
Googleスプレッドシート SEQUENCE関数 超応用例3(1行数式で あいおうえお 50音表を生成)

2024年 最初の note です。
Googleスプレッドシートの SEQUENCE関数にフォーカスした記事の3回目となります。
全2回を予定していましたが、X上で色々アドバイスをいただいたり、関連するネタを見つけ、とても学びが多かったのでSEQUENCEシリーズ の3回目で取り上げたいと思います。
前回、SEQUENCE関数シリーズ2回目では 超応用例を幾つか紹介しました。
今回のお題(超応用例)も、以下の SEQUENCE関数 お題演習用シート(有料)に追加掲載しております。
お題用演習シートで Googleスプレッドシートの関数の勉強したい!って人は、必ずこの noteを読む前に先にお題用演習シートを入手してください。(このnote読んだらネタバレになるんで)
ちなみに 2024年1月末まで noteポイント祭 で購入額の20%がポイント還元されるようです。ちゃーんす!
今回のnoteのゴール「あいうえお50音表 生成式を作る」
今回のゴールは 1つの式で生成することは難しいと思われた、以下のような「あいうえお 50音表」を生成する式を作ることです。
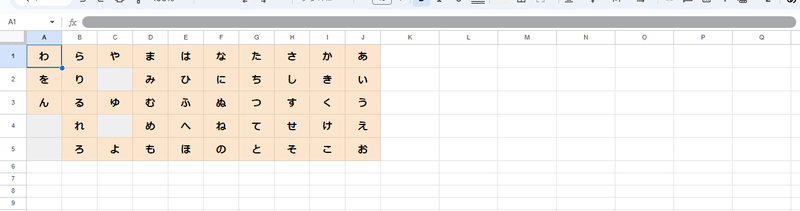
こんなん出来るん??ってなるかもしれませんが、X上で色々な案をいただき割と短い式で実現することができました!
ちなみに今回のTOP画像ですが、今回はCanvaのフリー素材に良い画像がなかったので、MIcrosoftの Copilotに

あいうえお を習字で練習する小学生の画像を生成してください
こんな依頼(雑なプロンプト)で作ってもらいました。

グローバルな小学生が 謎の言語を練習する画像が 4枚生成されたw
裏で動いてるAIは画像生成ではお馴染みの DALL-E3(だるーい ではなく、ダリと読むらしい)

とはいえ、この雑なプロンプトでも 結構イメージ通りの画像が生成されるもんだなと。2023年の1年で 生成AIがメガ進化したのを実感しますね。
もう少しやりとりすると、より精度が上がるのかもしれませんが、まぁ自分の noteで使う画像なんでこんなもんで十分でしょう。
生成AIとのやりとりは、日本人が苦手とする言語化を磨くのに良さそうです。「画像生成AI 伝言ゲーム」みたいな企画を、学校や企業の新人研修(内定者研修)でやってみると面白いかもしれません。
特殊な挙動1 SEQUENCE内でSEQUENCE
本題の前に、前回までのシリーズ中で触れられなかった、SEQUENCE関数の特殊な挙動2つを紹介しておきましょう。
どちらも、あまり使いどころがないので、実用的な知識とは言えませんが・・・。
特殊な挙動の1つ目は、SEQUENCE関数の引数にSEQUENCE関数を入れた時の挙動です。
こちらは X(旧Twitter)上で 風柳さんのポストを見て「おおー!!」ってなったんで取り上げてみました。
#エクセル のSEQUENCE関数なんだけど…これ(画像)、どういう理屈なんでしょうね…?(結果的には、第3引数で指定したSEQUENCEを第4引数のSEQUENCEで指定した数だけ繰り返している…?) pic.twitter.com/RZzmE0TH2e
— 風柳 (@furyutei) December 26, 2023
Excelでは SEQUENCE関数を入れ子にできる!?

上はExcelのSEQUENCE関数ですが、
第3引数の開始値を SEQUENCE(1,3) 横に 1,2,3
第4引数の増分量を SEQUENCE(5) 縦に1,2,3,4,5
と設定することで、なんと 横方向にに1,2,3 と展開される配列を縦方向に5回繰り返した(縦に重ねた)配列が生成されます。

第3引数、第4引数に 数値配列(SEQUENCE関数)を渡した場合は、第1引数、第2引数の数字は無視されるようです。(上の画像 左)
また、第3引数には SEQUENCEではなく 適当な 数値の配列を入れても同様に繰り返しが生成されます。(上の画像 左)
{1,4,2} ← こんな感じの数値配列でもいける
もちろん逆パターン、第3引数を縦方向に展開される配列(SEQUENCE)、第4引数を横方向に展開される配列(SEQUENCE)を指定して、縦に1,2,3と展開される配列を横に5回繰り返す、といったことも可能。(上の画像 右)
第4引数の方は 中身は重要ではなく 何行(何列)展開される配列か?だけが影響しているようです。
例:上の画像 右の式は 第4引数に SEQUENCE(1,5,2,2) を入れているので、「2,4,6,8,10」 という横に展開される配列だが、そこは重要ではなく単に横に5つの要素が展開される配列であるという点だけが 影響する。
エラーとなるケースを見ていきましょう。

当然っちゃ当然ですが、第3引数・第4引数がどちらも同じ方向に展開される配列だった場合はうまくいきません。
また、どちらかに 複数行複数列の配列を指定した場合もエラーが発生します。

この繰り返し配列を生成する為には、第1引数の行数と第3引数の配列だけでは配列の繰り返しにはならず、第4引数に配列を入れる必要があります。
そして第1引数や第2引数は無視されるといっても、受け付けられない(エラーになる マイナスの数値や文字列)を入れるとエラーとなる点、第3引数や第4引数に数値以外(文字列や文字列を含む配列)は指定できない点には注意が必要です。
つまりSEQUENCEだけでは、さすがに文字列や空白の繰り返し配列は生成できないってことですね。
Googleスプレッドシートでも SEQUENCEの入れ子は出来る!
ここまでは Excel側のSEQUENCE関数での検証でしたが、この挙動は GoogleスプレッドシートのSEQUENCE関数でも同じように発生します。

ただし Googleスプレッドシートの場合は ARRAYFORMULA関数をつけて
=ARRAYFORMULA(SEQUENCE(1,1,SEQUENCE(1,5),SEQUENCE(3)))
このようにしないと繰り返し配列が生成できません。(ちょっと式がコッテリした印象w)
また、Googleスプレッドシートの場合は第1引数、第2引数の省略ができないので、ダミーでなんらかの数値を入れてあげる必要があります。
その他の挙動、エラーになるケースは、基本的には ExcelのSEQUENCE内 SEQEUCEと一緒ですね。

第1引数、第2引数に マイナスを指定した時に Excel だと #VALUE! エラーですが、Googleスプレッドシートだと #NUM!エラー になるようです。
SEQUENCE内でのSEQUENCEの活用方法は?
SEQUENCE関数内の第3引数・第4引数に (1行または1列に展開される)SEQUECEN関数を指定すると 第3引数のSEQUENCEで返る配列を 第4引数の配列個数分繰り返すという 特殊な挙動が発生することがわかりました。
じゃあ、これが何に使えるか?
考えられるのは、繰り返し配列の生成でしょう。
以前 noteで 1~5を 横方向に3回繰り返す配列生成を様々な関数を使ってやりましたが、そこでは取り上げられなかった

=ARRAYFORMULA(TOROW(SEQUENCE(1,1,SEQUENCE(1,5),SEQUENCE(3))))
こんな方法もあったってことですね!
ただ、もっと簡単な式で対処できることを考えると、こちらは式の文字数も長いし微妙かも。。
変わった挙動なんで取り上げましたが、あんま役には立たなそうです。
特殊な挙動2 クロスSEQUENCE で上書き
もう1つ特殊な挙動を紹介しましょう。これは SEQUENCE関数の挙動というよりは、Googleスプレッドシートのスピル(セルへの配列展開)の挙動なんですが、どこかで触れたかったんで今回取り上げます。
Googleスプレッドシートでは配列を上書きできる
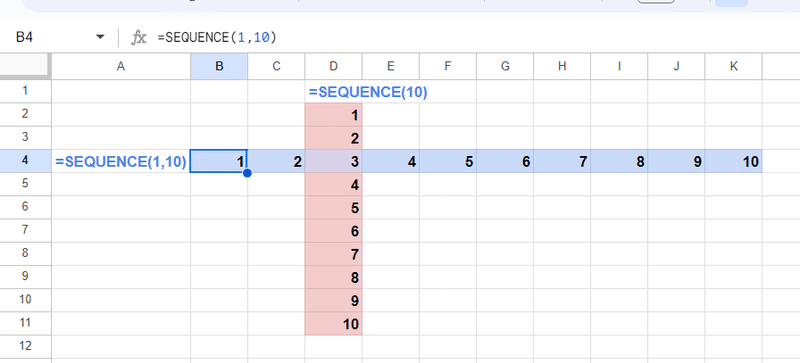
実は GoogleスプレッドシートではSEQUENCEを重ねて上のように表示させることが出来ます。
なにが凄いかわかりますか?

通常は数式で配列が展開されるセルに、余計な値が入っていたら #REF!エラーとなり、配列が展開されません。
しかし、Googleスプレッドシートの場合は 直接値や数式が入っていない、スピルで結果が表示されたセルにスピルで結果が表示されるセルが重なった場合は、なんとエラーにはならず上書きすることが出来るんです。
※Googleスプレッドシートの場合は、正しくはスピルという言い方はしませんが、わかりやすいように Excelと同じスピルという表現しています。

ちなみに 上の クロスしている箇所は 両方の式が 3 なので、問題ありませんが、
2つ以上の式のスピルが重なった場合は、表示はどのようになるか?
これは色々検証した結果、常に後から計算された方に上書きされる仕様になっていました。
つまり、再計算によってコロコロ変わってしまうってことですね。うーん、ん不安定だな。。
Excelのスピルは 重ねはNG

こっちの方が真っ当というか当然そうなるって感じですが、Excelの場合はスピル範囲にスピル範囲が重なっていた場合、 #スピル ! エラーで 結果が展開されません。
Excelの場合は スピルで結果が表示されたセルのことを ゴーストと呼びますが、Googleスプレッドシートのスピル(配列展開)とは挙動が違うってことかもしれません。

ただ、Excelのスピルの重なりも、上のようにちょっとでも隙を見せると一気に喰われて上書きされますw(あくまでも Web版 Excelでの検証で他では違う挙動の可能性があります)
Googleスプレッドシートの配列上書きもそうですが、まさに弱肉強食。いやむしろ「左ききのエレン」の名言
「グラフィティは より上手い人だけが上書きできる。」
ってセリフがしっくりくる挙動ですねw
Googleスプレッドシートの配列上書きも注意が必要

このGoogleスプレッドシートの配列の上書きを使うことで、上のような本来できない =SEQUENCE(COUNTA(D2:D)) で展開された 1~10の 途中の数値を 一つ左の列にいれた式
={"","欠席"}
で 3 や 7 が本来入る箇所に 欠席という表示を入れることができます。
SEQUENCEの結果を上書きするという、常識では考えられない手法です。
ただし「上書き」なので、

このように SEQUENCE側の再計算が走ると、今度はSEQUENCEの結果で上書きされて「欠席」表示は消えてしまういます。
非常に不安定・・・実務では使えないですね。
意外とこの上書きされたセルの値は、シート上の数式で参照しても GASのgetValue()で取得しても、見えている通りの結果となります。

では、「いっせーのせ」で同時に計算が走ったらどうなるか?

幾つか式を変えて試してみたんですが、どうも下の方のセルの計算が微妙に遅いのか、より下のセルの計算結果で上書きされました。

というわけで、どちらもまったく実用的ではない2つの特殊な挙動を紹介しました。
もし、なにか役に立つケースがあれば再度取り上げたいと思います。
SEQUENCE関数 超応用例:「あいうえお」50音表を生成する

それでは、いよいよ本題です。
ゴールは 上のような
・縦書き(右から左)で
・「や」行が1つ空きになっている
・あいうえお50音表 を
・1つの式で生成する
としています。
※「や」行 と表現していますが、日本語のような 縦書き文字の場合は縦方向が行になるらしい・・・紛らわしい!!
しかし、いきなりは難しいので段階を経てゴールを目指しましょう。
前提知識 Excelの場合はJIS関数で 半角カナ ⇒ 全角カナ ⇒ ひらがな 変換

いきなりお題に行く前に、まずは前提知識とExcelでの方法を押さえておきたいと思います。
もちろん自身のある上級者は、この辺りはすっとばして 直接ゴールを目指してもよいです。
まず、インストール版(Windows日本語版)のExcelで平仮名の「あいうえお」を生成するには、簡単に書くと
=CHAR(CODE(JIS(CHAR(ROW(A1)+176)))-256)
こんな式で 「あ」を生成してから下にオートフィルします。

ただし、最後だけ残念ながら 「ん」の前に「を」が出ません。

それを解決する式が 「を」と「ん」だけIFで分岐して処理させた
=CHAR(CODE(JIS(IF(ROW(A1)=45,”ヲ”,IF(ROW(A1)=46,”ン”,CHAR(ROW(A1)+176)))))-256)
こんな式です。
50音表作成には 半角カナをベースとする
上の式だとなぜ「を」が出てこないのか?
そもそも何をやってる式なのか?
それはCODE関数の 文字コードの仕組みに秘密があります。
ちなみに インストール版(Windows日本語版)のExcelだと CODE関数で返る数値はいわゆる JISコード値です。ユニコード値を返すGoogleスプレッドシートとは違う数値が返ります。

また、Web版ExcelやMac版Excelも違う結果となるので注意が必要です。
この、全角ひらがな、全角カタカナ、半角カタカナ、3種の「あ」の JISコード値から始まる連番を CHAR関数で 再び文字に戻すと

このようになっています。
平仮名や全角カタカナは あいうえお の並びの途中に余計な 小さい 「ぃ」、「ィ」や濁点の入った「ぎ」、「ギ」などが混じっていますが、一番右の半角カナだけは綺麗に「アイウエオ」と並んでいるのがわかりますね。
これは半角カナの ガやパといった濁音、半濁音の文字 ガやパは

このように2つの要素で構成されていること、
そして半角カナの小さい ァ や ッ は

このようにアより上に寄せられていることが理由となります。
しかし見ていただくとわかる通り なぜか 「ヲ」だけ変な場所。「ア」のはるか上 166に存在しています。
これが最初の式をオートフィルしても「を」が出てこなかった理由です。
もう1点、平仮名の「あ」とカタカナの「ア」のコード値の差に着目してみましょう。

このように JISコード値で 常に256の差があることがわかります。
つまり 平仮名の「あいうえお」を生成するには
半角カタカナをベースとする
ヲの扱いを工夫する
平仮名のコード値とカタカナのコード値のズレを活用する
この3つがキーとなるってことです。
冒頭の式
=CHAR(CODE(JIS(CHAR(ROW(A1)+176)))-256)
こちらは 中身を分解すると

こんな感じで処理しています。
ポイントは Excelでは 半角カタカナ ⇒ 全角カタカナ を JIS関数で処理できるって点です。

JIS関数で全角カタカナに変換した文字を再びCODE関数で数値にして、全角カタカナと全角ひらがなの差分である 256をマイナス。
その数値を再びCHAR関数で文字に変換することで、連続する平仮名「あいうえお」を生成しています。
Excelで 縦1列の「あ~ん」の ひらがな を生成する式
上の式を踏まえて、例外的な「を」と一つ上に「を」を入れる必要がある「ん」だけ例外処理する為にIFで分岐させた式が
=CHAR(CODE(JIS(IF(ROW(A1)=45,”ヲ”,IF(ROW(A1)=46,”ン”,CHAR(ROW(A1)+176)))))-256)
先ほどのこの式です。面白いですね。
ちなみに mir所有のExcelは2019なんですが、たまに調子いいとスピる上に SORTやSEQUENCEが使える時があります。

WRAPROWSやVSTACKは使えませんが、
=SORT(IFERROR(CHAR(CODE(JIS(CHAR(SEQUENCE(46,,176))))-256),"を"))
スピル対応のExcel(2021)なら、こんな式で縦1列の「あ~ん」を生成できます。
Googleスプレッドシートの場合の考え方
しかし、上の方法は Excelでのお話。
Googleスプレッドシートで同様のことが出来るんでしょうか?

Googleスプレッドシートの場合は、CODE関数、CHAR関数どちらもユニコードをベースとしているので、Excelとは対応する数値は違います。
しかし上の画像を見ていただくとわかりますが、
半角カタカナは余計なものがなく アイウエオ 順となっている
ただし半角カタカナの ヲ だけは ア より上に存在する
全角ひらがなと全角カタカナの並びはExcelと一緒で、コード値の差分は 96となっている
このように、コード値は違えども Excelと同じ構成になっていことがわかります。
ただし、 Googleスプレッドシートには JIS関数が存在しません。

Excelでは JIS関数を使った 半角カタカナ ⇒ 全角カタカナ の処理は、Googleスプレッドシートでは違う方法をとる必要があるってことです。
まとめるとGoogleスプレッドシートで平仮名の「あいうえお」を生成するには
半角カタカナをベースとする
ヲの扱いを工夫する
平仮名のコード値とカタカナのコード値のズレを活用する
ExcelのJIS関数の代替処理を考える
この4つがポイントとなるってことです。
ここまでが、超応用例のお題にチャレンジする上での前提となりす。
Q1. 縦1列の平仮名「あ~ん」を生成したい

それでは、超応用例 お題の1つ目です。
いきなり縦書きで折り返した表ではなく、縦1列の出力からいきます。
Googleスプレッドシートで、上のような 縦1列(画像が入りきらないので下の部分はスクショを隣に貼っています)で 「あ~ん」の46文字を生成するには、どのような式を組めば良いでしょうか?
当然式を入れるのは先頭のA2 セルのみです。画像では極限まで式を短くしているので 74文字となっていますが、幾つか方法はあるので100文字を下回る式なら十分です。
自信のある方は挑戦してみましょう!
↓↓↓
回答は以下
↓↓↓
A1. 縦1列の平仮名「あ~ん」を生成する
いきなり回答とはいかずに、解説から入ります。
ポイント1:SEQUENCEで「あ~ん」(余計なもの入り)を生成する方法
まず SEQUENCE関数を使って 余計なものが入った状態でいいので全角ひらがな、全角カタカナ、半角カタカナの「あ~ん」を どう生成するかを考えます。
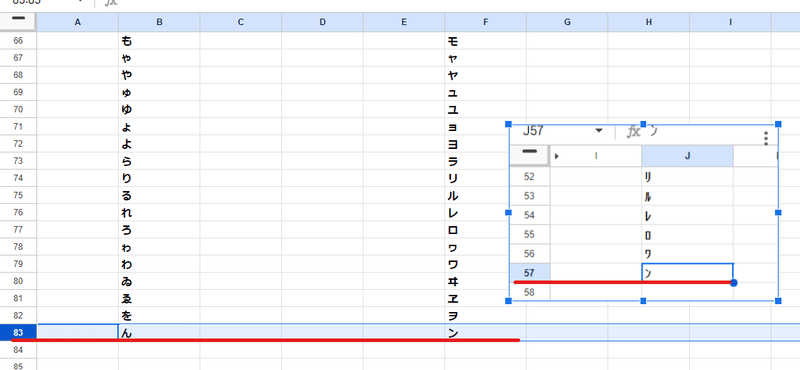
このように 全角のひらがな、カタカナの「あ~ん」までは、A2 に式を入れた場合 83行目までとなるので、全部で82文字。
半角カタカナは濁音、半濁音が無いので ヲ~ン までで、56文字となります。
これをSEQUENCE関数を使って生成すると

全角ひらがな
=ARRAYFORMULA(CHAR(SEQUENCE(82,1,CODE("あ"))))
全角カタカナ
=ARRAYFORMULA(CHAR(SEQUENCE(82,1,CODE("ア"))))
半角カタカナ
=ARRAYFORMULA(CHAR(SEQUENCE(56,1,CODE("ヲ"))))
このようになります。ここはOKですね。
次に JIS関数の代替方法ですが、ここを素直に考えると思いつくのは 全角を半角に変換するASC関数です。

この全角カタカナをASC関数で半角カタカナに変化した値と 半角カタカナの一覧を比較して、FILTER関数、UNIQUE関数で 絞りこむ方法も良いのですが、どうしても式が長く複雑になってしまいます。
そこで発想を変えて、全角カタカナをすっとばして、
半角カタカナ ⇒ 全角ひらがな
とする方法を考えてみましょう。
どういうことか?
ポイント2:Googleスプレッドシートのアバウトな一致を活用する
↑ 過去にXLOOKUPの回でも触れましたが、Googleスプレッドシートの一致は非常にアバウトな仕様となっており、

濁点等は除いて、イコールで比較した場合に 半角・全角・ひらがなか、カタカナ、小さい文字、これらは関係なしに全て一致(TRUE)という判定になります。
これを応用すると LOOKUP系で半角カタカナの「アイウエオ」を検索すると、全角ひらがなの「あいうえお」をヒットさせることが出来そうですね!

いい感じなんですが、一点「つ」が惜しいです。
これは、小さい文字 「っ」と「ツ」も一致と見なされてしまうので、普通に検索するとつ「ツ」の結果は「つ」より上にある「っ」がヒットししてしまう為です。

同様に「アイウエオ」に対しては「いうえお」より上に小さい文字が存在するので、「あぃぅぇぉ」がヒットしてしまいます。(※ぁは含んでいない)
これはどう対処すればよいか?
よく見ていただくと、常に 小さい文字は大きい文字の上に登場するという法則性があることがわかります。

これを利用して、一致する文字が複数ある場合は一番下を返すとすれば良さそう。
ここで思いつく方法がXLOOKUPの下から検索です。

XLOOKUPは 第6引数の検索モードを -1指定することで、末尾から先頭に向かって検索をかけることが出来ます。
つまり、これによって複数検索にヒットしたうちの一番下を取得できるわけです。

=ARRAYFORMULA(XLOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))), CHAR(SEQUENCE(82,1,CODE("あ"))),CHAR(SEQUENCE(82,1,CODE("あ"))),,,-1))
半角カタカナの ヲ から開始したので上の部分は変な感じですが、黄色塗りつぶし部分は綺麗にあいうおえお順になってますね。
ただし、XLOOKUPは第2引数で検索範囲、第3引数で結果範囲を指定する必要がある為、今回のように検索範囲と結果範囲が同一でも2回記述する必要があり、式が少し煩雑になっています。
もちろんLET関数で変数化する方法で回避できますが、実は今回のケースは データが昇順に並んでいるので別の方法をとることができます。
ポイント3: LOOKUP(VLOOKUP)の近似値一致を応用する

今回のような 検索対象の範囲が 昇順に並んだデータに限定されますが、範囲に検索キーに一致するデータが複数あった場合、
完全一致
=VLOOKUP(D4,A2:B16,2,FALSE)
⇒ 一致するデータの1番上を取得 ・・・ g
近似値一致
=VLOOKUP(D4,A2:B16,2,TRUE)
⇒ 一致するデータの1番下を取得 ・・・ i
VLOOKUP関数(LOOKUP関数)には、このような特性があります。
XLOOKUPの下から検索と同じではないので使う際は注意が必要ですが、今回はこのVLOOKUPの近似値一致 検索で完全一致するデータの一番下を取得する特性が使えるレアなケースといえます。
VLOOKUPの解説サイトでは「日本語データだと、昇順となっていた場合でも近似値一致は想定外のデータが返ることがあるので注意」と書いてあることも多いんですが、これは漢字を含むデータだった場合です。
基本的には「ひらがな、カタカナ」であれば近似値一致の利用は問題ありません。
さらに今回の場合は 検索列と結果列が同じ範囲なので、VLOOKUPよりもさらに記述が簡略化できる LOOKUP関数を使うことができます。
つまり
XLOOKUPだと
=ARRAYFORMULA(XLOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ"))),CHAR(SEQUENCE(82,1,CODE("あ"))),,,-1))
だったのが VLOOKUPだと
=ARRAYFORMULA(VLOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ"))),1))
さらに LOOKUPにすると
=ARRAYFORMULA(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))), CHAR(SEQUENCE(82,1,CODE("あ")))))

XLOOKUPをLOOKUPで代替して、このように短く書けるってことです。
唯一、ー(伸ばし)の箇所が#N/Aエラーとなっていますが(XLOOKUPは第4引数でエラーの際に空白処理されている)、これは後で対処するとしましょう。
だいぶ近づいてきました。
ポイント4: UNIQUE、SORT、TOCOLで成形 (回答1)

LOOKUPを使って 半角カタカナの連続データを検索キーとして、全角ひらがな を対象としてGoogleスプレッドシートのアバウトな判定で一致となったデータの一番下を引き当てることで、上のようなデータが出来ました。
あとは、
並び順を正しくしたい
重複をなくしたい
エラーを除外したい
この3つをやっつければ良いですね。
ここも素直に対処するなら
並び順を正しくしたい ⇒ SORT関数
重複をなくしたい ⇒ UNIQUE関数
エラーを除外したい ⇒ TOCOL関数(第2引数 2指定)
となります。
エラーがあると IFERRORを使いたくなりますが、今回のような1列のデータなら TOCOL関数のエラー除外を使うのがよいです。
とりあえず全部適用してみましょう。
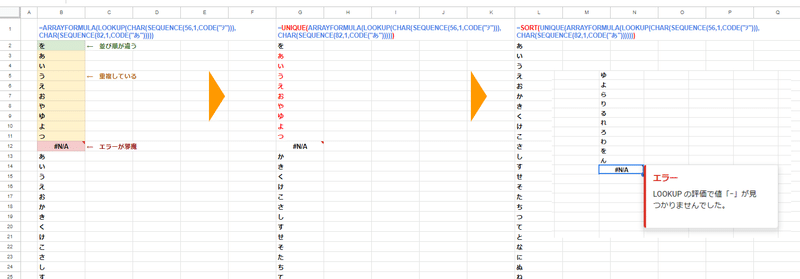
順番は特に気にしなくてよいですが、とりあえず UNIQUE関数で重複を排除して
※UNIQUE関数はまだ 当 noteでは取り上げていません。
SORT関数で並び替えを実施。

この時点で、最後の箇所も「わをん」となっており、ほぼ完成していますね。残るは最後の 邪魔な#N/Aエラーのみです。
最後に TOCOLの第2引数でエラー除外をかければ。

=TOCOL(SORT(UNIQUE(ARRAYFORMULA(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),CHAR(SEQUENCE(82,1,CODE("あ"))))))),2)
エラーが消えて完成です。
しかし、この式だとわずかに 100文字オーバー・・・
ではありません!よく見てみましょう
ARRAYFORMULAが残ってますが、配列処理はSORT関数内で行っているので ARRAYFORMULAをカットすることができます!

=TOCOL(SORT(UNIQUE(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ")))))),2)
94文字。100文字以下をクリアで完成です!!
ポイント5:SORTN関数で全てを解決する (最終回答)
さて、上の式でも十分すごいんですが、この式は
「その先 があります」
その先まで行ってみましょう。(年末年始に「左ききのエレン」を一気読みしたんで影響受けまくってますw)
この 重複を排除して、並び替えをして、一番下のエラーを除外(上から46個だけ取得)という、UNIQUE、SORT(兼Arrayformula)、TAKE(Excelオンリーの関数)の3つの関数処理を 一撃で可能とする関数が Googleスプレッドシートにはあります。
それが SORTN関数です。
SORTN(範囲, [n], [同等項目の表示モード], [並べ替え基準列1, 昇順1], ...)
SORTN関数はSORT関数の派生系ではありますが、第2引数で 出力する 行数、第3引数で同等項目(重複)があった時の挙動を指定することができます。
今回の場合は第2引数で「あ~ん」まで46文字を指定すれば、昇順で並び替えた際に一番下にくる#N/Aエラーは除外されますし、第3引数のモードを 2とすれば
2: 重複する行を削除したうえで、最初の n 行(n 行に満たない場合はすべての行)を表示します。
重複(同じ文字が2回登場するもの)を1回のみにする UNIQUE関数のような処理ができます。
さらに、SORT関数と同じく 1列データ昇順並び替えであれば、第4引数の並び替えのキーとなる列番号、第5引数の昇順・降順の指定も省略可能。
SORTNは全てを解決する・・・。

=SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ")))),46,2)
さらに 11文字短縮され、83文字の式になりました。
「あ~ん」の生成が、こんなにシンプルな式で実現でるのは驚きですね。
もちろん、CODE("ヲ") やCODE("あ") を数値化してしまえば、

=SORTN(LOOKUP(CHAR(SEQUENCE(56,1,65382)),
CHAR(SEQUENCE(82,1,12354))),46,2)
さらに75文字と短い式に出来ます。ただし、マジックナンバーだらけなんで微妙かなとw
100文字以下の式で、縦1列に平仮名の「あ~ん」を出力する式。完成です!

=SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ")))),46,2)
Q2. 縦1列の「あ~ん」を縦5ずつ折り返した「あいうえお」表にしたい

それでは、最後のチャレンジです。
先ほどの式をベースにゴールの上の表示形式にしてみましょう。
ポイントは「や」行の1つ空けですね。ここをどう対処するか?
では、自信のある方は挑戦してみましょう!
↓↓↓
回答は以下
↓↓↓
A2. 縦1列の「あ~ん」を縦5ずつ折り返した「あいうえお」表にする
いきなり ゴールの形を目指すのではなく、一旦以下のように 横に5つで折り返す配列に変換してから、上のような縦書き「あいうえお表」とするのがよいでしょう。

ポイント6:や行に空白を差し込む
これは TOCOL関数の 空白除去を使うとよいです。

Googleスプレッドシートが Excelよりいいなと感じる点の一つに、「式で空白を返すことができる」があります。
そして、TOCOL、TOROW は第2引数を 1、3で設定した時、空白は除外され詰まるのに対して、空文字は除外されないという特性があります。
これを使って「あいうえお」の1列の右に 「や」と「ゆ」の隣、つまり36番目と37番目だけ 空文字で、1~35までは空白 の1列データを用意する方法が思いつきます。
この35個の空白+2個の空文字の縦1列データを生成するには
{WRAPCOLS(,35,);"";""}
または
ARRAYFORMULA(IF(SEQUENCE(37)>35,"",))
こんな式で対応できます。
上の式の方が圧倒的に短いんですが、実は この後の処理で ARRAYFORMULAは外すことが出来ます。
ARRAYFORMULAなしだったら1文字差ですし、今回はSEQUENCE回ってことで下の式を使ってみましょう。
これを HSTACK関数で 「あいうえお」1列データと横に連結
=HSTACK(SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ")))),46,2),ARRAYFORMULA(IF(SEQUENCE(37)>35,"",)))
この時、
「あいうえお」1列データ・・・46行
生成した空白と空文字のデータ ・・・ 37行
と結合する配列のサイズが違うので、右側の不足部分 38行目から46行目までがエラーとなります。が、これは気にしなくてよいです。

この2列をTOCOLで第2引数を3として 縦1列に変換すると、 1~35までの空白と38~46までの#N/Aエラーは除外され、あ~ん と 36、37番目の空文字だけが残ります。
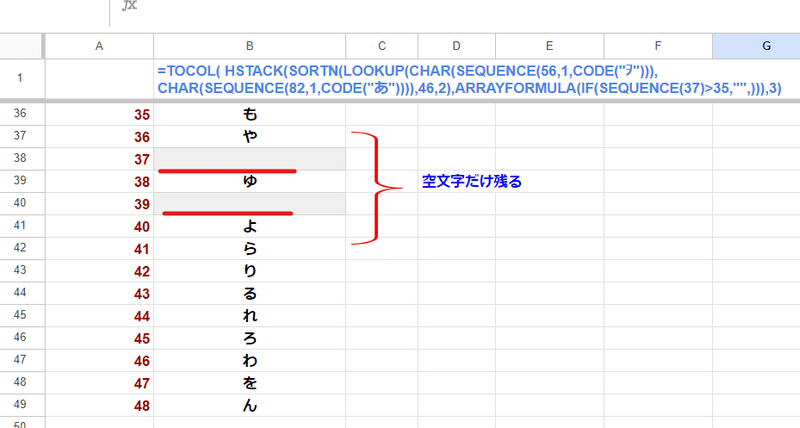
=TOCOL( HSTACK(SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),CHAR(SEQUENCE(82,1,CODE("あ")))),46,2),ARRAYFORMULA(IF(SEQUENCE(37)>35,"",))),3)
「や」の次、「ゆ」の次に1セルずつ空白を差し込むことができました。
最後に WRAPROWS関数で5つ折り返し、第3引数の埋め文字を 空白とすれば

=WRAPROWS(TOCOL( HSTACK(SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),CHAR(SEQUENCE(82,1,CODE("あ")))),46,2),ARRAYFORMULA(IF(SEQUENCE(37)>35,"",))),3),5,)
横書き5列折り返しの「あいうえお表」が完成しました。
※まだこの時点では ARRAYFORMULAは必要です。
ポイント7:折り返した行を並び替えて縦横変換

ここまでくれば、後は難しくはありません。
先ほど作った横書き「あいうえお表」を、まずはSORT関数で1番左の列をキーに降順に並び替えます。

=SORT(WRAPROWS(TOCOL( HSTACK(SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),CHAR(SEQUENCE(82,1,CODE("あ")))),46,2),IF(SEQUENCE(37)>35,"",)),3),5,),1,0)
この時、ARRAYFORMULA(IF(SEQUENCE(37)>35,"",)) の式は SORT関数内となる為、ARRAYFORMULAは不要になります。
最後にTRANSPOSE関数で縦横変換すれば

完成です。
最後に完成形を検証しましょう。
回答:「あいうえお」50音表を生成する式

=TRANSPOSE(SORT(WRAPROWS(TOCOL( HSTACK(SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ")))),46,2),IF(SEQUENCE(37)>35,"",)),3),5,),1,0))
=TRANSPOSE(SORT(
WRAPROWS(TOCOL(HSTACK(
SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),
CHAR(SEQUENCE(82,1,CODE("あ")))),46,2),
IF(SEQUENCE(37)>35,"",)
),3),5,)
,1,0))159文字とそこそこの長さにはなりましたが、ARRAYFORMULAもLETも使わずに書ける式ってのが凄いですね。
式内でSEQUENCE関数を3回利用してるってことで、SEQUENCE関数の超応用例と言って良いんじゃないでしょうかw (ちょっと無理やりですが)
とはいえ、かなりスプレッドシートの関数テクニックを駆使して生成した「あいうえお」50音表ですが、ぶっちゃけ ChatGPTなどの 生成AIに依頼すれば

さくっと作ってくれるんですよねw
実用性を考えればAIに依頼した方がよさそうです。
「あいうえお」表生成関数を 名前付き関数にしてみよう
最後に作成した関数を、名前付き関数にしておきましょう。
名前付き関数の作成
データ > 名前付き関数 > 新規作成で
=LAMBDA(a,b,LET(x,SORTN(LOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))), CHAR(SEQUENCE(82,1,CODE("あ")+96*a))),46,2),y,WRAPROWS(TOCOL( HSTACK(x,ARRAYFORMULA(IF(SEQUENCE(37)>35,"",))),3),5,),z,TRANSPOSE(SORT(y,1,0)),choose(b+1,x,y,z)))(a,b)
↑ 先ほどの式をアレンジしたこちらの式を数式の定義の欄にコピペ。

関数名を KANA(なんでもよいです)、プレースホルダ―を a, b の2つ設定します。
a,bで 出力を制御できるようにしたので、こんな感じの説明を入れておくとよいでしょう。
a ・・・ かなモード。
0(省略時)ひらがな、 1 カタカナ
b ・・・ 表示モード。
0(省略時)縦1列、 1 横折り返し、 2 縦折り返し
作成したKANA関数を使ってみよう
使ってみましょう。

このように、自由自在にひらがな、カタカナで50音表が生成できる式が完成しました~。
ひらがな50音表を生成する際には使わなかった
全角ひらがなと全角カタカナの 差分 96が、ここで使えましたね。
+96*a
で ひらがな ⇒ カタカナ の切り替えをしています。
※ a に 0か1以外の数値を入れても何も出力されません。
そして表示形式の切り替えは
choose(b+1,x,y,z)
CHOOSE関数で行っています。
このように、LET関数とCHOOSE関数を組み合わせて、出力結果を切り替えると便利です。
集合知の力と感謝
今回の SEQUENCE関数 超応用例「あいうえお50音表生成式」ですが、当社は JIS関数ないから無理そうだし、出来たとしても複雑な(きれいではない)式になりそうだしパスかなーと、あまり深堀せずスルーしていました。
しかし、X上で当 noteを見ていただいた 関数ガチ勢の皆さんから、
「こんな式で出来るのでは?」
とお知らせいただき、それらのいいとこどりをして、ブラッシュアップした式を回答としています。
mirは早々に無理そうって諦めてしまいましたが、やはり
ってのは大事ですね。
アドバイスいただいた方々に御礼申し上げるとともに、やっぱ集合知すげーなーと改めて実感。
面倒がらずにどっかコミュニティにでも所属するかなw
@mir_for_note
— 光希桃 (@mikimomo_as) December 25, 2023
=ArrayFormula(WRAPROWS(TOCOL(SORT(UNIQUE(VLOOKUP(CHAR(SEQUENCE(56,1,CODE("ヲ"))),CHAR(SEQUENCE(82,1,CODE("あ"))),1,TRUE))),3),5,""))
ということはX使わずVでもいい(ひらがなのコード順は昇順なので)っていうことですね
ーの#N/A消しにTOCOL必要でしたが pic.twitter.com/YBAEsBgnQY
=SORT(LET(
— ナカムラ (@Naka8685) December 25, 2023
半角,CHAR(SEQUENCE(56,1,CODE("ヲ"))),
全角,CHAR(SEQUENCE(82,1,CODE("あ"))),
UNIQUE(XLOOKUP(半角,全角,全角,,,-1))))
若干グレーな気もするけど... https://t.co/Fa8utBgJxU
次回(来週)は・・・、年末年始でだらけきった後の仕事で疲れそうなんで、軽めのネタにしときますw
↓ 今回のnote内でネタとして使った作品
この記事が気に入ったらサポートをしてみませんか?