
Python プログラムが遅い原因を調べる方法

この記事は、NAVITIME JAPAN Advent Calendar 2020の 11日目の記事です。
こんにちは、けんにぃです。
ナビタイムジャパンで公共交通の時刻表を使ったサービス開発やリリースフローの改善を担当しています。
今回は Python のプログラムが遅い時に、その原因をどうやって調べれば良いのかを調べる方法について説明しようと思います。
私は今回説明する方法を使って処理時間が 70 分もかかっていた Python プログラムのボトルネックを特定し、処理時間を 15 分まで改善しました。
遅いのは Python だからなのか?
Python で書いたプログラムが遅いとき
「まあ Python は遅いからしょうがないよね」
「並列化すれば早くなるんじゃない?」
といった話をしたことはないでしょうか?
確かに他の言語と比べると遅い方ではあるのですが、そんな Python でも遅い原因を調査すると改善できる余地が見つかることが多々あります。というのもプログラムが遅い原因は Python 自体のオーバーヘッドだけでなく、実装したアルゴリズムに問題があるケースも多々あるからです。
プログラミングではよくこういう言葉が使われます。
推測するな、計測せよ
プログラムが遅い原因を調査しないで推測だけで改善を図ろうとすると、期待する効果を生み出せない可能性があります。
プロファイリング
そこで Python プログラムが遅い原因を調べるときに活用できるプロファイリングツールをいくつか紹介しようと思います。
まず計測で使用するための適当なサンプルコードを用意します。下記のリポジトリに丁度よいコードがありましたので、今回はこれを使わせていただきます。
example.py
#!/usr/bin/env python
def computation():
a = range(int(1e6))
b = range(int(1e6))
result = 0
for x, y in zip(a, b):
result += x + y
return result
def function1():
function2()
function3()
def function2():
for _ in range(50):
computation()
def function3():
computation()
def main():
function1()
if __name__ == '__main__':
main()とりあえずこのプログラムの実行時間を計測してみましょう。
$ time python example.py
real 0m5.598s
user 0m5.346s
sys 0m0.090s私の MacBook Pro だと 5 秒ほどかかりました。この原因についてツールを使って調査してみようと思います。
cProfile
Python にはプロファイリングをするための cProfile というツールが標準で用意されています。さすが Battery Included ですね。
使い方は上記のサイトにも記載されていますが、簡単に使い方を説明します。
$ python -m cProfile example.py
58 function calls in 5.148 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 5.148 5.148 example.py:14(function1)
1 0.000 0.000 5.048 5.048 example.py:19(function2)
1 0.000 0.000 0.100 0.100 example.py:24(function3)
1 0.000 0.000 5.148 5.148 example.py:28(main)
1 0.000 0.000 5.148 5.148 example.py:5(<module>)
51 5.147 0.101 5.147 0.101 example.py:5(computation)
1 0.000 0.000 5.148 5.148 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}上記のように cProfile 経由で example.py を実行します。すると標準出力にプロファイリング結果が表示されます。各列の意味は下記のとおりです。
・ncalls: 関数の呼び出し回数
・tottime: 関数の実行時間(サブルーチンの実行時間は除く)
・percall: 関数呼び出し 1 回あたりの実行時間
・cumtime: 関数の実行時間(サブルーチンの実行時間も含む)
・filename:lineno(function): ファイル名:行数(関数名)
-s を付けると指定カラムでソートして出力できます。
$ python -m cProfile -s cumtime example.py
58 function calls in 5.146 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 5.146 5.146 {built-in method builtins.exec}
1 0.000 0.000 5.146 5.146 example.py:5(<module>)
1 0.000 0.000 5.146 5.146 example.py:14(function1)
1 0.000 0.000 5.146 5.146 example.py:28(main)
51 5.146 0.101 5.146 0.101 example.py:5(computation)
1 0.000 0.000 5.046 5.046 example.py:19(function2)
1 0.000 0.000 0.100 0.100 example.py:24(function3)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}cumtime はサブルーチンの実行時間も含む関数の実行時間なので、ソートするとだいたいエントリーポイントがトップに出てきます。代わりに tottime でソートして、サブルーチンを除いた関数自身の実行時間でソートしたほうが遅い関数を見つけやすいです。
$ python -m cProfile -s tottime example.py
58 function calls in 5.124 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
51 5.124 0.100 5.124 0.100 example.py:5(computation)
1 0.000 0.000 5.024 5.024 example.py:19(function2)
1 0.000 0.000 5.124 5.124 example.py:14(function1)
1 0.000 0.000 5.124 5.124 {built-in method builtins.exec}
1 0.000 0.000 0.100 0.100 example.py:24(function3)
1 0.000 0.000 5.124 5.124 example.py:5(<module>)
1 0.000 0.000 5.124 5.124 example.py:28(main)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}computation という関数がどうやら遅いということが分かります。
SnakeViz
SnakeViz というツールを使うと cProfile のレポートをブラウザ上で見ることが出来るようになります。
まず SnakeViz をインストールします。
$ pip install snakevizSnakeViz を使うために cProfile のレポートをファイルに保存しておきます。
$ python -m cProfile -o example.prof example.pyレポートファイルを指定して SnakeViz を起動します。するとブラウザが起動します。
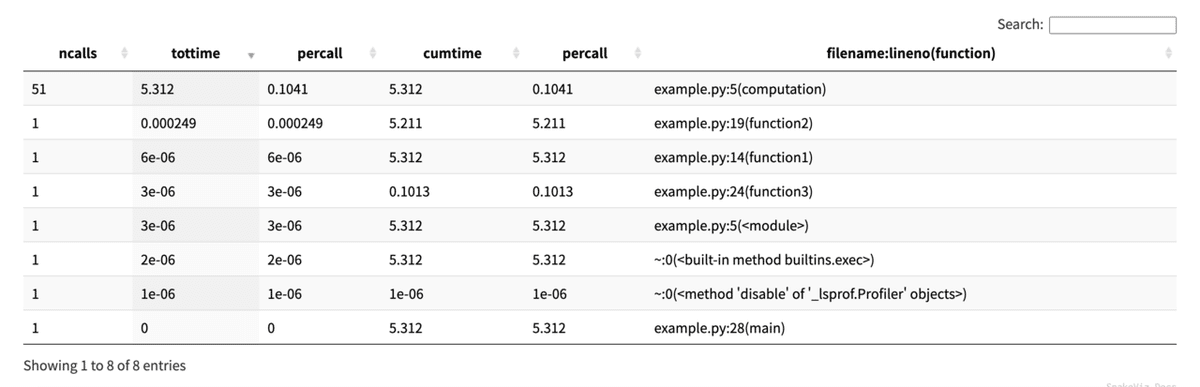
$ snakeviz example.prof画面の構成は、上部がコールスタックで

下部が計測結果になっています。列をクリックするとソートすることが出来ます。
py-spy
最近になって py-spy というプロファイラが登場しました。
cProfile との違いは cProfile は計測が終わるまで結果を確認できなかったのに対し、py-spy は実行しながら計測結果をリアルタイムに確認することが出来ます。
Rust で書かれていて軽快に動作することも特徴です。
py-spy をインストールします。
$ pip install py-spypy-spy は top コマンドと同じような UI で負荷の状態を確認することが出来ます。
$ py-spy top -- python example.pyWarning
py-spy は別のプロセスからメモリアクセスをしてプロファイリングを行いますが、セキュリティ上の理由で sudo を付けないとそれが実行できない場合があります。Linux はセキュリティの設定次第では付けなくても動きますが、少なくとも macOS では常に付ける必要があります。
参考:When do you need to run as sudo? - py-spy
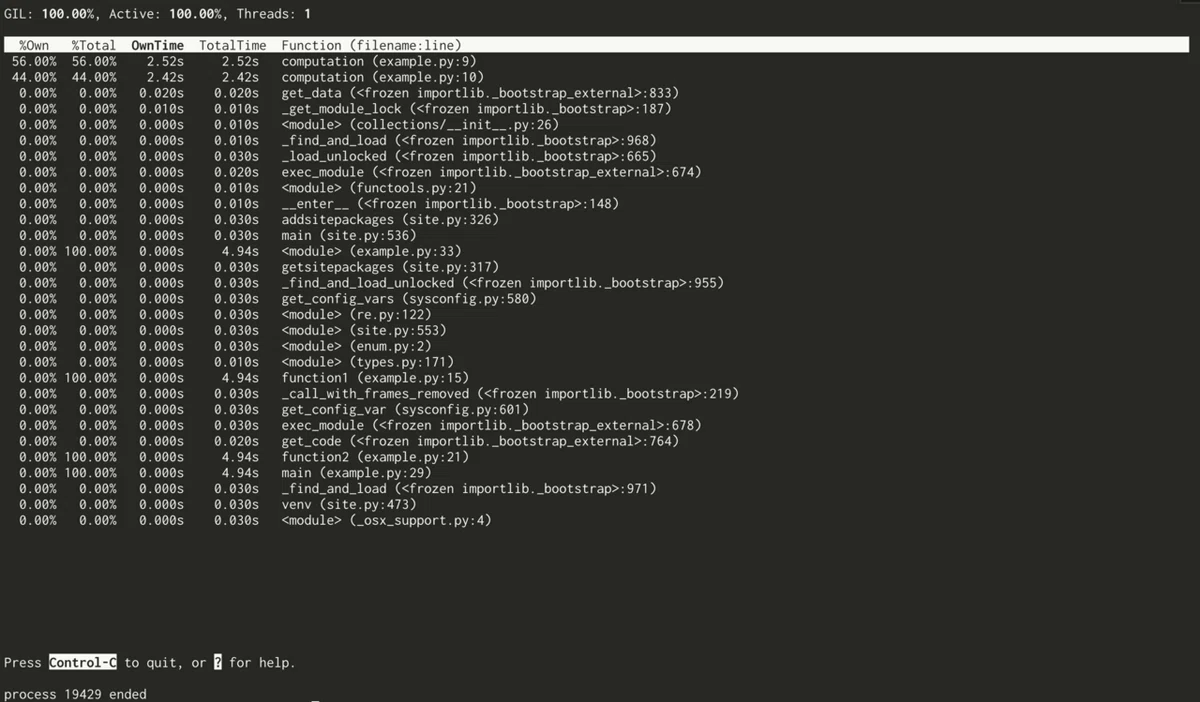
カラムに関する説明がドキュメントに見当たらなかったのですが、おそらく下記のとおりです。
・%Own: 処理全体に対してこの関数が占める割合(サブルーチンを除く)
・%Total: 処理全体に対してこの関数が占める割合(サブルーチンを含む)
・OwnTime: 関数の実行時間(サブルーチンを除く)
・TotalTime: 関数の実行時間(サブルーチンを含む)
・Function: 関数名
py-spy は PID を指定して起動することも出来ます。サーバのように起動しっぱなしのプログラムをプロファイリングするときには便利そうです。
$ py-spy top --pid <PID>例えば下記の記事で FastAPI という Web フレームワークについて解説しましたが…
FastAPI で実装したサーバアプリケーションのプロファイリングを取りたい場合は次のようにします。
$ py-spy top --pid $(pgrep uvicorn) -s-s を付けると子プロセスも含めてプロファイリングをしてくれます。
speedscope
speedscope はプロファイリングのレポートをブラウザで確認できるツールです。
可視化ツールと言う意味では SnakeViz と同種のツールになりますが、下記のような違いがあります。
・時系列で関数の負荷を確認できる
・Python 以外のレポートファイルも読み込める
・関数の呼び出し回数は見れない
speedscope のインストールは不要です。下記の URL にアクセスして利用できます。
speedscope に渡すためのレポートファイルは下記のように作成します。
$ py-spy record -f speedscope -o profile.speedscope.json -- python example.py
py-spy> Sampling process 100 times a second. Press Control-C to exit.
py-spy> Stopped sampling because process exitted
py-spy> Wrote speedscope file to 'profile.speedscope.json'. Samples: 490 Errors: 0
py-spy> Visit https://www.speedscope.app/ to viewレポートファイル作成したらブラウザ上でファイルを読み込みます。

結果

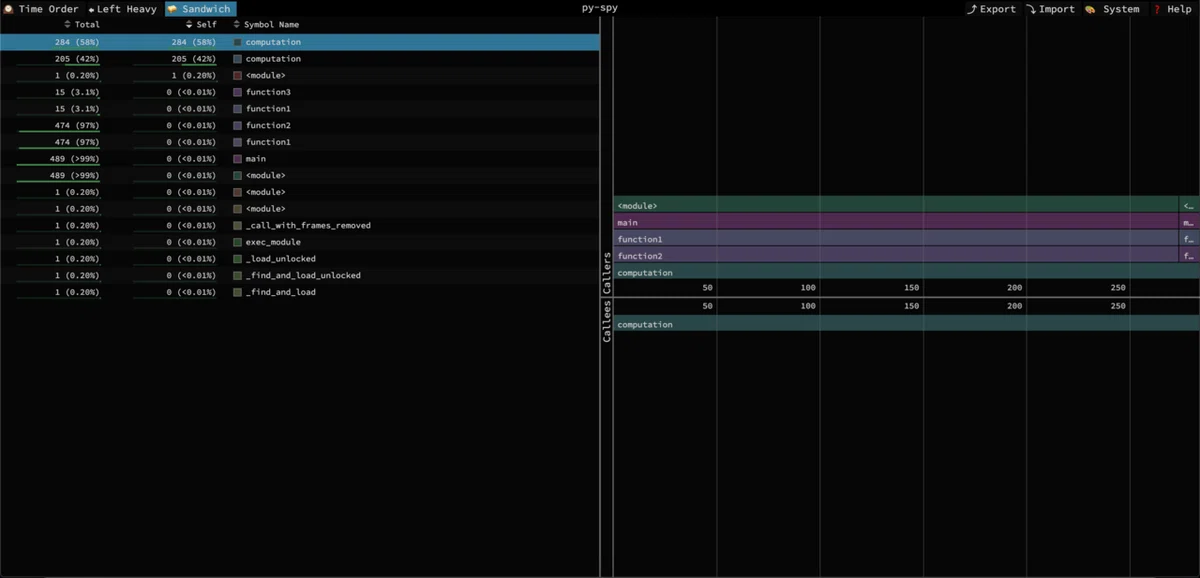
画面の左から右に向かって、プログラムの経過時間とともに関数の実行時間が可視化されています。
function2 の下部にある小さい四角が集まっている部分は computation の情報です。小刻みに何度も呼ばれているためこのようになっています。
computation は呼び出し 1 回あたりの実行時間は少ないのですが、何度も呼ばれているため、結果的に一番負荷がかかっています。このように処理時間を合算したときの結果を確認したいときは Left Heavy という表示モードに切り替えてみると分かりやすいです。
画面の左上に表示モードを切り替えるタブがあるので Left Heavy を選択します。
Left Heavy

さらに Sandwitch モードにするとコールスタックの確認ができます。
Sandwitch
遅い原因が分かった時に出来ること
遅い原因が分かった時にどのようなアプローチを取ればよいかは別途考える必要があります。プログラムの最適化に関する話は別の機会があれば話してみたいですが、本記事では遅くなる原因としてよく見る問題と対策を 1 つだけ紹介しておきます。
正規表現
正規表現による文字列処理は結構遅いです。私が今回改善したプログラムも正規表現を使っていてることが遅くなっている原因の 1 つでした。改善の仕方としては
・簡単な文字列処理では正規表現を使用しない
・.* を使わない
・re.compile でコンパイルしておく
などがあります。str.startswith や str.replace などの関数を使えばわざわざ正規表現を使わなくても解決できることはあります。
例えば文字列 s が "Hello" で始まるかどうかを確認したいときに
if re.search(r"^Hello.*", s):
...のように正規表現を使うよりは
if s.startswith("Hello"):
...と書いたほうが効率が良いです。
まとめ
以上プロファイリングを行うための 4 つのツールを紹介しました。
・とりあえずプロファイリングをしてみたいなら cProfile + SnakeViz
・リアルタイムに計測したいなら py-spy + speedscope
・正規表現は結構遅いということを知っておく
ボトルネックを特定してプログラムがどんどん速くなるのは楽しいので皆さんもぜひプロファイリングに挑戦してみて下さい。