
【都知事選×テクノロジー】東京都知事選におけるHuman-in-the-Loop機械学習

安野たかひろ事務所 技術チームの角野です。前回の投稿ではAIあんのにおける返答生成技術の詳細に触れましたが、今回は返答生成に用いるデータの整備に焦点を当てて解説します。
なぜデータの整備が必要なのか?
AIあんのでは政策に関する質問に対してLLMで返答の生成を行っていますが、元のLLMには安野の政策に関する知識が含まれておらず、そのままでは政策に関する質問には回答できません。
そこで、前回の記事でも解説しましたが、AIあんのではLLMに入力するプロンプト中に政策に関する知識を注入することで、政策に関する質問に回答できるようにしています。当然知識がない質問に対しては回答できないため、ユーザーの質問に対して正確に回答するには政策に関する知識をデータとして整備することが重要となります。
返答生成に利用しているデータ
AIあんのでは、次の2種類のデータを返答生成時に利用しています。
今回の記事では、私が携わったFAQの整備について解説します。
FAQ
よくある質問とその回答のペア
政策に関するドキュメント
安野たかひろの政策についてまとめたドキュメント
AIあんのにおけるKPI
返答内容を改善していくにあたっては、「返答の良さ」を評価できるKPIを設定することが重要となります。
今回、AIあんのでは「コメントに対する有効な返答数」をKPIとしてトラックしていました。AIあんのでは、知識やFAQが足りていない場合や、ハルシネーションチェックに引っかかった場合などの幾つかのケースで「質問に回答出来ない」旨を返すようになっており、このような返答を除外した返答を「有効な返答」として件数を集計しています。
注意点として、この指標は「返答の良さ」を計測する上で万能なものではありません。例えば、質問に対して的を得ていない回答がされていても「有効な返答」として集計されてしまうといった欠点はあります。一方で、返答の質を評価することは容易ではなく、その領域まで踏み込むと評価に労力もかかるため、測定のしやすさを鑑みて今回は「有効な返答数」をKPIとして採用しました。
FAQの整備フロー
「有効な返答数」及び返答率を向上させるために、AIあんのチームでは運用開始後も継続的にFAQのアップデートを実施していました。
FAQの整備フローの全体像は次の通りです。
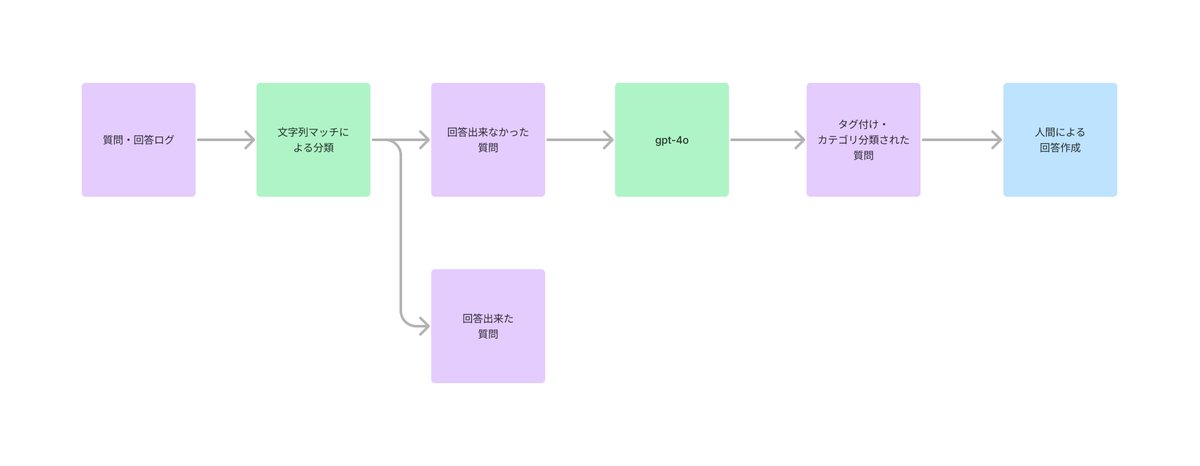
設計思想
なるべく人の手をかけずに効率よく回答を作成する為に、質問に対する回答作成に人間が着手する前にLLMを用いたタグ付けとカテゴリ分類を事前に実施しています。
カテゴリについては、大カテゴリ・小カテゴリとして固定のカテゴリを用意した上で、LLMを用いていずれかのカテゴリへの分類を行っています。
タグについては、幾つかのタグを用意してそれぞれ当てはまるか否かを分類しています。
タグの例
政策に関する質問か否か
選挙活動に関する質問か否か

タグ付け・カテゴリ分類を行う意図は、回答作成のアサインを効率化するためです。
質問に対する回答作成はチーム安野のメンバーが行うのですが、政策について詳しい方・技術に詳しい方・デジタル民主主義に詳しい方など、メンバーによって得意な領域が異なります。
このため、それぞれのメンバーが得意な領域で回答作成を行っていきたいのですが、カテゴリ分けがされていない状態で回答作成を依頼をしてしまうと各メンバーが回答を作成すべき質問を選別するのに時間がかかってしまいます。
そこで、今回AIあんのチームでは人間が回答作成に着手する前に、このようなタグ付けとカテゴリ分類を実施するような仕組みを作りました。
この仕組みを導入することで、回答作成を担当するメンバーが自身の得意領域に絞って効率的に回答を作成できるようになりました。
うまくいかなかった試み
前述したカテゴリ分類は、LLMを活用して人間の作業を効率化・サポートした事例として比較的上手くいった事例になるのですが、試してはみたものの上手くいかなかった試みもあります。そのような取組について以下でご紹介します。
LLMによる回答草案の作成
回答作成をより効率化するために、回答草案の生成をLLMで実施する試みを行ったのですが、生成される回答においてハルシネーションが発生する割合が高く、逆に回答作成の効率が悪くなると判断したためこちらは採用を見送りました
LLM as a Judgeを用いた出力の自動評価
LLM as a Judgeとは、LLMの出力を、LLMを用いて自動で評価する枠組みのことです
質問応答のような自然文を出力するタスクにおいて「返答の良さ」を自動で評価することは難しいとされていますが、この自動評価をLLMで実施するのがLLM as a Judgeです
今回、LLM as a Judgeの枠組みで出力の自動評価を実施できる仕組みの構築はしたのですが、LLMによる評価結果が人間の感覚と乖離しているケースがあり、評価の妥当性が担保出来なかったため運用には組み込みませんでした
評価プロンプトのチューニングや、適切な評価セットを整備していればまた違った結果になったかもしれません。今回は時間がかなり限られていたため、そちらの整備にまで手が回りませんでした。
まとめ
今回の記事では、AIあんのにおける返答生成のためのデータ整備について解説しました。機械学習の分野では、人間がデータ整備に積極的に関与して機械学習モデルの性能を向上させる枠組みを「Human-in-the-Loop機械学習(HITL)」と呼びます。今回実施したデータ整備も、このアプローチの一例であると考えています。また、今回はLLMを活用したデータ整備の効率化も図っており、都知事選という題材を抜きにしても少し面白いHITLの事例になったのではないかと考えています!
昨今ではLLMを初めとした基盤モデルが隆盛を極めており、学習データがなくとも様々なタスクを解けるようになったと言われています。この主張自体は間違いではなく、またとても良いことでもあるのですが、基盤モデルだけで全ての問題を解決できるわけではないため、取り組むタスクによっては依然としてデータの整備は重要な課題となります。今回のブログ記事が、これからデータ整備に取り組むどなたかのお役に立てば幸いです!
そして、いよいよ明日が投票日となりました。
本日7/6に有楽町でマイク納め(19時開始予定)を行う他、22時30分頃からはYoutubeで生配信も予定されていますので、こちらのnoteをきっかけに安野たかひろに興味を持っていただけましたらぜひご覧いただけますと幸いです!
#安野たかひろ を都知事に
最新情報は、本人・事務所の公式X(Twitter)アカウントをフォローしてご覧ください
安野たかひろ事務所(@annotakahiro24)
安野たかひろ本人(@takahiroanno)