
【LAMBDA】Googleスプレッドシート新関数 検証 -3 REDUCE / SCAN

これは本編のシリーズネタとは別で、旬の話題や Googleスプレッドシート、GoogleWorkspace関連でランダムに気になったことを書いていく 雑談記事です。といいつつ、こっちの方が最新ネタだからか人気ですが。。
可能な範囲で、土日に新しい記事を出していこうかなと思います。
↓前回(先週)の記事
【LAMBDA / XLOOKUP】Googleスプレッドシート新関数 検証 -2
2022年9月から使えるようになった LAMBDA関数とヘルパー関数。
前回は、LAMBDA の6つのヘルパー関数の中の配列系 MAP,MAKEARRAY について書きました 。
今回はヘルパー関数 最後、累積系の REDUCE,SCANを解説していきます。
累積系ヘルパー関数 の基本を理解する

今回は長くなりそうなので、早々に本題に入りましょう。
また、REDUCEとSCANは 式の基本構成は 同じ型ですし、REDUCEの処理動作を説明するには SCANで可視化させるのがわかりやすいので、2つ合わせて説明していきます。
アキュムレーターってなんだ?
GAS や javascriptを使う人なら、配列を処理するメソッドの一つである REDUCEは知っている(聞いたことはある)人も多いでしょう。ただ、 RDUCEは 知ってるけど使いこなせない、もしくは苦手という人も多いかと思います。
同じArray系メソッドでも、map や forEach、Filterなんかは比較的わかりやすいんですが、REDUCEは反復処理があって複雑なんですよね。私も一番慣れるのに時間がかかりました。
これを頭の中で理解(シミュレーション)しようとすると、無量空処 をくらったような情報過多状態で、あやうくオーバーヒートしそうになります。
凡人がREDUCEを扱う際は、理解ではなく使っていくうちに慣れていくといった、語学学習的な習得の方が良いかもしれません。
今回 Googleスプレッドシートに LAMBDAのヘルパー関数として導入された REDUCE も、jsのREDUCEと同じくかなり複雑です。理解が追いつかない人は、今回の記事は流し読みでOKです。
まず、厄介なのが アキュムレーターという聞きなれない言葉。
Excelの方の REDUCE関数の公式解説でも使われています。
accumulator は、accumulate が「ためる、蓄積する」という動詞であることからも察せますが、蓄積装置のような意味合い。関数においては、順に処理していく中で、その時点(一つ前の処理)までの計算結果 と捉えて良いんじゃないでしょうか。
昔は MDNでも javascriptのREDUCEの解説で 引数を accumulator と記載していたと記憶していますが、現在は previousValue (前回の値)となっていますね。こっちの方がわかりやすいかも。
アキュムレーターという言葉は解説では登場しています。
また、セル範囲や配列を与えた時に一つずつ処理をするという引数の取り方は、MAPと近いと言ってもいいかもしれません。
順に処理をしていく中で、一つ前の結果を利用できる(反復計算 である)という点が REDUCE ・SCANの最大の特徴です。
途中の結果の再利用が特徴と考えると、REDUCE(リデュース = 減らす)関数じゃなくて、リユース関数とかリサイクル関数 の方が 合ってそうにも思えますが、「配列」を単一の結果に収束させる という意味合いの方が強いのかもしれません。(jsのREDUCEの解説も「縮小」関数って記載があるし)
なんだか、昔のCMソング 「リデュース、リユース、リサイクル~♪」が流れてきそうですw
今風にいえば、REDCE関数は 地球にやさしい関数、SDGsな関数、ってことになるのかも? ← ならない!
MAP・REDUCE・SCAN の比較(まとめ)
「セル範囲、配列の値を与えた際の動きの違い」を簡単にまとめると
蓄積された途中(前回まで)の計算結果 = アキュムレーター
■MAP
一つずつ処理し一つずつ返す
(ひとつ前・途中の計算結果を処理に利用することができない)
■REDUCE
一つずつ順番に処理し、最終的に一つの結果を返す
(蓄積された途中の計算結果を処理に利用することが可能)
■SCAN
一つずつ順番に 一つずつ処理し、その時点の結果を一つずつ返す
(蓄積された途中の計算結果を処理に利用することが可能)
※ SCANの結果の最後が REDUCEの結果と同じ
うーん、これも識者の方からはツッコミが入りそうですが、ざっくりと理解するならこんな感じでよいんじゃないでしょうか。
累計でわかる 関数熟練レベル
言葉だけだとイメージがわかないので、具体例を使いましょう。
「前の結果」を利用する一番わかりやすい例が 累計です。
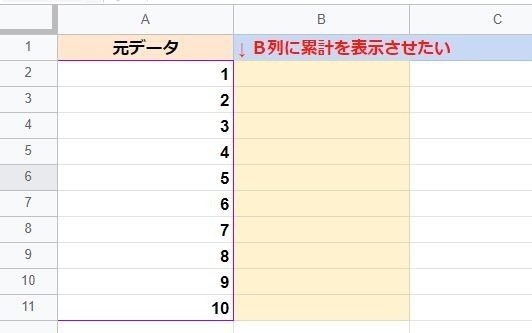
こんな感じで A2:A11の その行までの累計をB2:B11に出力したい時、
皆さんはどんな式を使いますか?
恐らく熟練度に応じて、以下のようになるんじゃないかと思います。
0. 関数がよくわかってない
→ 電卓を使い結果を手入力。または一つ一つ手作業で式を作る。
1. 関数が多少理解できている(シンプルな処理が出来る人)
→ B2セルに =B1+A2 を入れて 下にオートフィル。
2. 関数がある程度理解できている(絶対参照が使える人)
→ B2セルに =SUM($A$2:A2) を入れて 下にオートフィル。
(これが使えても1を選択する人もいると思います)
3. 関数ヲタクな人(詳しい人)
→ B2セルに ドヤ顔で以下の式を入れる
=ARRAYFORMULA( SUMIF( ROW(A2:A11), "<="&ROW(A2:A11), A2:A11 ) )
ここでもし、最新の LAMBDA / SCAN の式を出してくる人がいたら、確実に私みたいな関数ド変態クソ野郎でしょうw
自分的にはイケてると思って LAMBDAを使っても、女子社員から「すごーい💛」とか「mirさん素敵ー」と称賛され モテモテになることはありません。 裏で「なんかあの人変な関数使ってドヤってた」「きもーい」となるんで注意しましょうw
当然ですが、上の 1~3の式 は全部同じ結果になります。
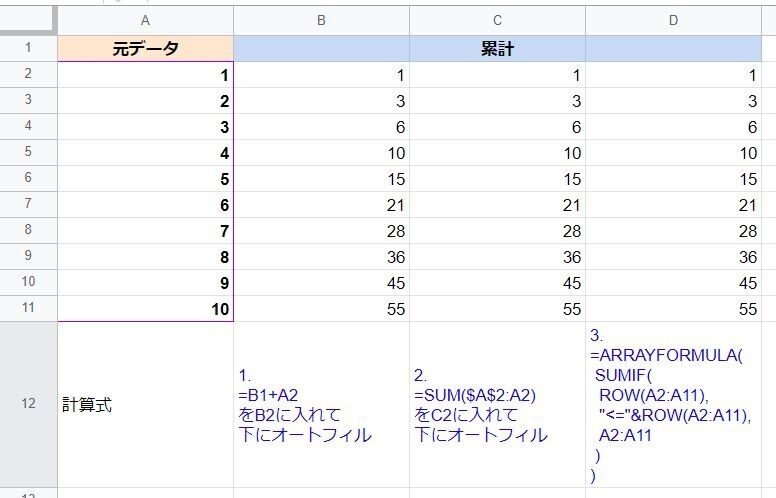
ちなみに 2の式をArrayformulaでスピル化させたものが、3の式です。SUMIFを使って「ROW(行番号)が自分以下」という条件をつけることで、累計処理にしています。
では、シンプルな1の式は Arrayformula化は出来ないのか? というと、実はそんなことも無くて、タイムスタンプ記事の3回目「関数タイムスタンプ」で使った「反復計算」をオンにしてあげることで、循環参照エラーを解除し動かすことができます。
ただし、以下の式と 「反復計算」を使って 一応出来なくもない。
というレベルです。
//B2に以下の式を入れる(循環参照)
=ARRAYFORMULA(A2:A11+B1:B10)
これを入れてみると・・・
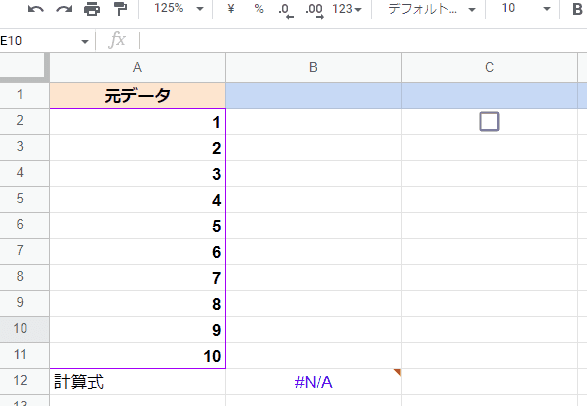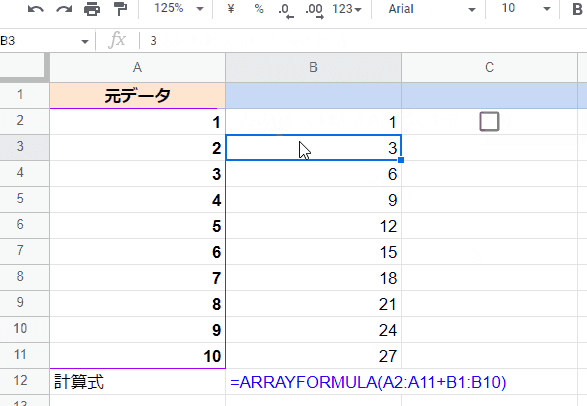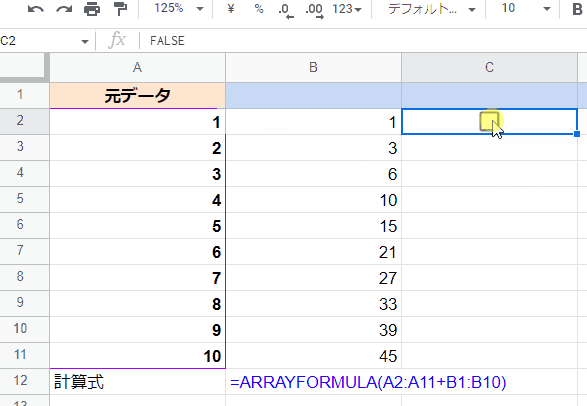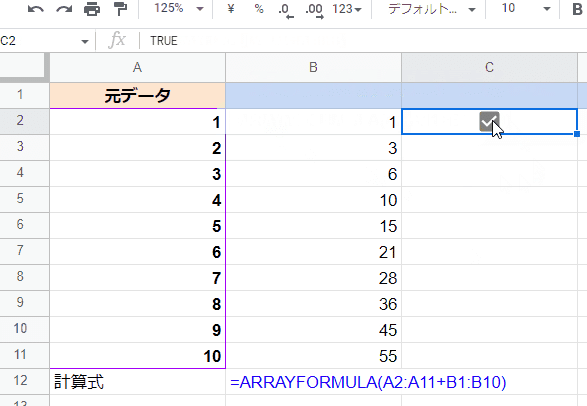
式を入れた直後は、B5から下のセルの結果が正しくありません。
これは反復計算が1回しか動いていない為です。残念ながら、自動で繰り返し計算をして正しい結果にたどり着いてくれるわけではありません。
シートに(セル入力等の)なんらかの更新をかけ 再(反復)計算させることで、徐々に求めている結果に近づいていき、最終的なゴールにたどり着きます。
再計算の実行を可視化させる為にチェックボックスを使っていますが、簡単に再計算させるには パソコンだと適当な空白セルを選択して Deleteキーを 連打という方法もあります。
今回の式だとカチカチと7回再計算させると結果にたどり着きました。求めてる結果(正しい答え)にたどり着いた後は、固定され数値が変わることはありません。
10行だから笑ってカチカチしてますが、100行の累計だと 97回も再計算(カチカチ)させる必要がります。現実的ではありませんし、スプレッドシート側にも無駄な負荷がかかってそう。
正直、反復計算を使ったこのやり方はお勧めできません。
そこで、ようやく REDUCE・SCAN の出番です。
今回の本題である REDUCE、SCANの動きの基本は、この 1の式をスピらせたもの だと思ってください。
累計でREDUCE・SCAN の動きを理解する
REDUCEで累計の最後の値、つまりA2:A10の合計を出すには、
=REDUCE(0,A2:A11,LAMBDA(pv,cv,pv+cv))
こんな式になります。これは 1~10までを足した結果 55を返します。
=SUM(A2:A11) と一緒ですね。
pv,cv は他の文字に変えても問題ありません。
pv・・・ previousValue (前回の処理までの返り値・結果)
cv ・・・currentValue(与えた配列を順に取り出した値)
として使っています。
0 を入れている場所は、初期値(initialValue)です。
ここは1つ目の処理の際のpvとして利用します。
0としてますが、今回の場合は何も入れなくてもよいです。
このREDUCE式の動きをトレースする為に、
REDUCEの影(途中経過)を返す SCAN式に置き換えてみましょう。
=SCAN(0,A2:A11,LAMBDA(pv,cv,pv+cv))
この2つの式の 結果と動きをまとめると 以下のようになります。

REDUCE も SCAN も
セル範囲から 1つずつ順番に値を取得 => cv
1つ前までの結果を参照 => pv
計算処理をして結果を返す => pv+cv (次の処理のpvとなる)
この処理を 今回であれば 10回ループ しているわけです。
1ループずつの途中経過(上の 3)をセルに出力するのが SCAN、
ループが終わった最後の結果だけ返すのが REDUCE
というわけです。
動きはイメージできたでしょうか?
どうしても理解するのが難しいREDUCE関数。これの何が凄いのか?
特徴をもう少し掘り下げていきましょう。
REDUCE(一部はSCANも)の特徴
REDUCEで配列を生成
先週 MAKEARRYを取り上げた際に 「ヘルパー関数の中で 自由なサイズの配列を返せるのは、このMAKEARRAY と REDUCE だけです。」 と書きました。
REDUCEは最終的に1つの結果を返す関数のはずですが、これはどういうことでしょう? 特級呪術師クラスしか使えない 領域展開が使えるってことでしょうか?
実は この最終的な 1つの結果は、1つの値(1セル)という意味ではありません。最終的な結果が、一塊になっている配列(ひとつなぎの大秘宝)でも良いのです。
そしてGoogleスプレッドシート は配列操作テクニックとして、
{ array1,array2 }、 {array1;array2} を使った セル範囲・配列の縦横の結合が使えます。これを式内に組み入れることで、 配列生成が可能となります。
範囲・配列結合に関しては公式ページだと図解がないので、
以下のQiitaの記事が参考になるかと思います。
REDUCEが配列を返せるということは、先ほどの累計の例で SCANと同じ結果を返すことも可能ということです。
REDUCEで SCANの累計処理をコピー

=REDUCE(,A2:A11,
LAMBDA(pv,cv,IF(pv="",cv,{pv;INDEX(pv,ROWS(pv),1)+cv})))
もちろん 累計に適したSCAN式よりもぐっと複雑になります。
この式を説明します。
初期値を空欄としifでそれを条件に分岐させることで、1回目は配列に追加ではなく単純にcvを返すようにしています。(これをしないと 結果が11行になります)
2順目以降は、 {pv; 計算結果} とすることで、結果配列の一番最後 に順に追加していく処理をしています。(縦方向、つまり下に追加するので ; で連結します)
また pvは配列化している為、そのまま pv+cvでは計算できません。
pvの配列の最後尾(最終行)の値を取得、それと cvを加算する記述にしています。(この部分がpvの最後尾 → INDEX(pv,ROWS(pv),1) )
前回のMAKEARRAYでも出てきましたが、INDEX関数は ARRAYFORMULAとは相性が悪かったですが、ヘルパー関数との組み合わせでは かなり活躍します。
ちょっと煩雑ですがこの配列に順に追加していく処理って、Array.prototype.push() っぽいって思いますよね。
同じく 配列の最後尾を取得する際の INDEX(pv,ROWS(pv),1) こちらは、
array[array.length - 1] と同じような処理ですね。
GASを使う人ならわかりますよね?
こんな形で 配列への値や・配列の追加が出来れば、かなり出来ることが広がるってことです。
なんでもSCANできるわけではない
REDUCEがやり方によっては、結果として配列を返せる関数であることはわかりました。一方、REDUCEの影である SCANはどうでしょうか? こちらは、最初から 途中結果を配列にして返す関数です。
与えられた配列と同じサイズの配列を返すという型(縛り)がある為、残念ながら 上記のような配列を返す REDUCEの場合は、SCANに置き換えることが出来ません。

この点は BYROWやBYCOLと同じです。SCANは 累計を返すには良い関数ですが、REDUCEほどの無敵感、万能さはありません。むしろ累計以外の出番があまりないかも。この点は注意です。
↑こちらは 2022年12月のこっそりアップデートで、SCANの途中結果で配列を返せるように改善されています。
REDUCE・SCANで 二次元配列的な処理
上の累計は 1列の単純なものでしたが、「複数列(AからC)の範囲を 行毎に合計したものを累計させたい」といった場合は、どうすればよいでしょうか?

単純に 先ほどと同じようにSCANで式を作りました。
=SCAN(,A2:C5,LAMBDA(pv,cv,pv+cv))
これを入れると・・・

当然こうなります。気を利かせて行毎の処理はしてくれません。
MAPと同じで、与えた配列(範囲)と同じサイズの配列(青字)が返ってきました。ちなみに処理の動きは茶色矢印で表しています。
横方向(右方向)が優先で最終列(右端)までいくと1行下がる。
TEXTJOIN や SEQUENCEと同じ動きです。
この動きをされると、行単位で処理をしたいことが多いのので、結構困ります。GASで慣れてる人だと、二次元配列が恋しくるかも。
GAS(配列)初心者殺しの二次元配列 。
不慣れな時は私も扱いが難しいと感じていましたが・・・
「一緒にいる時は窮屈に思えるけど、やっと自由を手にいれた僕はもっと寂しくなった」(もう getValuesしないなんて、言わないよ絶対~)
こんな感情がわいてきますw
でも、これも記述を変えることで、LAMBDAは 二次元配列的な処理にも対応できるのです。
=LAMBDA(array,
SCAN(,
SEQUENCE(ROWS(array)),
LAMBDA(
pv,cv,pv+sum(INDEX(array,cv,))
)
)
)(A2:C5)一番外側のLAMBDAはなくてもいいですが、使った方が範囲を変更する際に1箇所のみ修正で済みます。

式を入れると、求めていた結果が返りました。
解説します。
SCAN に直接 対象範囲 (A2:C5) を渡すのではなく、1から A2:C5の行数 = 4( ※ROWS(A2:C5)で取得 )までの連番をSEQUENCEで生成し渡します。
要はcvには 1,2,3,4が 順番に入ります。
このcvを使って、後ろのコールバック関数 (SCAN内のLAMBDA 式)で INDEXと合わせることで、対象範囲から 1行ずつ取り出し SUM(合計)。
これを pv に加算することで 行毎の合計の累計を算出しています。
ここでも INDEXが活躍してますね。
複雑そうに見えますが、処理としては単純です。
この辺りから REDUCE・SCANを お試しで使ってみるのがおススメです。
そして、二次元配列的処理が可能となることで、先ほどREDUCEを使ってSCANの動きをコピーしたのと同じように、REDUCEで行毎の処理や列毎の処理、つまり BYROWやBYCOLと同じ動きができるわけです。
REDUCEは最強なのか?
ここまで万能だと、REDUCEは 関数の究極奥義 「無双転生」 と言えるかもしれません。(他の関数の技をコピーできるんで「水影心」かも)
REDUCEの弱点は
じゃあ、REDUCEがあれば、他のヘルパー関数いらないのか?というと、そんなことはないです。
REDUCEは 記述が長くなる上に、非常に難解な式になっていくので、エラーを起こしやすい(エラーを見つけづらい)というリスクもあります。だから、それぞれの状況に適した関数を使うべきだと思います。
さらに REDUCEはその難しさ故に、「深い哀しみを知った者のみが体得できる」関数との言い伝えがあるほど。(嘘です)
単体でも難しい REDUCEですが、状況によっては他のヘルパー関数と組み合わせたり( BYROW + REDUCE)、REDUCE処理の中でさらにREDUCEを回したり( ダブル REDUCE)、こんな使い方の場合はさらに複雑になっていきます。
少年誌でお馴染みのチート技は制限があったり、利用後の反動が大きかったりってアレではないですが、REDUCE式を作ってると頭がこんがらがってくる というリスクがあるってことです。(もちろん 余裕で REDUCE使いこなせる達人もいるでしょうが)
REDUCEでなければ出来ないことも色々ありますが、REDUCEを使わなくて済むなら 別の関数で処理した方が簡単なんで、そっちを選びましょう。
REDUCEと名前つき関数の再帰の違い
REDUCEは1つ前までの結果を使って処理ができるので、再帰処理と言ってよいかと思います。じゃあ、名前つき関数を使った再帰処理との違いはなんでしょうか?
REDUCEが 与えた配列分のループを回し、途中でBreak(ループを終了すること)が出来ないのに対して、名前付き関数を使ったループは IF文などを使ってある条件を満たしたら (満たさなかったら)ループ終了という記述ができます。
つまりは REDUCEの場合は1000の要素の配列があった場合、ループ2つ目で処理が完了したとしても、残り 998回を計算する必要があります。一方の名前付き関数は 2つ目で欲しい結果が出たら、残りのループはなしで終了で良いのです。 名前付き関数の再帰処理は while 関数的と言ってもよいかもしれません。
実例を使って説明しようと思いましたが、かなり長くなってしまいそうです。これは別のタイミングで実例を交えて紹介します。
ここでは REDUCE と 名前付き関数の再帰処理、どちらを使った方が良いかは処理内容によって変わってくる。それだけ覚えておくと良いでしょう。
REDUCEの活用シーン
REDUCEが使えそうな場面をざっと思いつく範囲であげておきます。現時点で mirが思いつくレベルなので、今後はもっと色々出てくると思います。
■REDUCEが活用できそうな例
・ある数値以下の 素数抽出
・素因数分解
・その他の数学的な処理
・複数シートの結合(INDIRECT と結合の繰り返し)
・複数キーワード のアンド条件でのFILTER
・検索キー毎の Filter処理(FilterでArrayformula的な処理)
・範囲の指定回数分の繰り返し出力(縦、横)
・直積(組み合わせ全パターン出力)
・リスト表をもとにした文字のリプレース処理
・差し込み印刷的 リプレース処理
SCANの活用シーン
一方、SCANは残念ながら 累計や 累計的計算が必要な「複利計算」(定期預金などの利息にも利息が発生するもの)などしか出番がない印象。
もちろん無理やり使うことも出来ますが、BYROWでいいじゃんってケースも多い。。
こちらも活用シーンが思いついたら、また紹介していきます。
GASで REDUCEを使える人なら、違和感は感じつつも Googleスプレッドシートの LAMBDA / REDUCE 関数が感覚的に使えるんじゃないでしょうか?
一方で、プログラミングの配列処理や再帰処理、REDUCEメソッド にまったく触れたことがない人にとっては、シート関数とはいえ REDUCE関数 はかなりハードルが高いと思います。
便利だけど この難解さから、REDEUCE関数はそこまで世間一般では使われないかもしれません。少なくとも XLOOKUPのようなメジャー関数にはならなそう。(自称お笑い好きからの評価が高く、一部の熱狂的な信者がいる ラーメンズ 的なポジションにはなるかも)
でも、今までGAS使うしかなかった状況が一変する関数なのは間違いない チート関数なので、「シート関数を極めし者」を目指すのであれば頑張って習得していきましょう!

今回で LAMBDA、そして6つのヘルパー関数の検証は終了です。
次回はXLOOKUPの検証を予定。
動向記事や検証記事の中で ちらっと紹介した テクニックや、活用シーンは徐々に記事にしていきたいと思います。
今回紹介のヘルパー関数 公式 (掲載時 日本語未対応)