
Googleスプレッドシート UNIQUE関数 超応用例 2 - COUNTUNIQUE,COUNTUNIQUEIFSも

先週に続いて、なぜか Excelとは逆で EXACT関数以上に超厳密な一致判定となる Googleスプレッドシートの UNIQUE関数を取り上げていきます。
今回は UNIQUE関数以外の ユニーク処理の方法や UNIQUE関数の派生関数である COUNTUNIQUE関数、COUNTUNIQUEIFS関数などのマニアック関数の紹介、そしてお題形式の超応用例と UNIQUE関数の世界にどっぷり浸かっていきましょう。
2回で終わるかなと思ってましたが、超応用例のお題書ききれずに1000文字オーバーしちゃったんで、次回がUNIQUE関数シリーズのラストになります!
前回は UNIQUE関数の基本、挙動、Excelとの違い、応用例などを書きました。
UNIQUE関数以外のユニーク処理方法(機能)

UNIQUE関数は 重複を排除して 一意の値(データ)にする処理に、もっとも適した関数です。
以下のような特徴があり、簡単にこれらと同じことが出来る機能や関数は他にはありません。
■UNIQUE関数の特徴
・一致の判定が非常に厳密である
(※Googleスプレッドシートの場合。
ExcelのUNIQUE関数は逆に =の一致判定よりゆるい)
・第2引数 TRUE指定で 横方向のユニーク処理も可能
・第3引数 TRUE指定で 1つしかないデータだけを抽出可能
まさに UNIQUE関数自体が、ユニーク(他にはない)と言えますw
しかし、Googleスプレッドシートには、UNIQUE関数と完全に同じではないけど 重複を排除してデータをユニークにする方法が他にもあるんで、今回はまずそれらを軽く紹介していきたいと思います。
まずは関数ではなく、機能でデータをユニークにする方法から。
重複を削除
機能としてのユニーク処理の定番が、「重複を削除」という機能です。
使い方としては、先に ユニーク処理したい列(複数列可能)を選択した状態で、メニューから
データ > データクリーンアップ > 重複を削除
と進みます。

・ユニーク処理からヘッダー行 を除外
・重複をチェック(分析)する列を指定できる
といったオプションは、UNIQUE関数には無い便利な機能です。
実際に使ってみると

このように UNIQUE関数と同じ 重複を排除した一意の結果が得られました。
「ヘッダー行が含まれている」にチェックを入れてるので、範囲内の先頭行は重複チェックの対象外となっています
重複チェックは縦方向のみで、横方向のユニーク処理は出来ません。
重複を削除の便利な点
UNIQUE関数は 第1引数の指定した範囲 を行単位で全て重複チェックしてしまい、特定の列を重複チェックから除外といったことは出来ません。

画像のサンプルデータの場合、UNIQUE関数では単価列をユニーク処理のチェック対象から除外して、フルーツと産地だけ 重複チェックをして 上に登場(1回目に登場)する行だけ残すといったことは出来ないわけです。
一方、「重複を削除」機能であれば、これが可能です。
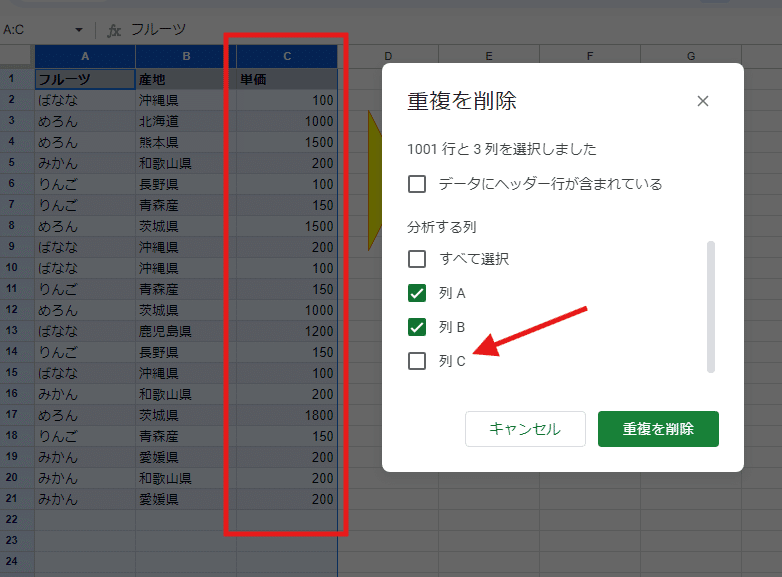
このように範囲から 列C のチェックを外すことで、
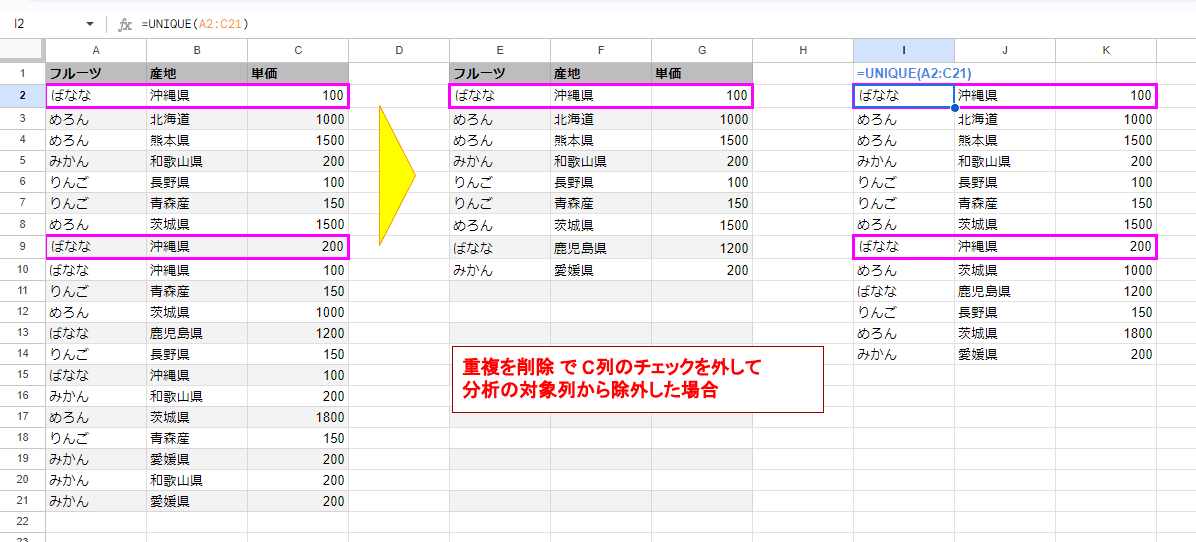
このようにフルーツと産地(A列とB列)だけを重複チェックの対象としてユニーク処理を実施し、重複があった場合は上にあるデータだけ残すといったことが可能となります。
これは状況によっては便利そうですね。
重複を削除は 大文字、小文字を同一と見なす(注意)
「重複を削除」機能は、Googleスプレッドシートの イコール一致のように 全角、半角、ひらがな、カタカナを 混同する 緩い一致判定ではありません。
これは非常にありがたいです。
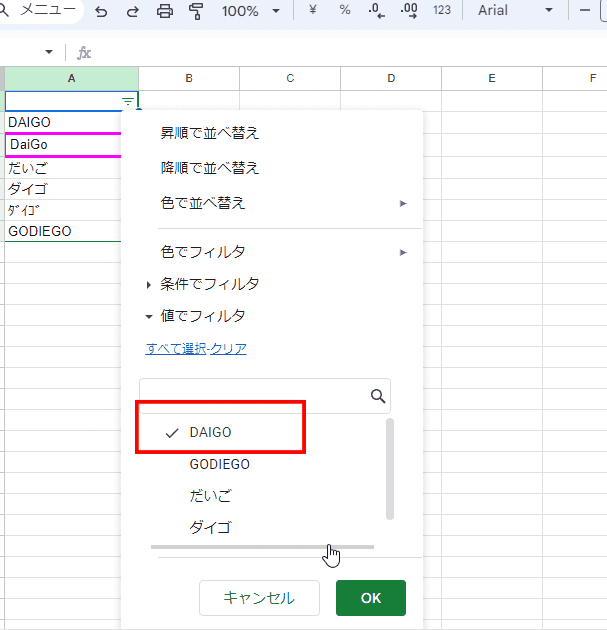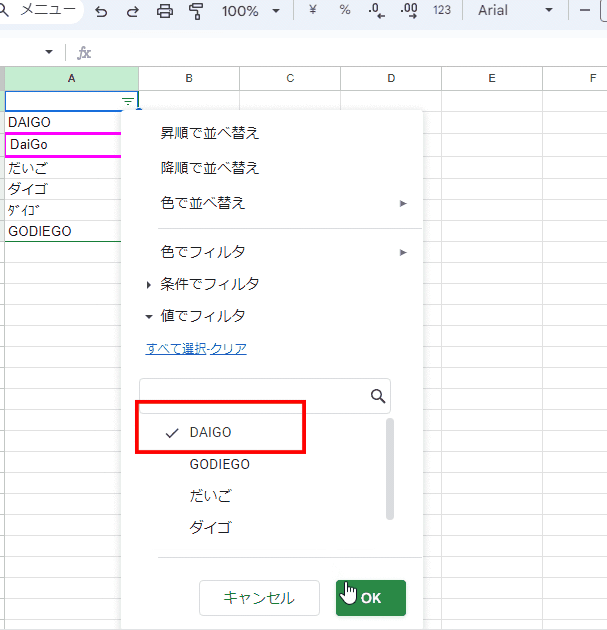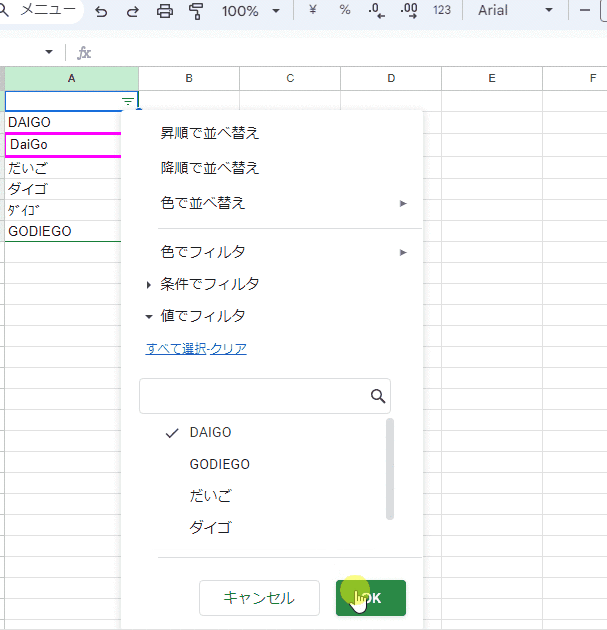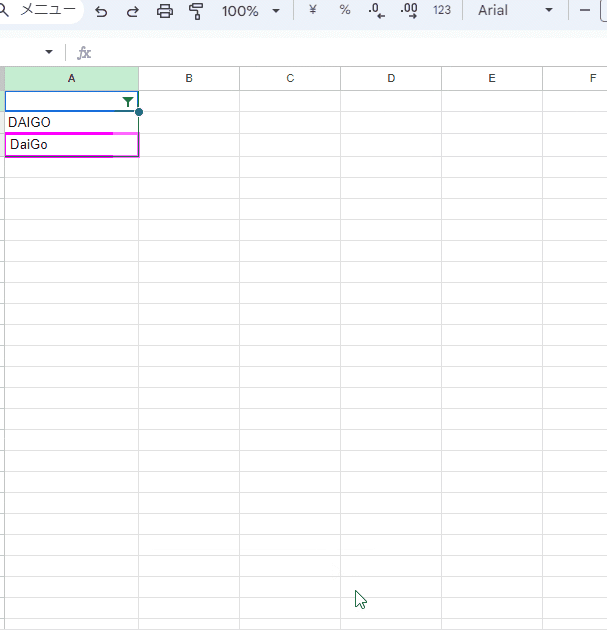
これが、「だいご」と「ダイゴ」、「ダイゴ」が重複扱いされて削除という挙動だったら、ちょっと使いどころが微妙な機能だったかも。
といっても、UNIQUE関数やEXACT関数ほどの最高レベルの厳密性ではなく、「重複を削除」はアルファベットの大文字、小文字は同一と見なす一致判定となっています。
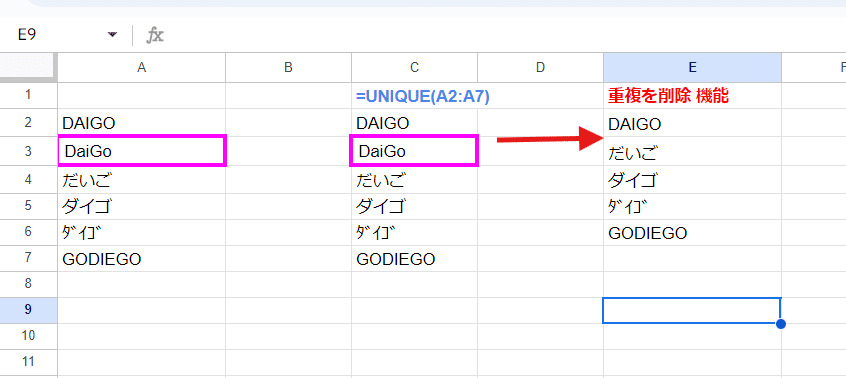
上の例は、左が元データ、真ん中が UNIQUE関数を使った結果、右が「重複を排除」機能を使った結果となっています。
「重複を排除」だと、ウィッシュの DAIGO氏と メンタリズムの DaiGo氏が 重複と見なされ、下にあった DaiGo が排除されてしまっているのがわかりますね。(問題発言のせいで 業界から排除されたという意味ではありません)
このように 大文字、小文字を区別せず重複削除されるリスクはありますが、これを理解した上で使えば非常に便利な機能です。
もちろん 関数と違って 元データを改変(削除)してしまう機能なんで、念のために コピーしたデータに対して「重複を削除」を使い、元データは残しておくことをお勧めします。
また、実行時に処理されるものなので、関数のように元データに変更・追加があった際にリアルタイムで反映されるものではありません。
その他のユニーク処理が出来る機能「フィルタ」
「重複を削除」以外にも、ユニーク処理(のようなこと)が出来る機能はあります。
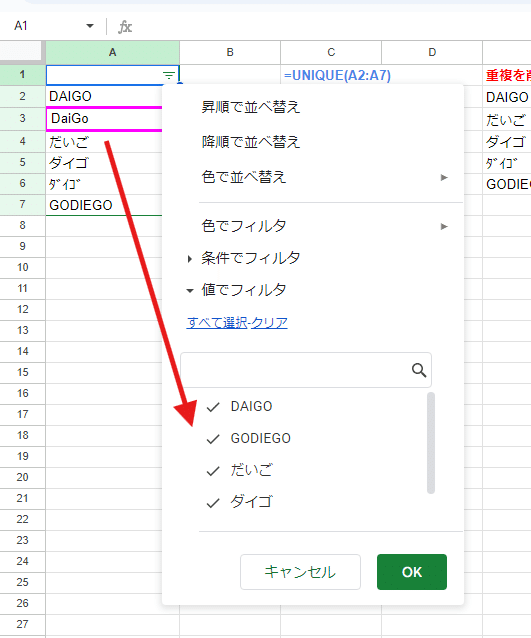
フィルタ機能(フィルタ表示)も列の値を一意にして 候補として表示してくれる点が、ユニーク処理と言えるでしょう。
もっとも対象は一列のデータに限られますし、結果が出力できるわけではありませんが。。
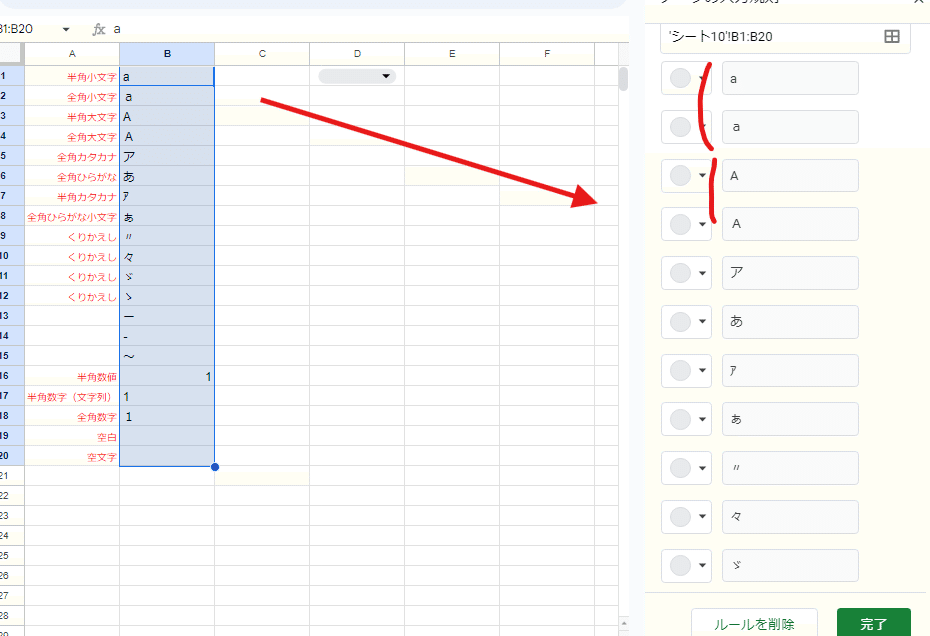
上の画像でわかりますが、「重複を排除」と同様に フィルタは大文字、小文字を同一として判定します。
なにげなく使ってるフィルタ機能ですが、裏側では大文字・小文字を区別しないユニーク処理で 選択肢が生成されてるんですね。
フィルタ以上に便利なフィルタ表示機能については 過去noteで特集していますので、よければご参照ください。
その他のユニーク処理が出来る機能「プルダウンリスト」

フィルタと同じく プルダウン(範囲内)もユニーク処理と言えるかもしれません。
Googleスプレッドシートの プルダウンリストは、セル範囲をリストとして利用する場合、自動でユニーク処理が適用されます。
もちろんリストを書き出しは出来ませんが、複数列、複数行のセル範囲を指定した場合も 一意の値にしてくれて、空白も自動で削除してくれます。

=UNIQUE(TOCOL(A:C,1))
こんな処理をしているイメージですね。
というわけで、Googleスプレッドシートのプルダウンリストは、事前にUNIQUE関数で一意の値にしておく必要はありません。
重複アリのデータ範囲をそのまま指定してOKってことです。
※ Excel(インストール版 2019以前)のプルダウンリストは 重複データのユニーク処理をしてくれません。
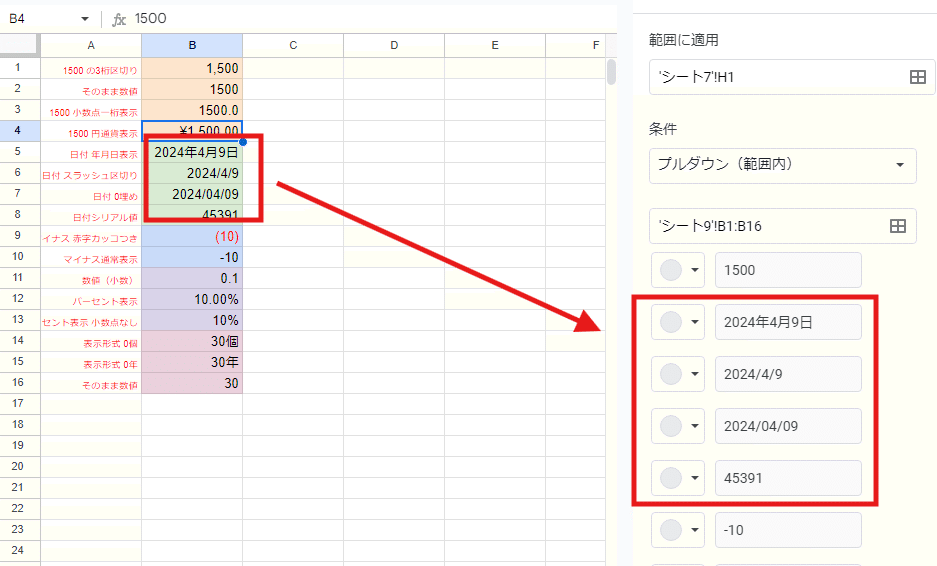
プルダウンリスト化の際の一致判定は厳密で、
大文字、小文字もしっかり判別してくれます。 EXACT関数と同等レベルかと。
ただし、日付などは表示形式で、別の値と判断する傾向があります
その他のユニーク処理が出来る機能「ピボットテーブル」、「列の統計情報」
他にも「ピボットテーブル」や「列の統計情報」という機能もユニーク処理と言えなくもないんですが、これはらまだ noteで取り上げてない機能なんで 別の機会に詳しく触れたいと思います。

軽く触れておくと、ピボットテーブルのデータのグループ化による ユニーク処理は、大文字・小文字を同一とみなします。
一方、列の統計情報という機能は、厳密な一致判定でカウントしています。
機能によるユニーク処理の中では、 「重複を削除」の 部分的なユニーク処理は使える機会がありそうです!
UNIQUE関数以外のユニーク処理方法(QUERY関数)
機能につづいて UNIQUE関数以外の 関数を使ったユニーク処理を見ていきましょう。
SORTN関数、FILTER関数+COUNTIFS関数 によるユニーク処理
前回の noteでは SORTN関数を使う方法、そして FILTER関数 + COUNTIFS関数を組み合わせた方法による ユニーク処理を紹介しました。
これらの関数を使うことで、「重複を排除」機能で実施したような、対象範囲(A2:C)のうち1列目、2列目でだけユニーク処理を行い、上に表示されているデータだけ残すといった部分的なユニーク処理が可能となります。
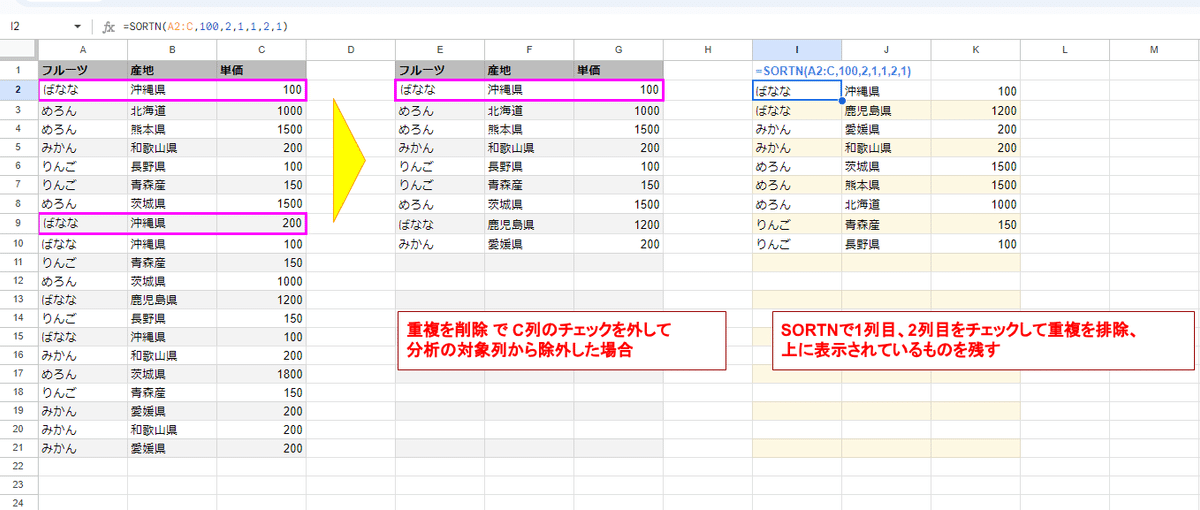
=SORTN(A2:C,100,2,1,1,2,1)
SORTN関数の場合、1列目、2列目で並び替えされてしまうので、まったく同じとはいきませんが、同じデータ(重複の場合は 上に表示されているものを残す)となっているのがわかりますね。
元データの並び順を保持しようと思えば出来ますが、非常に面倒な式になります。

=CHOOSECOLS(SORT(SORTN({SEQUENCE(ROWS(A2:C)),A2:C},100,2,2,1,3,1)),2,3,4)
並び替えをしたくない場合は、FILTER関数 + COUNTIFS関数 を使った方が簡単かもしれません。

=FILTER(A2:C,COUNTIFS(A2:A,A2:A,B2:B,B2:B,ROW(A2:A),"<="&ROW(A2:A))=1)
このように元の並びを保持した部分ユニーク処理が出来ます。
ただし、どちらも最もゆるい一致判定によるユニーク処理 なんで

データによっては 誤判定が発生し、 重複を排除や UNIQUE関数と同じ結果になりません。注意が必要です。
QUERY関数の group by を使う方法
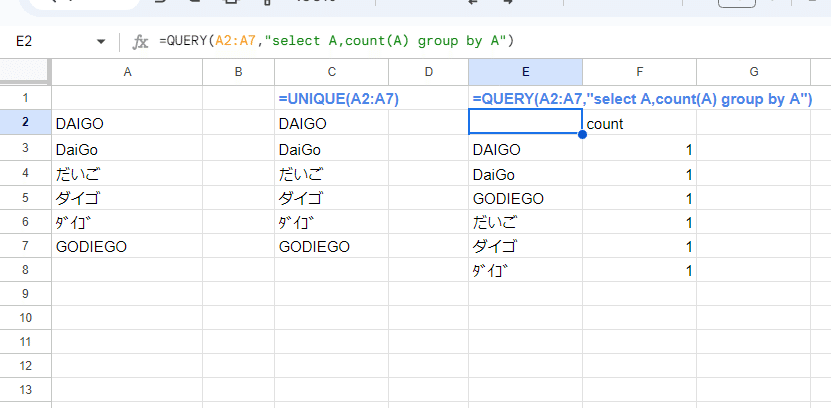
UNIQUE関数に近いレベルで厳密な一致判定をしてくれるのが QUERY関数です。
=QUERY(A2:A7,"select A,count(A) group by A")
いずれ QUERY関数も noteを書くつもりなんで、今回は ユニーク処理に絞って軽く触れるだけとしますが、たとえば group by を使った重複排除は、上の画像のように 半角、全角、ひらがな、カタカナ、大文字、小文字を区別してグループ化してくれます。
QUERY関数の一致判定は厳密で、 EXACT関数レベルである と言えるでしょう。
感覚的に ピボットテーブルと QUERY関数って 裏側では同じ処理が動いてると思ってましたが、一致の判定に違いがあるんですね。
ピボットテーブル ・・・ 大文字と小文字を区別しない判定
QUERY関数 ・・・ 大文字、小文字を区別する厳格な判定
ただし QUERY関数は group by を利用する際は必ず 集計関数とセットで使う必要がある為、どうしてもグループ毎の データの個数や合計、最大値などを一度出力せざるを得ません。

というわけで、QUERY関数の group by で ユニークにした値だけ欲しい場合は
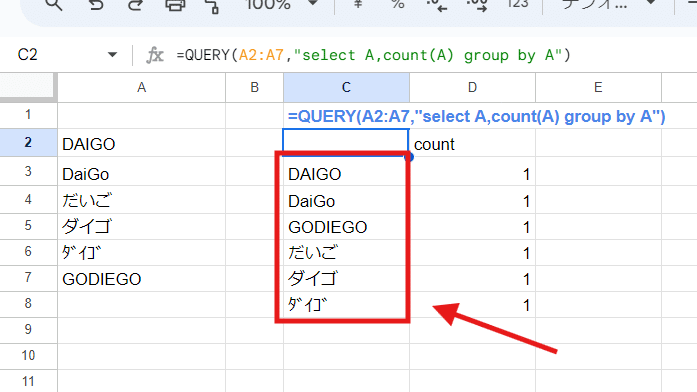
QUERY関数をもう1回使って入れ子にする必要があります。
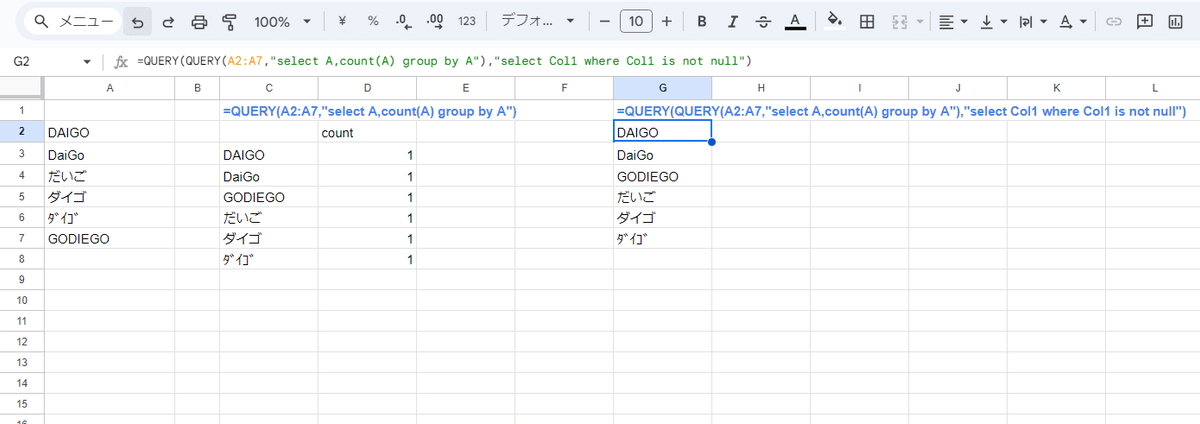
=QUERY(QUERY(A2:A7,"select A,count(A) group by A"),"select Col1 where Col1 is not null")
ちょっと手間が多いですし、group by を使うと ユニーク化(グループ化)と合わせて、並び替えもされてしまいます。
ユニーク処理だけしたいなら、普通に UNIQUE関数を使った方がいいです。
さらに QUERY関数は、 where句の = イコールによる一致判定も厳密になっています。
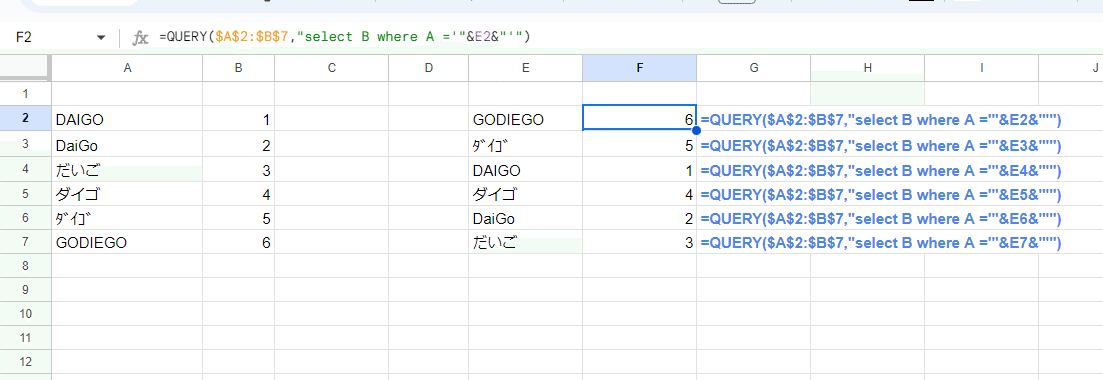
=QUERY($A$2:$B$7,"select B where A ='"&E2&"'")
FILTER関数やXLOOKUPでの一致判定の抽出が、ゆるい判定基準で困った場合はQUERY関数を使うのもアリかもしれません。
とはいえ、これらはだいぶトリッキーなQUEYR関数の利用方法であって、基本的には QUERY関数は グループ毎に集計といった時に使う関数と思っておいた方がよいでしょう。
UNIQUE関数の派生関数1 COUNTUNIQUE関数
次にUNIQUE関数の派生関数を紹介しましょう。UNIQUE関数にはスピンオフといえる関数が2つあります。
COUNTUNIQUE関数
範囲内のユニークな値の数をカウントする
COUNTUNIQUEIFS関数
範囲を条件で絞り込んだ上でユニークな値をカウントする
どちらも Excelには無い Googleスプレッドシートにのみ存在するニッチな関数ですw
それぞれ紹介していきましょう。
COUNTUNIQUE関数の基本

COUNTUNIQUE(値1, [値2, ...])
COUNTUNIQUE関数は、指定した範囲内のユニークな値をカウントする関数です。
A列(1列データ)に対して使用するなら
=COUNTA(UNIQUE(A:A))
の代わりに
=COUNTUNIQUE(A:A)
こんな感じで UNIQUEしてCOUNTAする代わりに、COUNTUNIQUEを使うことができます。
UNIQUE関数と違って値(範囲)を引数として複数とれるので
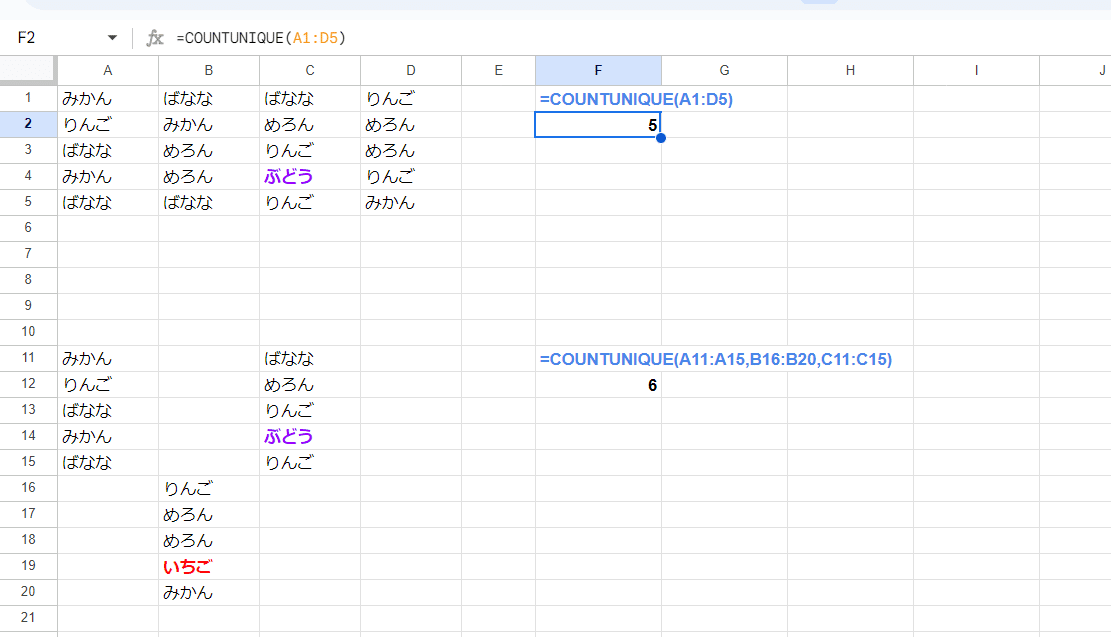
=COUNTUNIQUE(A1:D5)
複数行、複数列の範囲に含まれる一意の値の数を取得したり
=COUNTUNIQUE(A11:A15,B16:B20,C11:C15)
飛び飛びの範囲を連結することなく、ユニークな値をカウントすることが出来ます。
COUNTUNIQUE関数 特徴と注意点
特徴の1つ目は UNIQUE関数と同じ厳密な判定をしてくれる点です。
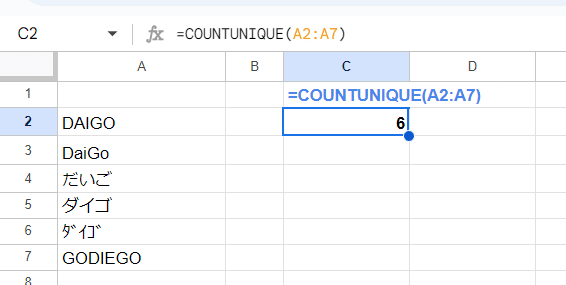
半角、全角、ひらがな、カタカナ、アルファベットの大文字、小文字を区別して一致を判定し ユニークな値が幾つあるかを厳密にカウントしてくれます。
特徴の2つ目は 空白や空文字はカウントしない点。
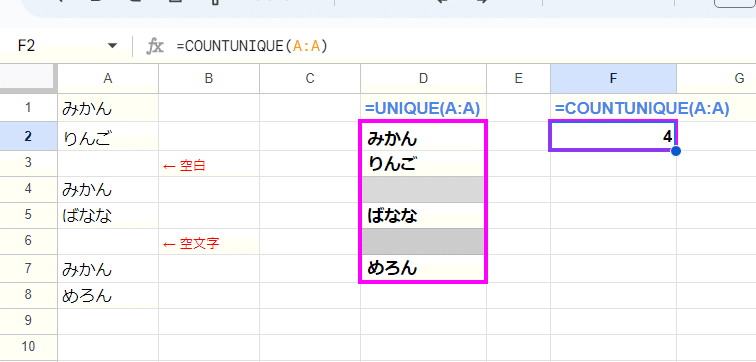
UNIQUE関数は空白や空文字を区別した上で、これらもユニークな値として抽出しちゃいますが、COUNTUNIQUE関数は空白、空文字はカウントしません。
空白を考慮しなくていいのは便利ですね。
一方注意点としては、エラーもカウントしてしまうという点があります。これはCOUNTAと一緒ですね。

行の削除やコピペで相対参照できなくなった際の #REF! や 一致する値が見つからなかった際の #N/A といったエラーが 1とカウントされてしまいます。
もう1つの注意点が COUNTUNIQUE関数は、あくまでもユニークな 「値」 をカウントする関数であるという点です。

たとえばフルーツと産地の2列データからユニークなデータ(行)をカウントすると、本来は 9 となるべきなんですが、
=COUNTUNIQUE(A:B) で 取得しようとすると フルーツ、産地、ひっくるめてユニークな 値の個数を取得してしまい、13という求めているものとは違う数値が返ります。
ユニークな行(データ)を取得するには一工夫必要ってことです。
Q1. 2列データから ユニークなデータ(行)の数を取得する為にはどんな式を作ればよいか?
ばなな 沖縄県
めろん 北海道
めろん 熊本県
みかん 和歌山県
りんご 長野県
りんご 青森産
めろん 茨城県
ばなな 沖縄県
ばなな 沖縄県
りんご 青森産
めろん 茨城県
ばなな 鹿児島県
りんご 長野県
ばなな 沖縄県
みかん 和歌山県
めろん 茨城県
りんご 青森産
みかん 愛媛県
みかん 和歌山県
みかん 愛媛県では、1つ目のお題いってみましょう。
上のようなデータが A:B列に入っています。範囲指定を A:Bとして、ユニークなデータ(行)の個数 9を取得する為の式を作ってみましょう!
まずは考えてみましょう!
↓↓
ここから回答です。
↓↓
A1. 2列データから ユニークなデータ(行)の数を取得する式
回答です。2通りのアプローチがあります。

1つは UNIQUEしてから ROWS関数で行数を取得する方法。
=ROWS(UNIQUE(FILTER(A:B,A:A<>"")))
ただし、UNIQUEは空白行も出力してししまう(可能性がある)ので、FILTERやQUERYで空白行を削除した上でUNIQUEしてから 行数を取得、としています。
※先にUNIQUEしてからFILTERやQUERYで空白を除去してROWSで行数(データの数)を取得でもよい
もう1つは A列とB列を連結して 1列データとしてから COUNTUNIQUEという方法。
=ARRAYFORMULA(COUNTUNIQUE(A:A&B:B))
FILTERやSORTと違って、UNIQUE系関数は残念ながら 内部で配列演算効果(Arrayformula効果)がありません。その為、別途 ARRAYFORMULAを付ける必要があります。
そのまま複数データを繋げた際にの誤判定が気になる場合、少し長くなりますが区切り文字を入れて
こんな式や
=ARRAYFORMULA(COUNTUNIQUE(IF(A:A="",,A:A&"_"&B:B)))
列数が多い場合も対応できる BYROWとTEXTJOINで行単位で文字連結させる
=COUNTUNIQUE(BYROW(A:B,LAMBDA(r,TEXTJOIN("_",true,r))))
こんな式でも良いでしょう。
UNIQUE関数の派生関数2 COUNTUNIQUEIFS関数
続いてCOUNTUNIQUEIFS関数です。
ちょっと関数名が長いんですよね・・・。
COUNTUNIQUEIFS関数の基本
COUNTUNIQUEIFS(一意の値の個数をカウントする範囲, 条件範囲1, 条件1, [条件範囲2, 条件2, ...])
COUNTUNIQUEIFS関数は、COUNTUNIQUE関数に条件による絞り込みを加えた関数です。
COUNTUNIQUE関数とCOUNTIFS関数が合体(フュージョン)したような関数、いやさらに分解すると
COUNTA + UNIQUE + IFS の三位一体関数と言えるかもしれません。
Excelに存在しない関数である為、あまり知られていない関数なんですが、Googleの公式の関数のページでも
COUNTUNIQUE関数の下に表示されないんですよね。。
なぜか データベース関数として扱われており、別ページにされています。
使い方としては COUNTUNIQUEしたい 範囲を第1引数で指定して、以降は
第2引数 範囲、第3引数 条件
第4引数 範囲、第5引数 条件
・・・
とCOUNTIFSと同じように、2つの引数をセットで使っていきます。

たとえば上の画像のケースのような使い方。
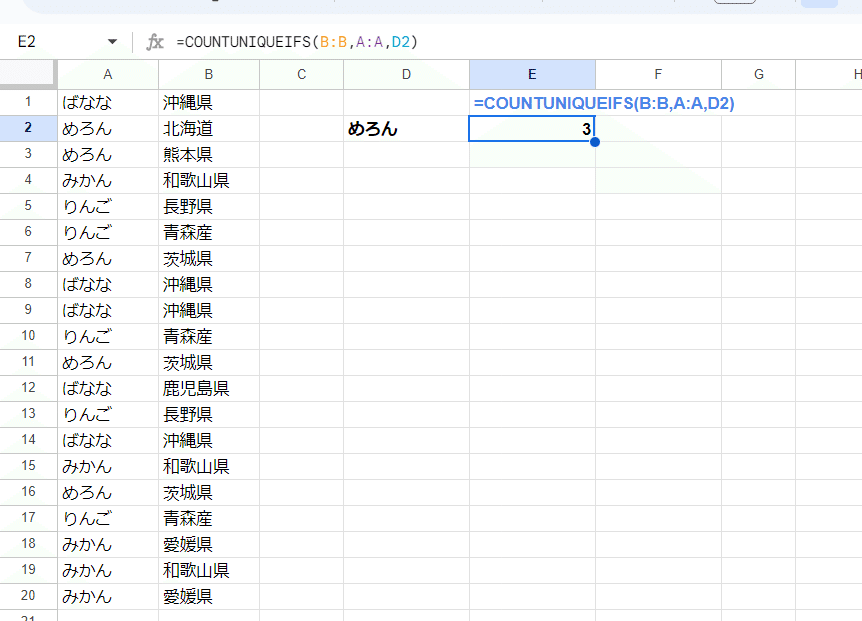
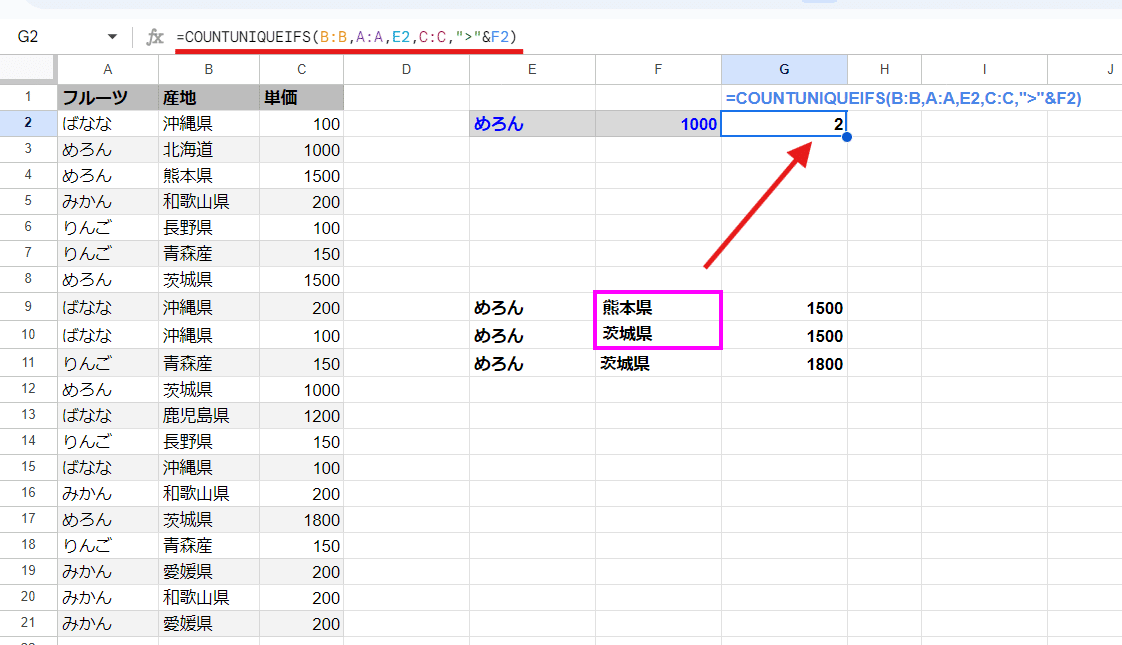
=COUNTUNIQUEIFS(B:B,A:A,D2)
B:B(産地列)が COUNTUNIQUEしたい範囲で、 A:A(フルーツ列)が、D2(めろん)であること を条件としています。
FILTER関数で、A列が めろん のデータを出力するとわかりますが、

北海道、熊本県、茨城県 の3つがユニークな値なので COUNTUNIQUEIFS関数の結果と一致しているのがわかりますね。
特徴と注意点は COUNTUNIQUE と共通していますが、COUNTUNIQUEIFS関数ならではの特徴、注意点もあります。
特徴の一つは、条件に 不等号、ワイルドカードが使える という点です。これはCOUNTIF、COUNTIFSと一緒ですね。
お題形式で理解を確認してみましょう。
Q2. フルーツ列がめろんで、単価が1000円より大きい(高い) 産地が幾つあるかカウントしたい

元データ
フルーツ 産地 単価
ばなな 沖縄県 100
めろん 北海道 1000
めろん 熊本県 1500
みかん 和歌山県 200
りんご 長野県 100
りんご 青森産 150
めろん 茨城県 1500
ばなな 沖縄県 200
ばなな 沖縄県 100
りんご 青森産 150
めろん 茨城県 1000
ばなな 鹿児島県 1200
りんご 長野県 150
ばなな 沖縄県 100
みかん 和歌山県 200
めろん 茨城県 1800
りんご 青森産 150
みかん 愛媛県 200
みかん 和歌山県 200
みかん 愛媛県 200A:C列にある元データから、E2セルのフルーツ(めろん)で、F2セルの単価(1000)より大きい(以上ではない)、この条件に合致する (ユニークな)産地が幾つかるかカウントしたい。
こんな要件があった時、どのような式を組めばよいでしょうか?
範囲は A:A、B:B、C:C という形で式を作ってみましょう。
↓↓
ここから回答です。
↓↓
A2. フルーツ列がめろんで、単価が1000円より大きい(高い) 産地が幾つあるかカウントする式
回答です。
=COUNTUNIQUEIFS(B:B,A:A,E2,C:C,">"&F2)
こんな式になります。これは大丈夫ですよね?
最終的に COUNTUNIQUEする範囲 ・・・ B:B
条件(第2引数以降)
A:A列(フルーツ)が E2(めろん)で・・・ A:A,E2
C:C列(単価)が F2(1000)より大きい ・・・ C:C,">"&F2
文字列である不等号と セル参照を組み合わせる時は、文字列の方を "(ダブルクォート)で囲うのと、セル参照と組み合わせる際に & を付けるのを忘れずに!
ワイルドカードを使うケースも同様です。(ほぼ同じなんでお題にするまでもないでしょう)
さらに 列ではなく行(横方向の)データだった場合も同じように式を組めばOKです。 ↓

=COUNTUNIQUEIFS(A1:S1,A1:S1,"*"&A7&"*")
COUNTUNIQUEIFSの注意点(1.第1引数が 複数列だと 条件列も 複数列である必要がある)
COUNTUNIQUEIFS関数ならではの注意点について、触れておきます。

=COUNTUNIQUEIFS(A2:B,C2:C,">"&E2)
あまり無いケースですが、第1引数のCOUNTUNIQUE範囲が複数列だった場合、
COUNTUNIQUEIFS の配列引数のサイズが異なります
というメッセージの #VALUE! エラー が出てしまいます。
これは行単位でデータをカウントする COUNTIFS関数とは違う挙動ですね。
COUNTUNIQUEIFS関数は あくまでも 行(データ)ではなく、個々のセル(値)を最終的にカウントする挙動に由来するものと考えられます。

COUNTUNIQUEIFSの場合は 行数(列の長さ)が揃っていることに加え、第1引数のカウント範囲と 条件部分の 列数も揃っている必要がある ってことですね。
一応、条件列を 第1引数に合わせ、条件部分を無理やり複数列にしてサイズを合わせることで回避できます。
=COUNTUNIQUEIFS(A2:B,{C2:C,C2:C},">"&E2)

このユニークな値の数をとっても意味はないんで、使いどころはなさそうです。
COUNTUNIQUEIFSの注意点(2.第1引数には配列は使えない、条件でスピらない)
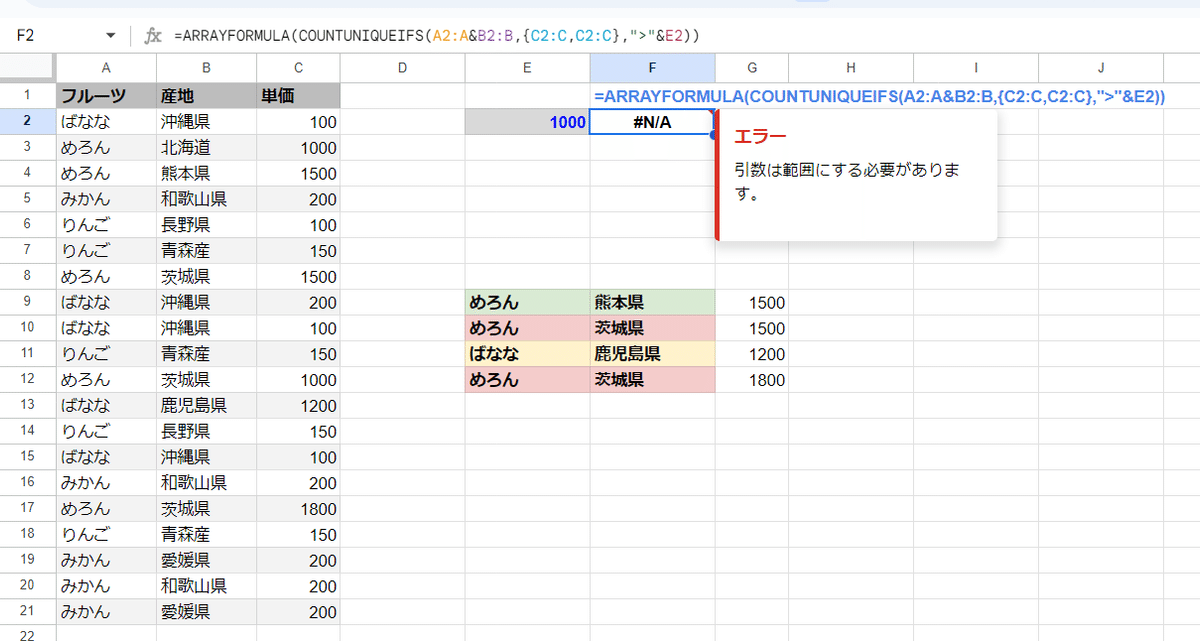
先ほどの流れですが、一般的に求めたい 数値としては、C列が 1000より大きい A:B列(フルーツと産地)のユニークな組み合わせ(行)が幾つあるか?だと思います。
なら、 COUNTUNIQUEで使った A列とB列を &で連結させた1列データとしてユニークをカウントする方法が使えるんでは?と
=ARRAYFORMULA(COUNTUNIQUEIFS(A2:A&B2:B,{C2:C,C2:C},">"&E2))
こんな式を入れてみるものの
引数は範囲にする必要があります。
と #N/Aエラーが出てしまいます。
Googleスプレッドシートの COUNTIFSはサイズさえ合ってれば配列が使えるんですが、残念ながら COUNTUNIQUEIFSは配列が使えないようです。。
A2:A&B2:B ← この部分が配列になってるってことですね。
これは 合計範囲に配列をとれない、SUMIFS関数と同じ挙動です。
ちなみに 第3引数の条件を配列にしても 結果は配列となりません。

=ARRAYFORMULA(COUNTUNIQUEIFS(B:B,A:A,E7:E9))
COUNTUNIQUEIFS関数はスピらない関数のようです。
COUNTUNIQUEIFSの注意点(3.条件部分は緩い一致判定)

=COUNTUNIQUEIFS(B:B,A:A,D2)
上のように 平仮名、カタカナ、全角、半角、さらに 伸ばし棒(長音記号)が混在したデータがあった場合、COUNTUNIQUEIFSの条件部分
A:A列が D2(葬送のフリーレン)と一致するとしても、残念ながら厳密な一致判定となりません。
つまり、条件部分の絞り込みは COUNTIFSと同じ ゆるーい一致判定ってことです。
一方、第1引数の B:B部分 は厳密な COUNTUNIQUEでカウントされるため、最終的に6という数値が返っています。
COUNTUNIQUEIFS関数については、 (「会社員がVLOOKUPの次に覚えるQUERY関数超入門」 の著者でもある)カワムラさんも noteで取り上げています。
↑ こちらは、まさにCOUNTUNIQUEIFSが使えそうな リアルケースですね。
COUNTUNIQUE も COUNTUNIQUEIFS も 使えなくても問題ありません。
UNIQUE関数と違って他で簡単に代替できる関数ですし、使えるケースも多くはありません。(スピンオフ作品は本家を超えられないことも多い)
ただ、たまーにこの関数がドンピシャではまる時があるんですw 知っていて損はないかと。
UNIQUE関数、COUNTUNIQUE関数、COUNTUNIQUEIFS関数 ちょい応用例
それでは、最後に UNIQUE関数と派生関数である COUNTUNIQUE関数、COUNTUNIQUEFIS関数、これらを使った超ではなく ちょい応用例 のお題をやってみましょう!
Q3. 範囲内のデータが全て一致しているかを厳密に判定したい

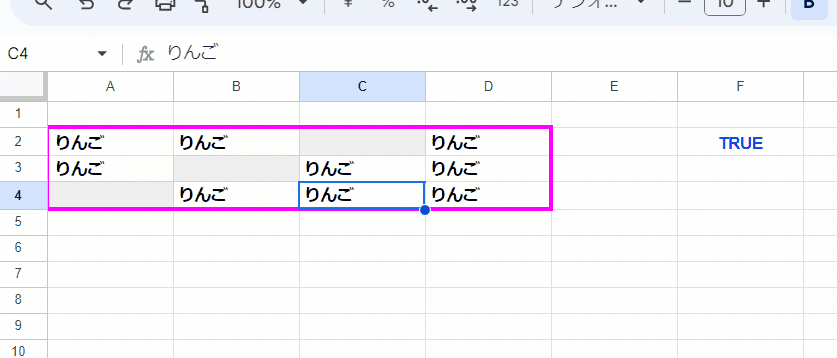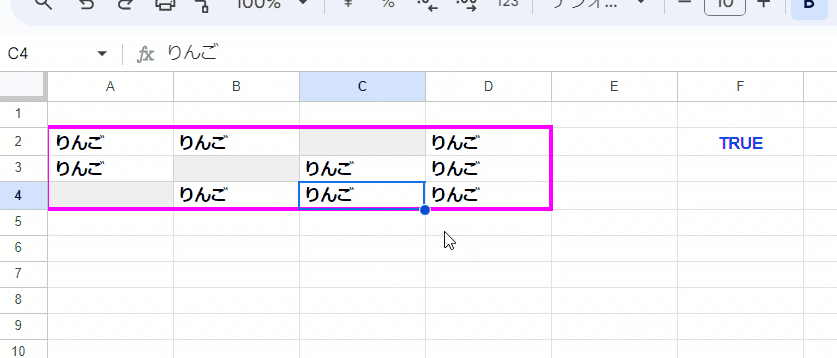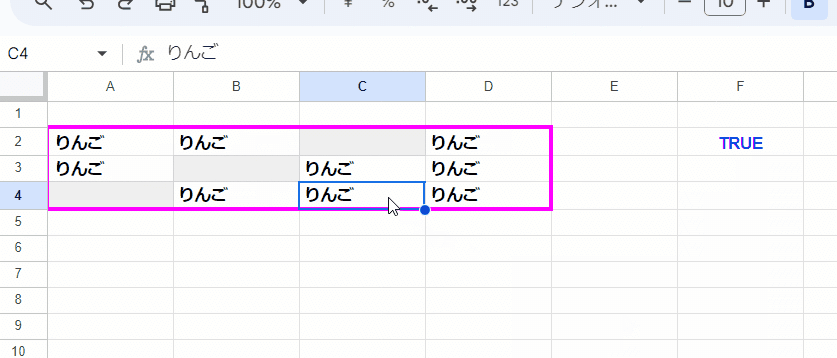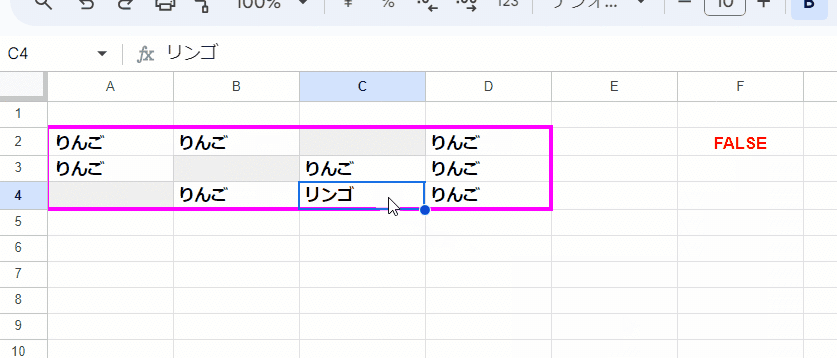
セル範囲 A2:D4 に入っている値が 全て一致するかを判定するには、どのような式を組めばよいでしょうか?
データは以下をA2セルに貼って利用ください。
りんご りんご りんご
りんご りんご りんご
りんご りんご りんごただし、以下を条件とします
・厳密な一致判定としたい (Apple と apple、リンゴとりんご を区別)
・結果は Boolean値 (一致なら TRUE)で表示して欲しい
・全て空白というケース、空文字が混じるケースは考慮不要
・ 2パターン 考えて欲しい
①空白セルが含まれてもOK 値が入っているセルが全て一致すれば TRUE
②範囲内の空白セルを認めず、全てのセルの値が一致して TRUE
どうでしょうか?厳密な一致ということで、EXACT関数か UNIQUE系関数が必要となります。どちらを使っても出来るんで、余裕があればそれぞれの式を作ってみてください。
考えてみましょう!
↓↓
ここから回答です。
↓↓
A3. 範囲内のデータが全て一致しているかを厳密に判定する式①
回答です。
①空白セルが含まれてもOK 値が入っているセルが全て一致すれば TRUE
UNIQUE系関数を使う場合

=COUNTUNIQUE(A2:D4)=1
空白を自動で無視してくれる COUNTUNIQUEを使うのが最も簡単ですね。
空白以外の全ての値が一致 = COUNTUNIQUEの結果が 1 なので、このシンプルな式だけで解決しちゃいます。
これを EXACT関数で頑張って作ろうとすると、なかなか面倒です。
EXACT関数を使う場合
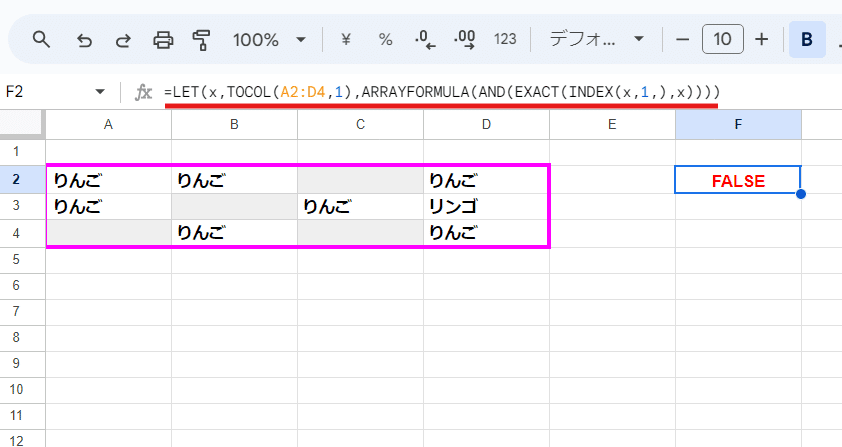
=LET(x,TOCOL(A2:D4,1),ARRAYFORMULA(AND(EXACT(INDEX(x,1,),x))))
EXACTを使う場合は少し面倒です。
ただし
× 全て一致・・・ 全組み合わせを一致判定
こんな処理を考える必要はありません。
基本的には 三段論法 の
A=B である
A=C である
よって B=C である
この考え方に則って、サンプルとして一つ取り出した 値と 他を比較して 全て一致していればOKってことです。
ただし、空白セルだけ例外とする必要があります。
もちろん OR関数を使って「一致または空白である」としてもいいんですが、先に空白を除外してしまう方が簡単です。
まず TOCOL関数の第2引数を 1として空白削除をしたデータを生成、 LET関数でそれを xと置きます。
INDEX(x,1,)で 先頭の値をサンプルとして取得し、それと 他の値が一致しているかを
EXACT(INDEX(x,1,),x)
で判定。
ここは配列処理になるんで ARRAYFORMULAが必要。最後にAND関数で括って 全てTUREなら TRUEを返す式としています。(一つでも FALSEがあれば FALSEとなる)

こっちはなかなか複雑じゃないでしょうか? この処理はCOUNTUNIQUE関数を使った方が超簡単ですね。
A3. 範囲内のデータが全て一致しているかを厳密に判定する式②
②範囲内の空白セルを認めず、全てのセルの値が一致して TRUE
パターン②の回答です。
EXACT関数を使う場合
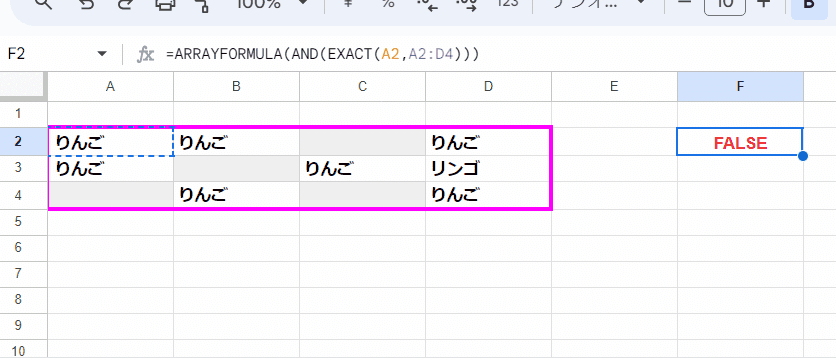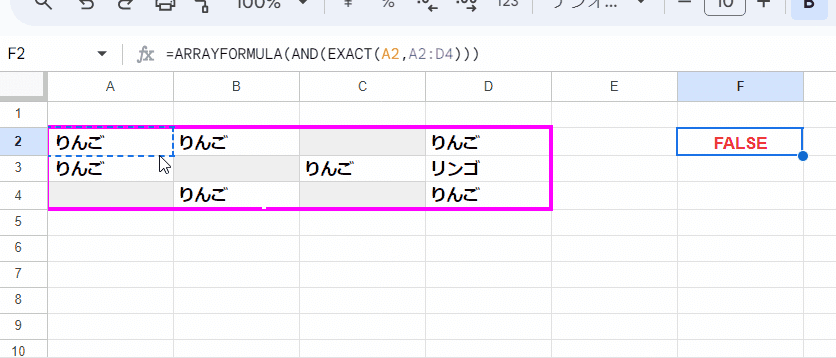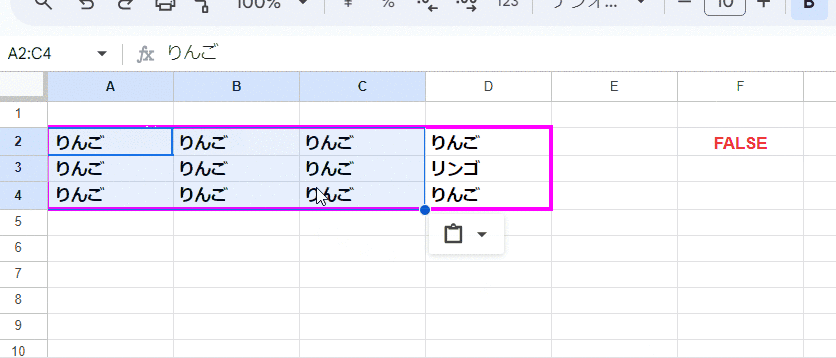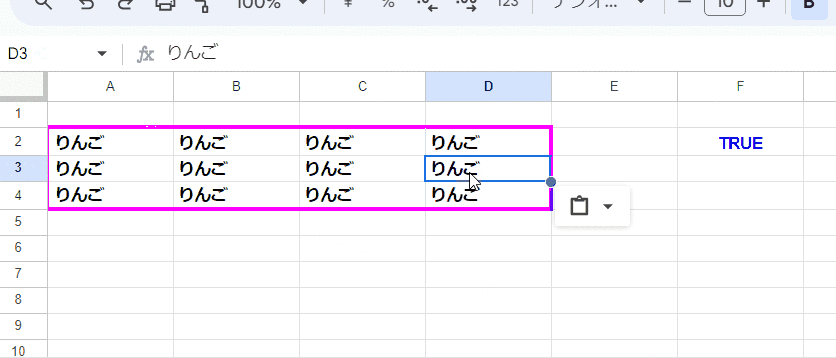
=ARRAYFORMULA(AND(EXACT(A2,A2:D4)))
空白を考慮しなければ、EXACTの式もだいぶ短くなります。
考え方は先ほどと一緒ですが、比較用に取り出すサンプルは 範囲左上の A2でよいので楽ですね。
UNIQUE系関数を使う場合
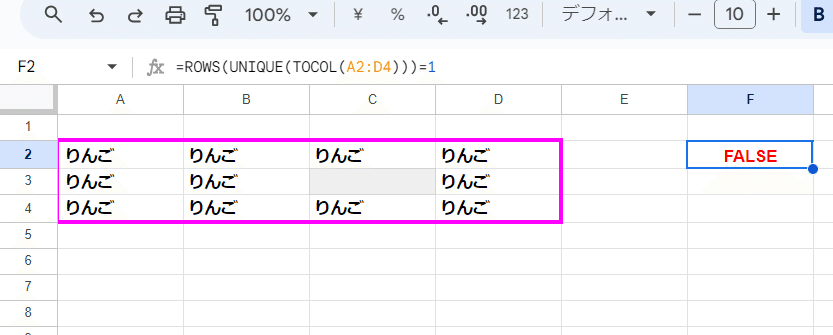
=ROWS(UNIQUE(TOCOL(A2:D4)))=1
空白が混じったらFALSEとしたいので、空白を自動で無視する COUNTUNIQUEやCOUNTUNIQUEIFSは使えません。
ここでは TOCOLで空白除去なしで一列データとした上で、空白もユニークな値として抽出する UNIQUE関数を使って 一意の値にして、最後にROWS関数でデータの行数を取得。
これによって 空白が混じると 2を返し FALSEとなる式にしています。(※全部空白だと 1で TRUEとなるが、そこは前提条件で考慮不要)
最後をCOUNTAにしてしまうと 空白が混じっても 1になるんで、最後は 空白を含め結果の行数(データ数)を返す ROWS関数である必要があります。
複数データの厳密な一致判定で、UNIQUE系関数を使う例でした。
別解として
=COUNTUNIQUE(A2:D4)+COUNTBLANK(A2:D4)=1
この方がわかりやすいのでは?というご意見もありました。全て空白であるケースを考慮外とすれば確かにアリですね。
COUNTUNIQUEIFSは出番なかった・・・
UNIQUE関数、次回ラストの前に・・・アレを検証
UNIQUE関数なら 2回で終わるかなと甘くて見ましたw ちょっと余談が多かったのもあり、まだ
UNIQUE関数とSUMIFSやCOUNTIFS、FILTER、TEXTJOINを組み合わせた集計ワザ
UNIQUE関数を使いまくる 厳密な一致判定による 条件付き書式や データ抽出処理
これらの超応用例にたどりついていませんw
次回ラストは 、お題連発でUNIQUE関数を使い倒す応用例祭り・・・といきたいところですが、その前に
UNIQUE関数シリーズの途中ですが、番外編として
範囲 → 配列 変更で COUNTIF、COUNTIFS、SUMIFの 一致判定をExcelと同等レベルまで性能アップ ってネタを先に取り上げたいと思います。
Googleスプレッドシートの ひらがな、カタカナ、全角、半角を一致とみなされるゆるーい判定のせいで、COUNTIF、SUMIFなどの集計がうまくいかない。
— mir (@mir_for_note) April 27, 2024
こんな時、実は 範囲を { } で括って配列にすることで、なぜか判定がExcelと同じ程度に厳密になります。(大文字小文字は同一とされる)
ふしぎー pic.twitter.com/dkvpv5Jbjg
難しい数式を組む必要なく、「ちょっとの工夫でこのうまさ!」を体感できる超絶便利ネタです。
次回、難しい関数や小難し検証には興味ないだけど・・・って人も要チェックや!