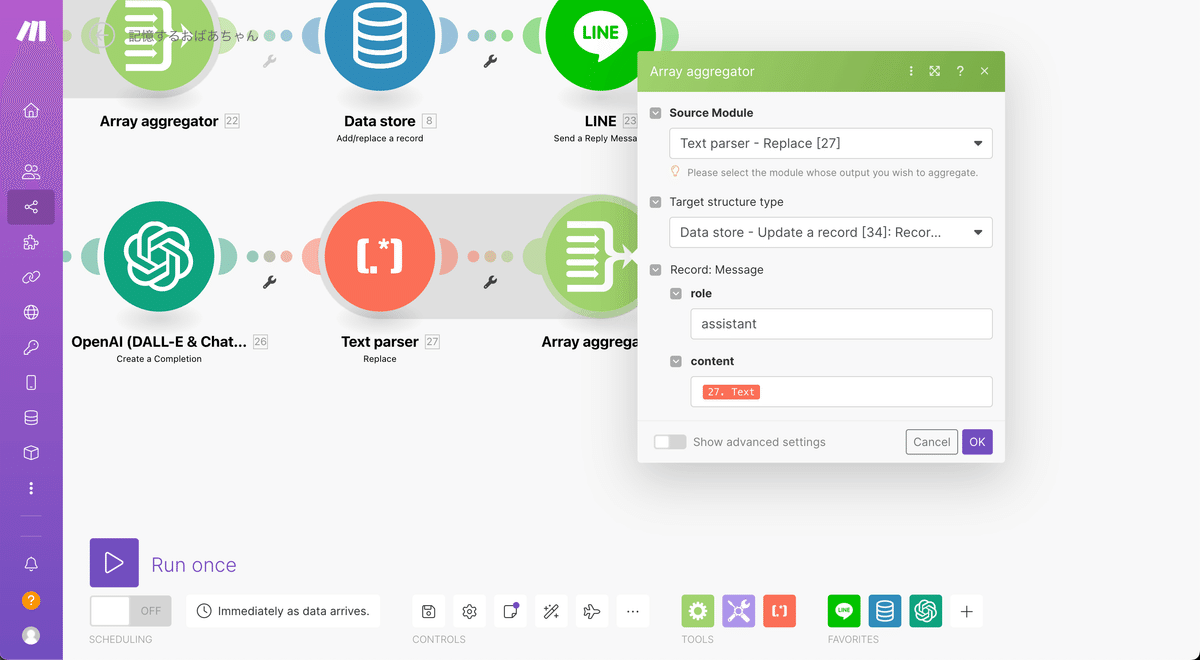
ここで右隣のData storeに戻りましょう。先程UserIDが入力できなかった方は今度こそ表示されていると思うのでKeyにUserIDタグを挿入していきます。
次にRecordを下記の手順で設定しましょう。
MapスイッチをONにする
mergeを挿入する
左側に3つ前で作成したmessagesArrayを挿入
右側に左隣のArray aggregatorを挿入
正しく設定できると下記のようになります。
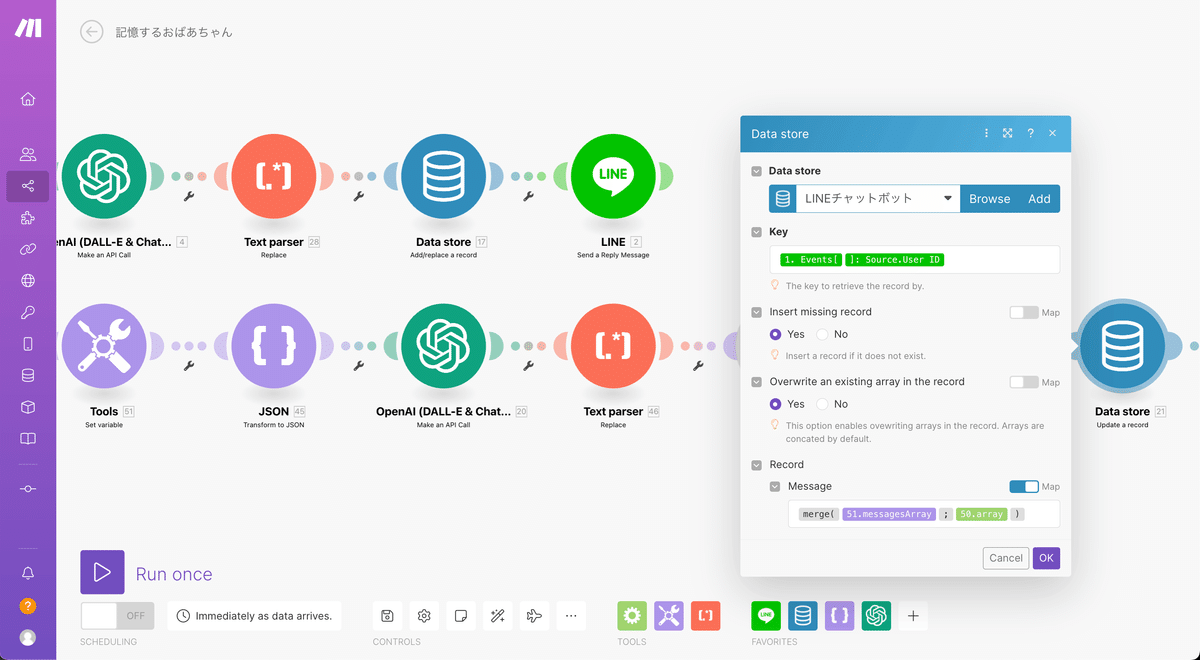
ここの処理によって元々保存されていた会話履歴にChatGPTからの返事を含めた内容が保存されることになります。
なお、ChatGPTへ渡すメッセージは途中で説明したように6メッセージ分ですが、保存されるメッセージは7つになります。計算は下記のようになります。
会話履歴から取得した5件 + LINEから受け取ったメッセージ1件 + ChatGPTから受け取った返事1件 = 7件次回以降のメッセージを受け取ったときに古いものが2件削除され、新しいものが2件挿入されることになります。


LINEを接続してテストを行う
最後に「ユーザーIDが存在しない」ルートからLINEの設定をCloneして接続し、ChatGPTの返事を「ユーザーIDが存在する」ルートのChatGPT返信タグに差し替えて完成です。
完成したら充分にテストを行いましょう。特に現状のテスト回数では保存されているメッセージ数が少ないと思うので何度かメッセージを送り、新旧のメッセージの入れ替えが正しく行われているかの確認をしてみてください。(SCHEDULINGをONにするかRun onceを押す→LINEを送る、としないとメッセージが返信されないので注意)
また、下記のように過去のメッセージを記憶していないと答えられないような質問もしてみましょう。

会話履歴がない場合「他にはあるかな?」と質問しても困ってしまうはずですが、設定がうまくいっていれば上記のようにちゃんと文脈を理解して返答してくれます。
以上、設定作業お疲れさまでした!
この記事が気に入ったらサポートをしてみませんか?