メルカリにおけるA/Bテスト標準化への取り組み

こんにちは、Analytics Infra チームの @yaginuuun です。主にA/Bテスト周りの改善や Recommendation 関連の分析を担当しています。
当ブログは 2021/07/28 に開催された Retty ✕ Mercari Analyst Talk Night! におけるLT内容を改めて少し補足を加えながらブログの形に書き起こしたものです。
当日の資料はこちらです。
A/Bテストとは
A/Bテストは Randomized Controlled Trial (RCT) とも呼ばれる効果検証手法です。最も単純な例をあげると、二つの群を用意し片方の群にのみ何かの変更を加えることでその変更による数値変動を評価します。
A/Bテスト自体は医学や農業の分野など幅広く行われています。特に医学の領域においては Level of Evidence という考え方があるようですが、A/Bテストはその中でも上から2番目に位置しており、かなり信頼性の高い検証方法と見なされているようです。
1a: Systematic reviews (with homogeneity) of randomized controlled trials
1b: Individual randomized controlled trials (with narrow confidence interval)
1c: All or none randomized controlled trials
2a: Systematic reviews (with homogeneity) of cohort studies
2b: Individual cohort study or low quality randomized controlled trials (e.g. <80% follow-up)
…
Web業界においてもA/Bテストによる施策の効果検証がゴールドスタンダードとして用いられています。加えて先進的な企業では Experimentation Platform と呼ばれるA/Bテスト基盤をそれぞれ保有しており、大量のA/Bテストを半自動的に分析することによってスピーディな改善を行っています。
・It's All A/Bout Testing: The Netflix Experimentation Platform | by Netflix Technology Blog
・Under the Hood of Uber's Experimentation Platform
・Scaling Airbnb's Experimentation Platform | by Jonathan Parks | The Airbnb Tech Blog
もちろんメルカリも例外ではなく、毎日のようにA/Bテストによる改善活動が行われています。このブログではそんなA/Bテストについて、社内の標準化を進めた取り組みについて書いていきます。
A/Bテストの標準化とは何か
混同されがちなところとして、一つ前の項でも取り上げた Experimentation Platform によるA/Bテスト評価の自動化がありますが、今回のブログでは標準化にスコープを絞ります。
このブログではA/Bテストの標準化について、以下のように定義します。
施策評価者(主に Data Analyst )が統計的な検討事項やアンチパターンを考慮しつつ、一定以上の品質でA/Bテストから信頼に足る結果を得、それを元に意思決定できるようにすること。
念の為ですが、自動化が不要だと考えているわけではありません。むしろ今後のステップとして必ず必要になってくると考えています。
なぜA/Bテストの標準化に取り組むのか
では自動化は必要とした上で、なぜ標準化に焦点をあてて取り組むのでしょうか?
自動化がもし実現できれば以下のようなメリットが考えられ、インパクトがとても大きく思えます。
・Data Analyst の工数が削減でき、他の分析に時間を使えるようになる
・クエリを書く中での human error の削減が期待できる
・A/Bテスト結果が自動で一箇所にまとまり将来参照しやすくなる
この点について説明するために、ここで Experimentation Maturity Models(成熟モデル)というものを取り上げます。
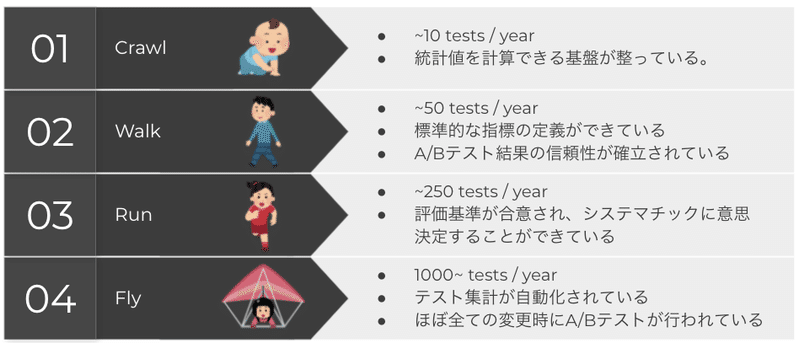
これによると成熟度は Crawl, Walk, Run, Fly の四段階に分かれているとのことです。A/Bテスト集計の自動化は最終レベルの Fly として定義されています。そして、それよりも前のステップを見てみるとA/Bテスト結果の信頼性の確立など標準化に関する項目が記載されています。
A/Bテストは一見とてもシンプルな効果検証手法ですが、それを適切に使用するためにはさまざまな統計的事項やアンチパターンを考慮する必要があります。もしもそういったアンチパターンにはまってしまうと、得られた結果はもはや信頼できるものではなくなってしまいます。
標準化のないままに自動化を進めてしまうと、こういったアンチパターンを意識しないままにバイアスを含んだ結果が蓄積し、それにより発生する適切でない意思決定が高速に積み重ねられてしまう危険性があります。
こういった背景が自動化よりも標準化に先に取り組むモチベーションとなっています。
Experiment design doc
前置きが少し長くなってしまいましたが、ここからが本題になります。
ではどのように標準化を進めていくのか?という話ですが、現時点で私たちの取り組みの中心となっているのが Experiment design doc というものです。
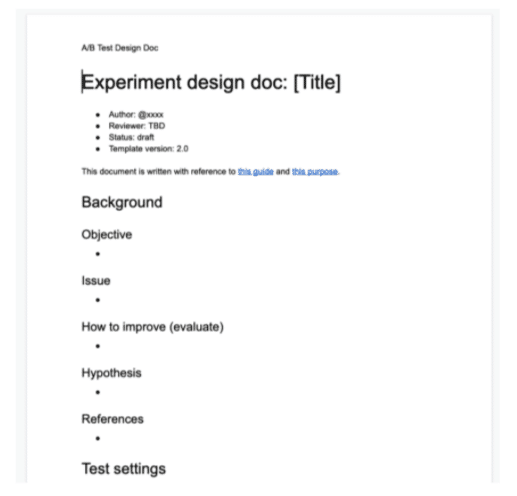
Experiment design doc とは簡単に言うとA/Bテストの設計項目が網羅されたテンプレートのことです。Experiment design doc を中心としつつ、レビュープロセスや Reference の整備を通じて標準化へのアプローチを試みています。
Experiment design doc は主に以下の項目から構成されます。
・Background
・Test settings
・Metrics details
・Action plans
以下の項で一つずつ解説していきます。
Background
A/Bテストの背景情報を記入します。具体的には以下のような内容を記入します。

これらの情報が簡単にでも書かれていることで、どのような課題感からA/Bテストが行われたのか素早くキャッチアップできるようになることや執筆者が評価指標を考える上での仮説をシャープにするといったことが期待されます。
Test settings
A/Bテストの設定情報を具体的に記入します。例えば以下のような内容を記入します。
・対象OS
・Trigger: 割り当てが行われるタイミング
・variant(比較群)
・割り当て率
・期間
ほとんどの項目がA/Bテストを行う上で自然と決める必要のあるものとなっていますが、一点 Trigger についてだけ補足をします。
テストをより Sensitive にするために、アプリを開いた方ではなく特定の画面を開いた方だけに対して割り当てを行いたいケースがよくあります。
ところが、そのような状況では集計された数値は当然 特定の画面を開いた方の中で という条件のついた値になるので、Trigger を明記しておかないと結果の解釈が適切に行われない危険性があるので注意が必要です。
Metrics details
A/Bテストをどんな指標で評価するのかを記入します。大きく以下の3種類のmetrics が定義されています。

Goal metrics
A/Bテストの成功を定義する指標です。多くの場合 Background の Hypothesis に書いてある内容から変化を期待できる指標、かつ UX や Business にとって意味のある指標をピックアップして設定します。
例えばメルカリへの出品をより簡単にする施策であれば、出品完了率( = 出品完了/ 出品開始)が設定されることが考えられます。
Guardrail metrics
A/Bテストにおいて、棄損したくない指標を設定します。Guardrail metrics はどちらかというと監視の意味合いも強く、例えば収益に直結するビジネス上極めて重要な指標であったり、良い UX を提供できていることを反映できるような指標が設定されることが多いです。
Goal metrics はA/Bテストが行われる領域によって変わることがほとんどですが、Guardrail metrics は共通のものが使われるケースも多いです。
Debugging metrics
A/Bテストが意図通り進行しているのかを確認する指標です。意図通りというのは大きく下記の2種類に分けられます。
・施した変更は十分に認知されているか?
・何か予想外のバイアスが混入していないか?
一点目に関して、例えば何も変化が起こっていなかった場合にそれが施策に効果がなかったのか、それとも認知が足りていなかったからなのかは何も数値が無い状態では切り分けることができません。
そこで変更箇所の使用率をモニタリングしておくことで要因を切り分け、例えば認知が足りていなかったのであれば導線改善によって認知を高め、真の変更の効果を検証するというような次のアクションが取りやすくなります。
二点目に関して、主に Sample Ratio Mismatch(SRM) が発生していないかのチェックを行います。Sample Ratio Mismatch とは、実際に割り当てられているサンプル数が事前に想定したものとズレる現象のことを指し、A/Bテストの様々な段階で起こりうることが報告されています。
SRM のチェックは意図しないバイアスが入り込んでいることを検知するシンプルかつ強力な手段であり、気付かない内にバイアスの入り込んだ結果を元に意思決定してしまっていた、というようなことを防げる確率をぐんと上げることができます。
以上 Goal, Guardrail, Debugging の3種類の指標がA/Bテストを行う際に必須で設定される指標ですが、その他にもA/Bテストによって起こった変化をより深く理解するための指標をまとめてモニタリングしています。
Action plans
指標の動き方による大まかな Next Action を記載します。
例えば Good scenario(Goalが改善、Guardrailに棄損なし)であれば 100% 展開、Bad scenario(Goalが期待ほど改善せず)の場合は Close などを記載しておきます。
事前に関係者間で合意をしておくことで、後から試行錯誤をして Open/Close の判断をしようとして Analyst に多大な分析負荷がかかってしまったり、Cherry picking をしてしまったりということを未然に防ぐことに繋がります。
以上が Experiment design doc の骨子となっており、冒頭にも述べた通りこれを中心として Guide book を整備したり、Analyst 間で互いに Document をレビューすることで検証の質を一定以上に保つ取り組みを行っています。
実際どんな嬉しいことがあったのか
取り組みとして完結するものでは無い一方で、現時点で以下のようなメリットがあったと感じています。
Template のメリット
・書体が揃う → 過去のDocumentを読み解くコストが下がる
・検討項目の抜け漏れがなくなる
・話し合いをする板としての役割を果たしてくれる
Review のメリット
・A/Bテストの検証に慣れていないメンバーでも Pitfalls を避けつつ一定基準の質を保ちつつ検証を行うことができる。
以上のように、当初期待していたことは概ね満たせているという実感があります。
一つ個人的に意外だったのが、話し合いをする板としての役割を果たしてくれるので PdM-Analyst 間のコミュニケーションが取りやすくなった という点です。元々検証の質を担保する、ということをコアにおいたものであったため、このように設計のワークフロー自体も改善されることは少し意外でした。
また、実際に使用者にヒアリングを行ったところ、確かにA/Bテストの設計に慣れた方については検証の質が上がったとは感じていないとのコメントを頂いたのですが、そうでない方については上がったと感じるとコメントを頂き、一定以上の検証の質を担保する という目的に近づくことのできるものになれているのではないかと感じています。
また、基本的にドキュメントを書くことは作業者にとってはコストなため、このように人それぞれメリットを感じていただくことは取り組みを広げていく上でとても重要だと考えています。
この先の話
ここまで取り組みについて紹介してきましたが、個人的には決してまだ手放しに成功とは言えない状況だと感じています。最後に現状感じている課題感についてまとめ、このブログを締めくくろうと思います。
プロジェクトから文化へ
現在文化のように定着しているというよりは、人の力を加えつつ進めている感触を持っています。これから人の力を抜ける方法を模索し、仕組み化を進めていく必要があると思っています。
自動化との掛け合わせ
自動化より先に標準化に手をつけるべきと言いつつも、やはり自動化と合わせると相乗効果がある取り組みであることは間違いないとも感じています。
一人一人のAnalystが十分に知識を付けたとしても、人の手でやっている限りはどこかでミスが起こることは間違い無いですし、全てのPitfallを意識して設計を行うのはあまり現実的でない側面もあります。
また、検証の質を担保するという目的を超えて、過去に行われたA/Bテストのナレッジを蓄積するということに挑戦しようとするとその場面でナレッジと呼ばれるものは検証の設定ではなく主に背景と結果です。
現状のものでは背景を簡潔に残す、という面では良いのですが結果の蓄積という部分に対して弱く、結果までも統一的な方法でまとめていくとなるとExperimentation Platform のような中央システムは必須になってくると思います。
終わりに
以上のように課題を考えてみると、先に述べた Experiment maturity models ではまだまだ入り口に立った段階でこれからまだまだやることがあるという状態です。
Analytics Infra team はこのブログで紹介させて頂いたように、Data Analyst として分析の仕事をする傍ら組織としてのデータ活用レベルの底上げを担う面白いチームとなっています。
もしこのブログを読んでこの取り組みやメルカリの分析チームについてもっと知りたい!と思った方がいらっしゃれば、ぜひお気軽にご連絡ください!(Twitter, Linkedin)
▼採用情報サイト・関連記事はこちらから
▼Analytics teamに関する他のオススメ記事
・「他人の目」ではなく「自分のやりたいこと」に集中できる場を求めて メルカリAnalytics新卒メンバーの所感
・アナリスト歴3ヶ月目と3年目のメンバーそれぞれが考える、楽しさの軸とキャリアプラン
・メルカリAnalyticsチームのミッション・ロールモデルを策定した狙い マネージャーが語る“変遷”と“今
・レガシー化したData Pipelineの廃止 ― メルカリのData Architectのお仕事例
この記事が気に入ったらサポートをしてみませんか?