
Googleスプレッドシート UNIQUE関数 超応用例 3 - QUERY関数では出来ない集計にはコレ!

UNIQUE関数シリーズの3回目です。
UNIQUE関数シリーズ前回の note ↓
シリーズの最後になる今回は、UNIQUE関数と〇〇IF(〇〇IFS)関数を組み合わせた「集計」での超応用例、そしてUNIQUE関数の特性である行単位での厳密な一致を使った 超応用例を取り上げていきます。
前回はUNIQUE関数を 1週お休みして、Googleスプレッドシートの一致の緩さと対応策を紹介した「COUNTIFやSUMIFS、FILTER関数を(割と)厳密な一致判定に切り替える{魔法}」という note を書きました。
UNIQUE関数を集計で活用する
UNIQUE関数の 一意の値にする処理は、数式で データからピボットテーブルのような集計表を生成する時に使えます。
Excelの場合は 集計でUNIQUE関数を SUMIFSなどの集計関数と組み合わせる方法がポピュラーですが、実はQUERY関数のある Googleスプレッドシートでも QUERY関数では対応出来ない集計をする場合に UNIQUE関数を使う方法が活躍します。
お題形式で理解していきましょう!
Q1. A列の名前 ごとの登場回数(いくつあるか)を集計したい
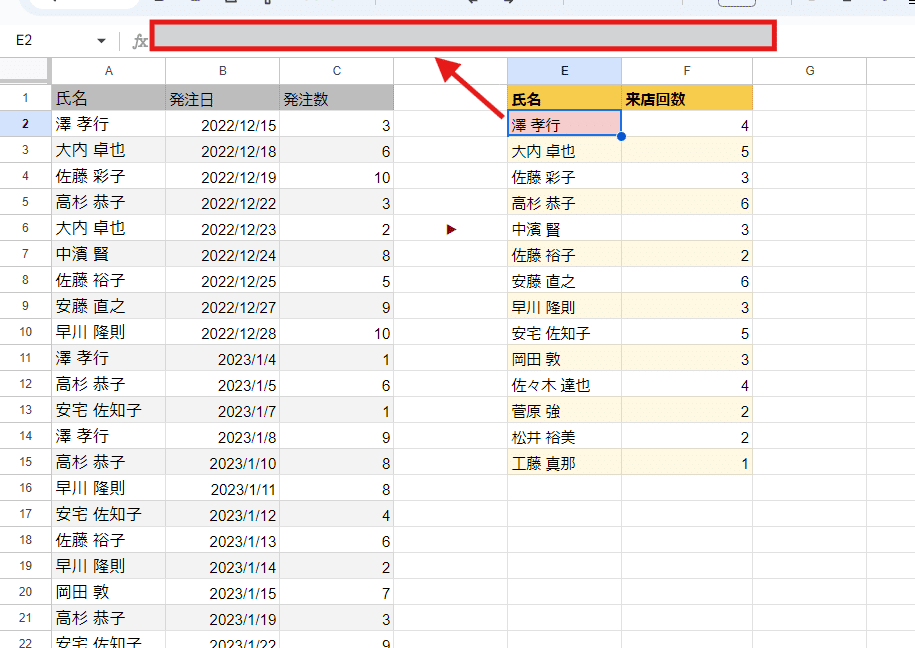
たとえば、A列 氏名、B列 発注日、C列 発注数 のような 簡易的な販売データがあったとします。
このデータから 「お客様(氏名)ごとの来店回数(リピート数)を集計したい。」(E:F列のような表を出力したい)
こんな時、どのような式を組めば良いでしょうか?
ピボットテーブルを使う方法 や QUERY関数を使う方法もありますが、今回は
氏名の並び順は 元データの中の登場する順番 のままとしたい
という制約を付けておきましょう。
これがあると集計の際に並び替えされてしまう ピボットテーブルやQUERY関数で集計することが難しくなります。
また見出し行の E1:F1は 入力されているものとして、
式は E2 にのみ入れる(1つの式)
元データは増える可能性があるので 対象範囲を A2:A とする
これらを追加条件とします。
データはコチラをご利用ください。
氏名 発注日 発注数
澤 孝行 2022/12/15 3
大内 卓也 2022/12/18 6
佐藤 彩子 2022/12/19 10
高杉 恭子 2022/12/22 3
大内 卓也 2022/12/23 2
中濱 賢 2022/12/24 8
佐藤 裕子 2022/12/25 5
安藤 直之 2022/12/27 9
早川 隆則 2022/12/28 10
澤 孝行 2023/1/4 1
高杉 恭子 2023/1/5 6
安宅 佐知子 2023/1/7 1
澤 孝行 2023/1/8 9
高杉 恭子 2023/1/10 8
早川 隆則 2023/1/11 8
安宅 佐知子 2023/1/12 4
佐藤 裕子 2023/1/13 6
早川 隆則 2023/1/14 2
岡田 敦 2023/1/15 7
高杉 恭子 2023/1/19 3
安宅 佐知子 2023/1/22 9
澤 孝行 2023/1/23 7
安宅 佐知子 2023/1/25 1
安藤 直之 2023/1/27 4
佐藤 彩子 2023/1/28 5
佐々木 達也 2023/1/29 7
高杉 恭子 2023/1/30 3
菅原 強 2023/2/1 7
松井 裕美 2023/2/2 3
大内 卓也 2023/2/4 10
安藤 直之 2023/2/6 7
安藤 直之 2023/2/7 5
大内 卓也 2023/2/8 5
佐々木 達也 2023/2/9 10
岡田 敦 2023/2/10 6
中濱 賢 2023/2/11 8
安宅 佐知子 2023/2/13 2
松井 裕美 2023/2/14 2
工藤 真那 2023/2/15 10
中濱 賢 2023/2/16 1
佐々木 達也 2023/2/17 9
岡田 敦 2023/2/19 1
安藤 直之 2023/2/23 8
高杉 恭子 2023/2/24 4
佐々木 達也 2023/2/26 1
大内 卓也 2023/2/28 6
安藤 直之 2023/3/3 10
菅原 強 2023/3/4 4
佐藤 彩子 2023/3/6 9コピーして、A1セルに貼ればOK。
※氏名は 個人情報テストジェネレーター を使って作成しています。
集計の基本ですが、少し難しいかもしれません。
じっくり考えてみましょう!
↓↓
ここから回答です。
↓↓
A1. A列の名前 ごとの登場回数(いくつあるか)を集計する
考え方を解説しながら回答していきましょう。

昔はこの部分 を手動で用意してたんですね。名前ごとなので A列を一意にする必要があります。早速UNIQUE関数の出番ですね!
ただし、単純に UNIQUE(A2:A) としてしまうと、空白まで出力してしまうのでNGです。
これは UNIQUE関数シリーズの1回目で触れました。
空白を除いて一意の値にするには、1列データの空白を簡単に除去できる TOCOL関数を組み合わせます。
UNIQUE(TOCOL(A2:A,1))
TOCOL関数は 範囲・配列を 1列データとする関数ですが、第2引数を指定することで 空白除去やエラー除去が出来るのが便利です!
この式で以下のように 一意の氏名データを得ることができました。

1つの式という制限がなければ、F2セルに ARRAYFORMULA と COUNTIF を組み合わせた式を入れれば完成なんですが、今回は E2 の一つの式で完結したいので、一旦この UNIQUE関数の結果を a とおきましょう。
ここで使えるのが LET関数です。
=LET(a,UNIQUE(TOCOL(A2:A,1))
※この段階はカッコを閉じてない状態の不完全な式です
次に 元データ 氏名の範囲 A2:A 内に、a(ユニークな氏名)の個々の値と一致するものが、それぞれ幾つあるかをカウントしたいので、
ARRAYFORMULA(COUNTIF(A2:A,a))
こんな式を作ります。
条件の a が配列(複数の値)なので、各々のCOUNTIFの結果を得る配列処理をする為に ARRAYFORMULAが必要になります。

この式の結果を bと置いておきましょう。
=LET(a,UNIQUE(TOCOL(A2:A,1)),b,ARRAYFORMULA(COUNTIF(A2:A,a))
氏名を一意の値とした a、A2:A内 に a の各要素が幾つかるかをCOUNTIFで取得した結果 b、これを最後に横に連結すれば良いですね。
{ a , b }
HSTACK関数を使ってもよいですが、Googleスプレッドシートは 中カッコによる連結が簡単です。

というわけで最終的な式は
=LET(
a,UNIQUE(TOCOL(A2:A,1)),
b,ARRAYFORMULA(COUNTIF(A2:A,a)),
{a,b}
)
このようになります。
少し難しいかもしれませんが、LET関数があれば 一つ一つ進められるので、LET関数以前のネストしまくりの式に比べれば、だいぶ解読しやすくなったんじゃないでしょうか?
ちなみに 回数が多い順にしたい場合は、最後に SORT関数を組み合わせて対応できます。
SORT({a,b},2,0)

QUERY関数を使う方法とその弱点
Googleスプレッドシートを普段から活用している方ならご存じかと思いますが、当然この手の集計なら QUERY関数を使うことが多いです。
回数で並び替えたいって場合も、SORT関数不要でQUERY関数一発で終わります。

=QUERY(A:A,"select A,count(A) where A is not null group by A order by count(A) desc label count(A) '来店回数'",1)
UNIQUE関数の データの一意化 ・・・ group by
COUNTIF関数の登場回数の集計 ・・・ count(A)
SORT関数の回数が多い順の並び替え ・・・ order by
さらに見出し行設定 ・・・ label
うーん、QUERY関数が最強と言われるわけですw
ただ、冒頭で書いた通り QUERY関数は group by を使うと 特に並び順の指定をしない場合は、一意化した列の昇順で並び替えされてしまうという仕様があります。

さらに QUERY関数の 並び順は ユニーコード値を基準としている為、対象列が「漢字」のデータだった場合は、意味不明の並び順となる弱点もあります。
「元データで登場する順番を保持したい」(このような要件は少ないと思いますが)という場合は、QUERY関数ではなく UNIQUE関数を他の集計関数と組み合わせた方が良い場合もあるってことですね。
ExcelのUNIQUE関数を使った集計の式
Googleスプレッドシート以上に、UNIQUE関数を使った集計式を使う機会が多いのがExcelです。

しかし Googleスプレッドシートと Excelでは 同じ関数がなかったり、同じ関数でも挙動が違ったりするので、そのまま Googleスプレッドシートの式が使えるわけではありません。
=LET(
a,UNIQUE(TOCOL(A2:A,1)),
b,ARRAYFORMULA(COUNTIF(A2:A,a)),
SORT({a,b},2,0)
)
たとえば、最後に回数が多い順に並べたGoogleスプレッドシートの ↑ の式を Excelにおきかえると
=LET(
_a,DROP(TOCOL(UNIQUE(A:A),1),1),
_b,COUNTIF(A:A,_a),
SORT(HSTACK(_a,_b),2,-1)
)
こんな感じになります。
■Googleスプレッドシートの式をExcelに変換する際のポイント
・A2:Aという指定が出来ないので、A:Aとして1行目をDROP関数で除外
・LETで a と定義すると COUNTIF(A:A,a) がエラーになる。_aとアレンジ
・最新Excelは自動でスピルので ARRAYFORMULAは不要
・中カッコを使った 配列変数の横連結が出来ない。HSTACK関数を使用
・SORT関数の 昇順・降順は TRUE、FALSE(1 , 0 )ではなく、1, -1
DROP関数は Googleスプレッドシートに輸入されなかった便利関数です。そのうち追加されて欲しいもんです。
式の移行は 気にしないといけない点や ExcelならではGoogleスプレッドシートならではの関数や挙動の違いの理解が必要なんで、なかなか大変です。
プログラミングのコンバージョンに通ずるものがあるかもw(そこまでじゃないですが)
ただ、上の書き方は Googleスプレッドシートをこじらせた mirのような人の式の書き方です。
一般的なExcelユーザーだと、以下のような書き方が多いかなと。

このように元データをテーブル化(販売実績と名付ける)して、
=UNIQUE(販売実績[氏名])
構造化参照で 氏名データの列範囲を取得することで、空白除去や見出しの考慮が不要となり、すっきりした式を書くことができます。
さらに並び替えの必要がなければ、
=COUNTIF(販売実績[氏名],F2#)
F2# のようなスピル演算子を使うことで、一意の氏名データの増減があっても可変で対応することが出来るので、式を分けて書くこともできます。
最後に並び替えたい場合は、LETとHSTACKで一つの式にまとめて
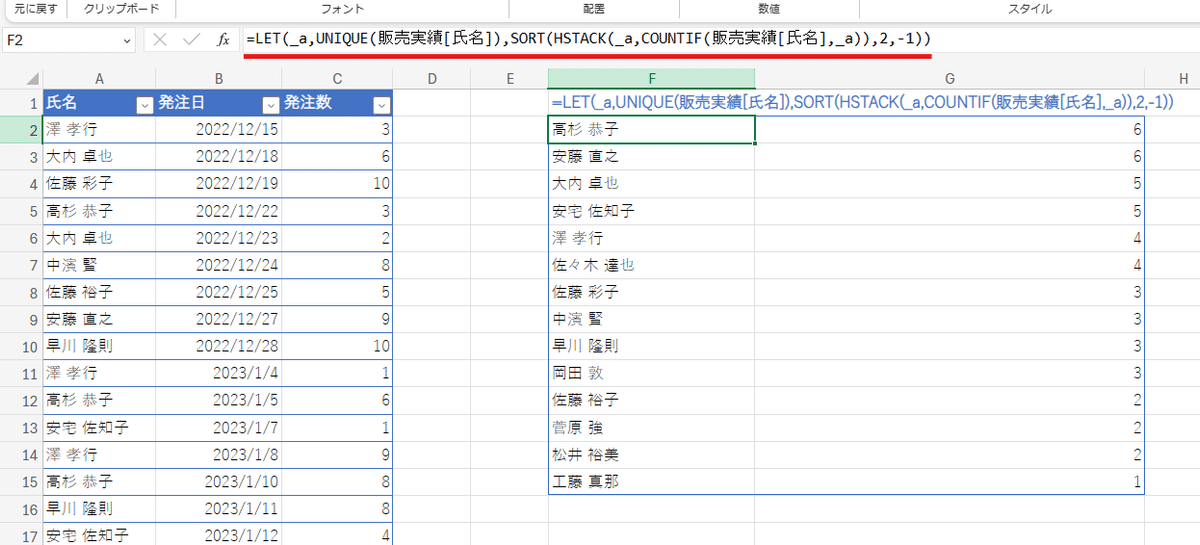
=LET(_a,UNIQUE(販売実績[氏名]),SORT(HSTACK(_a,COUNTIF(販売実績[氏名],_a)),2,-1))
こんな感じでしょうか。
2024年5月現在、Excelのテーブル機能やスピル演算子に該当するものは Googleスプレッドシートにはありません。
ただし、テーブル機能はGoogleスプレッドシートに導入予定と発表されています。
一方、Excelには GoogleスプレッドシートのQUERY関数に該当する関数はありませんが、将来的に GROUPBY関数、PIVOTBY関数という強力な集計関数の追加が計画されています。(既に先行ユーザーは利用してる)
どちらも楽しみですね!
Q2. A列の名前と B列の日付、C列の発注数から 人毎、年毎の発注数をピボット集計したい

では、もう少し難しいお題ってことで Q1と同じデータを使って、今度は画像のように 氏名と発注日の年で発注数をピボット集計したい時は、どのような式を組めばよいでしょうか?
もちろんQUERY関数を使わずに、範囲はお尻を決めずに(A2:A、B2:B、C2:Cという指定)という縛りです。
あと、年はどうしても「年」を付けたいという要望。
ちょっと難しいというか、面倒な式ですが興味ある人はやってみましょう!(本来これは、ピボットテーブルかQUERY関数を使った方がよいお題です)
↓↓
ここから回答です。
↓↓
A2. A列の名前と B列の日付、C列の発注数から 人毎、年毎の発注数をピボット集計する式
今回も考え方を解説しながら回答していきましょう。
まず集計の縦軸と横軸を作っていきます。

縦軸は Q1と一緒ですね。
UNIQUE(TOCOL(A2:A,1))
今回はこれを 列なんで LET関数で c と置くことにしましょう。
横軸の 年ですが、これはなかなか悩ましいかもしれません。
YEAR関数で YEAR(B2:B)&"年" としてもいいんですが、今回はTEXT関数で TEXT(B2:B,"YYYY年") としましょう。
配列処理のための ARRAYFORMULAが必要となります。

しかし、YEAR関数にしろTEXT関数にしろ 空白を 0 (シリアル値0は Googleスプレッドシートの場合は 1899年12月30日)として扱ってしまう為、空白セルは1899年が返ってしまいます。
これを回避する為には、TEXT関数に渡す前に空白除去した方が良さそうですし、縦並びではなく最終的に横並びにする必要があるので、、、
今回は TOROW関数を使って 空白除去 + 横方向に変換してから UNIQUE関数の第2引数を TRUE(1)と指定することで、横方向のユニーク処理をしましょう。
=ARRAYFORMULA(UNIQUE(TEXT(TOROW(B2:B,1),"YYYY年"),1))
こんな式になりました。

縦軸、横軸が用意できたので、いよいよ中身の集計部分です。
集計部分は今回は発注数の合計なんで、SUMIFS関数を使うのが良さそうですね。
いきなり配列で考えるのではなく、わかりやすいように 一度出力した 縦軸、横軸データを範囲として使うと考えてみましょう。
表の中身の一番左上のF2セルに

=ARRAYFORMULA(SUMIFS($C$2:$C,$A$2:$A,$E2,TEXT($B$2:$B,"YYYY年"),F$1))
こんな式を入れて右と下にフィルすればOK。
発注年の一致を判定するのに B2:Bを TEXT関数で 〇〇年に変換した配列を使いたいので ARRAYFORMULAを組み合わせています。
このSUMIFSをフィルせず 一つの式で書く、ここが実は 一番厄介なポイント化もしれませんw
SUMIFS関数はARRAYFORMULA関数でスピらない関数なので、ここはMAP関数を組み合わせた処理が必要になります。

=ARRAYFORMULA(LET(c,E2:E15,r,F1:G1,MAP(IF(r<>"",c),IF(c<>"",r),LAMBDA(cv,rv,SUMIFS(C2:C,A2:A,cv,TEXT(B2:B,"YYYY年"),rv)))))
かなり複雑になってきましたねw
後々のことを考えて一旦出力してますが、LET関数で 縦(氏名)を c、横(年)をrとおいて、MAP関数でSUMIFSをスピらせてるんですが、
MAP関数の式の冒頭を
MAP(IF(r<>"",c),IF(c<>"",r)
このように記述しています。
ここは何をやっているか?というと、欲しい結果と同じサイズの2つの配列を生成してMAP関数にわたしています。
1つ目の配列 IF(r<>"",c) は、c (氏名)を r(年)の長さ(列数)分繰り返した配列

2つ目の配列 IF(c<>"",r) は、 r(年)をc (氏名)の高さ(行数)分繰り返した配列

となっています。
この同じサイズの2つの配列から MAP関数で 同じ位置の値をそれぞれ一つずつ取り出して、それをcv、rvとして SUMIFSの条件に使用することで、SUMIFS関数をスピらせてるわけです。
この方法は 過去 noteでも紹介しております。
これでパーツは揃ったわけですが、最後の連結の際に注意点があります。
配列の連結は中カッコでやるにせよ、VSTACK関数、HSTACK関数を使うにせよ、縦横一気にはできません。
縦連結して横連結するか、横連結して縦連結する、このようにSTEPを踏んで処理することになります。
また、連結の際は基本的に
横に連結する場合は 上揃え
縦に連結する場合は 左揃え
となります。そこで問題になるのが

この左上の部分です。
たとえば先に 氏名 c と SUMIFSの結果(xと置く)を横連結して、その後 r(年)と縦連結しようとすると

このように 年が左にズレてしまいますし、そもそも結合面のサイズが違うので中カッコでは連結ができません。
これを解消する為に、縦結合前に rの方も 左側に空白(空文字)と横連結してから、最後に縦連結とする必要があるわけです。※"氏名"としてもよい

一つにまとめると

=ARRAYFORMULA(
LET(
c,UNIQUE(TOCOL(A2:A,1)),
r,UNIQUE(TEXT(TOROW(B2:B,1),"YYYY年"),1),
x,MAP(IF(r<>"",c),IF(c<>"",r),
LAMBDA(cv,rv,SUMIFS(C2:C,A2:A,cv,TEXT(B2:B,"YYYY年"),rv))),
{{"",r};{c,x}}
)
)こんな式になります。
ARRAYFORMULAは全体に配列効果を効かせたいので一番外側に置くのがよいでしょう。
なかなかヘビーな式ですね。。
こちらもQUERY関数を使えば

=QUERY(A:C,"select A,sum(C) where A is not null group by A pivot YEAR(B) label sum(C) '年'")
このようにQUERY関数のみで割とシンプルに書くことができます。
謎の並び順になる点と 0の部分が空白となってしまうのが気になりますがw
Q3. A列の名前ごとに 発注した商品がわかるように 横に展開したい
UNIQUE関数や他の関数が力を合わせて苦労して解決した集計表のお題が、最後に登場したQUERY関数が ワンパンで 秒殺しているのを見ると、なんともやるせない気持ちになりますねw
しかし QUERY関数だって万能ではないので、UNIQUE関数と他の関数を組み合わせた方が良い集計?もあります。

たとえば、少しアレンジしたC列に商品という列を加えたこんなデータがあった時に、右のように 人ごとに過去に発注したことのある商品(の一意のデータ)を横に出力したい。
こんな集計ともいえない集計をリクエストされた場合、QUERY関数での対応は難しくなってきます。
基本的にQUERY関数のgroup by や pivotは、集計関数(SUMやCOUNT 、MAXなど)と組み合わせて使う必要があります。
つまり、数値をまとめるわけではない 変則的な集計には使えません。
このケースに対応するには、UNIQUE関数と ゆかいな仲間たち関数が力を合わせる必要があります。
氏名 発注日 発注商品 発注数
澤 孝行 2022/12/15 いちご 3
大内 卓也 2022/12/18 りんご 6
佐藤 彩子 2022/12/19 りんご 10
高杉 恭子 2022/12/22 りんご 3
大内 卓也 2022/12/23 ばなな 2
中濱 賢 2022/12/24 りんご 8
佐藤 裕子 2022/12/25 いちご 5
安藤 直之 2022/12/27 ばなな 9
早川 隆則 2022/12/28 ばなな 10
澤 孝行 2023/1/4 ばなな 1
高杉 恭子 2023/1/5 ばなな 6
安宅 佐知子 2023/1/7 いちご 1
澤 孝行 2023/1/8 いちご 9
高杉 恭子 2023/1/10 めろん 8
早川 隆則 2023/1/11 めろん 8
安宅 佐知子 2023/1/12 いちご 4
佐藤 裕子 2023/1/13 めろん 6
早川 隆則 2023/1/14 めろん 2
岡田 敦 2023/1/15 めろん 7
高杉 恭子 2023/1/19 めろん 3
安宅 佐知子 2023/1/22 いちご 9
澤 孝行 2023/1/23 ばなな 7
安宅 佐知子 2023/1/25 りんご 1
安藤 直之 2023/1/27 いちご 4
佐藤 彩子 2023/1/28 めろん 5
佐々木 達也 2023/1/29 めろん 7
高杉 恭子 2023/1/30 りんご 3
菅原 強 2023/2/1 りんご 7
松井 裕美 2023/2/2 りんご 3
大内 卓也 2023/2/4 めろん 10
安藤 直之 2023/2/6 いちご 7
安藤 直之 2023/2/7 ばなな 5
大内 卓也 2023/2/8 ばなな 5
佐々木 達也 2023/2/9 めろん 10
岡田 敦 2023/2/10 いちご 6
中濱 賢 2023/2/11 ばなな 8
安宅 佐知子 2023/2/13 りんご 2
松井 裕美 2023/2/14 りんご 2
工藤 真那 2023/2/15 めろん 10
中濱 賢 2023/2/16 いちご 1
佐々木 達也 2023/2/17 ばなな 9
岡田 敦 2023/2/19 めろん 1
安藤 直之 2023/2/23 りんご 8
高杉 恭子 2023/2/24 いちご 4
佐々木 達也 2023/2/26 めろん 1
大内 卓也 2023/2/28 ばなな 6
安藤 直之 2023/3/3 りんご 10
菅原 強 2023/3/4 ばなな 4
佐藤 彩子 2023/3/6 いちご 9では、データとして上をコピーして、お題にチャレンジしてみましょう!
式を入れるのはF2セル1カ所のみです。
やってみましょう!

余裕がある人は 発注した商品の種類が多い人が上にきて、かつ商品の並びが整理されたデータに並び替える という条件も加えてチャレンジしてみてください!
↓↓
ここから回答です。
↓↓
A3. A列の名前ごとに 発注した商品がわかるように 横に展開する式
回答です。

=LET(c,UNIQUE(TOCOL(A2:A,1)),x,MAP(c,LAMBDA(cv,
TOROW(SORT(UNIQUE(FILTER(C2:C,A2:A=cv)))))),{c,x})
登場する関数は多いですが、そこまで難しくはないです。
UNIQUE(TOCOL(A2:A,1)) 今までと同じように最初に氏名をユニーク化+空白除去したデータを作成、これを cと置いて
MAP(c,LAMBDA(cv, Q2と同じように MAP関数を使って cから 一つひとつの氏名を cvとして取り出し
FILTER(C2:C,A2:A=cv) A列がcvと一致する C列のデータを FILTER関数で取得
UNIQUE(FILTER(C2:C,A2:A=cv)) それをUNIQUE関数で一意の値にして
SORT(UNIQUE(FILTER(C2:C,A2:A=cv))) SORTで並びをそろえて
TOROW(SORT(UNIQUE(FILTER(C2:C,A2:A=cv)))) 最後にTOROWで横1行にする
{c,x} で、最後に氏名と 結果を 横連結で完成です。
トリッキーな技もなく、面倒ですが割と素直な式かなと。(面白みはないかもしれませんがw)
最後のTOROWの部分を TEXTJOINに変えることで、カンマ区切りで氏名の右の列に出力、と言ったことも出来ます。

=LET(c,UNIQUE(TOCOL(A2:A,1)),x,MAP(c,LAMBDA(cv,
TEXTJOIN(",",TRUE,SORT(UNIQUE(FILTER(C2:C,A2:A=cv)))))),{c,x})

「余裕のある人は 商品の種類が多い人が上にくるように」とオマケお題を書きましたが、やってみた人はいますでしょうか?

幾つか方法はありますが、
BYROW(x,LAMBDA(r,counta(r)))
このように 行毎の 要素の数を BYROW関数を使って取得して、これをキーに降順で並び替え + 2列目の 商品の中の一番左の列を第2キーとして並び替えが割と簡単かなと。
=LET(
c,UNIQUE(TOCOL(A2:A,1)),
x,MAP(c,LAMBDA(cv,TOROW(SORT(UNIQUE(FILTER(C2:C,A2:A=cv)))))), SORT({c,x},BYROW(x,LAMBDA(r,counta(r))),0,2,1))
他には、BYROW関数の部分をMMULT関数に置き換えるなんてのも通好みですね。
=LET(
c,UNIQUE(TOCOL(A2:A,1)),
x,MAP(c,LAMBDA(cv,TOROW(SORT(UNIQUE(FILTER(C2:C,A2:A=cv)))))),
SORT({c,x},MMULT(--(x<>""),SEQUENCE(COLUMNS(x))^0),0,2,1))
また、UNIQUE関数シリーズの2回目に登場した COUNTUNIQUEIFSを使う方法もありますが、
=LET(
c,UNIQUE(TOCOL(A2:A,1)),
x,MAP(c,LAMBDA(cv,TOROW(SORT(UNIQUE(FILTER(C2:C,A2:A=cv)))))),
y,MAP(c,LAMBDA(cv,COUNTUNIQUEIFS(C2:C,A2:A,cv))),
SORT({c,x},y,0))
MAP2回でちょっと式が長くなっちゃいますね。
いぜれにせよ、こういった合計や個数、平均値ではない 文字列を出力するような集計の場合は、QUERY関数の出番ではありません。(無理すれば出来なくはないですが)
UNIQUE関数で 一意の 条件キーを用意した上で、MAPやBYROWなどのLAMBDAヘルパー関数で 式内で一つひとつ処理を回してFILTERやSORT、再度UNIQUEをしていく。
この手の集計では、こんな式が書けると便利です。
ちなみにExcelだと Q2は SUMIFSはスピルけど 条件範囲に配列がとれないし、Q3の方は MAPやBYROWの中で配列が返せないという制約があるんで難易度が高くなります。
集計での UNIQUE関数の超応用例でした。(UNIQUE関数以外の部分が難解だったような気もしますが・・・)
UNIQUE関数を 厳密な行単位の一致判定で活用する
UNIQUE関数は「行単位」で厳密に一致を判定できる珍しい関数です。
この特性を使った超応用例を紹介していきましょう。
ここで活躍するのが UNIQUE関数の第3引数 「重複なし」(英語名 exactly_once)です。
※イグザクトリーワンス って厨二ワードっぽくていいですね
行単位の一致で UNIQUE関数を使う方法

たとえば 画像のような 横並び4つで一組(4列1行)の Aというデータ、Bというデータ があった場合、この2つの行が一致しているかどうかを判定する為には、どのような式を書けばよいか?(並び順も一致している必要があります)
=AND(A2=A6,B2=B6,C2=C6,D2=D6)
もちろん、考え方としてはこれなんですが、これだと一つ一つ式を書いてるので手間がかかる上に汎用性がありません。
ここは

=ARRAYFORMULA(AND(A2:D2=A6:D6))
このように書けます。
でも、前回も登場しましたが この Googleスプレッドシートのイコール一致は ひらがな・カタカナ、全角・半角 などを区別しない緩い一致判定です。
これを厳密に判定するには
=ARRAYFORMULA(AND(EXACT(A2:D2,A6:D6)))
このように EXACT関数で判定した結果を最後に AND関数で全てTRUEか判定する式になります。
しかし、今回のテーマであるUNIQUE関数を使った解法もあります。

1つがUNIQUE関数の 行単位で重複したものを一意にする特性を使った
=ROWS(UNIQUE({A2:D2;A6:D6}))=1
この式。
比較するデータ(行)を縦に連結して一つの配列とし、UNIQUE関数に入れ ROWS関数で行数を取得することで
重複していない → 2行
重複している → 1行
このような結果を返すことを利用しています。
UNIQUE関数を使ったもう一つの方法が
=NOT(ROWS(UNIQUE({A2:D2;A6:D6},,1)))
第3引数 TRUE(1)を使う方法です。
こちらも 比較するデータ(行)を縦に連結して一つの配列とし、UNIQUE関数に入れて ROWSで行を取得するところまでは一緒なんですが、UNIQUE関数で 真に1回しか登場しない(重複の無い)行だけを返すことで、
重複していない → 2行 → NOTで反転して FALSE
重複している → 0行 → NOTで判定して TRUE
としています。
1番目の方法が簡単に見えますが、実は応用が効くのは2番目の方法です。
ケースを変えてお題形式で考えてみましょう。
Q4. 複数行のデータ内に 一致する行が存在するかを判定したい

では単体の行 Aと一致する行が 複数行の範囲Bに存在するか?これを判定する式を考えてみましょう。
素直に考えると
=ARRAYFORMULA(OR(BYROW(A6:D9,LAMBDA(r,AND(A2:D2=r)))))
BYROWを使って 行単位でAND条件で一致を比較して、最後に1つでも TRUEがあれば TRUEとなるように OR関数でまとめる式や
=COUNTIFS(A6:A9,A2,B6:B9,B2,C6:C9,C2,D6:D9,D2)>0
あまり汎用性はありませんが、ひたすら列単位でCOUNTIFSの条件を記述するこんな式が考えられます。
もし、ここで 「ひらがな・カタカナ」や「半角・全角」を同一と見なされる誤判定が出てしまう場合は、先週登場した{魔法}(配列化) が使えます。
=COUNTIFS({A6:A9},A2,{B6:B9},B2,{C6:C9},C2,{D6:D9},D2)>0
今回は、これをUNIQUE関数でやってみましょう!というお題です。
なお、組み合わせの一致ではなく並び順も含めた一致を想定しています。
データはこちら。
データA
りんご ばなな いちご めろんデータB
すいか ばなな なし ぶどう
みかん いちご めろん なし
りんご ばなな いちご めろん
いちご めろん ばなな りんご考えてみましょう!
↓↓
ここから回答です。
↓↓
A4. 複数行のデータ内に 一致する行が存在するかを判定する UNIQUE関数の式
回答です。大きく2通りあります。

1つ目が 普通に UNIQUE関数を使う式。
範囲B内での重複も考慮する必要があるので、こんな感じの式になります。
=ROWS(UNIQUE({A6:D9;A2:D2}))-ROWS(UNIQUE(A6:D9))=0
これは、重複データがある場合は UNIQUE({A6:D9;A2:D2})) とUNIQUE(A6:D9) は同じ行数となるけど、

重複データがない場合は UNIQUE({A6:D9;A2:D2})) は UNIQUE(A6:D9) よりも A2:D2 の分、データが1行増えることを使って判別しています。

もう1つは UNIQUE関数の第3引数を使って 重複なしのデータを抽出する方法。
=NOT(ROWS(UNIQUE({A2:D2;A6:D9;A6:D9},,1)))
このように書くことができます。
ポイントは
{A2:D2;A6:D9;A6:D9}
ここの部分。A6:D9 という範囲Bを 2つ縦につなげることで、 データBの方は必ず同じデータの行が2回以上はある状態になります。
これを UNIQUE関数の第3引数TRUE とすると全て重複アリで 消しこみされるわけですが、ここでさらに A2:D2を 連結すると
A2:D2 と 一致する行が A6:D9 に存在する ・・・ A6:D9 一緒に全て消える
▶ 出力されるデータの行数は0 (NOT反転で TRUE)
A2:D2 と 一致する行が A6:D9 に存在しない ・・・ A2:D2だけ残る
▶ 出力されるデータの行数は1 (NOT反転で FALSE)

→ これはROWSで行数を取得すると 0になる

この
UNIQUE({範囲A;範囲B;範囲B},,1)
というテクニックが以降の応用問題を解く上での基本となります。
そしてもう一つ活用すべきテクニックが UNIQUE関数の1回目に登場した、範囲内の重複する行(データ)だけを抽出する式
=UNIQUE({UNIQUE(A1:B20);UNIQUE(A1:B20,,1)},,1)
こちらです。
では、これらを使ったさらなる 超応用例にいってみましょう!
Q5. 2つのリストを比較して リストBと 重複している(重複していない)リストAのデータを抽出したい

上の画像のような リストA(A2:B)とリストB(E2:F)があった場合、リストBと重複する(一致する)リストAのデータを抽出したい。
また、逆にリストBと重複(一致)しないリストAのデータも抽出したい。
このような場合、どんな式を組めばよいでしょうか?
いよいよ、行単位での多対多の比較です。
ただし、どちらのリスト も行が増える可能性があるので、最終行を指定しない範囲(A2:B、E2:F)という範囲指定をするとします。
さらに 条件として、上のようにデータは英字となっているので、厳密な一致判定で アルファベットの大文字・小文字を区別したい。(bananaとBANANAは一致とみなさない)
こんなお題(超応用例)です。
データはこちら。
list A
BANANA OKINAWA
melon HOKKAIDO
melon KUMAMOTO
orange WAKAYAMA
apple NAGANO
Apple AOMORI
melon IBARAKI
banana OKINAWA
banana OKINAWA
りんご 青森産
melon IBARAKI
banana KAGOSHIMA
Apple NAGANO
BANANA OKINAWA
orange WAKAYAMA
MELON IBARAKI
apple AOMORI
orange EHIME
orange WAKAYAMA
orange EHIMElist B
banana OKINAWA
melon HOKKAIDO
MELON KUMAMOTO
melon EHIME
apple NAGANO
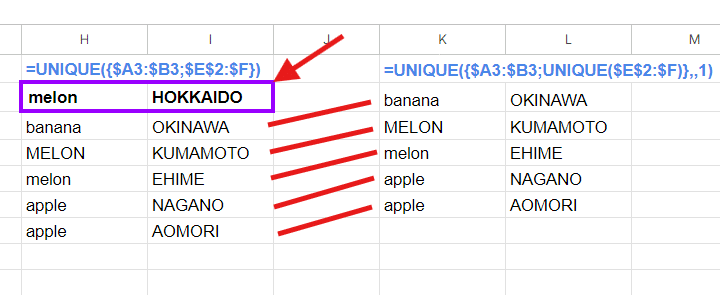
apple AOMORI英字の大文字・小文字を区別する必要があるので、先週登場した{魔法}、中カッコの配列化とCOUNTIFが使えません。
ここはEXACT関数で頑張る方法もありますが、UNIQUE関数をどう使うか?という方向性で 考えてみましょう!
↓↓
ここから回答です。
↓↓
A5. 2つのリストを比較して リストBと 重複している(重複していない)リストAのデータを抽出する式
回答です。

重複するデータ=LET(a,UNIQUE(A2:B),b,E2:F,x,UNIQUE({a;b;b},,1),UNIQUE({a;x;x},,1))
重複しないデータ
=LET(a,UNIQUE(A2:B),b,E2:F,UNIQUE({a;b;b},,1))
先に重複しないデータを考えた方がわかりやすいです。
LET関数で、リストAを UNIQUE(A2:B)で 一意のデータにしたものを a、リストBの E2:F を b と置きます。
で、 UNIQUE({a;b;b},,1)) こうすることで、bは 必ず2回以上登場するので、UNIQUE関数の第3引数 1(TRUE) 指定で 消滅するんですが、その際 aのデータがで bと重複するものがあると、巻き込まれて消滅することになります。

結果として bと重複しない aのデータ、つまり リストBと 重複していない リストAのデータを抽出することになるわけです。
一方、リストBと重複するデータをリストAのデータを抽出したい場合は、
この リストBと 重複していない リストAのデータ UNIQUE({a;b;b},,1)) を利用します。
これをさらに xとおいて UNIQUE({a;x;x},,1) とすることで、
リストBと 重複していない リストAのデータ xと一致しない aのデータ
▼ つまり
リストBと一致する(重複する) リストA のデータ
を取得することが出来るわけです。
なかなか複雑なんで、しっかり手元で自ら式を組んで理解をしましょう。
Q6. 条件付き書式で 厳密な判定で行の一致を判断し、リストB内の行と一致する行がリストAにあった場合に色付けしたい

では次に 条件付き書式のお題をやってみましょう。
先ほどと同じリストA、リストBで、同じく 最終行を指定しない範囲とした上で、
リストAの行(データ)が、リストBのいずれかの行(データ)と一致する(重複する)場合、リストAの行(データ)に色をつけたい。
この時、条件付き書式でどのようなカスタム数式を組めばよいでしょうか?(UNIQUE関数を使う方法で考えよう)
やってみましょう!(データは Q5 のものがそのまま使えます)
↓↓
ここから回答です。
↓↓
A6. 条件付き書式で 厳密な判定で行の一致を判断し、リストB内の行と一致する行がリストAにあった場合に色付けするカスタム数式
回答です。UNIQUE関数を使ったやり方が2つあります。

=AND($A2:$A<>"",NOT(ROWS(UNIQUE({$A2:$B2;$E$2:$F;$E$2:$F},,1))))
一つ目は Q4で登場した式をベースとした
NOT(ROWS(UNIQUE({$A2:$B2;$E$2:$F;$E$2:$F},,1)))
という式を使う方法。
この式で リストBと一致(重複)する リストAの行は TRUEとなります。

ただし、空白行も TRUEとなってしまう為、$A2:$A<>"" という条件を追加して AND関数で 両方を満たすものをTRUEとして条件付き書式適用させています。
=AND($A2:$A<>"",NOT(ROWS(UNIQUE({$A2:$B2;$E$2:$F;$E$2:$F},,1))))
もう一つが2回以上登場する(重複する)データだけをUNIQUEで取り出す式を応用した
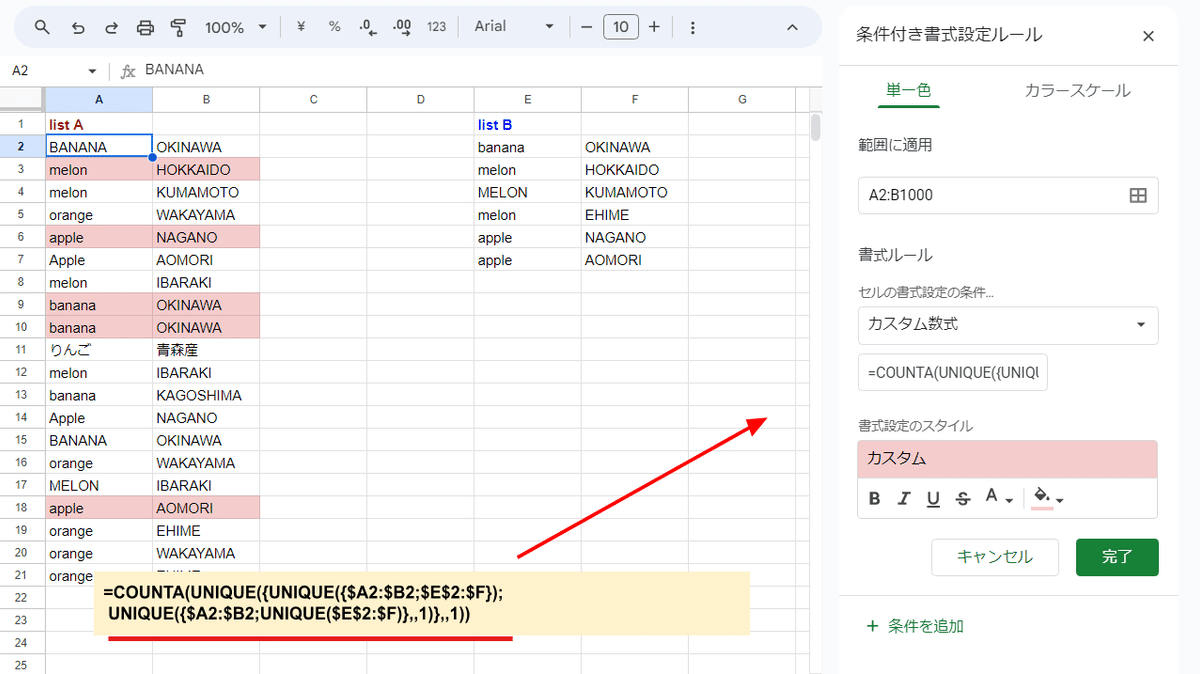
=COUNTA(UNIQUE(
{UNIQUE({$A2:$B2;$E$2:$F});UNIQUE({$A2:$B2;UNIQUE($E$2:$F)},
,1)},,1))
こちらの式を カスタム数式に使う方法。
UNIQUE関数のフルコース(晩餐歌)ですねw
なにをやっているか?というと、条件付き書式のカスタム数式は 自動で 配列処理がなされるので、
例えばリストAの3行目の処理の場合
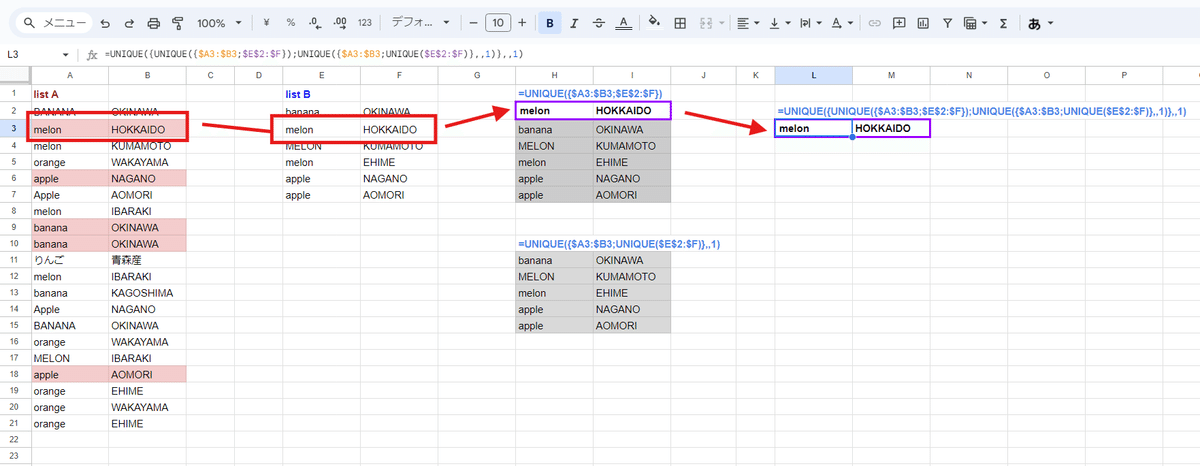
=UNIQUE({$A3:$B3;$E$2:$F})
こちらで、まず リストAの 3行目とリストBを結合させてユニークなデータを取得し
=UNIQUE({$A3:$B3;UNIQUE($E$2:$F)},,1)
さらにこの式で リストBのユニークなデータとリストAの3行目を連結させた上で真の一意のデータを取得することで、
リストAの3行目と重複する行(データ)がリストBに存在する
→ =UNIQUE({$A3:$B3;$E$2:$F}) が
=UNIQUE({$A3:$B3;UNIQUE($E$2:$F)},,1) より
1行多くなる(リストA 3行目の分)
リストAの3行目と重複する行(データ)がリストBに存在しない
→ =UNIQUE({$A3:$B3;$E$2:$F}) と
=UNIQUE({$A3:$B3;UNIQUE($E$2:$F)},,1) が
同じ行数になる
このような差を生ませています。
これを 2つの行数の差をとってもいいんですが
=ROWS(UNIQUE({$A2:$B2;$E$2:$F}))-ROWS(UNIQUE({$A2:$B2;UNIQUE($E$2:$F)},,1))
これだと 空白行も 1(TRUE)になってしまい最初の回答と同じような感じで芸がありません。
そこで、この2つをさらに連結してUNIQUE関数で 真のユニークを取得することで

UNIQUE({UNIQUE({$A2:$B2;$E$2:$F});UNIQUE({$A2:$B2;UNIQUE($E$2:$F)},,1)},,1)
リストBにあるデータと一致する行だけ残し、さらに空白行もカウントしてしまうROWS関数ではなく、空白を数えない COUNTAを使うことで 空白行の場合は 0(FALSE)とする判定にしています。
=COUNTA(UNIQUE({UNIQUE({$A2:$B2;$E$2:$F});UNIQUE({$A2:$B2;UNIQUE($E$2:$F)},,1)},,1))
当然ですが、条件付き書式のカスタム数式なので 絶対参照も重要です。
UNIQUE関数を使った 行単位での厳密な一致を FILTER関数で使う

少し長くなってしまったのと、ほぼ方法は同じなんで お題ではなく解説のみとしますが、UNIQUE関数を使った行単位の 厳密な一致は 条件付き書式だけではなく、FILTER関数でも活用できます。
たとえば、重複チェックは2列だけど A2:C の3列を抽出したいといった場合は、UNIQUE関数だけでは不可能なので FILTER関数と組み合わせる必要があります。
さらに UNIQUE関数は ARRAYFORMULAが効かない 関数なので、FILTER関数内で使う場合、BYROWと組み合わせて リストAの方を1行ずつ取り出し UNIUQEによる一致判定をしていくことになります。
リストBと重複するデータ(行)を抽出
=FILTER(A2:C,BYROW(A2:B,LAMBDA(r,COUNTA(UNIQUE({UNIQUE({r;E2:F});UNIQUE({r;UNIQUE(E2:F)},,1)},,1)))))
リストBと重複しないデータ(行)を抽出
=FILTER(A2:C,BYROW(A2:B,LAMBDA(r,ROWS(UNIQUE({r;E2:F;E2:F},,1)))))
こんな式で対応できます。
UNIQUE関数の行単位の厳密な一致判定を活用した 超応用例でした。
四天王 UNIQUE関数 もついにクリア・・・残るは!
さて、途中で関連ネタを挟みましたが 全3回の UNIQUE関数も終了です。
ついにUNIQUE関数もクリアして
配列系関数 四天王も 残るは QUERY関数のみ。
今回もそうでしたが、FILTER関数やSORT関数の回でも 圧倒的な力を見せつけてきた 魔王 QUERY関数。
早く取り上げたいと思いつつも「今のお前の力では QUERY関数には勝てん!」って感じもするんで、なかなか手をつけられておりませんw
気合が乗ったら頑張って書きたいと思います!
次回は、前にnote書いた時から 結構変更があった フィルタ表示(フィルタビュー)の続き(補足)を書こうかなと。
この記事が気に入ったらサポートをしてみませんか?