
データからみる競輪予想印の見方その1:#機械学習 #競輪予想

#機械学習 #競輪予想
合同会社ムジンケイカクプロ、代表の通称ムジンさんです。
競輪ファンの方、もしくは大量データ好きの方、分析好きの方、こんちわ。
私は競輪ファンではありませんが、分析の対象として競輪を選んだのは、鍛えた人間の生身の戦いというのが好きだからです。
(プロレスや格闘技が好き)
いい脚してるわー
2着が当たらない理論
分析をしているうちにハマったのがここです。
予想紙面から、2着が予測できないということ。
そのままですね。
3着にくる選手というのは、1着2着に絡みそうな選手が、予測上、直感的に理解できる形で出力されてくるのですが、2着をビッタリ当てるのが難しいというところです。
元になるデータ
過去に行われた約42000レースのデータから読む傾向と題して、データを見ていこうと思います。
print(df.groupby(['開催日','レース場','何日目','レース']).count())
[42613 rows x 33 columns]元データの集積方法
Pythonによるスクレイピング
1,DBへ、各月ごとの開催情報のURLをExcelで作って格納。
2,開催情報のURLから、レースごとのURLを一覧化し、DBへInsert
3,2で作ったURLから、HTMLをローカル保存。
4,ローカル保存したHTMLから必要部分をスクレイピング
集計
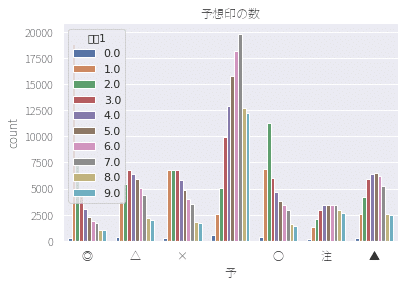
予想印に対する着順の集計です。
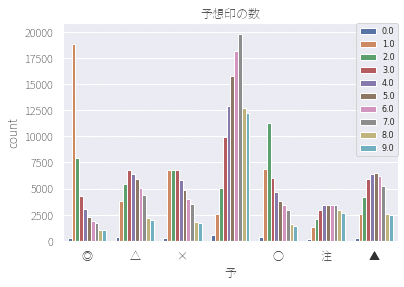
見栄えを変えました。
1.0が1着ということです。
本命対抗、1番人気と2番人気
◎が本命ということで、最も人気のある選手。
1着が多いですね。
適当に車券を買う時に、本命を買っておけばいいが・・・。
○の対抗という2番人気の選手。
やはり2着にくることが最も多いのですが、わりと他の着順にバラけています。
この数値が最も謎で、2着が当たらない理論と呼んでいます。
更に読んでいきます。
データからみる競輪予想印の見方その2:#機械学習 #競輪予想
いつもお読みいただき、ありがとうございます。 書くだけでなく読みたいので、コメント欄で記事名入れてもらうと見に行きます。