
Windows PCでAUTOMATIC1111版Stable Diffusion web UIを利用する手順(2023-03版)

※最近の更新
03-20-2023:記事の改修を行っています。そのため、不完全な内容となっている場合がありますが何卒ご容赦ください。
1. 概要
目的
Stable Diffusion形式のモデルを使用して画像を生成するツールとして、AUTOMATIC1111氏のStable Diffusion web UI(以下web UI)が有名で簡単かつ高機能です(その他、NMKD Stable Diffusion GUIも有名です)。
本記事では、web UIをPCにインストールして動作させるまでの手順や、いくつかのTipsを説明します。元々が高機能であることや、様々な拡張機能によって非常に奥深くなっていることから、詳細な使い方は割愛します。
ディレクトリ構成
本記事での作業ディレクトリは「\aiwork」です("\" は半角の "¥"と同じ)。主な構成は以下のとおりです。
\aiworkディレクトリ内の構成
stable-diffusion-webui\ web UI本体
stable-diffusion-webui\models\Stable-diffusion\
モデルの設置場所(ckptまたはsafetensors)
VAEの設置場所(モデルと同じファイル名で.vae.ptとする)
stable-diffusion-webui\models\VAE\
VAEの設置場所(.ckptのままか.ptまたは.vae.ptに変更)
stable-diffusion-webui\outputs\ web UIの画像出力ディレクトリ
webui.bat web UI起動用のバッチ本記事ではこれだけしか使用しませんが、他の用途でも「\aiwork」を使用するため、このような構成になっています。
動作環境(3-21-2023現在)
必要なハードウェア
Windows 10または11のPC
GeForce(10 Series以降、VRAM 8GB以上を推奨)
高速かつ大容量のSSDを推奨
(本体は5GB以上、モデルごとに2~8GBが必要)
必要なソフトウェア
GeForce のドライバー
(問題の無い範囲で新しいバージョンを推奨)Python(バージョン3.10固定)
Git(基本的には最新版)
CUDA Toolkit 11.7以上
(推奨は11.8、確認時点では11.6も動作可)
2. ツールの準備
動作に必要なPython、Git、CUDA Toolkit(以下、CUDA)をインストールします。導入済みの場合は3.へ進んでください。
インストール手順は、下記の記事にある「2. ツールの準備」を参照してください。ただし、「Build Tools for Visual Studio 2022」と「ninja」はインストール不要です。
3. web UIのインストールと起動
作業ディレクトリの作成
これ以降はコマンド プロンプトを使用します。また、作業ディレクトリを変えたい場合は適宜読み替えてください。
まず、Cドライブに「aiwork」ディレクトリが無ければ作成してください。次に、Windowsの検索欄に「cmd」を入力する等の方法でコマンド プロンプトを起動して、「cd \aiwork」のコマンドを実行してください。以下の3行目のような表示になって、作業ディレクトリに移動したことを確認してください。
cd \aiwork
C:\aiwork>これ以降は基本的に、入力するコマンドのみを記載します。行頭に「#」があったり、あきらかにコメントとみられる行は入力しないでください。
web UIのダウンロード
以下のコマンドは、「stable-diffusion-webui」ディレクトリが無い状態で実行してください。「git clone」コマンドで「stable-diffusion-webui」ディレクトリが作成されて、その中に最新版がダウンロードされます。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git本記事ではGitを、web UIのダウンロードにのみ使用します。しかし、アップデートが「git pull」のコマンドだけで済むようになったり(後述)、他の作業でも必要なったりするため、導入をおすすめしています。
モデルのダウンロード(任意)
この手順に従う場合は「web UIを初めて起動する前」に行ってください。3-21-2023現在、初回起動時にモデルが無い場合は、Stable Diffusion v1-5がダウンロードされるようになっています。この動作を避けるためには、予め別のモデルを設置する必要があるというわけです。
web UIで画像を生成するためには、モデル(元となるデータ)が必要です。モデルを切り替えると異なる画風が得られます。今となっては古くて性能も劣るモデルですが、ここではアニメ的なイラストが出力できるWaifu Diffusion v1.3を紹介します。現在はもっと優れたモデルがあるので、付録2の末尾で紹介している記事もご覧ください。
Waifu Diffusion v1.3
https://huggingface.co/hakurei/waifu-diffusion-v1-3
上記のリンク先から、ファイルサイズの最も小さい「Float 16 EMA Pruned」のリンクを選択してください。ダウンロードされずに画面が切り替わった場合は、「but you can still download it.」の箇所にあるリンクからダウンロードできます。2GB程度の「wd-v1-3-float16.ckpt」がダウンロードできたら、「\aiwork\stable-diffusion-webui\models\Stable-diffusion」に移動してください。
余談ですが、Hugging Faceに置いてある一部のモデルを利用する際は、ログインやアクセストークンが必要な場合があります(アカウントやアクセストークンの作成は無料)。現在、そのようなモデルはごく少数です。
起動(インストールと動作確認)
以下のコマンドを実行してください。インストールは初回の起動時に行われる仕組みで、それなりの量のダウンロードと構築の時間を要します。のんびりお待ちください。
cd \aiwork\stable-diffusion-webui
webuiインストールが済んで起動が完了すると、下記のような表示が出ます。指示されたURLにWebブラウザでアクセスすると、UIが利用できます。
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 11.2s (import gradio: 2.7s, import ldm: 0.9s, other imports: 2.1s, load scripts: 1.0s, load SD checkpoint: 4.1s, create ui: 0.2s).Prompt欄に文字を入れてGenerateボタンを押すと画像が生成されます。生成にかかる時間は環境(グラフィックボードなど)や設定(画像サイズなど)に依存しますが、1枚あたり数秒から数十秒程度です。
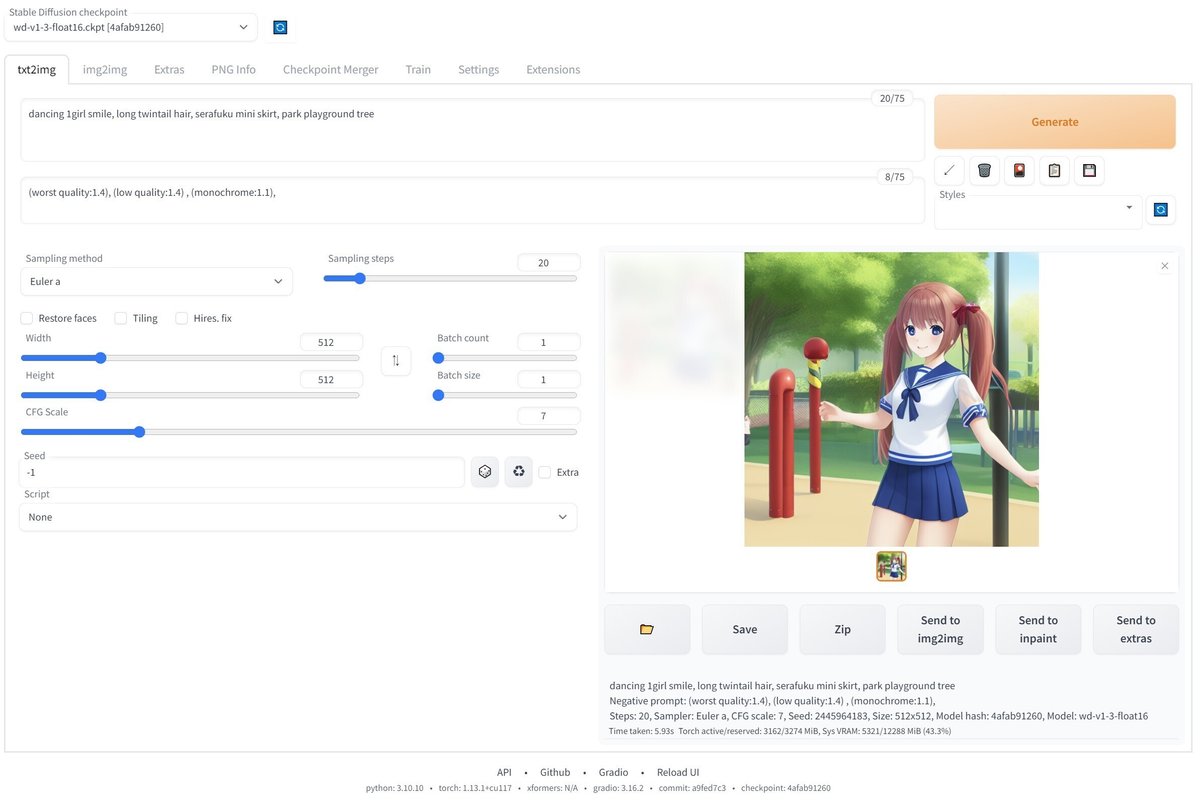
Negative prompt: (worst quality:1.4), (low quality:1.4) , (monochrome:1.1)
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2445964183, Size: 512x512, Model hash: 4afab91260, Model: wd-v1-3-float16
生成された画像は「\aiwork\stable-diffusion-webui\outputs」の下に保存されますが、使用した機能(今回はtxt2img)によって保存先が異なります。
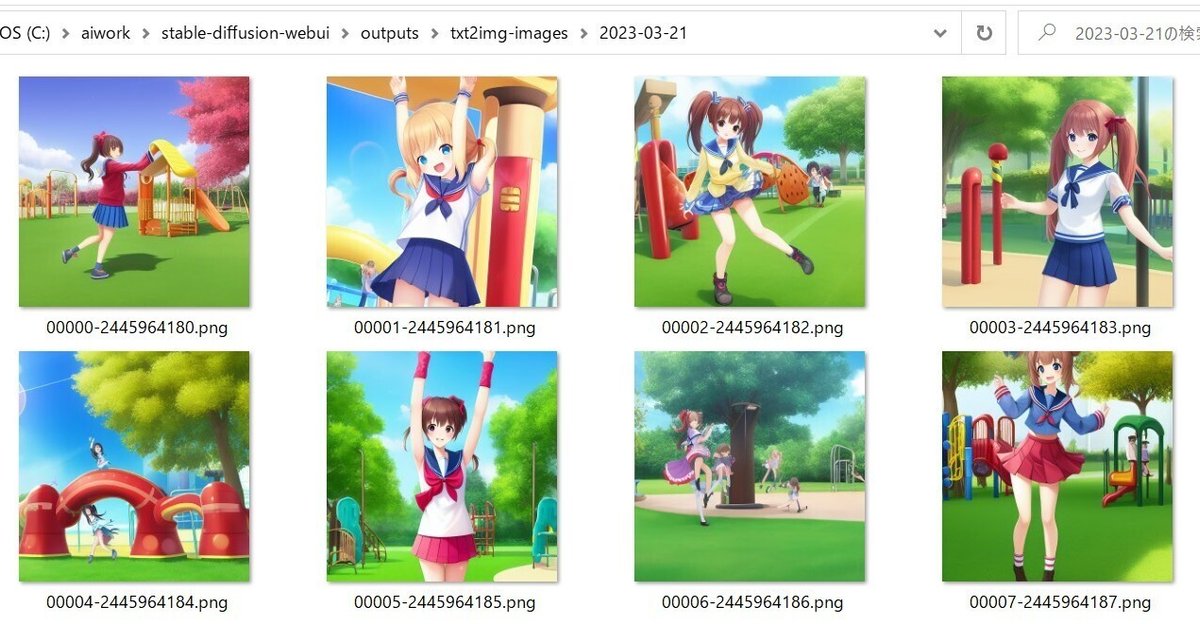
一度に複数の画像を生成することもできます。「Batch size」は1回あたりの生成枚数(VRAMの使用量を見ながら調整)、「Batch count」は繰り返しの回数、それぞれを掛けた数だけ生成されます。さらに、全てを連結した画像が「****-grids」ディレクトリに保存されます。
web UIの終了
起動に使用したコマンド プロンプトでCtrlを押しながらCを押します。「バッチ ジョブを終了しますか」の問いは、バッチの処理を中断したいかどうかで変わりますので一概には言えませんが、ここでは「N」を選んでください。うまくいかない場合はウインドウを閉じてください。おもむろに閉じても大丈夫だと思いますが、続けての作業ができなくなります。
使い方のヒント
モデルは「\aiwork\stable-diffusion-webui\models\Stable-diffusion」に置くように書きましたが、さらに下のディレクトリに置くこともできます。ジャンルや種類で分けたい場合に便利です。
Promptと生成される画像の対応については、以下の記事が参考になると思います。なお、モデルによって有効なPromptや効果が異なり、大きく異なる場合は他のモデルで使ったPromptの使い回しができない点に注意が必要です。
より良い画像を生成するためには、Promptの作り込みが重要になります。個人的には、AIイラスト専用の投稿サイトchichi-puiやAIPictorsに登録(Twitter連携で簡単にアカウントが作成が可能)してみるのがおすすめです。投稿された作品にはPrompt等の設定が掲載されている(投稿者が記載した場合のみ)ので、参考になるでしょう。
ちちぷい https://www.chichi-pui.com/
AIPictors https://www.aipictors.com/
以下のリンク先はテクニカル寄りな内容が多いですが、本記事では書かなかったweb UIの情報が掲載されています。
4. 付録1(推奨オプション)
web UIの導入について最小限の説明は終わりましたが、他にも何点かおすすめのノウハウがあるので説明します。
web UIをアップデートする方法
本記事の手順に従って「git clone」コマンドでダウンロードした場合は、以下のコマンドでアップデートができます。「Already up to date.」と表示された場合は最新の状態で、そうでない場合は何らかの情報が表示されてアップデートされたことが分かります。
cd \aiwork\stable-diffusion-webui
git pull何かエラーが出てしまった場合は、メッセージを検索すると解決方法が出てくるかもしれません(投げやり)。
起動用バッチファイルの作成
起動のたびに「\aiwork\stable-diffusion-webui」ディレクトリへ移動するのも手間なので、「\aiwork」ディレクトリにオプション設定も可能な起動用バッチファイルを置くことにします。
「\aiwork\stable-diffusion-webui\webui-user.bat」を「\aiwork」にコピーして、名前を「webui.bat」に変えてください(他の好きな名前でも構いません)。このファイルをテキストエディタで開き、「call webui.bat」の前後に下記と同じように記述を加えてください。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
cd stable-diffusion-webui
call webui.bat
cd ..これ以降にweb UIを起動する際は、以下のコマンドを実行してください。
cd \aiwork
webui また、web UIにはいくつかの起動オプションがありますので、必要があれば「COMMANDLINE_ARGS=」の後に記述してください。複数ある場合は半角スペースで区切ります。起動オプションの説明は下記のリンク先に書いてあります。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings
#オプション例
set COMMANDLINE_ARGS=--xformers --medvram推奨するオプションとして「--xformers」があります(詳細は後述)。また、VRAMが少なくて起動できなかった場合は「--medvram」や「--lowvram」を付けてみる必要があるかもしれません。
VAEを変更する方法
web UIでは、画像と潜在空間(Latent Space)の変換を行うVAE(Variational Auto-Encoder)を、別のものに変更することができます。別途VAEを用意して、使用するよう指示しているモデルもあります。ここでは例として、Waifu Diffusionのものを使ってみます。
まず https://huggingface.co/hakurei/waifu-diffusion-v1-4/tree/main/vae へアクセスして、「kl-f8-anime2.ckpt」をダウンロードしてください(「kl-f8-anime.ckpt」もダウンロードして構いません)。これを、「\aiwork\stable-diffusion-webui\models\VAE」に移動します。拡張子はそのままで構いません。モデルの「.ckpt」との混乱を避けたい場合は、「.pt」または「.vae.pt」に変更してください。
次にweb UIの「Settings」タブへ移動して、左側の「User interface」を選択してください(「Show all pages」でも構いません)。一覧の中から「Quicksettings list」の項目を探し、「sd_vae」を追加してください。
sd_model_checkpoint, sd_vae追加が終わったら画面一番上の「Apply settings」をクリックしてください。「** settings changed: ~~~~」の表示が出たら変更完了です。次に右の「Reaload UI」をクリックしてください。
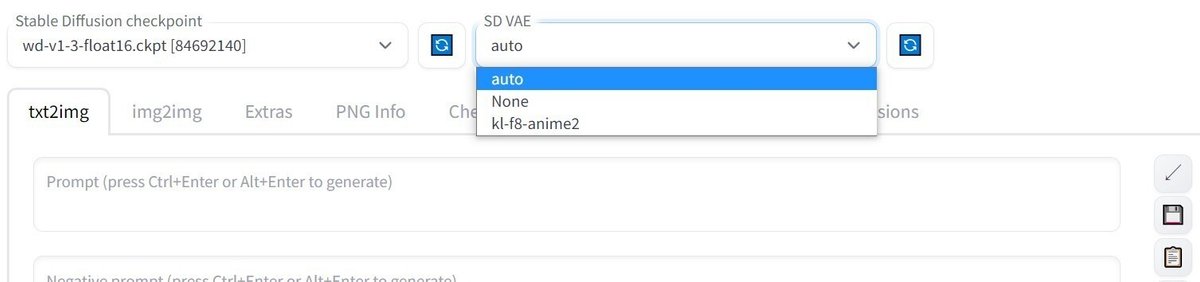
リロード後、画面上部にVAEのプルダウンメニューが表示されました。ただし、UI起動中に後から入れたファイルはそのままでは一覧に出てこないので、右側の青いアイコン(リロード?)をクリックしてください。
VAEはいつでも変更できるので、違いを確認することができます。Waifu Diffusion v1.3にkl-f8-anime2を当てたところ、瞳の表現が良くなったのが分かります。VAEが別途必要なモデルでは、VAEを指定しないとコントラストの低い画像が出力されたりする場合があります。
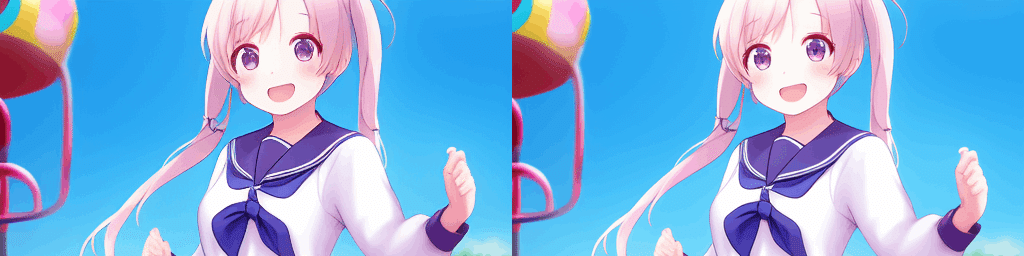
VAEに「auto」を選ぶと、モデルを変更した時にVAEを自動的に読み込みますが、設置方法が特殊ですので注意が必要です。VAEのファイルはモデルと同じ場所に置いて、ファイル名をそろえて拡張子を「~~~~.vae.pt」に変更してください。
まとめです。単体のVAEは、VAE用のディレクトリへ置いてください(「.pt」「.vae.pt」へ変更可)。VAEがあるモデルや、特定のVAEを適用したいモデルは、「~~~~.vae.pt」のファイルをモデルと同じディレクトリに設置してください。そして普段は「auto」のままで、必要なときだけ別のVAEに切り替える使い方が良いでしょう。
web UIでxFormersを使用する
Meta ResearchのxFormersを使用することで省メモリ化と高速化がはかれます。起動用バッチファイルに、下記のように「--xformers」のオプションを加えて起動してください。通常はこの方法でパッケージがインストールされて使用できます。その後もオプションはそのままにしてください。
set COMMANDLINE_ARGS=--xformersxFormers使用の有無は、web UIの画面の最下部に表示されるほか、コマンド プロンプトに出てくる表示でも分かります。
#--xformers未指定時
Applying cross attention optimization (Doggettx).
#--xformers指定時
Applying xformers cross attention optimization.xFormersが正しく動作しない場合は別途入手するか、自分でビルドする必要があります。
上記の記事ではxFormersの別途入手(さらに別の記事)やビルドの手順、web UIの環境にインストールする手順について説明しています。
LDSRのUpscalerを使えるようにする
メインの画面で「Hires. fix」にチェックを入れると、アップスケールの設定が表示されます。これは、解像度の縦横を任意の倍数に設定して出力する機能です。
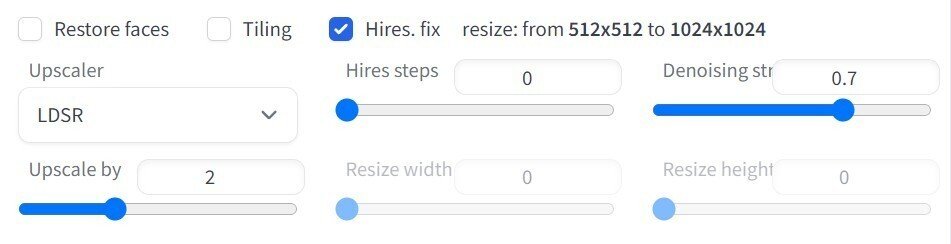
拡大の方法である「Upscaler」を変えると、初回の実行時に必要なファイルをダウンロードしてくれます。が、LDSRだけはうまくいきませんでした。その場合の手順を説明します。ただし、速度が非常に遅いものなので利用は推奨しません。
下記のURLへアクセスして、一番下にある「Download project.yaml and model last.cpkt.」の箇所から2つのファイルをダウンロードしてください。ファイルを「\aiwork\stable-diffusion-webui\models\LDSR」に移動し、先ほどの箇所の説明どおり、ファイル名をそれぞれ「model.ckpt」「project.yaml」に変更してください。
https://github.com/Hafiidz/latent-diffusion
5. 付録2(Stable Diffusion v2の情報)
現在のweb UIでは、下記の手順は基本的に必要ありません。画像の生成がうまくできなかった場合に参照してください。
v2系モデルの利用方法
2022年11月にStable Diffusion v2が公開されました。学習元の解像度が512x512と768x768の二種類あり、「base」の表記がある方が前者です。それから少し後に、より幅広い表現ができるように改良(?)されたStable Diffusion v2-1が公開されました。
これらは、web UIではモデルの設置のみでは動作せずエラーになりますので、対応方法を説明します。

まず、上記のリンク先から必要なモデルをダウンロードして、「\aiwork\stable-diffusion-webui\models\Stable-diffusion」に設置してください。ファイル名は「v2-1_512-ema-pruned.ckpt」「v2-1_768-ema-pruned.ckpt」です。noemaは用途が違うのでemaの方を選んでください。
次に、下記のいずれかのリンク先にアクセスしてください。使用するモデルによってファイルが異なります。
512x512のモデルの場合
https://github.com/Stability-AI/stablediffusion/blob/main/configs/stable-diffusion/v2-inference.yaml
768x768のモデルの場合
https://github.com/Stability-AI/stablediffusion/blob/main/configs/stable-diffusion/v2-inference-v.yaml
コード1行目の上の右側にある「Raw」を右クリックして保存したあと、ファイルをモデルと同じ場所に移動してください。これを必要分コピーして、モデルと同じファイル名に変更してください。
これで準備ができました。モデルの読み込みや画像の生成がうまくいかない場合は、コマンド プロンプト上でweb UIを終了してから起動し直してみてください。

本家以外のv2系モデルの場合は、配布先に.yamlのファイルがあればそちらを使用してください。無い場合は上記のいずれかを使用してください。現在のところ、派生モデルはほとんど512x512のモデルのようです。
6. 付録3(関連記事)
web UI上のLoRAで学習を行ってみた記事をご紹介します。
web UI上で実行するものではありませんが、DreamBoothで学習を行った記事もありますので紹介します。
7. twitterの連絡先
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?