
【IA】ゼロから学ぶ情報アーキテクチャ

情報アーキテクチャとは
情報アーキテクチャ (Information Architecture: IA) とは、情報を整理しユーザに分かりやすく伝える、または情報を探しやすくするための表現技法です。情報アーキテクチャの定義としては、以下のものがあります。
情報の階層化、ラベリング、ナビゲーションシステムの組み合わせ
コンテンツへの直感的な理解、およびアクセスを容易にするためのデザイン
情報の構造化と分類を行うことで発見、および管理を容易にする
アーキテクチャの基本的なコンセプトを理解するために、上記に登場するキーワードの定義を詳しく説明していきます。
情報(インフォメーション)
データと情報は、似ているようで厳密に区別されます。データとは、事実や数字が関係しています。例えば、天気や、電車の到着時間などで、それら単体では意味や価値を持ちません。一方で、情報とはデータを収集、加工したもので、それらの事実から法則を見つけたり、意味を見つけたりします。
データが高度に構造化された例としては、データベースがそれにあたります。例えば、Google はインターネットの情報を整理し、データベースで管理しています。私達は、Google に対して何らかの質問(クエリー)を投げかけ、情報を取得します。
Google は投げかけられた質問に対して、膨大な量のデータから、そのユーザにもっとも相応しい情報を返します。それらは、信頼できるサイトであったり、問題を解決するための手段が書かれた情報であったり、役に立つサービスかもしれません。いずれにしても、Google は収集したデータに付加価値を付けてユーザに情報として提供しています。
構造化・組織化・ラベリング
構造化(Structuring)を行うためには、サイト内の情報を適切な粒度に切り分ける必要があります。例えば、漫画に特化したサイトを設計する場合、情報の粒度は作品単位が考えられます。
組織化(Organizing)は、それらの要素をグループ分けし、意味があって他と区別できるカテゴリーに分類することです。例えば、漫画の場合は恋愛、推理、ホラー、ギャグ、スポーツ、グルメ、ギャンブルなどです。
ラベリング(Labeling)は、ラベリングとは、情報にタグと呼ばれるラベルを付け、検索できるようにする分類方法です。ラベリングは、別々のカテゴリーを横断するためのナビゲーションリンクとしての機能も果たします。
情報の発見
ここで説明する情報の発見とは、見つけやすさ(ファインダビリティ)を指します。情報の見つけやすさは、ユーザビリティにとって非常に重要な要素です。例えば、図書館の中から目的の本を探したり、百科事典の中から目的の項目を探したりするなどです。
私達はインターネットから情報を発見するために、Google などのサービスを利用して情報を検索します。しかし、「情報を検索する」機能は極めて難しいものです。同一のキーワードで検索を行っても、検索結果の評価はユーザによって異なるためです。もしかすると、同一ユーザであったとしても、状況次第で評価が変わるかもしれません。人工知能、情報の視覚化、パーソナル検索、セマンティック Web などの技術の向上により、検索における諸問題が解決されるという意見もありますが、現状は否定的な意見が多数派です。「情報の検索」は、これからもノイズが混じり、変則的で、ユーザのニーズや、抱える問題を解決するための完璧な結果は返せないという見方をされています。
情報アーキテクチャの設計
Jesse James Garrett が考案した 5 Planes Model は、ユーザのニーズや目的から視覚的デザインまでを 5 階層に分けて定義したモデルです。最初に最下層のユーザのニーズや目的を定義し、上位層にシフトしながらデザインを具現化していく設計手法です。この手法は、ユーザにフォーカスした設計が可能であり、ユーザの求めるデザインを実現する可能性を高めます。情報アーキテクチャは、構造の部分に位置します。
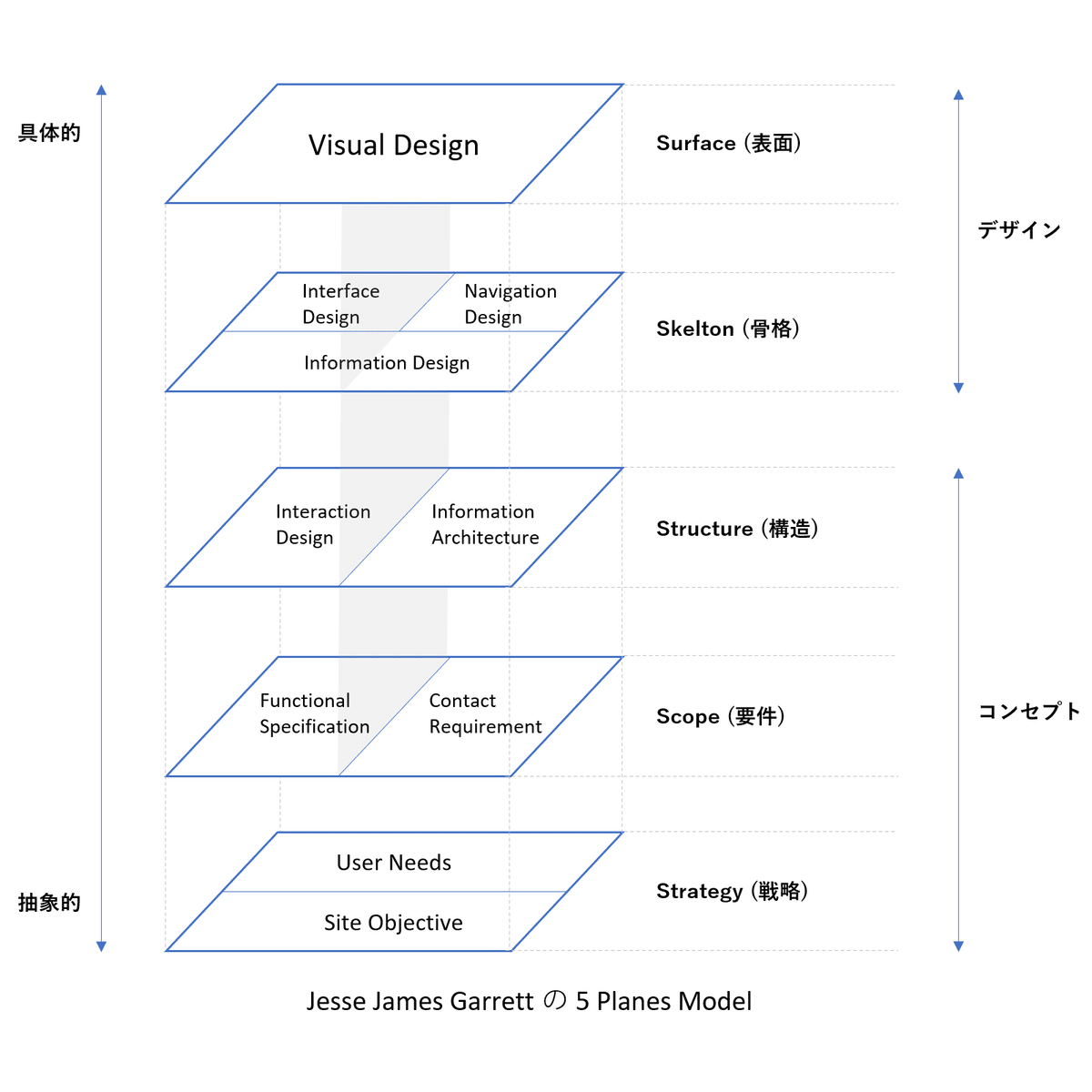
情報アーキテクチャを構成する要素は、ユーザ、コンテンツ、コンテキストからなり、これらの要素は相互に依存している関係になります。これらの構成要素における概念は、複雑な依存関係を扱うために使用されます。

ユーザ
情報を利用するユーザには、嗜好や行動に違いが見られます。あなたの Web サイトを利用しているユーザの行動はどのようなものでしょうか。例えば、問題を素早く解決したいユーザが多い場合、結論から先に書くべきです。逆に最初からじっくり読みたいユーザが多い場合、体系的な文章構造が良いでしょう。
いずれにしても、コンテキストにおける情報ニーズや情報探索行動に違いがあります。そのため、設計時にはペルソナ/シナリオ法が用いられます。ペルソナ/シナリオ法は、架空のターゲットユーザ (ペルソナ) を仮定し、要求分析を行う方法です。ペルソナとして選定されるターゲットユーザには、年齢、性別、職業、住所、家族構成など、様々な属性が与えられます。
ペルソナ/シナリオ法の要求分析は、ペルソナが満足するための目標設定を行います。ペルソナが製品をどのように操作し、どのように学習していくかシナリオを作成し、検証していく過程でユーザビリティに関する問題点を洗い出します。ペルソナ/シナリオ法のメリットは、設計や実装時にインターフェースや操作性の制約が、ハードウェアやプログラムによって左右されない点です。また、ペルソナという架空のユーザがいることで、ユーザ視点に立った要求が見えやすいというメリットもあります。
コンテンツ
一般的にコンテンツの定義は、非常に広いものになります。ドキュメント、アプリケーション、サービス、メタデータなど、ユーザが Web サイトで使用したり見つけたりするものが含まれます。Web サイトのコンテンツの要素としては、以下のものが重要であるとされています。
所有権
誰がそのコンテンツを作成し、所有者になるのかを表します。所有権はコンテンツの著作グループにあるのか、外部の情報ベンダから使用許可を得ているコンテンツはどれだけあるのかなどです。その他の要素をどれだけコントロールできるのかは、所有権の範囲によって大きく異なります。
フォーマット
Web サイトにおけるドキュメントやデータベース、アプリケーションにおけるフォーマットを表します。例えば、製品カタログ、アーカイブ、レポート、ビデオクリップなどです。
構造
Web サイトのドキュメントは、いずれも同じように作られているとは限りません。例えば、1,000 文字程度の記事もあれば、1 万文字を超える記事もあります。構造の要素は、ドキュメントを最小単位とみなし、細かい粒度での管理、およびアクセスができるようにします。
メタデータ
Web サイト内のコンテンツを記述するメタデータもドキュメントと同様に、いずれも同じように作られているとは限りません。例えば、カテゴリの分類や、タグ付け、パフォーマンスのチューニングなど、品質としての一貫性を保つべきです。メタデータの要素は、情報検索とコンテンツの管理に関して、どの程度の段階から始めることになるのか決まる要素になります。
ボリューム
コンテンツのボリューム(量)を表します。アプリケーションや、ドキュメントの数は、どの程度ありますか。それらは、Web サイトの規模を測るための要素になります。
ダイナミズム
成長率や変化率を表します。更新頻度や、記事を追加するペースはどの程度になりますか。逆に古いコンテンツを削除する基準や、アーカイブされる基準は存在しますか。ダイナミズムの要素は、Web サイトの成長や変化を測るための要素になります。
コンテキスト
すべての Web サイトは、特定のビジネス的、あるいは組織的コンテキスト(文脈、関連性)の中に存在しています。明示の有無に関わらず、どの組織にもミッション、目標、戦略、スタッフ、プロセス、手順、基盤、予算、文化があります。そのため、それぞれの組織ごとに情報アーキテクチャも独自性が必要になります。
実際には、コンテキストの調査することから始めると良いでしょう。ビジネスやプロジェクトの実現を無視することはユーザを無視することと、同じくらい危険です。例えば、使いやすい UI であったとしても、ビジネス上の目標を支えていないのであれば、そのサイトは長くは持たないでしょう。
コンテキストの典型的な失敗例としては、空気を読む文化や阿吽の呼吸などによるコミュニケーションの失敗です。多少の矛盾が含まれていても暗黙知として解消することができる思考スタイルでは、ユーザに提供するコンテンツも見当違いのものになるでしょう。
情報の分類
情報の分類方法は様々な方法があり、考え方の違いによっても大きく異なります。例えば、他人の PC を操作した経験がある人は、アクセスしたい目的のファイルがどこに分類されているのか迷子になったことはないでしょうか。情報を分類して整理するということは簡単そうに見えて、実は非常に難しい問題なのです。
例えば、多くの情報を所蔵している図書館では、どの図書館でも情報がある程度決められたルールで整理されています。そのため、初めて訪れた図書館でも読みたい本がどの棚に置かれているのか、それほど迷わずに到達できます。
Web サイトで情報を分類するときもこれと同じ問題に直面します。ただし、情報の分類方法はひとつではないため、Web サイトの特性に合わせた分類方法を選択しなければユーザは混乱するでしょう。分類方法には正確に情報を分類するパターンと曖昧に情報を分類するパターンの 2 種類があります。それぞれのパターンはどのようなものか順番に見ていきましょう。
正確に情報を分類するパターン
情報が正確に分類されたパターンでは、初めて見る場合でも情報がどこに分類されているか簡単に理解できるパターンになっています。例えば、国語辞典や電話帳などの "あいうえお順" になっているパターンなどが該当します。これは 既知項目検索 (Known-item search) と呼ばれ、何が必要か分かっており、それを言葉で表現でき、どこから探し始めればよいか明らかである場合に有効です。情報を正確に分類するパターンでは、情報を分類するための曖昧さはなく、設計や保守も比較的簡単になります。
アルファベット順
英語圏では "アルファベット順" のみですが、日本語圏では "あいうえお順" と "アルファベット順" の両方が使われます。そのため、しばしば一般的に使われている英語の用語を探すときは、カタカナの項目を探せば良いのか、アルファベットの項目を探せば良いのか迷う場合があるため、厳密な意味での曖昧さを排除しきれませんが、アルファベット順は正確に情報を分類するパターンに属します。
時系列順
プレスリリースのニュースなどでは時系列順でまとめられており、最新の情報が上位に掲載されるようになっています。その他にも、歴史の本、日記、TV の番組表、雑誌のバックナンバーなどは、時系列順での分類が適している情報であると言えます。
曖昧に情報を分類するパターン
アメリカの図書館学者メルヴィル・デューイが 1873 年に創案した "デューイ十進分類法" という以下の 000 ~ 900 まで大別する図書分類法があります。1876 年に初版が公刊され現在では以下の分類になっています。
000:コンピュータサイエンス、情報および総記
100:哲学および心理学
200:宗教
300:社会科学
400:言語
500:自然科学および数学
600:技術
700:芸術
800:文学および修辞学
900:歴史および地理
アメリカでは公共図書館の 95 %、大学図書館の 25 % で使用されていますが、日本では洋書に対して公共図書館で 1 %、大学図書館で 5 % に留まるため、見たことがない方もいるかもしれません。このような、曖昧に情報を分類するパターンがアメリカの図書館で広く採用されている理由は、自分が何を探しているのか探している本人すらよく分かっていない場合が多いためです。ぼんやりした情報しか手がかりがない場合、曖昧に情報を分類するパターンは正確に情報を分類するパターンに比べて便利だと感じる場合があります。
曖昧に情報を分類するパターンでは、作業が大変で内容の分類も困難ですが、正確な情報を分類するパターンよりも高い価値をユーザに提供できる場合が多いのです。曖昧な情報を分類するパターンが成功するかどうかは、分類の質と個別項目の配置にかかっており、厳密なユーザテストが必要になります。多くの場合、情勢の変化に伴って出現する新規項目の分類に対して、既存項目のメンテナンスをすることになります。では、曖昧に情報を分類するパターンには何があるのかを見ていきましょう。
トピック
情報をテーマやトピック毎に分類することはユーザに大きな価値を提供しますが、作り手側からすると非常に厄介な分類方法になります。トピック毎に分類しているサイトは多くありませんが、大半のサイトでは検索機能によりサービスを提供しています。例えば、Wikipedia などの百科事典に見られる体系では、広範囲のわたって知識に関する情報が網羅されています。
トピックによる分類を行う場合、範囲を広く定義することが重要です。ユーザがサイト内検索によって期待するコンテンツを見つけられるように全体を設計するようにしましょう。
タスク
タスクの分類方法では、コンテンツやアプリケーションをプロセス、機能、またはタスクの集合にまとめることができます。この分類方法は、ユーザが実行しようとしている優先度の高いタスクが少数しかない場合に適しています。例えば、Office の Word、Excel などのリボン形式にまとめられたタスクなどが一般的な例です。
Web サイトでのタスク指向の分類は、ユーザがいくつかの操作を行う Amazon などの電子取引サイトなどで見られます。電子取引サイト以外でも Web サービス、またはアプリケーションなどでもタスク指向の分類方法が適しています。
ユーザ
Web サイトに訪問するユーザ層が複数存在する場合や、多くのリピーターが利用する場合は、ユーザ層別の体系が適している場合があります。例えば、Amazon ではユーザの購入履歴や、商品の特性からオススメの商品などの情報が自動的に表示されます。その他にもユーザ別の情報を表示する事例は、Youtube や Google のパーソナルサーチなど多岐に渡ります。
ただし、ユーザ別の分類は、オープン形式である場合とクローズド形式の 2 種類あります。オープン形式の場合は、ユーザが自分を対象にしたコンテンツ以外に、他のユーザを対象にしたコンテンツにもアクセスできます。一方、クローズド形式では他のユーザを対象にしたコンテンツにはアクセスできません。オープン形式の場合は、重要な情報が含まれる場合があるため、公開範囲の設定やセキュリティに関する問題があります。そのため、どちらの形式を選択するかは、サイトの特性によって選択すると良いでしょう。
メタファー
メタファーとは、新しいものを親しみやすいものに関連付けることです。これはユーザビリティを向上させるために、多くはユーザの理解を助けるために使われる手法です。例えば、デスクトップにコンピュータ、フォルダ、ゴミ箱などがインターフェースにメタファーを適用した例になります。ユーザはこれらのメタファーのおかげで、機能を直感的に理解できます。
メタファーでは、多くの人が直感的に理解しているものに関連付けることが求められます。関連付けられたものが何であるか知らないユーザにとって、そのようなメタファーは役に立ちません。
Web の世界では、このメタファーはモバイルにおけるメニューのアイコンなどに利用されています。モバイルは画面サイズが限られているため、デスクトップほど多くの情報を表示できません。そのため、メニューなどを文字ではなくメタファーを用いたアイコンなどで表現しています。
ラベリング
ラベリングとは、Web サイト上の情報に、タグ と呼ばれるラベルを付け、検索できるようにする分類方法です。ラベリングは、一般的にタグ付けを行うこと自体を指しますが、個人の Web サイトであれば管理者がラベリングを行いユーザは変更できません。これに対して、ユーザが情報に対して自由にタグを付けて分類することは フォークソノミー (folksonomy) と呼ばれ区別されます。フォークソノミーを導入しているサイトとしては、Flickr、はてなブックマーク、ニコニコ動画、pixivなどがあります。
ラベルの目的は情報を効果的に伝えることです。ただし、ラベルは多ければ良いというものではありません。不適切なラベリングは、ユーザに混乱を与えるだけです。フォークソノミーが発達しているサイトでは、ユーザ自身が考えた言葉による分類がなされ、情報へのアクセスがしやすいものになっているため、参考になるでしょう。
ラベルの設計は単純のように見えて非常に難関です。言語自体が曖昧であるため、言葉のゆらぎ (多義性) を排除できず、類義語、同音異義語の考慮も必要になり、コンテキストが異なれば使う言葉も異なるためです。
ラベリングにおけるガイドラインとしては、「最小単位」と「一貫性」です。ラベルの最小単位では、テーマの範囲を小さくすれば、より明確かつ効果的に情報を表現するキーワードを見るけることができます。ラベルの一貫性では、キーワードの粒度、種類、総合性を考慮しましょう。
ラベリングは正解がないため、難しく考えてしまいがちですが、自動化する方法もあります。WordPress では、コンテンツを分析して最適なキーワードを自動的にタグとして付けてくれるタグクラウドのプラグインがあります。また WordPress のプラグイン以外にも同様のタグクラウドサービスもあります。
ある情報にアクセスする場合、多くのユーザは検索エンジンを利用します。検索エンジンは Web の膨大な情報の中からユーザが探している情報に最も近いページを検索結果に掲載します。このように Web 全体を横断する検索方法はトップダウンの検索方式と呼ばれるのに対して、サイト内を横断するラベリングはボトムアップの検索方式と呼ばれます。
ラベリングは、サイト内における同一のカテゴリに属する情報を分類するための強力なツールです。Amazon などでオススメの商品が表示される仕組みは協調フィルタリングと呼ばれるアルゴリズムのおかげですが、ラベリングは協調フィルタリングすら上回る利便性をユーザに与える場合があります。ラベリングの恩恵はそれだけではありません。ブログに代表されるような雑記は情報の分類が非常に難しい場合がありますが、ラベリングを行うことでコンテンツの分類コストを大幅に下げることができます。
ファインダビリティ
ファイダビリティ (Findability) とは、情報の見つけやすさを意味します。ファインダビリティの概念は Web だけではなく、多くの情報の中から目的の情報を探し出すこと全般に通用します。Web は非常に大きな情報の集合体です。ユーザは、その多くの情報の中から目的の情報を見つけなければいけないため、ファインダビリティの概念が重要視されています。
検索とは何か?
検索は多くの情報を返してくれます。天気予報、株価、交通状況、スポーツ試合の結果などです。あまりにも多くの情報を返すため、困ったら何でも検索すれば解決するという錯覚を起こすほどです。実際、ユーザは様々な問題を解決するソリューションとして検索を使い、答えやヒントを知ろうとします。
しかし、Web を検索することが答えを知る唯一の方法ではありません。例えば、家の鍵はどこにしまったのだろう?、両親の結婚記念日はいつだっけ?、体調が悪いけど何かの病気だろうか?などです。それらの質問を投げかける相手は Web の検索機能ではありません。自分の家族、または医者に質問することで答えが得られるパターンの質問になります。ただし、それらの社会的、または社交的な質問についても Web の検索機能を使うユーザが増えてきています。
Google はトップページに "I'm feeling lucky" ボタンを設置しています。このボタンは、検索結果のトップに掲載されるページに直接アクセスするためのボタンです。しかし、実際に情報を検索する場合、様々なページをブラウジングして答えを見つけようとします。それは、売り場を歩き回ったり、棚を物色したり、TV 番組をザッピングしたり、音楽をシャッフルするように、"セレンディピティ" を呼び込む一種の運任せになっている側面もあります。ユーザが時間をかけてブラウジングするにしろ、質問を色々変えて検索するにしろ、いずれも答えを見つけるための戦術にすぎません。
ユーザがクリエイターのコンテンツにたどり着くためには、検索エンジンがどうしても必要になります。最適な検索とは、正しいキーワードで質問することです。間違った質問では、間違った検索結果しか返ってきません。まるで、"アリババと 40 人の盗賊" に登場する呪文のようです。しかし、ユーザは問題を解決するために、どのような質問が適切なのか分からない場合があります。そのため Google では、検索キーワードに関連するキーワードなどを表示して、ユーザが期待するゴールまで誘導するように手助けをしています。
検索における UX の性質としては、以下の要素があります。
利便性 (Useful)
可用性 (Usable)
望ましさ (Desirable)
ファインダビリティ (Findable)
アクセシビリティ (Accessible)
信用 (Credible)
価値 (Valuable)
検索は、利便性が高く、いつでも利用可能で、シンプルで、速く、正確であることが求められます。ユーザの抱える問題はそれほどまでに深刻で、根深く、解決が困難であり、今すぐにでも正確な答えを検索によって知りたがっています。そのため、検索における UX 特性がなければ、ユーザはその検索エンジンを使わなくなるでしょう。それでは、ユーザの検索を支援するために検索エンジンの UX における具体的な施策を次章から見ていきましょう。
オートコンプリート
オートコンプリートとは、ユーザが入力ボックスに文字を入力すると、自動的にキーワード候補が現れる仕掛けです。オートコンプリートにより、文字入力にかかる時間が短縮され、スペルの間違いなどの誤字が訂正され、ユーザに他のキーワードを気付かせるメリットがあります。
オートコンプリートは、候補を含むデータの情報源がある場合に実装できます。例えば、アプリケーションのヘルプトピックでは見出しタイトル、Google ではユーザ個人の検索履歴、Firefox では閲覧履歴とブックマークなどです。また、Google や Yahoo! ではその他のユーザの行動特性から、検索するキーワードと組み合わせて検索される頻度の多いキーワードを引き当て、サジェスト機能を提供しています。サジェスト機能は、キーワードの概念や特性を理解し、関連性の高い分野からユーザに有用であるページを探す手助けをしてくれる便利な機能です。多くの場合、サジェスト機能はオートコンプリートと合わせて提供されています。
オートコンプリートは、範囲指定検索やパーソナライズド検索とも相性がよく、サジェスト機能と同じように合わせて提供されています。例えば、範囲指定検索では都道府県から市区町村を入力する場合、上位のエリアに存在しない地名は表示されません。ユーザビリティが考慮された Web アプリケーションにおいて、住所を登録する際に見かけることができます。
インクリメンタルサーチ
インクリメンタルサーチとは、検索したいキーワードをすべて入力してから検索を実行するのではなく、文字を入力するたびに検索結果を即座に表示する仕組みです。日本語では "逐語検索" や "逐次検索" とも呼ばれます。インクリメンタルサーチでは、検索キーワードによる絞り込みがリアルタイムで行えるため、すべてのキーワードを打ち込む必要がなく、入力誤りの対処も即座に行えることができます。そのため、この方法では検索における手順をいくつか省略できるので検索コストを下げることが期待できます。
インクリメンタルサーチは、電子辞書、アドレス帳などで多く採用されています。ただし、日本語検索では漢字・カナ変換の手順を含むため、インクリメンタルサーチの利点が大幅に減ってしまうデメリットがあります。そのため、その不便さを補うためにローマ字入力された文字を解析し、漢字・カナ変換しなくてもユーザが何をキーワードを入力しようとしているのか推測するライブラリの開発が進められています。
曖昧さ回避
曖昧さ回避とは、検索キーワードが複数の意味を持ち、ユーザがどの意味で検索しているのか判断できない場合に、通知する機能です。例えば、"スピード" と検索した場合、速度、映画、音楽グループ、トランプなど、複数の意味があり、検索エンジンには判断ができません。Wikipedia では曖昧さ回避のページが用意されていて、"スピード (映画)" のように語尾に何に対してのキーワードであるか書かれており、タイトルと内容が一意になるようにしています。また、Google では曖昧さ回避のページはありませんが、"次の検索結果を表示しています" 機能によって、曖昧さや、検索キーワードが誤っている可能性が高い場合などでも、修正後のキーワードと検索画面を提示するサービスを提供しています。
Google などの検索は、非常に高い技術が集まって実現している高次のソリューションです。そのため、一般的な Web アプリケーション見られるデータベースから単純な文字列一致のクエリで引き当てるといった検索には注意が必要です。多くの Web アプリケーションでは、単純な文字列一致による検索が行われているのが現状であり、"スピード" と "SPEED" と "すぴーど" はすべて区別されます。しかし、ユーザは Google の検索品質に慣れてしまっているため、同じ検索品質を Web アプリケーションにも求める場合があります。ユーザの期待を裏切る結果を返す場合、それがユーザの過剰な期待値であったとしてもユーザビリティに対する評価や、ユーザの満足度は低下します。
Google は、企業向けにサイト内検索サービスである "Google Site Search"[1] を有料で提供しています。Google Site Search は Google の技術を利用したサイト内検索サービスであるため、ユーザの期待する検索結果に応えることができます。また、同様の機能を無料で利用できる "Google カスタム検索エンジン" のサービスもありますが、Google のロゴや検索に連動した広告が表示されます。そのため、企業サイトでは Google カスタム検索エンジンはあまり利用されていません。しかし、単純な文字列一致のクエリをやめて、独自で Google と同程度の検索サービスを用意する場合、大きなコストがかかります。特に日本語は英語に比べて文法の解析が非常に困難であるため、ユーザの意図したキーワードを汲み取ることは難しいでしょう。
スコアリング
検索結果画面における表示順は非常に重要な意味を持ちます。以下のグラフは、3 つのリサーチ会社が検索順位とユーザのクリック率を調査した結果です。どの調査結果も同じような結果を示しています。つまり、ほとんどのユーザは検索結果の上位にしか興味を示しません。また、ページネーションも考慮するならば、検索結果の 2 ページ目以降まで注目するユーザはごくわずかになります。

多くのユーザは検索結果の上位数件のページに目的の情報がなかった場合、それ以降のページを訪問することよりも、検索キーワードを変えて再検索を行います。そのため、検索エンジンにおける最優先事項は検索のスコアリングであり、そのランキングアルゴリズムが検索エンジンの品質を左右します。クリエイター側もその特性を充分に理解しており、どうにかして自身のサイトが検索結果の上位にランキングされるように "検索エンジン最適化" を行っています。検索エンジン最適化については以下の記事を参照してください。
ユーザが探している情報を見つけ出すために有効な検索指標として "関連度" があります。検索キーワードがページ内に含まれているだけではなく、頻出度、近接度、順序、タグ、ドキュメントの長さ、正確性、信頼性、網羅性など、関連度を測るための要素は数多くあります。また、検索キーワードとは異なるキーワードでも、同じ意味を持つキーワードも検索範囲に含める場合、検索キーワードの変換も必要になり、適合率と再現率の望ましいバランスを保つには、適切なチューニングが必要になります。例えば、"検索エンジン最適化" と "SEO (Search Engine Optimization)" は同じ意味で使われますが、"SEO" と "瀬尾" には何の関連性もありません。このような関係性を持つキーワードは無数にあるため、関連度を正しく評価するのは難しい作業になります。
"関連度" 以外にもスコアリングの品質を上げる観点として "人気度 (ポピュラリティ)" があります。人気度の観点は、SNS のデータを利用します。例えば、あるページがツイッターや Facebook、はてなブックマークなどで多くのツイート、いいね、ブックマークなどがされている場合、それは人気のあるページであると見なす尺度になり得ます。ただし、この尺度には 2 つの問題点があります。ひとつは、多くのユーザがあるページを SNS で共有したとしても、ポジティブな反応とネガティブの反応が混ざる場合があるということです。性別、国籍、人種、宗教、地位、戦争、憲法など、賛否が分かれる議論や、挑発的、扇動的、タブーな話題、センシティブな問題に触れる場合、多くの反応があります。しかし、多くの反応があるからと言って、それが必ずしもスコアリングに良い影響を与えるとは限りません。もうひとつは、互助会などの集団によって SNS データ件数の不正に操作され、低品質なページでも人気度があるように見せかけることができてしまうことです。例えば、はてなブックマークでは、あるページを一定時間内に一定数のブックマークが得られた場合、勢いや拡散されていると判断され、エントリーに表示されます。ブックマークの数によって、新着エントリー、人気エントリー、ホットエントリーと昇格していきます。多くのユーザに認知されると、どんな低品質のページであっても、ある程度の確率で共有されます。このように、少ない人数でもエントリーに登録されてしまえば、"テコの原理" のように多くのシェアを得ることができます。人気度にはこのような問題点があるため、参考データにはなりますが決め手にはなりません。
横断検索
横断検索とは、複数のデータベースやコレクションを同時に検索するものです。例えば、Google で検索すると、Web、地図、画像、動画、ニュースなどのジャンルに対して同時に検索されるため、それぞれのジャンル毎に検索する必要がありません。コンテンツが別々の場所に格納されている場合、ユーザはどこに探しに行けばいいのか分からなくなります。横断検索は、この問題に対処する方法のひとつですが、根本的な原因はコンテンツが断片化しており、情報が整理されていないことです。そのため、情報を整理してコンテンツの断片化を解消するのも対処方法のひとつになります。
情報が整理されている場合、横断検索はファセット型ナビゲーションと非常に相性の良いものになります。横断検索のインターフェースデザイン次第ではファセット型ナビゲーションの一部となり得ます。ファセット型ナビゲーションについては次章で説明します。
ただし、横断検索には問題点があります。それは、複数のデータベースやコレクションを同時に検索するため、どうしても検索におけるレスポンスが落ちることです。データベースやコレクションの数が増えれば増える程、ユーザは何度も検索する手間が省ける代わりにパフォーマンスが低下し、ユーザビリティが相殺されるどころかマイナスになる場合もあります。例えば、ユーザが望まない、またはニーズが少ないデータベースやコレクションを常に横断検索の対象としている場合、メリットよりもデメリットの方が大きくなります。そのため、横断検索では気を付けなければならない点が 2 点あります。ユーザが求めるデータベースやコレクションを選別しなければならない点と、パフォーマンスが落ちないようにハードウェア的、ソフトウェア的にチューニングを行わなければならない点です。
ファセット型ナビゲーション
ファセット型ナビゲーションとは、メタデータを利用して検索結果の関連するカテゴリの提示や、絞り込みを行う選択肢を示すナビゲーションモデルです。ファセット型ナビゲーションは、ガイド型ナビゲーションや、ファセット型検索とも呼ばれます。例えば、Amazon などでは検索結果画面にファセット型ナビゲーションのフィールドを設けており、ユーザのクエリーに対してカテゴリの選択や絞り込みを行えるようにしています。
ユーザが「ユーザビリティ」の本について検索すると紙媒体の結果が提示されますが、電子媒体である Kindle の商品を求めていた場合、ファセット型ナビゲーションから Kindle ストアを選択するだけで再検索されます。ユーザは、いつも完全で正しい検索キーワードを打ち込むとは限りません。多くの場合は曖昧で断片的なキーワードであり、求めている情報がどこにあるのかすら理解していない場合があります。ファセット型ナビゲーションは、そんな曖昧なクエリーに対してユーザが求める情報までアクセスできるように手助けするナビゲーションだと言えます。
Amazon では多くの商品を取り扱っているため、ファセット型ナビゲーションに提示する選択肢も必然的に多くなります。しかし、Amazon のファセット型ナビゲーションでは、もっとも良く選択される 4 ~ 5 件だけを表示し、それ以外の選択肢を非表示にしています。このデザインが優れている点は、ファセット型ナビゲーションの情報量が適切に調整され、ユーザが検索結果のメインエリアに集中できるという点です。ファセット型ナビゲーションがどれほど優れたインターフェースであっても、検索結果よりも主張することは本末転倒です。
詳細検索
詳細検索とは、単純な検索よりも多くの条件を付加して検索ができる機能を指します。詳細検索は、"検索のオプション" や "高度な検索" とも呼ばれます。大規模なサイトで検索機能を提供している場合、多くは詳細検索も提供しています。
ただし多くの場合、トップページには単純な検索しか設置されず、詳細検索は隔離されたページに設置され、あまり日の目を見ることはありません。詳細検索は初心者ユーザの検索ウィザードであると考えられたり、上級者ユーザのパワーツールであると見なされたりします。このように目的も使い勝手も混乱するような検索ツールは、インターフェースとして失敗しています。
しかし、多くの問題点は抱えるものの、詳細検索は検索におけるアンチパターンではありません。詳細検索は、そのサイトが提供する検索ツールの可能性を提示してくれます。例えば Google の詳細検索では、AND 検索、OR 検索、語順、含めないキーワード、言語、地域、最終更新日、サイトまたはドメイン、検索対象の範囲、ファイル形式、ライセンスなど様々な検索オプションが可能であることを提示してくれています。
あとがき
最後までお読み頂きありがとうございました。
高評価やフォローをお待ちしております。
X や note では、ブログやデザインに関する有益な情報を発信しています。
x.com:https://x.com/murashun
この記事が気に入ったらサポートをしてみませんか?