
【AI x 教育 論文紹介】 第1回 Deep Knowledge Tracing

はじめまして。atama plusというAI x 教育のスタートアップでエンジニアをしている安本です。4月に入社して、6ヶ月が経とうとしています。
教育の分野では、アカデミア・インダストリーの両方で、日々様々な研究が世界中で行われおり、特にAIをはじめとしたテクノロジーの活用は大きなトピックとなっています。これらの研究成果を必要に応じてプロダクトに適用できるよう、atama plusでは週に1度、AI x 教育に関連する論文の勉強会を行ない、世界的な技術トレンドのキャッチアップを行っています。
勉強会は6月からスタートし、atama plusの中でも、生徒の学習体験の改善を主なミッションとしている、アルゴリズム開発チームのメンバーが主に参加しています。
このシリーズでは、勉強会で発表した内容を紹介していきたいと思っています。第1回となる今回は、Deep Knowledge Tracing と呼ばれる論文の紹介です。
ここからは、Knowledge Tracingというタスクの紹介と、論文の詳細な説明に入りますが、最初に、今回の論文の要点を簡単に説明しておきたいと思います。
・オンラインの学習システムにおいて、生徒が次に与えられる問題に対してどの程度の確率で正解できるかを当てる「Knowledge Tracing」というタスクがある。
・このタスクに深層学習を持ち込んだのが「Deep Knowlege Tracing」と呼ばれる手法。深層学習の導入によって、生徒の長期にわたる過去の正答履歴や問題の背景にある潜在的なスキルを考慮した予測ができるようになった。
・結果として、既存手法と比較して大幅な予測精度向上を達成した。また、この予測モデルが、出題順序アルゴリズムの改善や問題間の関係性理解にも使えることを示した。
1. Knowledge Tracing
Deep Knowledge Tracingは、「Knowledge Tracing」と呼ばれるタスクにDeep Learningの技術を導入した、という内容の論文です。
まずは、この「Knowledge Tracing」がどのようなタスクなのかを説明します。
1.1 Knowledge Tracing とは?
Knowledge Tracing(以下、KT)とは、「これまでの学習履歴から生徒の習熟度を予測する」というタスクです。A Survey of Knowledge Tracing によると、KTは以下のように定義されています。
“Given the sequence of students’ learning interactions in online learning systems, knowledge tracing aims to monitor students’ changing knowledge states during the learning process and accurately predict their performance on future exercises”
ざっくりと翻訳すると、こんな感じになります。
「オンライン学習システムにおける学生の学習インタラクションのシーケンスを考えると、ナレッジトレーシングは、学習プロセス中に変化する学生の知識状態をモニターし、将来の演習における学生のパフォーマンスを正確に予測することを目的としています。」
前半の「学生の学習インタラクションのシーケンス」とは、生徒のこれまでの学習履歴のことを指します。同じ論文にもう少し分かりやすい図があるのでこちらも紹介しておきます。

通常、オンライン学習システムでは、様々な問題(Exercise)が生徒に提示され、生徒はその問題を順番に解いていきます。それぞれの問題には、問題を解けるようになることで上昇が期待されるスキルが事前に紐付けられていることがほとんどかと思います。例えば、「1.2 + 1.5=?」という問題には、「小数の足し算」というスキルが紐付けられます。
このようなスキルのことを、KTの文脈では、ConceptやCompomentと呼ぶことがあります。上の図では、k1:equality、k2:inequality、k3:plane vector、k4:probabilityの4つのスキルが定義されており、それぞれ異なる色が割り当てられています。そして、各問題の色が、紐づけられているスキルを表しています。
KTでは、生徒が問題を解いたときの正誤情報などに基づいて、生徒の習熟度を推定します。生徒の習熟度は、各スキルに対して0〜1.0の間でスコアリングされ、結果としてレーダーチャートで表現できています。なお、スコアは、1.0に近いと、高い確率でその問題に正答できるという意味になります。
また、ここでは予測に利用する情報として正誤情報を挙げましたが、他にも解答にかかった時間やヒントの利用有無など、システムを通して収集可能なデータであればどのようなデータも活用できます。
なお、KTのタスクは以下のように定式化できます。定式化方法もいくつかバリエーションがあるようですが、ここではDeep Knowledge Tracingの論文に準拠しました。

1.2 Knowledge Tracingの嬉しさ
KTができるようになると、どのような嬉しさがあるのでしょうか?ここではメリットを2つの観点から紹介します。
(1) オンライン学習システムが生徒のレベルに応じた適切な問題を出題できる
生徒にとって、難しすぎる、あるいは簡単すぎる問題を出題することは、効率性の低下に繋がります。現在の生徒の習熟度を把握できていれば、生徒に個別最適化された出題が可能となり、効率のよい学習体験を提供できると考えられます。
(2)生徒が自分の状態を把握できる
自分の習熟度が可視化されることで、生徒はどのスキルが足りておらず、学習が必要なのかを把握できるようになり、結果として学習効率の向上が期待できます。
1.3 Knowledge Tracingの研究トレンド
先ほど紹介したサーベイ論文によると、KTという言葉が最初に登場したのは、Corbett and Andersonらの研究(1994年)であり、彼らはベイジアンネットワークを用いて生徒の学習プロセスのモデル化を行いました。この手法はBayesian Knowledge Tracingと呼ばれています。
その後、多くの人々にKT研究の重要性が認識され、Learning Factor Analysisや、Performance Factor Analysisなどのロジスティックモデルを用いた研究に繋がりました。
近年は、複雑な表現の学習が可能なDeep Learningの技術がKTの分野にも導入されています。例えば、この記事で紹介するDeep Knowledge Tracingの論文では、Recurrent Neural Network(RNN)を用いることで、従来手法を大幅に上回る性能を達成しました。その後は、RNN以外にも様々なNeural Networkを導入した研究が行われてきており、一大ムーブメントとなっています。
この記事では、この一大ムーブメントを引き起こすきっかけとなった論文である、Deep Knowledge Tracingについて、解説していきたいと思います。
なお、KTのサーベイ論文の中では、KTの手法を以下のように分類しています。Deep Knowledge Tracingは、Deep learning-based modelsの中でも、最初に提案された手法となります。

2. Deep Knowledge Tracing
ここから、本題の論文紹介に移りたいと思います。今回紹介する論文の出典情報は以下となります。
論文名:Deep Knowledge Tracing
著者:Chris Piech, Jonathan Bassen, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas J. Guibas, Jascha Sohl-Dickstein
雑誌/会議名:Advances in Neural Information Processing Systems, 2015, 28: 505-513.
以下の紹介では、論文の各章を簡単にサマライズして説明していきますが、補足が必要と思われる部分については、適宜詳細な説明を加えています。
2.1 導入
学習とは、人間の認知能力を反映したものであるため、本質的に複雑であり、よってそれを表現するためには複雑なモデルが必要とされます。そこで、本研究では、より複雑な表現を学習できる深層学習の手法を導入します。深層学習を用いたモデルでは、生徒の習熟度を潜在変数として表現し、これを大量のデータから学習できるようになります。
この論文の主な貢献は以下となります。単に性能が良いだけでなく、#3に書かれているように、これまでの手法で必要とされていた問題とスキル(*1)のマッピングが不要であり、逆にこれをデータから学習できる点も、この手法の大きな特徴の1つと言えます。
(*1)論文中ではConceptと書かれていますが、この記事では分かりやすさを重視して「スキル」に置き換えて説明しています。
(1) KTのタスクにRNN(Recurrent Neural Network)をはじめて適用した。
(2) Assistmentsデータセットを用いたKTのベンチマークにおいて、過去のbest resultと比較して25%のAUC改善を達成した。
(3) 開発したモデルは、エキスパートによるアノテーション(どの問題がどのスキルに紐づいているかのマッピング)が不要であることを示した。
(4) 学習したモデルを分析することで、問題間の関係性の発見やカリキュラムの改善に繋げることができることを示した。
2.2 RNN/LSTMを使ったモデル化
これまでにも何度か触れられている内容ですが、著者らは人間の学習は、多様な側面(教材、文脈、時間変化など)によって影響を受けると考えており、人間の専門家が問題の属性を定義したり、グラフィカルモデルを構築したりするだけでは、定量化に限界があると考えています。
そのため、これらの属性や関係性といったものは、深層学習によってデータから自動で抽出、あるいは学習されるべきと考えています。
本研究では、2つのタイプのRNN(vanilla RNNとLSTM)のモデルを、KTのタスクに適用しています。ご存知の方も多いかとは思いますが、簡単にRNNとLSTMについて紹介します。
まずRNNには、時系列のデータを順に入力していきます。各時刻tでは、1つ前の時刻t-1における隠れ状態hと、その時刻のデータxを入力として、更新された隠れ状態と出力yを出力します。隠れ状態が再帰的に利用されるため、”Recurrent” Neural Networkと呼ばれています。
RNNを使うと、隠れ状態を通して、その時刻における入力の情報だけでなく、過去の情報までもを考慮して出力を計算することができるようになります。過去の情報をどのように未来に伝えるかや、それらの情報を使ってどのように出力を計算するか、といったことが、RNNの重み(下図におけるW)に格納されます。

先に説明したRNNには、長期的な依存関係の情報を伝達しづらい(情報が伝播の途中で消失しやすい)という問題がありました。
このような問題に対応するため、LSTM(Long Short Term Memory networks)が考案されました。LSTMは、RNNに対していくつかのゲートを付与することで、情報の伝達を直接制御しやすくしたもので、結果として情報がより長い期間を通して伝わりやすいという特徴があります。
LSTMについては、Christopher Olahによるブログがとてもわかりやすいので、詳細を知りたい方は合わせてご覧ください。
次に、モデルの入出力について説明していきます。
入力xについては、以下の図で説明しています。基本的にはone-hotベクトルに変換して入力として使いますが、問題の種類が多くなると次元数が増えてSparseになってしまうため、全ての入力の組み合わせに対して次元の少ないランダムベクトルを割り当てるというトリックを用いて次元削減を行っています。

出力yについては、問題(Exercise)の数と同じ長さのベクトルとなります。ベクトルの各値は、生徒がある特定の問題に正解できるかを予測した確率(0〜1)を表します。
最後に、最適化の方法ですが、loss関数はcross entropyを用い、SGD(Stochastic Gradient Descent)によって最適化を行います。

2.3 DKTの応用方法
Deep Knowledge Tracing(DKT)の応用先として、論文では以下の2つを提案しています。
①カリキュラムの改善
どの問題を次に出すべきかを、生徒の習熟度に応じて適切に変えることができるようになるため、カリキュラムの改善に繋げることができます。
②問題間の関係性発見
問題間の潜在的な構造や、問題の背景にあるスキルを発見できるようになります(一般的には専門家が作成するものです)。
問題間の関係性の強さの計算方法として、ある問題iから問題jへの影響度を、以下の式に従って計算できます。ここでy(j|i)は、最初に問題iに正解した後に、問題jの正解確率を予測した値を表します。
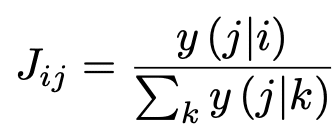
2.4 実験に用いたデータセット
この論文では、以下の3つのデータセットを扱います。
①Simulated data
5つの仮想的なスキルと、これに紐づく問題50問を作成し、2,000人の生徒がこれを解いたシミュレーションデータを作成します。各生徒はそれぞれのスキルに対する潜在的な習熟度を保持しており、各問題は1つのスキルと難易度を持つものとします。
このとき、生徒の正答確率を、IRT(Item Response Theory)の式によって下図のように求めます。ただし、αは各生徒のスキルに対する習熟度、βは問題の難易度、cはランダムな値とします。

生徒が時間とともに学習することも考慮します。具体的には、問題を解くと、その問題に紐づくスキルの習熟度lが線形的に変化していきます。
②Khan Academy Data
Khan Academy上での解答情報を使ったデータセット。データセットには、47,495人によって解かれた、69の異なる問題に対する、計140万分の解答データが使われています。なお、Khan academyのカリキュラムは、基本的にself-directed、つまり生徒がどの問題を解くかを自分で決めるため、バリエーションに富んだデータが得られていると考えられます。
③Benchmark Dataset (Assistments)
Assistments 2009-2010 public benchmark dataset。
論文執筆点で、最も大規模なKTタスク用の公開データセットとなります。
2.5 実験結果
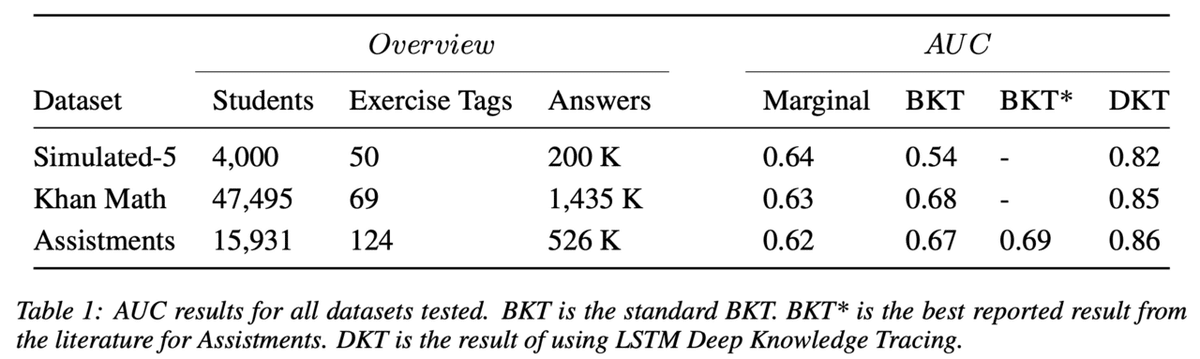
予測精度を既存手法と比較した結果が以下の表となります。既存の手法であるBKTと比較して、DKTが大幅な精度向上を達成していることが分かります。なお、BKTはBayesian Knowlege Tracingのことで、Marginalというのは、周辺確率を求めてそれをもとに予測した時の結果となります。
次に、Simulated datasetにおいて、スキル(図中ではHidden Conceptsに対応)の数と予測精度の関係性をプロットした図が以下となります。Oracleというのは、IRTの全パラメータを既知としたときの予測精度を示します。全パラメータを知っているのに精度が1.0より低いのは、結果が確率的に振る舞うことが原因です。
DKTの結果は、赤(RNN)、および青(LSTM)の線で描かれており、紫の線で描かれているOracleの結果、つまり、IRTの全パラメータを既知としたときの予測性能とほぼ同等の性能を達成できていることが分かります。
この結果から、潜在的なスキル、各問題の難易度、生徒の知識の事前分布、各問題を解いた後の習熟度変化、といったものを、DKTが学習できていると言えます。
なお、スキルの数が増えるに従ってBKTの性能が落ちているのは、BKTにはラベル化されていないスキルを学習するようなメカニズムが備わっていないことが原因と考えられます。

次に、カリキュラム改善の観点から、DKTを活用した実験の結果です。5つのスキルから抽出された30問の問題に対し、異なるカリキュラム(=出題順)で解いたときの予測正答率の平均値を算出したものが、以下の図となります。

ここで、Mixingは、異なるスキルの問題を混ぜて出題するカリキュラム、Blockingは同じタイプのexerciseを続けて解かせるカリキュラムのことを指します。
またMDP-N(MDP-1、MDP-8)は、将来のNステップを予測した上で次の出題を決める方法で、他のカリキュラムより優れた性能を示すことが分かります。
この結果はシミュレーションデータによるものではありますが、精度の高いKCのモデルを構築することで、カリキュラムの改善に活用できることを示した、興味深い結果だと思いました。
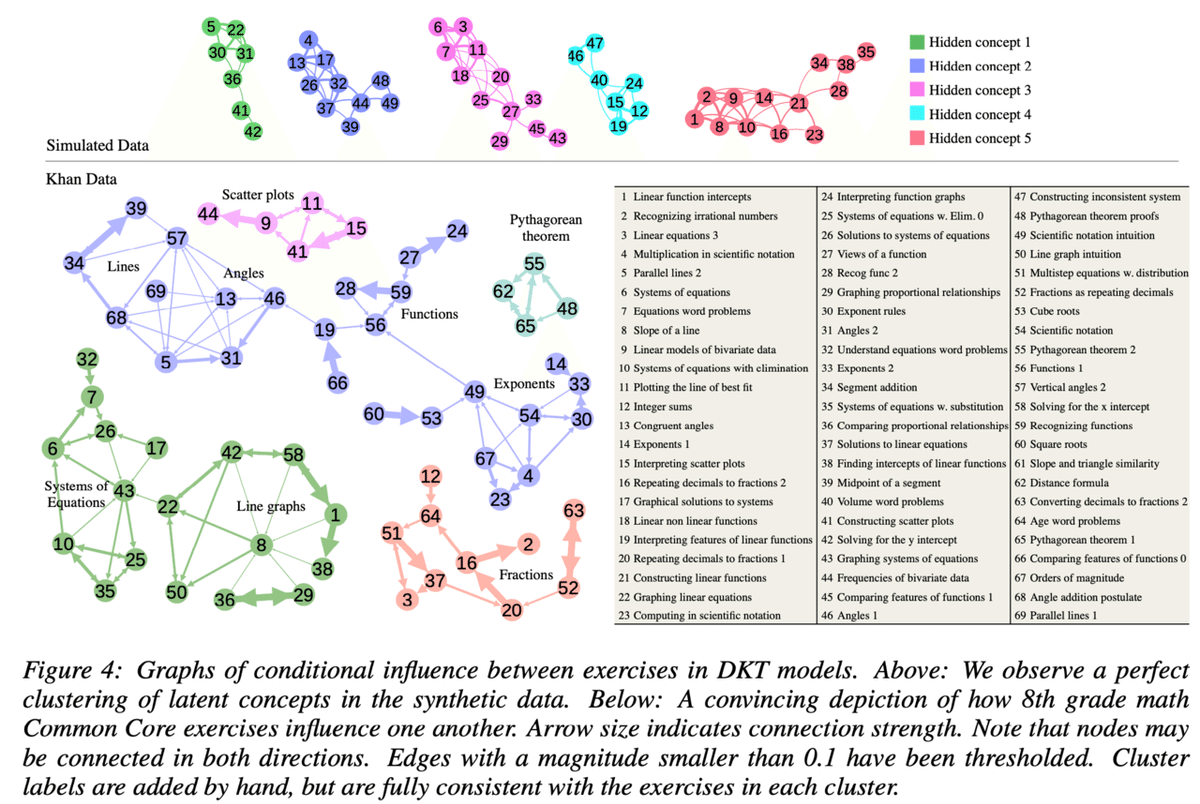
最後に、問題間の関係性を可視化した結果です。図の上側がSimulated data、下側がKhan Academy Dataの結果となります。
Simulated dataでは、意図した通り5つのクラスタができていることが分かります。Khan Academy Dataでも同様の手法でグラフ化を行った結果、それらしいクラスタが生成されていることが分かります。
ここでは割愛しますが、論文中では、単純な問題間の遷移確率や、連続で正解した問題間の遷移確率でも同様のグラフを作成しており、それら手法ではこのような綺麗なクラスタは作成できなかったと報告しています。
2.6 まとめ
提案したRNN/LSTMを用いたモデルには、問題とスキル間のマッピングを与える必要がなく、また入力として様々な特徴量を扱うことができる、という特徴があります。一方で、学習には、大量の訓練データが必要になるという問題がありました。
今後の研究の拡張としては、他のデータを入力として用いる(例:解くのにかかった時間など)、他の利用用途の検討(ヒントの生成、dropoutの予測)、教育学の文献などで提唱されている仮説の検証に用いるといったことが考えられます。
3. 所感
深層学習を使って、大量のバリエーション豊かなデータがあって、end-to-endで学習すれば、高い性能を得られる、というのを証明した論文です。
性能の大幅向上を達成したのは凄いと思う一方、深層学習等のブラックボックスな手法で一般的に課題として言われる解釈性については、そこまで議論されていないように思えます。
最近は、もう少し明示的なモデル化を行った上で、モデルのパラメータを深層学習の手法で推定するといったアプローチなども出てきており、このような解釈性の向上に関する研究についてもウォッチしていきたいと思っています。
atama plusでは、蓄積されるデータを元に、生徒の学習体験を日々改善しています。もし少しでも興味がありましたら、ぜひ一度お話させて下さい。ご応募お待ちしております。
また、9/29(水)には、弊社のエンジニアリングについて紹介するイベントが予定されています。こちらも是非ご参加下さい。
この記事が気に入ったらサポートをしてみませんか?