
「Googleスプレッドシートから見た!」Excel 14の新関数 -3 TOROW / TOCOL

Excelに追加された 14の新関数を Googleスプレッドシートからの視点で検証する記事 3回目です。
関数の特徴
Excelでの メリット、デメリット、活用
Googleスプレッドシートの機能、関数との違い
Googleスプレッドシートでは無い機能を どう補うか
主にこの 4つの視点で検証していきます。
前回の記事
※この記事は Googleスプレッドシートに TOROW / TOCOL が輸入される前に執筆したものです。現在は Googleスプレッドシートでも TOROW / TOCOL が利用可能となっています。
EXCEL 14の新関数 TOROW / TOCOL
Excel 14の新関数 3回目は 1本満足系の TOROW、TOCOLSを取り上げます。ま、ま、満足!と草彅くんが踊りながら登場はしませんし、もちろん MS公式が この関数を 1本満足系 といった表現はしていませんw
mirが勝手にそう呼んでるだけです。
この2つの関数も 展開方向が縦か横かの違いだけなんで、2つまとめて検証していきましょう。
TOROW / TOCOLの特徴
簡単に言うと、縦横に広がってるデータ(セル範囲、配列)を縦1列、または横1行 のフラットな(1次元的な)配列 に変換する関数です。
前回検証した 折り返した形にする WRAPROWS / WRAPCOLS と逆ですね。
=TOROW(array,ignore,scan_by_column)
=TOCOL(array,ignore,scan_by_column)
array ・・・ 対象となるセル範囲、または配列データ
ignore ・・・ 無視(除外)の設定
0 そのまま (既定)、1 空白無視、2 エラー無視、3 空白とエラー両方無視
scan_by_column ・・・ スキャン(読み込む方向)
FALSE(既定) 横(行単位)、TRUE 縦方向(列単位)
TOROW、TOCOL どちらも引数は一緒ですね。
ignore(イグノア)は、無視する・スルーする って意味の英語です。この引数で、そのまま出力するか、空白、エラーを除外するかを設定できます。
Excelオンラインで関数の動きをみてみましょう。
A-Zを 横4つで折り返すサンプルデータを用意しました。A1:D7のサンプルデータ範囲には、適当に 空欄 や幾つかのタイプのエラーを入れてます。
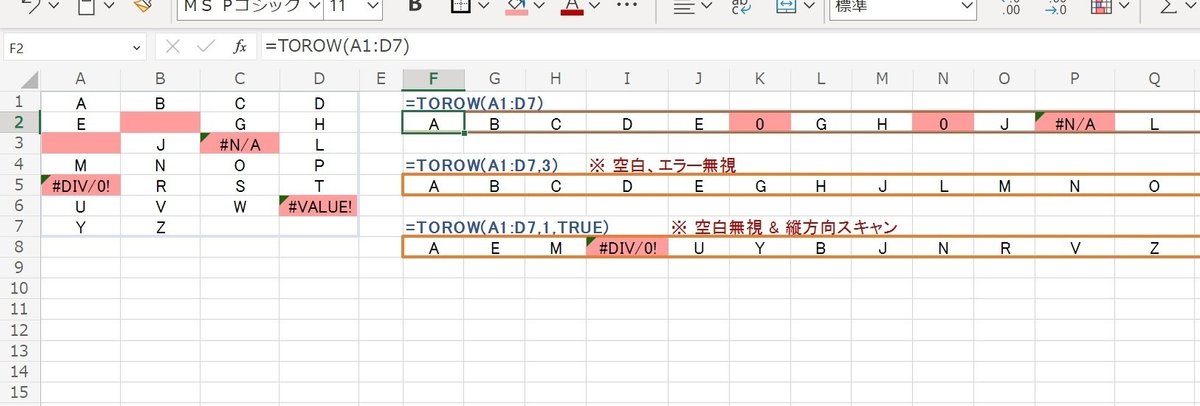
まず TOROWですが、結果は 横1行に展開されています。
元データのスキャン(読み込み)は 左から右 の横方向で 端までいったら下の行に折り返すという動きになっています。
範囲以外の引数を省略した場合は、空白(Excelなので 0として表示)やエラーが残った状態になります。
第2引数を3とすると 空白とエラーが除外されているのがわかりますね。
さらに第3引数を TRUEにすることで、スキャン(読み込む方向)が 上から下の縦方向となり、下までいったら次の右の列 という動きになっています。
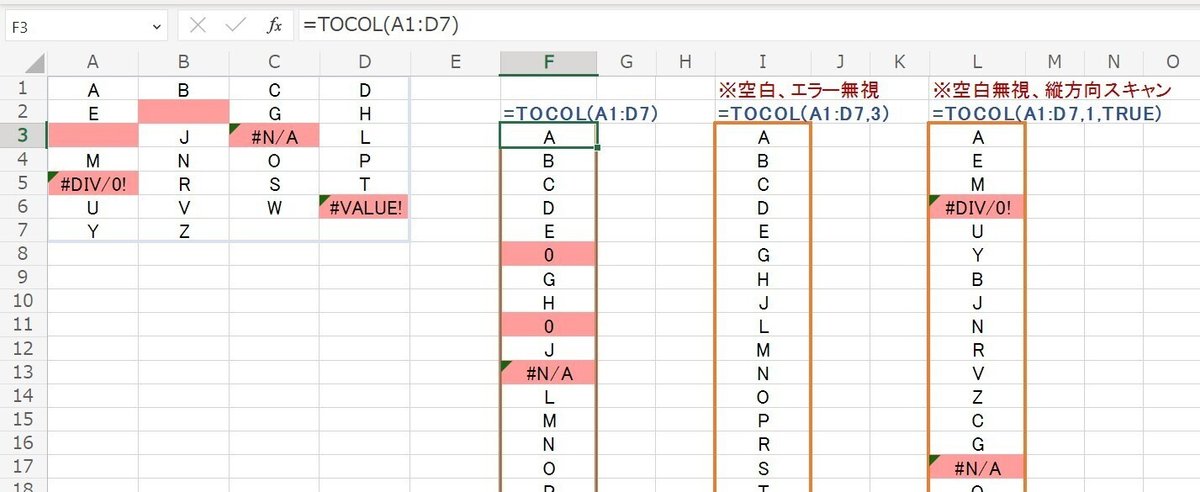
TOCOLの場合は、結果データは 縦1列に展開されます。それ以外の引数設定による挙動は、TOROWと一緒ですね。
最初に言った通り、横と縦どっちに展開されるかだけの違いです。
うーん、毎回思いますが これTRANSPOSEをかませれば よくね?
※ EXCELにも TRANSPOSE関数はあります
TOROW、TOCOLの詳しい解説は おなじみ オフィスタナカさんを参考に
余談:EXCELとGoogleスプレッドシートは 空白の扱いが違う
ちょっと余談ですが、久しぶりにExcelを触って、数式を通すと空白が勝手に 0 になるクソ仕様を思い出しましたw
この部分は本当に Googleスプレッドシートだとストレスがないです。

■EXCELとGoogleスプレッドシートの 数式における 空白の違い
・Excelの場合
空白は数式を通して出力すると 0 表示になる
数式では空白は返せず ”” (空文字) とする必要がある
(例 IF(A1=0,"", A1) ・・・ A1が0なら空文字を返す)
""(空文字)は 厳密には空白とは違うので、ISBLANK や COUNTBLANKでは空白とみなされない ="" や <>"" では 空白と同じ扱い
・Googleスプレッドシートの場合
空白は数式を通して出力しても 空白のまま
数式で空白を返すことができる。その場合は 何も入れない
(例 IF(A1=0, , A1) ・・・ A1が0なら空白を返す)
数式で返した空白は ISBLANK や COUNTBLANKで拾える
""を使うと EXCELの空文字と同じ扱い
Excel職人時代は「こういうもんだ」って慣れちゃってましたが、Excel教団を脱退して洗脳が解けると 「もし空白なら空文字を返す」って処理は異常だったんだなと感じますw
TOROWを先に解説しましたが、表計算では縦方向に長いデータを入れることが多いので、実務では TOROW よりも TOCOLの方が 出番が多いかな。
検証を進めましょう。
Excelでの メリット、デメリット、活用
この関数のメリットは、 簡単にデータを1行、または1列に変換出来る点でしょう。同じく引数だけで 空白、エラー除去が選択できるのも便利ですね。
一方デメリット(これできたらよかったのに)は、今回もしいてあげるなら、先に述べた通り 関数を2つに分けないで 1つの関数 として 展開方向(横か縦か)は 引数で切り替えでも良かったんでは?と思います。
活用場面は、これも単体利用ではなく他の関数との組み合わせでしょうね。
例えば以下の4つは思いつきます。
1. 数式の結果が横、もしくは縦横に展開さえるものを、縦1列表示に
2. TOROW、TOCOL で1本データにしてから WRAPROWS、WRAPCOLS
3. 縦横範囲のデータの重複チェック UNIQUE
4. すでに1列のデータに対して FILTERでの空白除去替わりに使う
1は オフィスタナカさんのTOROWの解説を参照。
同じくオフィスタナカさんはWRAPROWSの解説の方で、2番のケースの活用例、 TOROW と WRAPROWS を組み合わせて 12行3列のデータを 6行6列に再構築 を紹介しています。
3番のUNIQUE と TOCOL の組み合わせは 以下のようなケースで使えます。

日付と3つの当番(空白あり)の表から、名前を重複無しで取り出したい時、そのまま B2:D10に対して UNIQUE関数を適用すると 行単位での比較となってしまいます。
TOCOL で 空白を削除しつつ 縦1列にしてから UNIQUE関数に食わせれば、縦横範囲から 重複しないユニークな値だけを抽出できるわけです。
=UNIQUE(TOCOL(B2:D10,3))
このデータを使って例えば 隣に COUNTIF の式を作って、誰が何回当番をやるか、といった情報も簡単にまとめることが出来ます。
4のFILTER代わりの空白除去・エラー除去の利用は 「いきなり答える備忘録」さんを参考に。最近アップされた記事で触れています。
他にもTOCOLを活用した記事が幾つかありますね。(TROWは見つからない)
いずれも複数の関数との組み合わせの中の一つって感じで、TOCOLは調味料的なポジションで活躍 しています。
今回の配列操作系新関数 全般に言えることですが、XLOOKUPやFILTERといった スターたちのような 主役級の関数では無いけど、作品(数式)を作る上で欠かせない、いぶし銀の名脇役(バイプレイヤー) という表現がしっくりきます。
Googleスプレッドシートの機能、関数との違い
まったく同じ挙動の関数はありませんが、Googleスプレッドシートには FLATTENという 範囲・配列を 1列に変換する関数があります。
=FLATTEN(範囲1, [範囲2, …])
※空白やエラー無視はできない
※スキャン(読み込む方向)は、横(左から右)固定
※出力は 縦1列 固定
※ 範囲1,2…と サイズの違う複数の範囲を指定可能
FLATTENは EXCELには無い関数です。
違いは 引数の部分でしょうか。スキャン方向や出力の縦横は TRANSPOSEを使えば済む話なんでいいんですが、空白除去やエラー除去が出来る点で有利な TOCOL、TOROWは、FLATTENの上位互換と言えそうです。
Googleスプレッドシートでは無い機能を どう補うか
これは、そのまま FLATTEN を応用すればよさそうですね。
動きとしては
EXCELの =TOCOL(A1:A20)
の代替は
Googleスプレッドシートの =FLATTEN(A1:A20)
これが同じものという理解でよいです。TOROWに関しては
=TRANSPOSE(FLATTEN(A1:A20))
として、TRANPSOSEで縦横を変換すればOK。
あとは 中の2つの引数、ignore、scan_by_column を 他の関数をどう組み合わせて実現するか だけです。
今回もこれをお題にしてみましょう。
Q. Googleスプレッドシートで、 TOCOL と同じ結果を返す式を作れるか?
array ・・・ 対象となるセル範囲、または配列データ
ignore ・・・ 無視(除外)の設定
0 そのまま (既定)、1 空白無視、2 エラー無視、3 空白とエラー両方無視
scan_by_column ・・・ スキャン(読み込む方向)
FALSE(既定) 横(行単位)、TRUE 縦方向(列単位)
これらの引数で出力を制御できるようにする
自力で挑戦してみる方は、以下のサンプルデータを使って作成を。(右上のコピーボタンでコピーして、そのまま スプレッドシートA1で貼り付け)
A B C D
E G H
J #N/A L
M N O P
#DIV/0! R S T
U V W #VALUE!
Y Z どうでしょう? ignore の処理がなかなか面倒かと思いますが、出来そうでしょうか?
↓↓
回答はここから。
↓↓
A. Googleスプレッドシートの 既存関数で TOCOL を再現する
いきなり答えるではなく、順を追って式を作ってみましょう。
まずは FLATTENをベースに作成します。とりあえず先に 3つの引数部分を LAMBDAっておきましょう。
=LAMBDA(array,ignore,scan,FLATTEN(array))(A1:D7,0,false)
scan_by_column はIFで判別し TRANSPOSE
第3引数の scan が TRUEなら データを読み込む方向を上から下にすればよいので、ここはFLATTENの前に(中で) IFを使って分岐させましょう。
FLATTEN(IF(scan,TRANSPOSE(array),array))
FLATTENは横方向(右から左)への読み込みなので、scan(scan_by_column)が trueなら TRANSPOSE(array)と縦横変換してから FLATTENすることで、上から下へ読み込むのと同じ動きになります。
scanが false または 省略(空欄)の場合は、そのまま arrayをFLATTENします。
この後に ignore での 絞り込み処理があるので、再度LAMBDA(ラム)ってこれを xと置きます。
=LAMBDA(array,ignore,scan,LAMBDA(x, このあとの ignoreでの絞り込み処理)(FLATTEN(IF(scan,TRANSPOSE(array),array))))(A1:D7,,)
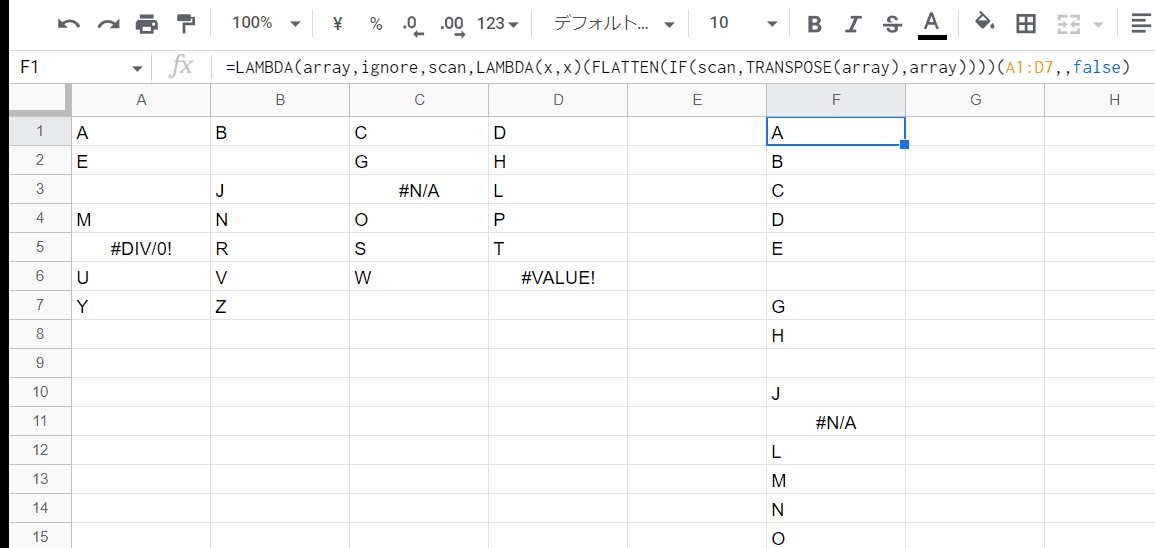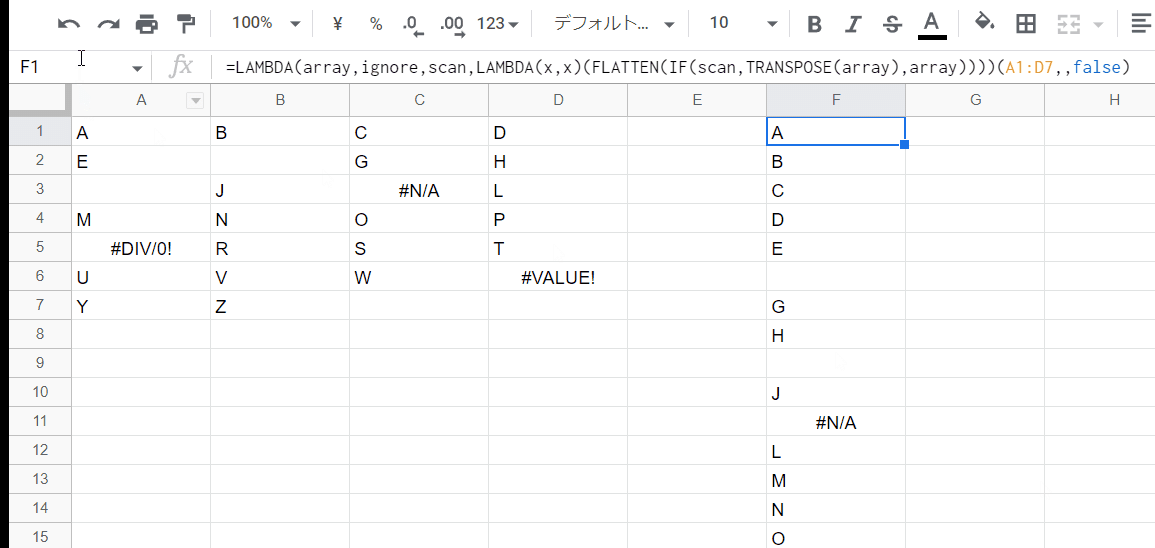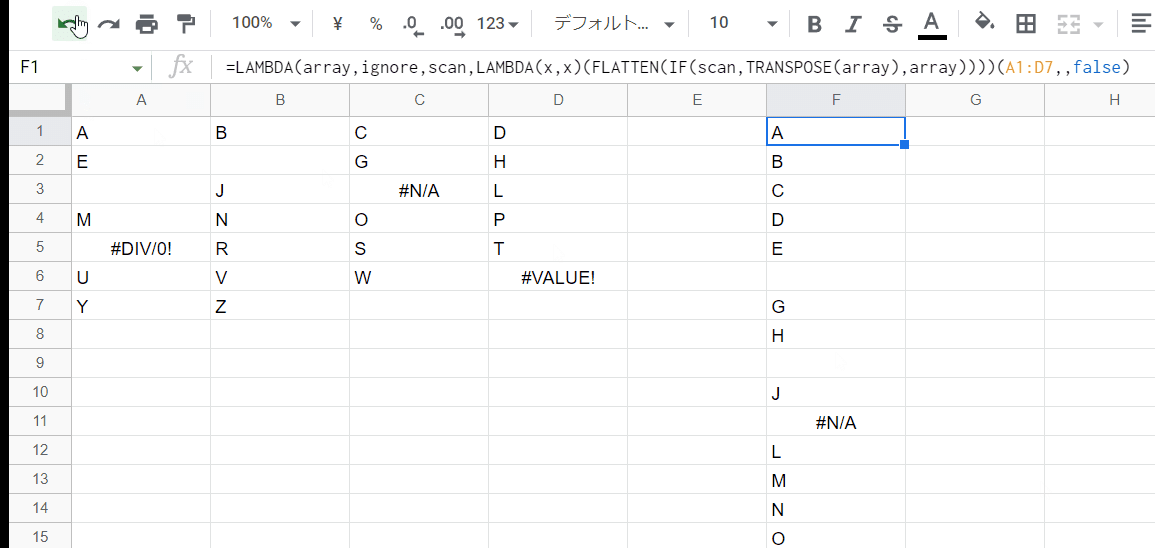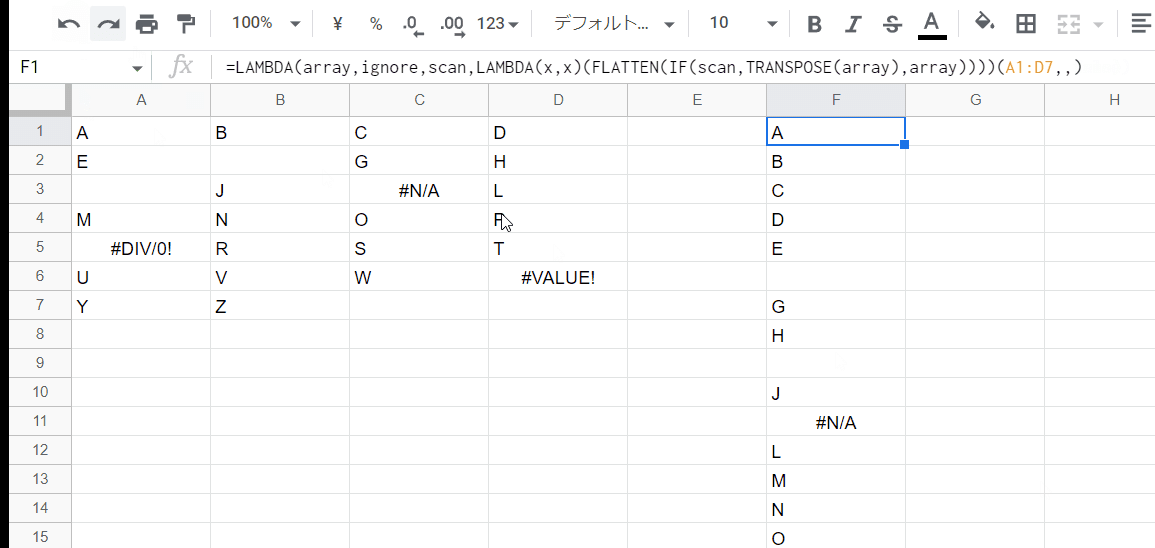
あとは、「このあとの ignoreでの絞り込み処理」 この部分の数式を作っていくだけです。
QUERY関数では エラー除外が出来ない
Googleスプレッドシートでは、FLATTENで1列にしたデータの空白除去は QUERY関数を使い以下のように記述することも多いです。
=QUERY(x,"where Col1 is not null")
これは、QUERY関数だと 条件部分の記述で 対象範囲(列)を Col1 と指定できるという利点があるためです。
ただ、今回は 空白除外だけでなく、エラーの除外も必要となっています。実は Query関数の Where句の絞り込みでは エラー除外が出来ません。
厳密には 出来なくはないんです。今回の場合は 3種類のエラー表示がありますが、それら全てに対応するように
QUERY(x,"where Col1 <>'#N/A' and Col1 <>'#VALUE!' and Col1 <>'#DIV/0!' ")
このように1つ1つ記述すれば対象のエラーを除外できます。
でも、これだと全てのエラーパターンを書き出すんかぃ!って感じで現実的じゃないですよね。
エラーかどうか?を判別する場合、通常は ISERROR関数(エラーの場合はTRUEを返す)を使います。この関数は全てのエラータイプを網羅しています。
しかし、QUERYのWhere句では、残念ながら シート関数が使えないので、ISERROR による エラー判別が出来ないのです。
ちなみにQUERY関数は特殊な仕様なので、QUERY関数を経由して出力された #N/Aや#VALUE! はエラー表示ではなく 単なる文字列扱いになってしまいます。これも注意です。
Query関数は勝手に気を利かせたデータ排除がある
もう1点、対象範囲(配列)には エラーがない、つまり 空白除去だけの場合でもQuery利用をお勧めしない理由があります。
=QUERY(FLATTEN(A1:D7),"where Col1 is not null")
例えば上記のようなQUEYR関数の式を使って空白除去する場合、対象データによっては勝手に一部のデータが削除されるリスクがあることに注意しましょう。
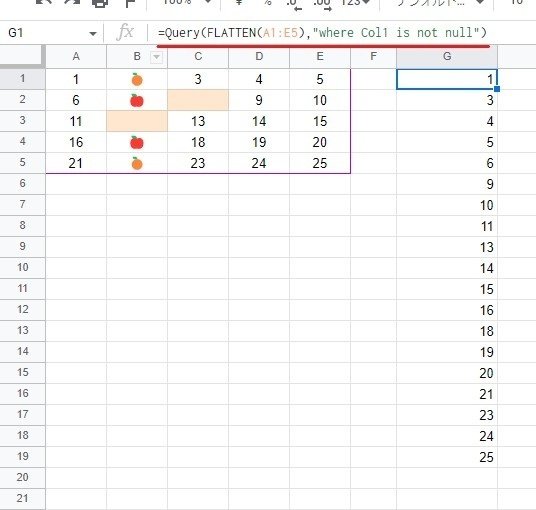
B列のデータだけ 🍎🍊 というデータが入って残りは数値という A1:E5範囲を対象に、FLATTENで1列にして QUERY関数で 空白除去したつもりが、🍎🍊 まで消されてしまっています。
これはQUERY関数の独特な仕様、 自動マイノリティー除去が作動してしまうからです。
A~E列をまとめて一つの列とした為、
列内のデータの大多数(マジョリティー)が数値である
=
この列は数値を入れる列である
とQUERY様が判断し、少しだけ混じった他の型のデータはノイズと見なされ弾かれてしまいます。
これについては、以前の記事「1行数式で作る年間カレンダー」でも触れています。
勝手に判断して
「この列のデータにふさわしくないデータだったんで、処分しておきましたよ。」
って、どんな メンヘラ彼女 か 毒親だよって感じだわですね。
スパイファミリーだったら、フィオナ(夜帷)っぽいかも?
絞り込みに関しては QUERY関数以上のFILTER関数
QUERY以外で配列を絞り込み出来る関数といえば、同じく最強クラスの関数 FILTER ですね。今回はこちらを使いましょう。
QUERY関数は確かに最強ですが、それは絞り込みだけじゃなく、グループ化、ピボット、集計、並べ替え と 複数同時魔法(処理)が使えるチートってのが大きいです。
「条件による抽出・絞り込み」に特化した利用では、専用関数である FILTER関数の方が Queryより 上です!

FILTER関数は 絞り込み条件で シート関数がフル活用できる のが強みですね。
さらにLAMBDAの登場で、繰り返し部分の記述を変数宣言で簡略化できるようになったので、今回のような対象の配列を生成する式が長いケースでも シンプルに書けるようになりました。
FILTER関数の抽出条件を理解する

=FILTER(A2:A10,{1;0;-3;"";0.02;FALSE;#N/A;TRUE;"あ"})
ちょー便利な FILTER関数は使ったことがある人も多いかと思います。
でも、いまだにVLOOKUPで 1つしか抽出されないのはどうすればよいかって質問見かけるんで、知らない人もまだまだいるのかも。。
とりあえずは FILTER関数を使える、使ったことがある人を対象に聞きますが、FILTER関数の条件による抽出ロジックってわかりますか?
なんとなく TRUEだと 抽出対象、FALSEは除外対象ってイメージで理解している方が多いんじゃないでしょうか?
上の画像と式を見てください。TRUEだけでなく、0以外のマイナスや小数も含めた数値(1,-3,0.02)は全て抽出されてますね。
しかも、わかりやすいように隣のB列に条件を出力していますが、式内の条件部分は 対象範囲のA2:A10 とは関係ない 9行1列のただの配列 です。
つまり
■Googleスプレッドシートの FILTER関数の条件の記述ルール
・条件は 対象範囲(配列)と 同じ行数の 1列の配列 であればよい
(または結果として 同じ行数の1列の配列を返す式)
・抽出対象となる条件
真偽値 TRUE 、もしくは 0以外の数値(これは TRUE扱い)
※上記以外(FALSE、0、文字列、空白 は除外対象)
→ 抽出対象結果 と同じ行の 対象範囲(配列) が返される
・複数条件 (AND,OR)での絞り込み
- AND式、OR式は 配列では使えない
- 四則演算 で TRUEは 1、FLASEは 0 と扱われることを活用する
※ 1以上も全てTRUEの扱い
- AND条件 (条件1) * (条件2) ・・・ 両方TRUEで TRUE
どちらかがFALSE 0だと 0をかけるので 全体が 0 FALSEとなる。
- OR条件 (条件1) + (条件2) ・・・ どちらか TRUEで TRUE
どちらかが TRUE 1 なら 全体としては 1以上になる
・FILTER関数の エラーあるある
- 条件配列の行数が 対象範囲の行数と 違っている
- 条件配列が 1列ではなく 複数列になっている
- 条件配列が 配列ではなく 1つの値を返している
こんな感じで理解すると良いと思います。
Googleスプレッドシートの FILTER関数と書いたのは、EXCELのFILTER関数とは挙動が違うからです。
Excelの場合は 条件の配列に 一つでも エラーや文字列がある場合は、全体がエラーになってしまいます。一方Googleスプレッドシートでは条件配列に エラーや文字列があっても、単にその位置に該当する範囲が抽出対象外と見なされるだけで 全体に影響を与えません。
ExcelのFILTER関数の方が厳しくて融通が利かないという印象です。
また、配列での複数条件絞り込みは AND、ORが使えず、かわりに * と + といった演算子を利用する
↑この点については、「いきなり答える備忘録」さんが記事を書いていますので参考に。(Excelの記事ですが、この部分は Googleスプレッドシートも一緒です)
<>"" による空白以外判定と ISBLANKの違い
ロジックが理解できたので、ignore による 分岐を組み立てていきたいところですが、空白判定の部分では注意が必要です。
FILTER(x,x<>"")
空白を除外し 空白以外を出力するのに 上記のような式を使いたいところですが、これを使うと 空白 と エラー が除外されてしまいます。
理由は xがエラーだと x<>"" もエラーとなり、条件配列が TRUEではない 為に除外対象となるからです。
では、どうするか?
TRUE か FALSE しか返さない ISBLANK 関数を使いましょう。
ISBLANK は 「空白か?」という問いに対して TRUE(はい。空白です)、FALSE(いいえ。空白ではありません) のどちらかしか返しません。
「いや~TRUEかFALSEか判定しようと思ったんですが、対象がエラーだったんで、よくわかんないんでとりあえずエラーのままにしておきました。」(あと報告もしてませんでした)みたいな、出来の悪い新人の言い訳のような返しをしないのが素晴らしいですw
条件としては 空白ではない方をTRUEとしたいので、ISBLANKの結果を NOT関数で反転させます。

並べると エラー値の時の挙動の違いがわかりますね。
ignore 1(空白無視)は これでOK、エラーの方は同じように ISERROR関数を使えば良さそうです。
これらを +(または), * (かつ) の演算子と組み合わせて、ignoreの分岐ロジックの式を作ってみましょう。
FILTER式を組み立てる
FILTER(x,(NOT(ISBLANK(x))+ISEVEN(ignore))*(NOT(ISERROR(x))+(ignore<2)))
幾つか書き方はありますが、上記がシンプルでよいかなと。
* (乗算)の左、右 がそれぞれ 空白、エラー の条件判定となっています。
■条件 ignore が 1,3 の時は 空白を除外
左① NOT(ISBLANK(x))+ISEVEN(ignore)
■条件 ignoreが 2,3 の時は エラーを除外
右② NOT(ISERROR(x))+(ignore<2)
0、空欄の時は そのまま(除外なし)
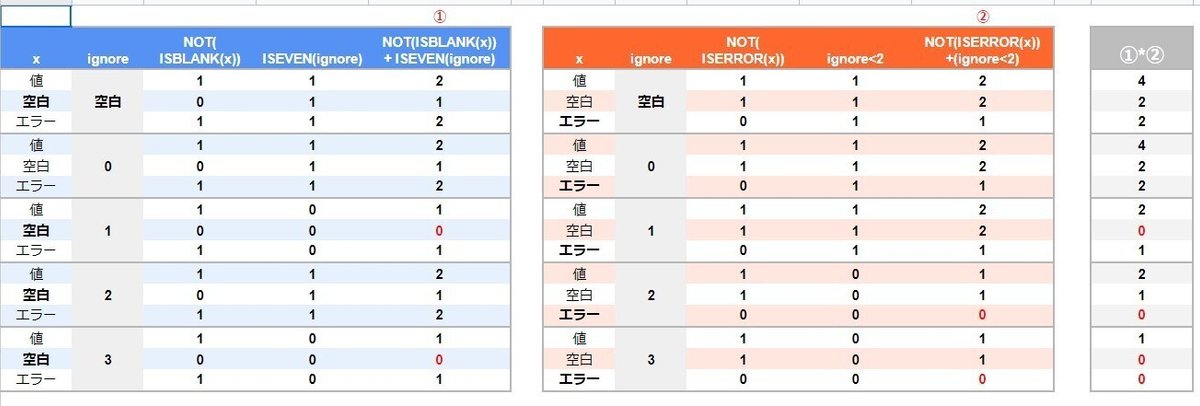
左側の式ですが、ISEVEN関数で ignoreが 偶数の時(2, 0,空欄も偶数扱い)に 1(TRUE)を返します。逆に ignore が 1,3の時は 0 (FALSE)となります。
ISEVEN(ignore) が 1の場合は①部分は NOT(ISBLANK(x))の結果 +1 となるので、 NOT(ISBLANK(x)) の結果が なんであろうと 1以上(TRUE)になります。
つまり、 ignoreが 空白、0,2の時は左側 ①の方の 空白除外の条件が有効になっていないわけです。
一方 ignore が 1,3 の時は +0なので NOT(ISBLANK(x)) の結果 1,0がそのまま 左側の結果 = 空白除去の条件が有効となります。
右も同様に ignore<2 で ignoreが 空白、0,1の時は NOT(ISERROR(x)) を無効化し、2,3の時のみ エラー除去を有効化しています。
左①と右②を掛け合わせることで、3の時は 空白除去、エラー除去 両方を有効化しています。
これによって
ignore ・・・ 無視(除外)の設定
0 そのまま (既定)、1 空白無視、2 エラー無視、3 空白とエラー両方無視
この切り替えを実現しています。
もちろん、厳密には 0,1,2,3 以外を ignore に入れた時にはエラーを返すといった分岐も入れた方がいいんですが、今回はその部分は考慮していません。
いろいろなやり方があると書きましたが、分岐処理だから IFS や Switch を使おうと思っても今回の場合は 単体の値 ignore が条件である為、そのまま記述しても エラーになります。
IFを入れ子にする方法もありますが記述が煩雑になるので、最終的に 上記のような 数的な処理で対応する形としました。
もしかしたら、上記以外のよい記述があるかもしれません。(こっちの方がいいよーという式がある方は、コメント入れてください)
TOCOL 代替式 【完成版】
上のFILTER式を 組み込んだ 完成版の TOCOL代替式が こちらです。
=LAMBDA(array,ignore,scan,LAMBDA(x,FILTER(x,(NOT(ISBLANK(x))+ISEVEN(ignore))*(NOT(ISERROR(x))+(ignore<2))))(FLATTEN(IF(scan,TRANSPOSE(array),array))))(A1:D7,0,false)
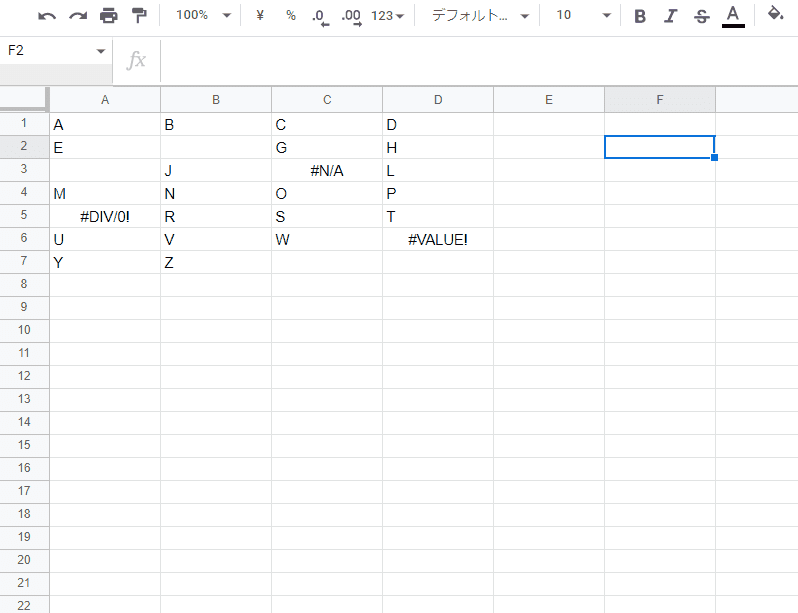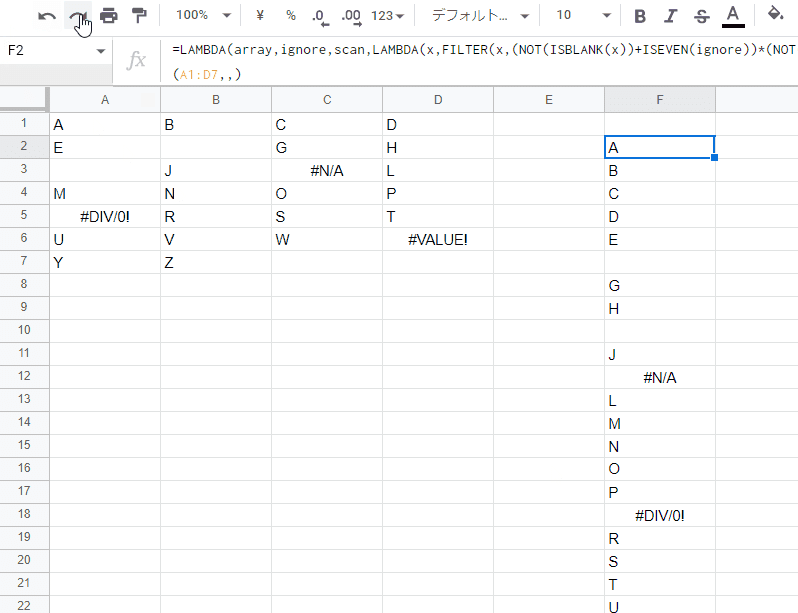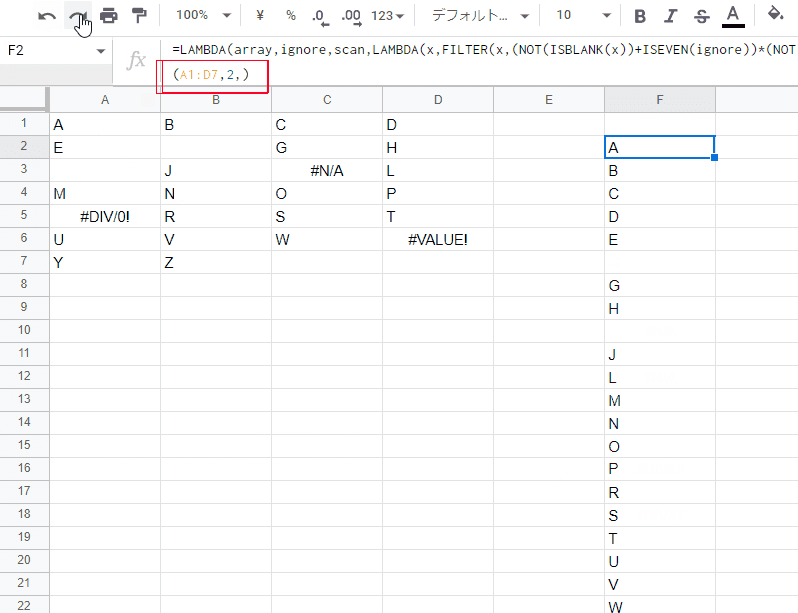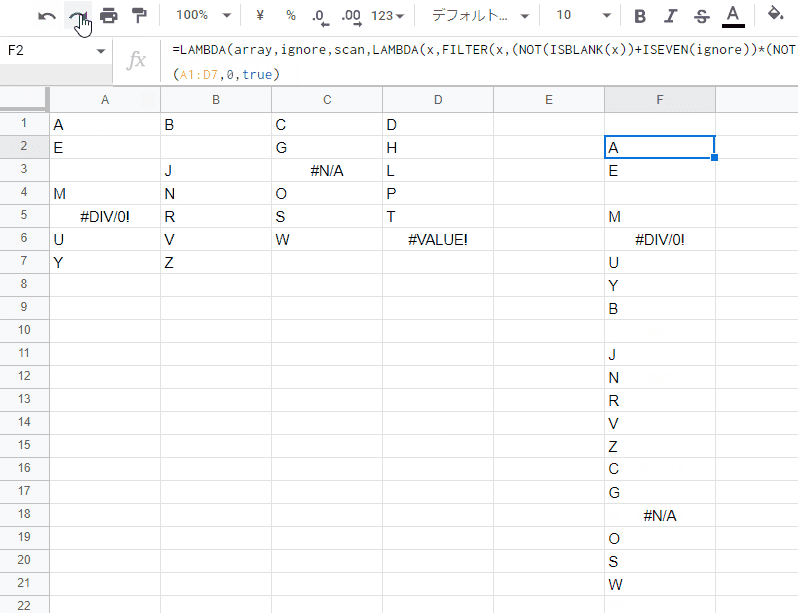
第2引数 ignore、第3引数 scan(scan_by_col)による出力切り替えも実装され、TOCOLの代替式が完成しました。
横方向への出力 TOROWは、最後にこれを TRANSPOSEすればOKですね。
リアルケースでは エラー無視は使わないかも
今回も TOCOLと同じ動きを再現する というお題ありきなんで、面倒な引数制御を実装させていますが、実際の利用シーンではここまでする必要はないでしょう。
そもそも 空白を除去してエラーを残したいなんてケースがあるのか??って思いますし、その手前段階の範囲、配列でエラーを出力させないようにすべきです。
WRAPROWSの時と同じように、通常使う分にはもっとシンプルな以下のような式を使いわければ十分でしょう。
■空白のみ除外 (ignore=1と同じ)=FILTER(FLATTEN(A1:D7),NOT(ISBLANK(FLATTEN(A1:D7)))
■エラーのみ除外 (ignore=2と同じ)
=FILTER(FLATTEN(A1:D7),NOT(ISERROR(FLATTEN(A1:D7)))
■空白、エラーどちらも除外 (ignore=3と同じ)
=FILTER(FLATTEN(A1:D7),FLATTEN(A1:D7)<>"")
TOROW / TOCOL Googleスプレッドシート代替式 まとめ
まとめです。
TOCOL の代替式
=LAMBDA(array,ignore,scan,LAMBDA(x,FILTER(x,(NOT(ISBLANK(x))+ISEVEN(ignore))*(NOT(ISERROR(x))+(ignore<2))))(FLATTEN(IF(scan,TRANSPOSE(array),array))))(A1:D7,0,false)
TOROW の代替式
=LAMBDA(array,ignore,scan,LAMBDA(x,TRANSPOSE(FILTER(x,(NOT(ISBLANK(x))+ISEVEN(ignore))*(NOT(ISERROR(x))+(ignore<2)))))(FLATTEN(IF(scan,TRANSPOSE(array),array))))(A1:D7,0,false)
実用的な TOCOLの代替式
■空白のみ除外 (ignore=1と同じ)=FILTER(FLATTEN(A1:D7),NOT(ISBLANK(FLATTEN(A1:D7)))
■エラーのみ除外 (ignore=2と同じ)=FILTER(FLATTEN(A1:D7),NOT(ISERROR(FLATTEN(A1:D7)))
■空白、エラーどちらも除外 (ignore=3と同じ)
=FILTER(FLATTEN(A1:D7),FLATTEN(A1:D7)<>"")
類似の関数 FLATTENで1列にしてから、FILTERで空白やエラーを除去って感じですね。データによってはQueryでの空白除去もOK。対象の配列を返す式が長い場合は LAMBDAと組み合わせって感じで。
後半は QUERYとか FILTERの 解説ばっかでしたねw
今回の検証は以上となります。残りは9関数。
ちなみに今回、鎌倉殿の13人を意識したタイトルをつけたんで、この関数は こんな特性なんで まさに 義盛 と言えるでしょう。みたいな、主要キャラにたとえたりする 鎌倉殿のドラマとリンクする 検証を期待していた方いますかね?
ごめんなさい。鎌倉殿の13人は、見てません!(全然ドラマ見れない)
だから、鎌倉殿に うまくたとえるとか出来ません。
でも、流行りには乗りたかったんで、それっぽいタイトルを付けちゃったんですw
EXCEL殿の14の新関数 シリーズは まだまだ続きます!
■このシリーズの次の記事
この記事が気に入ったらサポートをしてみませんか?