レガシー化したData Pipelineの廃止 ― メルカリのData Architectのお仕事例

Analytics Infra チームの@hizaです。
この記事ではメルカリの分析環境を改善した事例を紹介します。
今回は「運用に課題があってリプレースしたいが、業務への影響が大きすぎてリプレースできない」そんな板挟みな状況を解決した事例です。
また、その紹介を通じてメルカリのData Architectがどんな仕事をしているのかその一部を感じてもらえる記事をめざしました。
メルカリのデータ活用の現状
メルカリには様々な職種でデータを活用する文化があります。
AnalystやML Engineerの他にも、PdMやCustomer Supportなども業務にデータを活用しています。結果として社内のBigQueryユーザー数は月間800名を超えるほどになりました。
こういった環境ではデータが良く整備されている事が事業の成果に大きく影響しえます。例えば、使いやすいDWHがあれば多数の社員の業務が効率的になりますし、もしData Pipelineに障害が起きれば広範囲な業務が止まってしまいます。
レガシー化したData Pipelineの問題
そうした環境にも関わらず、メルカリのデータ基盤には課題もありました。
例えば「レガシー化したData Pipeline」の問題です。レガシー化したData Pipelineとはこの記事における造語で、以下のような状態のData Pipelineのことです。
レガシー化したData Pipeline ... 運用に課題があってリプレースしたいが、業務への影響が大きすぎてリプレースできなくなったData Pipeline
以下で事例を交えて詳しくします。
メルカリのデータ基盤を大まかに言うと「①本番環境の大小様々なシステムから、②複数のData Pipelineを通じて、③BigQueryにデータを集約する、④それをSQLやDashbaordから使う」構成です。
②のData Pipelineの内1つが「レガシー化したData Pipeline」の状態に陥っていました。
このData Pipelineは本番環境のとあるMySQLからBigQueryにデータを日次でuploadするシステムで、以下の2つの問題を抱えていました。
1. 高い運用コストとリスク
・同様のシステムで広く用いられているAirFlowやEmbulkではなく、node.jsによる独自実装のワークフローシステムという独特な構成
・開発スタートが創業直後の約8年前であり主要な開発者がすでに社内に居ない
→ 平常時のメンテナンスコストが高く、障害発生時の復旧に時間がかかるリスクもありました。
2.再現困難なデータ
・BigQueryにuploadを行う際にデータを加工しており、その処理内容がソースコードの複数箇所を調べないと分からない
・1度uploadされたデータにMySQL側で変更があっても変更内容がBigQueryに反映されない。そのため、BigQueryにuploadされたデータは日次バッチの実行タイミングに依存した内容になっている
→ 他のData Pipelineを使って同じデータを再現するのが困難でした。
このように課題を抱えつつも、このData Pipelineが生成するデータは1日あたり150名程度に参照され、影響が大きかったために簡単にリプレースすることも出来ません。この板挟みの状態を「レガシー化したData Pipeline」と呼んでいます。
レガシー化したData Pipelineをリプレースする試み
問題を解決するために、リプレースが過去に何回か試みられました。
まず最初に試みられたのがレガシー化したData Pipelineの仕様を完全に再現する形でのリプレースです。日次バッチの挙動やデータ加工のロジックなどの全てを再現しようとされましたが、複雑すぎて頓挫してしまいました。
具体的には「仕様を再現したデータの生成 → 実物との比較 → 数字のズレの確認 → 原因調査 → 原因が分かったら再現する仕様に追加」のサイクルを繰り返して不透明な部分を全てを明らかにしていくのですが、仕様の複雑さと量が予想以上で手間がかかりすぎたのです。
次に、技術的に無理がないように仕様を単純化したシステムへの移行も試みられました。しかし今度はデータの利用者から、データ、あるいはそこから集計するKPIの定義が変わる事への反対意見が出てこちらも頓挫してしまいます。
まとめると以下のジレンマが起きていました。
1. 仕様の完全再現は技術的に困難
2. かと言って単純な仕様への変更は業務への影響が大きい
→ 結果としてリプレースできない
技術的に無理がなく、かつ業務上十分な仕様を「データ」と「足」で解き明かす
ちょうどこの辺りの時期にAnalytics InfraチームにData Architectのポジションが設けられ、あらためてリプレースに取り組みはじめました。
過去の事例から言えることは、この板挟みから脱するには「技術的に無理がなく、かつ業務上十分な仕様」を作る事が不可欠という事です。そこで以下のアプローチでこの課題に取り組みました。
1.データを使う
過去の取り組みでは、思ってもいなかったチームがリプレース対象のデータを使っていた事が後から判明する事がよく起きていました。すると移行要件を後から見直す必要が出て望ましくありません。そこでリプレース対象のデータを使っている人をもれなく洗い出すために、BigQueryのjob historyを分析しました。
今回はBigQueryのJOBS_BY_ORGANIZATIONというログを分析しました。このログは、job_idごとに1レコードになっていて、job実行者のアカウント(mailアドレス)や、job開始時間、そしてそのjobでアクセスしたテーブルなどの情報がふくまれています。このログを使うと特定のテーブルにアクセスしたアカウントを組織内の複数のGCPプロジェクト横断で検出できるので、データの利用者をもれなく洗い出すために好都合です。
このログを使うことでリプレース対象のテーブルを使っているケースを1件も漏れなく洗い出せました。
2.インタビューを行う
データを使えば誰がどのくらいテーブルを使っているのか正確に調べる事ができますが、なぜ、どんな業務で使っているのかはログデータからは分かりません。
ユースケースを把握して必要十分な要件に落とし込むには実際に話しを聞きに行く事が欠かせません。今回もログから洗い出した利用者の一部にインタビューを行なってユースケースを洗い出していきました。
これらのインタビューを通じて仕様をもっとシンプルに出来る部分が見えてきました。例えば、「前日分のデータを日次でBigQueryにuploadし、一度uplaoadしたデータはMySQL側で変更があっても反映させない」という仕様は「そのテーブルから集計しているとあるKPIが、集計するたびに値が変わったりしなければよい」という事が分かったのです。詳細は省きますが、後者の方が技術的にずっと簡単でした。
3.データとインタビューを使い分ける
「データ」と「インタビュー」について使い分け方を少し補足します。例えば図のような依存関係があったとして、図中のDWHに変更を加えたければそれより下流への影響を全てケアする必要があります。それにはシステムだけでなく業務への影響に踏み込まなければいけません。むしろ業務への影響こそが重要なのです。オレンジで囲った「業務の依存関係」はインタビューしない限り分かりません。それはシステムの外で起きる出来事だからです。そして、そのインタビューを誰にすべきなのかというヒントが③のログを始めとした「データ」から得られる情報なのです。

このようにデータとインタビューを使い分けながら利用者のユースケースを集めていった上で、技術的に無理がない仕様へと落とし込んでいきました。
定義を「絵に書いたモチ」にしない
こうして新たなData Pipelineに求められる仕様が明らかになりました。そして仕様をよく検討したところ新規の開発はほとんど不要だと判明したのです。KPI定義の変更が必要になるものの、データ自体はすでにある別のData Pipelineから取得できる物を加工すれば良いと分かったからです。そのため、結果的にはviewと新しいKPI定義を作るだけで済みましたこれが全社に普及さえすればレガシー化したData Pipelineが廃止できます。
しかし、定義は作っただけでは普及しません。150名以上いる利用者にそれぞれのクエリを書き換えて貰わなければいけません。こういった作業は「移行の必要性」を全体に周知するだけでは中々進みません。
再びJOBS_BY_ORGANIZATIONログの出番です。
まず、廃止の進捗を可視化するために、廃止対象のテーブルにアクセスしているユーザー数やjob数の推移をモニタリングしました。これで移行のための各種施策が実際に利用者の減少に結びついているのか確認しながら進められます。
以下が実際のダッシュボードです。横軸が日付、縦軸が参照回数で、色は参照元の種類(Service Account / Dashboard / ユーザーの直接のアクセス)を示しています。
①のタイミングで、赤の参照元からの参照をへらす対策、
②のタイミングで、緑の参照元からの参照をへらす対策を行なっており、実際に参照が減っている事が分かります。
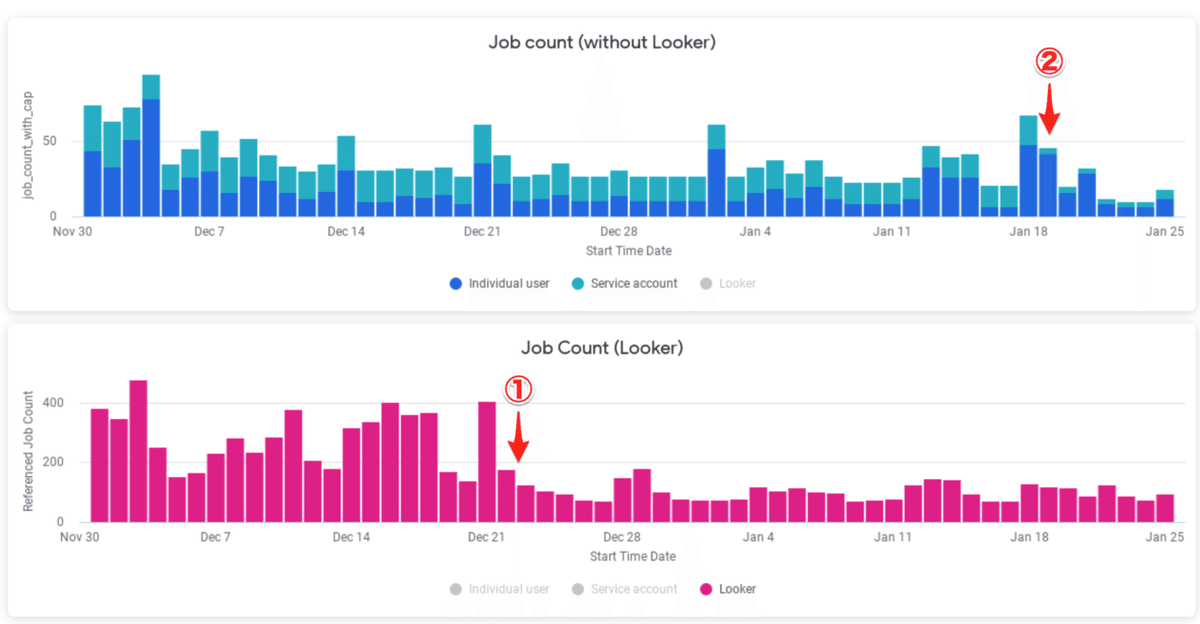
「ボリュームが大きいアクセス元をしらべて対策を実施→ダッシュボードで効果を見ながら次の対策を考える」この地道なサイクルの繰り返しで利用者をほぼ0にする事ができ、廃止が可能になりました。
ちなみに具体的な対策内容は、移行対象のデータにアクセスした人を検出してslackにpostする仕組みを作り、マイグレーション手順を案内するといった物です。
運用を健全にする意義
ここまで読んでいただければ分かるようにレガシー化したData Pipelineの廃止には非常に手間がかかります。「この取り組みによって来月どんな効果が得られるの?」と考えると意義もよく分からなくなりがちです。ではこれは「必要ではあるけど費用対効果が低い」取り組みなのでしょうか? 私はそうは思いません。
実は、今回の取り組みから何ヶ月か経ったあと、レガシー化したData Pipelineは致命的な障害を起こしました。復旧は不可能ではないものの非常に困難で、復旧するまでこのData Pipelineが生成していた全てのテーブルが更新されなくなる重大な障害です。しかし、その時点で利用者がほぼ0になっていたため全く影響なくそのまま廃止する事ができたのです。
もし、この取り組みを「費用対効果が低い」からと先送りしていたらどうなっていたでしょうか? レガシー化したData Pipelineが生成するデータは多くの社員に使われていただけでなくある程度クリティカルな用途に使われていたため、業務に重大な影響が影響が出ていたはずです。トラブルによるネガティブな影響を防いだ点で非常にインパクトが高い取り組みだったと私は考えます。
運用を健全にする取り組みは、効果を定量化しにくいですが、それは効果が低い事とは全く異なります。
Data Architectというキャリアの面白さ
最後に、今回のような取り組みは個人のキャリアにとってどんな意義があるのか私の考えを説明します。
私達のチームは、純粋なEngineerのチームでもなければ、純粋なDataの利用者(Analyst)のチームでもなく、その中間に立って橋渡しをするチームです。事業部によって異なるのですが私の所属する事業部ではこのポジションをData Architectと呼んでいます。「中間に立つ」ことにはスペシャリティを高めにくくなるデメリットもありますが、複数の領域を横断する面白さ、複数の領域を横断しなければ解けない課題に取り組む意義があると考えます。今回のリプレースは、まさしくEngineering(技術)の領域とAnalytics(利用)の領域を横断したからこそ出来たものだと考えています。
▼採用情報サイト・関連記事はこちらから
この記事が気に入ったらサポートをしてみませんか?