
Googleスプレッドシート UNIQUE関数 超応用例

今回の関数超応用例シリーズは、重複を排除して一意の結果を返す UNIQUE関数です。
Googleスプレッドシートだけではなく、現在は Excelでも使える
FILTER関数
SORT関数(SORTBY関数)
UNIQUE関数
これらの便利関数。※Excel2021以降、および 365版、Web版のみ
スピル以前のExcelでは難しかった(非常に面倒だった)処理を、悪魔的なほど簡単に一つの式で記述できるこの3つの関数に加え、最強のチート関数 QUERY関数。
mirは これらの最強クラスの関数を 勝手に四天王と呼んでますが、実際にExcelへ輸入される前は「この関数が使いたい!」って理由で、Excelと併用してGoogleスプレッドシートを使うようになった人もいたくらい 強力な関数です。
これまで mirのnoteでは FILTER関数
そして SORT関数 を取り上げました。
今回は UNIQUE関数の基本から ExcelのUNIQUE関数との違い、そして超応用例 までをみていきましょう。(といっても UNIQUE関数は使いどころが限定的なんで、あまり応用例もないんですが・・・)
久しぶりに お題形式で書きたいと思います!
わかりやすい故に応用の幅は少なそうな UNIQUE関数なので、
「ククク……。奴は四天王の中でも最弱」
と言われないように 隠された魅力を引き出したいと思いますw
前回は、iPhone、iPadのGoogleスプレッドシートで値貼付けをする方法、合わせてGoogleドキュメントなどでも発生している貼付け時の文字化け問題の解決方法、セル内改行ありのテキストコピペ時の " が付いちゃう問題への対処について書きました。
UNIQUE関数の基本

まずは UNIQUE関数の基本を理解しましょう。
一応、公式ヘルプはこちら
UNIQUE関数は重複を排除して一意のデータにする関数
UNIQUE(範囲, 行で処理, 重複なし)
UNIQUE関数は3つの引数をとれますが、必須なのは第1引数の範囲のみです。
まずは 第1引数のみで基本の動きをみてみましょう。

A1:A20 範囲に 4種類のフルーツ名がランダムに入った一列のデータがあります。これを重複を排除して一意の値としたい場合
=UNIQUE(A1:A20)
こんな式で 「みかん、りんご、ばなな、めろん」という一意の値だけに絞り込んだ結果を取得できます。
簡単に重複排除ができますね!
イメージとしては範囲を上から走査していって、1回目に登場する値だけ出力してる感じでしょうか。
そのため結果は元データの上から見た登場順のままとなります。

複数列のデータの場合は 一意の行を返す

さきほどのような一列データを対象とした場合は、UNIQUE関数は重複する値を排除したユニークな一意の値を返しました。
では、複数列複数行のデータを対象とした場合はどうなるでしょうか?
この場合は、行単位でみて 各要素の全てが同じ行 を重複として 排除し、一意の行にしていきます。

めろん 北海道
めろん 熊本県
この2つは別モノ(ユニーク)として扱われているのがわかりますね。
つまり、複数行・複数列の範囲を対象として、その中に登場する ユニークな値を取り出したいと思った場合
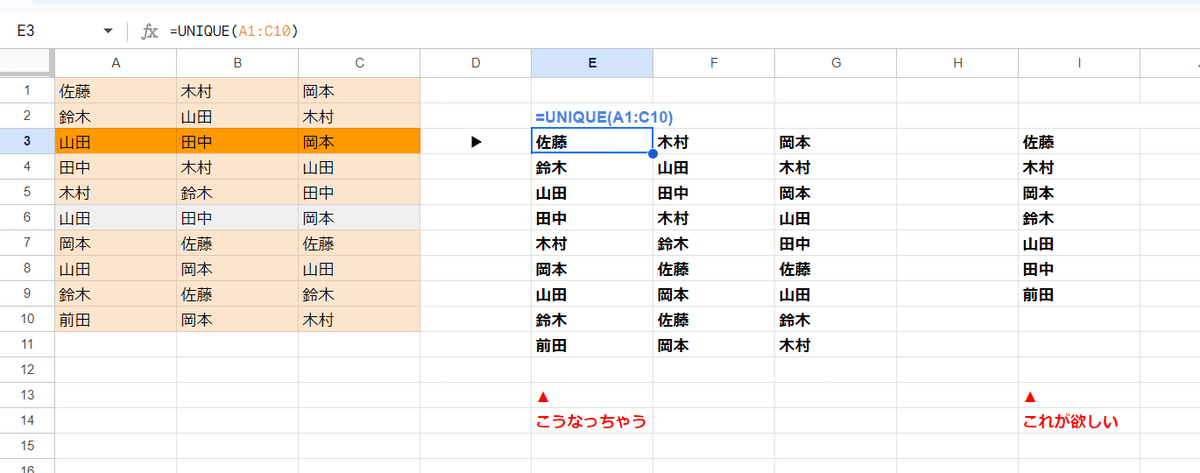
単純に =UNIQUE(A1:C10) では 思うような結果が得られないわけです。
この手のデータからのユニークな 値の取り出す式については後ほどお題の中で触れていきます。
また行単位でユニーク化した結果ですが、先ほど書いた通り登場順に単にユニークになっただけなんで
こんな感じになります。
1列目がバラバラで、これだと 集計としてはちょっと見づらいですよね。
綺麗に並びをまとめる為はもう一工夫必要です。これも後ほどお題としますんで、やってみましょう。(簡単です)
UNIQUE関数は 第2引数 TRUEで 横方向にユニーク処理ができる
UNIQUE(範囲, 行で処理, 重複なし)
UNIQUE関数の 第2引数(公式では「行で処理」)は、重複チェックの方向指定です。
省略時は FALSE扱いで、これは先ほどのように 縦に見て重複を排除する動きとなります。
この第2引数を TRUE指定することで 縦から横にモードが変わり、横方向にスキャンしていく(列単位で比較する) ユニーク処理となります。

=UNIQUE(A1:T1,TRUE)
こうすることで、横に展開されたデータを 重複排除し一意のデータとして返すことが出来ます。(結果は 横に展開します)
しかし気になるのは 第2引数の「行で処理」って言葉・・・
初期値 FALSEで TRUEにしたら 列単位で処理されるんだから・・・これ逆じゃね??
と思ったら、ExcelのUNIQUE関数の公式ヘルプだと 第2引数は by_col引数 ってなってますね。
GoogleスプレッドシートのUNIQUE関数も 英語版の本家ヘルプページだと by_column ってなってるんで、日本語ページの誤訳かもしれません。
当然 複数行のデータに対しても、第2引数をTRUEとすることで 横方向に 列単位で重複を排除したユニーク処理が出来ます。

=UNIQUE(A1:T2,TRUE)
Googleスプレッドシートの FILTER、SORT、UNIQUEのうち SORT関数だけが 横方向の処理ができないのか・・・。(Excelは横方向のSORT処理が出来る)
第3引数 TRUE指定で 一つしか登場しないデータを取得できる
独特な挙動となるのが第3引数の 「重複なし」(英語名 exactly_once)です。
UNIQUE(範囲, 行で処理, 重複なし)
こちらは 省略時(初期値)は FALSE なんですが、これを TRUE指定すると 範囲内で重複していない(1回しか登場しない)データのみ抽出することができます。

たとえば 上の画像のように A1:A20 の範囲に色々フルーツが書かれていますが、みかん、りんご、 ばなな、めろん は複数回登場しているのに対して、すいか と さくらんぼ だけは、1回しか登場しない値となっています。
この1回しか登場しないものを抽出する式が
=UNIQUE(A1:A20,,TRUE)
こちらです。これで重複していない 値のみ出力ができます。

複数列のデータだった場合 や 横方向のデータに対しても「重複なし」の1回しか登場しないデータを取得できます。
=UNIQUE(A1:B20,,1)
=UNIQUE(D10:W10,1,1)
では、逆に重複している(2回以上登場する)データだけ取得したい場合はどうしたらよいでしょうか?こちらも式を工夫することで取得可能です。後ほどお題でやってみましょう!
UNIQUE関数の基本、および 3つの引数については以上となります。
Googleスプレッドシート UNIQUE関数の特徴
基本をおさえた上で、UNIQUE関数の特徴も理解しておきましょう。
特徴がわかっていれば、どの関数と組み合わせればよいか? どういった要件の時に使うべきか? これらが見えてきます。
大きい特徴としては以下の4つです。
結果は元のデータの並び順(登場順)となる
空白はそのまま 1つのユニークな値として出力される
GoogleスプレッドシートのUNIQUE関数は 厳密に一致判定される
表示形式は無視した形で 重複判定、出力結果は 表示形式が保持される
1つ目の並び順については冒頭でふれたので、残り3つを説明していきます。
空白はそのまま 1つのユニークな値として出力される
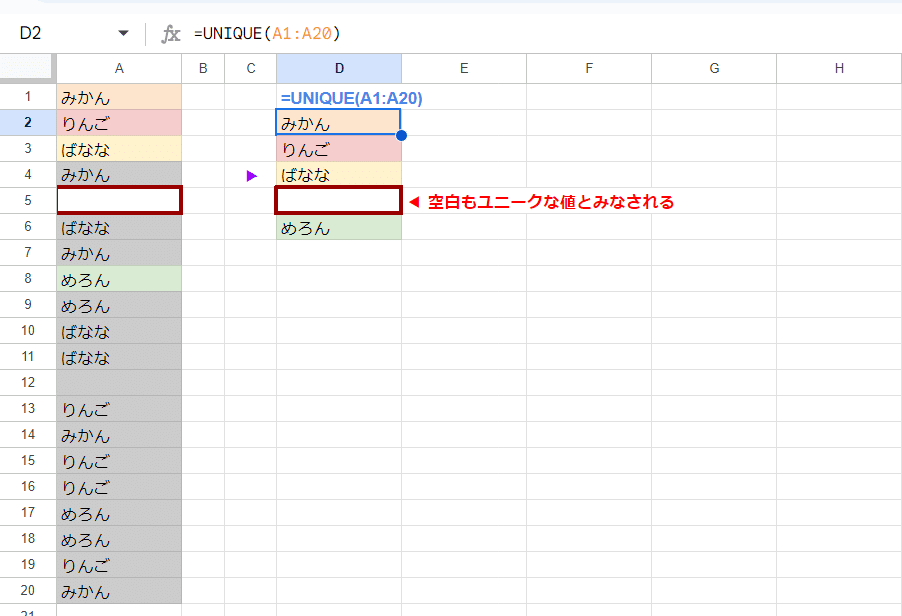
冒頭で登場した 基本の使用例 =UNIQUE(A1:A20)
このデータ範囲である A1:A20 の中に 空白セルがあった場合、上のように 空白も 1つのユニークな値として 登場順で めろん の上に出力されてしまいます。
つまり UNIQUE関数は 空白は除外してくれないってことです。
途中に空白セルなんて無いよって場合でも、Googleスプレッドシートでよく使う お尻(最終行)を指定しない範囲指定 A:A を使った際に

このように見た目はわかりませんが、実は UNIQUE関数の結果は めろんの下の D6セルの空白まで を返しています。
ROWS関数でデータの行数を数えると 5となっているのがわかりますね。
この D6セルは 何も入っていないようで、実は空白を返している 数式の結果出力範囲なので

このように D6セルに 値や数式を入れると、数式の展開が邪魔されてしまう為、D2セルの UNIQUE関数がエラーとなります。
さらに 下で触れますが Googleスプレッドシートの UNIQUE関数は 超厳密な一致判定なので

こんな感じで 数式で ""(空文字)を返している場合、空白と別に 空文字も一つのユニークな値として結果に出力されてしまいます。
UNIQUE関数の結果の途中、もしくは最後に出力される 空白を除外する為には 別の関数を組み合わせる必要があるってことです。(これも後ほど お題として登場)
GoogleスプレッドシートのUNIQUE関数は 厳密に一致判定される

これは Googleスプレッドシートの UNIQUE関数の大きい特徴と言えるかもしれません。
Googleスプレッドシートは Excelに比べて 通常の一致の判定が非常に甘く、B2=C1 といった イコール式で 判定(一致なら TRUE)とした場合、上のように
半角小文字 a
全角小文字 a
半角大文字 A
全角大文字 A
全角カタカナ ア
全角ひらがな あ
半角カタカナ ア
全角ひらがな小文字 ぁ
となってしまいます。
〇〇IFS系関数 や LOOKUP系関数 でも この一致判定が採用されている為、
アマゾン
と
ぁまぞん
が同じと見なされた結果になってしまい困ったりします。
芸能人格付けチェックに登場するアイドルくらいダメダメな判定ですw
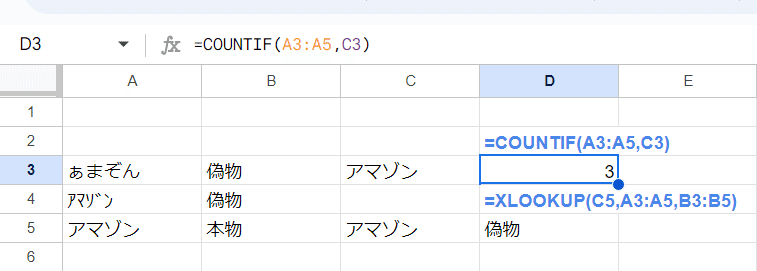
これらの厳格な一致を判定する為には EXACT関数を使うことが多いです。

で、なぜか Googleスプレッドシートの UNIQUE関数は、この EXACT関数以上に厳密な一致判定となっています。

このようにUNIQUE関数は、半角や全角、大文字、小文字、平仮名、カタカナを別モノと判定してくれます。
さらに EXACT関数では一致と判定される

空白と空文字
数値としての半角数字 と 文字列の半角数字
これらですら UNIQUE関数は区別します。
UNIQUE関数は EXACT関数 以上の超厳格チェックであると言えます。
もちろん、もうちょい緩い判定の方がいいって時もあるでしょうが、これだけ厳格な判定はありがたいですね。
ちなみに「Googleスプレッドシートの」と付けたのは、後で触れますが Excelだと勝手が違うからです。
表示形式は無視した形で 重複判定、出力結果は 表示形式が保持される
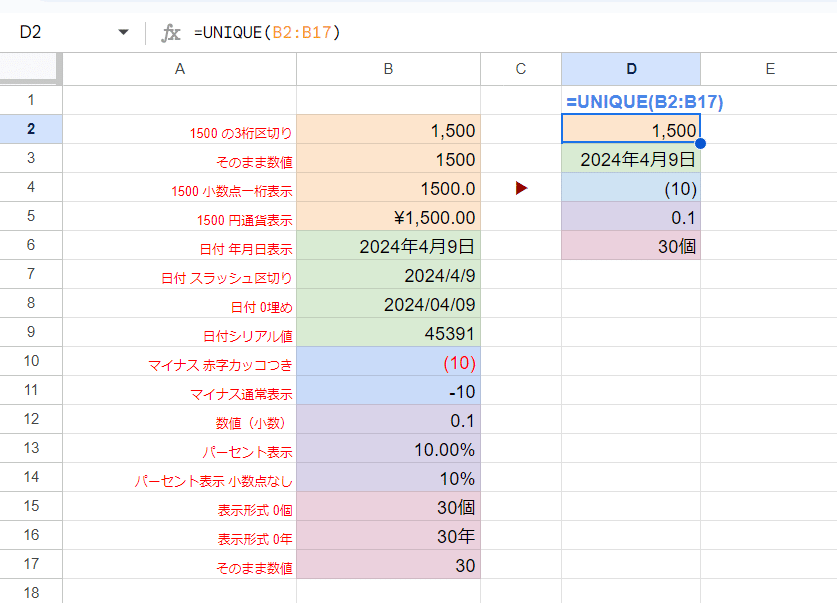
セルの中身の値に関しては厳密に一致を判定する UNIQUE関数ですが、表示形式には 惑わされることなく 重複排除、ユニーク処理がなされます。
上のように 数値や日付など 表示形式を変えても 同じものとして扱われます。日付はシリアル値の場合も一致判定されてますね。
ちなみに Googleスプレッドシートの UNIQUE関数の結果は、一意の値が最初に登場した時の書式が反映された形となります。
面白いですね。
Excel / Googleスプレッドシート UNIQUE関数の違い

GoogleスプレッドシートのUNIQUE関数の特徴はわかりましたね。では、Excelの UNIQUE関数との違いはあるのか?をみていきましょう。
友好の証? 珍しく 引数が完全一致している UNIQUE関数
Googleスプレッドシートは 後発なだけあって、Excelの関数を輸入する際は互換性を意識して基本的に 引数や仕様は Excelのものに準じることが多いです。
例:XLOOKUPなど
しかし、Excel側は シェアを奪おうとする Googleスプレッドシートを快くは思っていないようで、先にGoogleスプレッドシートが実装していた関数を輸入する際に、魔改造してくることが多いです。
Googleスプレッドシート SPLIT関数
▼
Excel TEXTSPLIT関数
(関数名変更、縦分割ありに)
Googleスプレッドシート FILTER関数
▼
Excel FILTER関数
(条件は第2引数のみ、第3引数に 見つからなかった時の値が追加)
Googleスプレッドシート SORT関数
▼
Excel SORT関数、SORTBY関数
(役割を分けて 2つの関数に)
もちろん便利になってる部分もあるんですが、互換性を潰す 嫌がらせじゃない?って思うんですよねw おそろしい子!
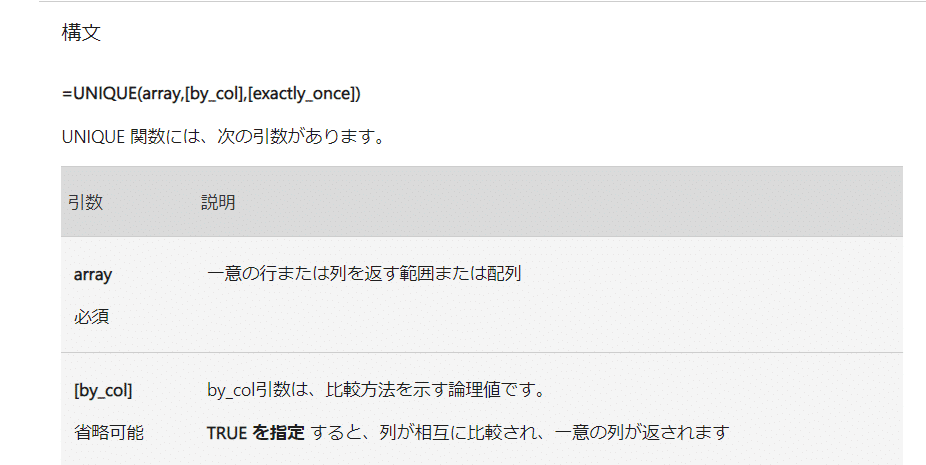
で、そんな中 UNIQUE関数は 珍しく 引数や使い方が完全に Googleスプレドシートと Excelで同じ関数となっています。
=UNIQUE(array,[by_col],[exactly_once])
※でも、おぼろげな記憶ですが Googleスプレッドシートの初期のUNIQUE関数は 第2引数、第3引数がなかったような。。
▼ 公式情報ではありませんが、「いきなり答える備忘録」様が、UNIQUE関数の記事冒頭で、引数がExcelから逆輸入されたことを明記しています。
ただ先ほど少し触れましたが、ExcelとGoogleスプレッドシートの UNIQUE関数では、結構 挙動に違いがあるんです。その点を見ていきましょう。
ExcelのUNIQUE関数は 一致がゆるーい

もっとも大きい違いが、 ExcelのUNQIEU関数の一致判定の甘さです。
GoogleスプレッドシートのUNIQUE関数がこれでもか!ってくらい厳密判定の設定だったのに対し、ExcelのUNIQUE関数は イコール一致よりも緩い判定となっています。
特に 半角、全角、大文字、小文字を 重複としてみなしているのが悩ましいですね。
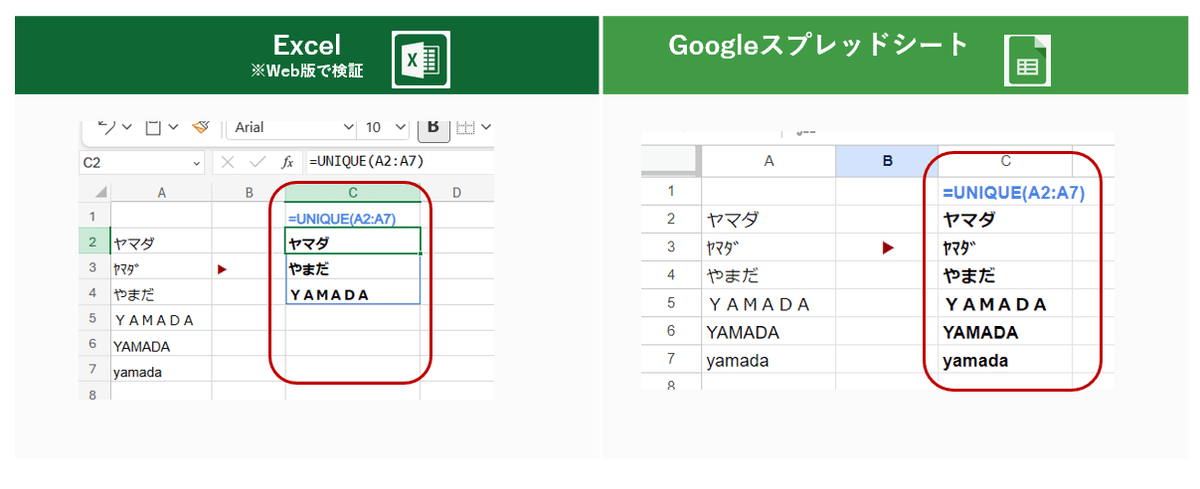
Excelで UNIQUE関数を使う場合は、この一致判定の甘さにより誤って重複と見なされるリスクがあることを注意しなければなりません。
ちなみに ExcelのUNIQUE関数を紹介したサイトは多いですが、この一致の緩さに触れてないことも多いんですよね。
UNIQUE関数で一致と判定された値は 全角が優先されるとか、小文字が優先されるといったルールはなく、同一とみなされる値のうち 初回に登場した値が表示される仕組みとなっています。
Excelの UNIQUE関数は 空白は 0となる
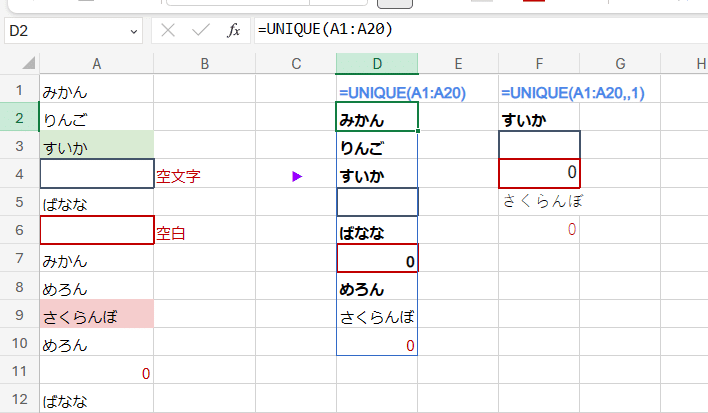
これは Excelの仕様なんで仕方ないんですが、UNIQUE関数で出力した結果も 空白があった場合は 0表示となります。
この空白が0表示されたセルは、空文字 "" を返しているセルとは区別されます。
また、もともと範囲内に 数値の 0が存在していても、数値の0と空白の結果の 0は 重複として判断されません。(空白は最後の最後に出力される瞬間に 0となるから?)
Excelで A:A のような 指定をすることは多くはないでしょうが、当然このように範囲指定すると

こうなるわけです。
空白のない綺麗なデータを用意してテーブルを使いましょうってことですね。
ExcelのUNIQUE関数の結果は 書式が保持されない

これも Googleスプレッドシートの仕様が特殊って話なんですが、ExcelのUNIQUE関数は結果に元データの表示形式は反映されません。
特に困るのは日付でしょうか。
上のように 表示形式によらず シリアル値含め 同じ日付と判断して UNIQUE関数では 一意の値となるんですが、結果が出力されるセルに書式設定をしていないと日付はシリアル値で返ります。

Googleスプレッドシートに慣れてると、空白の0化や 書式飛ぶのは、あーExcelはそうだった~ ってなりますね。
一致の判定の違いは大きいですが、UNIQUE関数は ExcelとGoogleスプレッドシートどちらも同じように使えると良いでしょう。
UNIQUE関数ちょい応用例
まずは 超応用例とまではいかない、ちょい応用例を幾つかお題形式で学んでいきましょう。
Q1. ユニークにした上で並び替えたい

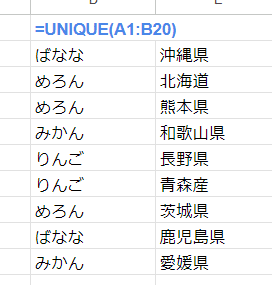
2列のデータ(A1:B20)を ユニークにしただけでは、並びがバラバラで見づらいので、一番右のように並び替えて綺麗に表示したい場合、どのようにすればよいでしょうか?
ばなな 沖縄県
めろん 北海道
めろん 熊本県
みかん 和歌山県
りんご 長野県
りんご 青森産
めろん 茨城県
ばなな 沖縄県
ばなな 沖縄県
りんご 青森産
めろん 茨城県
ばなな 鹿児島県
りんご 長野県
ばなな 沖縄県
みかん 和歌山県
めろん 茨城県
りんご 青森産
みかん 愛媛県
みかん 和歌山県
みかん 愛媛県元データはこちらを利用して、チャレンジしてみましょう。簡単です。
やってみましょう!
↓↓
ここから回答です。
↓↓
A1. ユニークにした上で並び替える
回答です。

UNIQUEして SORT(並び替え)でいいですね。
=SORT(UNIQUE(A1:B20))
SORT関数 は第1引数のみとした場合は、1列目から優先キーとして昇順に並び替えとなるので、割とシンプルな式でユニーク後のデータを綺麗に並べることができます。
実はUNIQUE関数を使わない簡単な方法もあるんですが、それは後で触れます。
Q2. 複数列のデータから 一意の値を取得したい

UNIQUE関数は 行単位(第2引数 TRUE時は列単位)で 重複をチェックします。
では、上のような A1:C10 の範囲にある 複数列にまたがる名前データから ユニークな 名前の一覧を出力したい場合はどうすればよいでしょうか?
佐藤 木村 岡本
鈴木 山田 岡本
山田 田中 佐藤
田中 田中 鈴木
木村 鈴木 田中
木村 前田 木村
岡本 佐藤 佐藤
山田 岡本 鈴木
鈴木 佐藤 鈴木
前田 岡本 木村こちらのデータを使って考えてみましょう!
↓↓
ここから回答です。
↓↓
A2. 複数列のデータから一意の値を取得する
回答です。
=UNIQUE(TOCOL(A1:C10))
UNIQUE関数で一意の値を取得できる形、つまり一旦 1列データに元データを成形してあげれば良いわけです。

ここで使えるのが TOCOL関数です。(FLATTEN関数でも可)
1列データとしたら、あとはUNIQUEするだけ。割と簡単ですね!
UNIQUE関数の第2引数を TRUE指定した 横方向の処理の場合は、TOCOLではなくTOROW関数を使えばOK。
Q3. 空白を削除したユニークな値を取得したい

UNIQUE関数の特徴で触れましたが、空白は一意の値の一つとして結果に表示されてしまいます。
では空白を除外したユニークな値を取得するにはどうすればよいでしょうか?
みかん
りんご
ばなな
ばなな
ばなな
みかん
めろん
めろん
ばなな
ばなな
めろん
りんご
みかん
りんご
りんご
めろん
めろん
りんご
みかんこちらのデータをコピー、A1以下に貼って 範囲 A:A を対象として式を書いてみましょう!
↓↓
ここから回答です。
↓↓
A3. 空白を削除したユニークな値を取得する
1列データなら 先ほど登場した TOCOLを使うのがベストですね!
=UNIQUE(TOCOL(A:A,1))
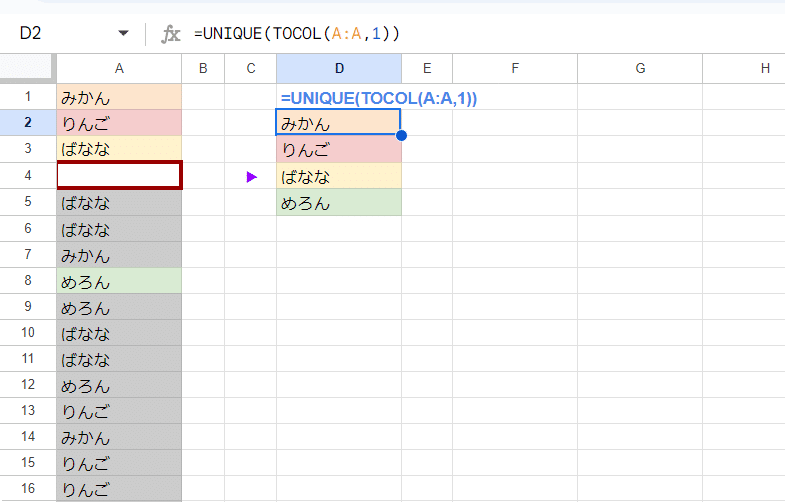
TOCOLの第2引数を 1と指定すると 空白を無視して上に詰めて出力できるので、これをUNIQUE関数と組み合わせます。(TOCOLの第2引数は 3として エラーも合わせて除外してしまっても良い)
もちろん 先にUNIQUEしてから最後にTOCOLでもよいです。
=TOCOL(UNIQUE(A:A),1)
簡単ですね。TOCOL関数はUNIQUE関数と相性がいいです。
Q4. 空白を削除してユニークな行を綺麗にまとめたい
では1列データではない場合の空白行削除は どうでしょうか?

画像の上部のような、とびとびのデータがあります。 色がついている範囲は空白であっても値が入る可能性があるので範囲対象にする必要があります。※フルーツ、産地片方だけ入ることはありません。
これを 空白行が途中に出ない ユニークな行データにして、並びを綺麗にしてまとめたい。
こんな時はどのような式を組めばよいでしょうか?
残念ながら 1列データではないので TOCOLが使えません。
フルーツ 産地 フルーツ 産地 フルーツ 産地 フルーツ 産地
ばなな 沖縄県 りんご 長野県 めろん 茨城県 みかん 愛媛県
めろん 北海道 りんご 青森産 ばなな 鹿児島県 みかん 和歌山県
めろん 熊本県 めろん 茨城県 りんご 長野県 みかん 愛媛県
みかん 和歌山県 ばなな 沖縄県 ばなな 沖縄県
ばなな 沖縄県 みかん 和歌山県
りんご 青森産 めろん 茨城県
りんご 青森産 こちらのデータをA1にコピペしてやってみましょう!
↓↓
ここから回答です。
↓↓
A4. 空白を削除してユニークな行を綺麗にまとめる
回答です。まず、範囲を結合してUNIQUE処理をします。
UNIQUE関数はセル範囲だけでなく、中カッコで連結した配列や IMPORTRANGEや他の関数で生成された配列にも使えます。
UNIQUE({A2:B8;D2:E8;G2:H8;J2:K8})
ここから、空白除去と並び替えがセットで出来る QUERY関数と組み合わせるのがよいでしょう。
=QUERY(UNIQUE({A2:B8;D2:E8;G2:H8;J2:K8}),"where Col1 is not null order by Col1 asc")

本当は QUERY関数は group by で ユニーク化も出来ちゃうんですが、今回はその部分は UNIQUE関数に任せますw
ただ、途中に空白が入らなければよいって考えるなら QUERY関数で長い式をつくら無くても、シンプルに SORT関数を使って 空白の行を一番下に追いやるという方法もあります。
=SORT(UNIQUE({A2:B8;D2:E8;G2:H8;J2:K8}))

見た目上は 一番下に空白が返ってることは気にならないので、これでも良いかもしれませんね。
UNIQUE関数 ちょっとだけ超応用例
もう少しハードルを上げたお題を最後に少しやって、今回は終わりにしましょう。
Q5. データ内で 重複している(2回以上登場する)データだけ 抽出したい

UNIQUE関数は 第3引数を TRUEとすることで、範囲内に1回しか登場しない、つまり重複がないデータだけを取り出すことができました。
では逆に、範囲内に2回以上登場する重複があるデータを取り出すにはどうすればよいでしょうか?(実は UNIQUE関数だけで出来ちゃいます)
ばなな 沖縄県
めろん 北海道
めろん 熊本県
みかん 和歌山県
りんご 長野県
りんご 青森産
めろん 茨城県
ばなな 沖縄県
ばなな 沖縄県
りんご 青森産
めろん 北海道
めろん 茨城県
りんご 長野県
ばなな 沖縄県
みかん 和歌山県
ばなな 鹿児島県
りんご 青森産
みかん 愛媛県
みかん 和歌山県
みかん 愛媛県こちらのデータを A1以下に貼って 式を作ってみましょう!
↓↓
ここから回答です。
↓↓
A5. データ内で 重複している(2回以上登場する)データだけ 抽出する
UNIQUE関数だけで実現する方法、それは!
=UNIQUE({UNIQUE(A1:B20);UNIQUE(A1:B20,,1)},,1)

え?UNIQUE関数を3回も使うの??って感じですね。
でも、複数列のデータの重複チェックは UNIQUEが圧倒的に便利なんで、これがたぶん一番短い式じゃないかなと。
考え方としては

こんな感じで処理しています。頭がこんがらがりそうですねw
={UNIQUE(A1:B20);UNIQUE(A1:B20,,1)}
UNIQUEで 一意にしたデータとUNIQUEの第3引数を1として、重複のないデータを縦に連結させる
▼
すると元データで重複がなかったデータだけが重複する(2回登場する)データになる
▼
=UNIQUE({UNIQUE(A1:B20);UNIQUE(A1:B20,,1)},,1)
これを再度 UNIQUEの第3引数1設定で重複がないデータを取得すると、元データで重複があったデータだけが残る
ちなみに 対象の範囲に 重複がない値が1つもない と
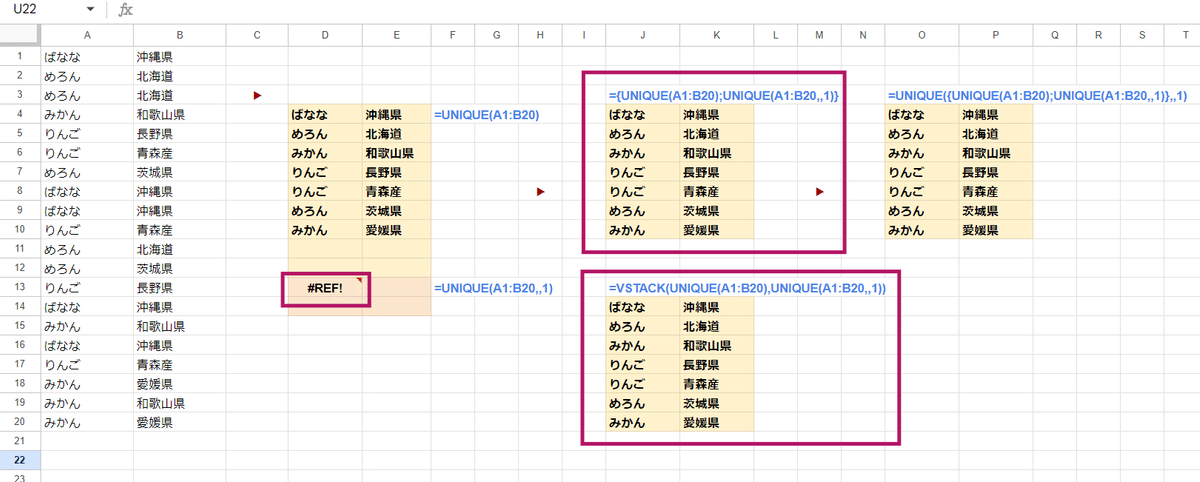
=UNIQUE(A1:B20,,1) は #REF!エラーを返しますが、これは中カッコやVSTACKで連結すると なにも無かったことになります。
よって 上の式は このケースでもエラーとならず、重複があるものを全て返すことができます。
これは Googleスプレッドシートのみで使える技です。
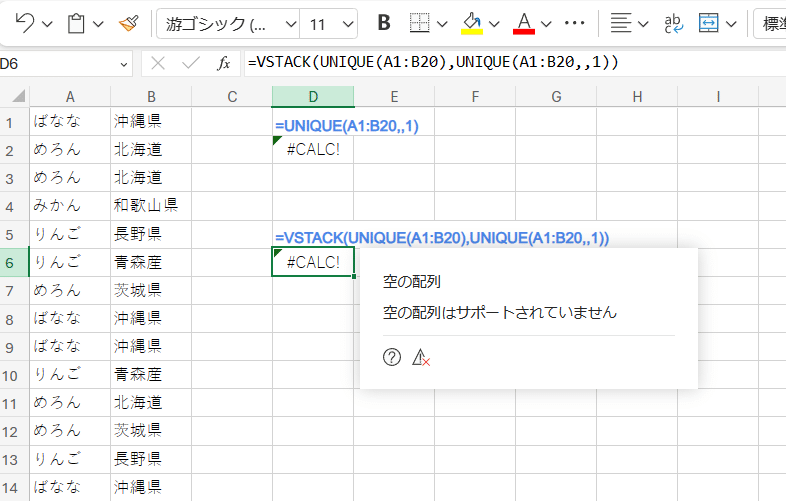
Excelの場合、範囲に重複がないデータが1つもない場合 =UNIQUE(A1:B20,,1) は #CALC! エラーを返し、これはVSTACKで連結してもエラーのままとなります。残念。
細かい解説は割愛しますが、一応他の方法も紹介しておきます。

=LET(a,A1:B20,FILTER(a,COUNTIFS(INDEX(a,,1),INDEX(a,,1),INDEX(a,,2),INDEX(a,,2),ROW(a),"<="&ROW(a))=2))
こんな式や
=UNIQUE(FILTER(A1:B20,LET(t,BYROW(A1:B20,LAMBDA(r,TEXTJOIN("_",,r))),COUNTIF(t,t)>1)))
こんな式もありますが、どっちも厳密な比較ではないですし式も長くてイマイチですね。
Q6. Googleスプレッドシートで厳密ではない ゆーるいユニーク処理がやりたい
UNIQUE関数の厳密一致判定は非常にありがたいのですが、状況によっては表記のゆれを吸収できる ゆるーい一致でユニーク処理したいって場合もあります。

では、このゆるーい一致判定のユニーク処理をするには、どのような関数を使えばよいでしょうか?
moonchild
MOONCHILD
moonchild
アイマス
ヒロアカ
ヒロアカ
あいます
アイマス
ひろあか
MoonChild
ぁぃます
MOONCHILDこちらのデータを対象として、これが ユニーク処理で3つの要素にまとまる式をくんでみてください。
やってみましょう!
↓↓
ここから回答です。
↓↓
A6. Googleスプレッドシートで厳密ではない ゆーるいユニーク処理をする
正攻法というか 一般的な解法はFILTER関数を使う方法です。
=LET(a,A2:A13,FILTER(a,COUNTIFS(a,a,ROW(a),"<="&ROW(a))=1))

この COUNTIFSの式は 登場回数の累計を出力する式です。

このように COUNTIFSの緩い一致判定で 登場回数の累計が 1のものだけを抽出することで、ゆるい UNIQUE関数を実現しています。
ただ、この式だと式が長く複雑な上に、複数列で ユニーク判定をする場合ケースだと対応が難しいです。
また、COUNTIFSは 範囲と配列で 一致判定が変わるという不確定要素もあります。(これについては、また改めて どっかのタイミングで note書きます)
Googleスプレッドシートの ひらがな、カタカナ、全角、半角を一致とみなされるゆるーい判定のせいで、COUNTIF、SUMIFなどの集計がうまくいかない。
— mir (@mir_for_note) April 27, 2024
こんな時、実は 範囲を { } で括って配列にすることで、なぜか判定がExcelと同じ程度に厳密になります。(大文字小文字は同一とされる)
ふしぎー pic.twitter.com/dkvpv5Jbjg
では、ゆるーい ユニーク処理をするには どんな式がベストなのか? その回答がこちらです。
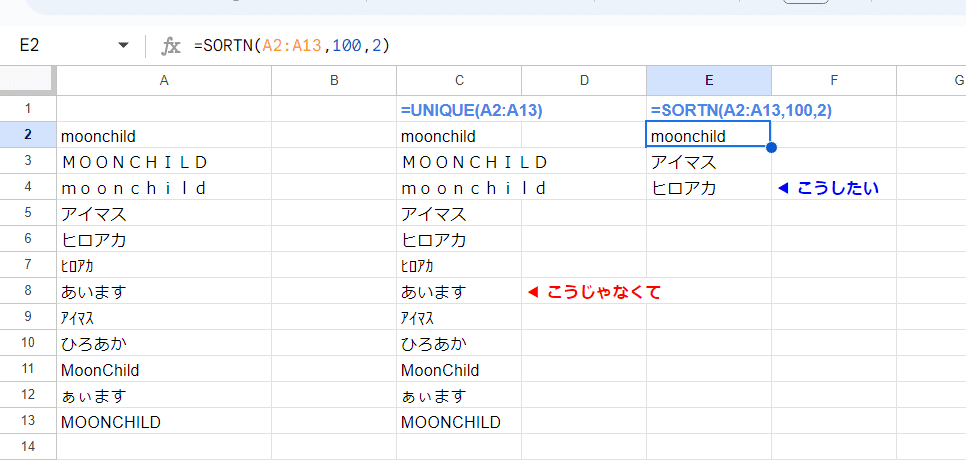
=SORTN(A2:A13,100,2)
でました! Googleスプレッドシートにしかない SORTN関数です。
SORTN関数は 第3引数で 2を指定することで、重複排除モードになるんですが、第2引数に結果の行数と同等の十分な数値(適当に100などの 元データの行数以上でOKI)の数値を入れ、第4引数以降を省略すると、ゆるい一致判定のUNIQUE関数 + SORT関数 のような挙動となるのです。
第2引数をちゃんと書くと
=SORTN(A2:A13,ROWS(A2:A13),2)
こうなります。
並び順は 1列目から順に優先キーとして 昇順となりますが、
ゆるい一致判定のUNIQUE関数 ≒ SORTN関数 第3引数2指定
と言えるんじゃないでしょうか。
もちろん 複数列データでも
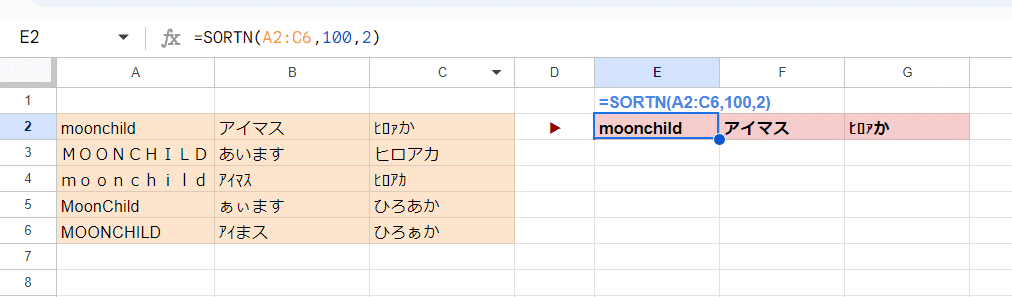
このように、ゆるい判定で一意の行にユニーク処理されます。
厳密判定の ユニーク処理 ・・・ UNIQUE関数
ゆるーい判定のユニーク処理 ・・・ SORTN関数
どちらも便利なので、ケースによって使い分けましょう!
もちろん 上記のような表記のゆれを気にしなくて良いデータなら、
UNIQUE + SORT 関数の処理を SORTN関数で一発処理することも可能です。

次回は UNIQUE関数 の代替方法や 派生関数、超応用例を
長くなったので今回はここまでとします。
次回は今回触れなかった Googleスプレッドシートで UNIQUE関数以外の 一意の値にする方法、そして UNIQUE関数の派生関数である
COUNTUNIQUE関数
COUNTUNIQUEIFS関数
について、そして UNIQUE関数の超応用例の続きを書きたいと思います。
この記事が気に入ったらサポートをしてみませんか?