
AUTOMATIC1111版Stable Diffusion web UI上でLoRAを利用する手順(Windows、VRAM 8GB以上、CUDA 11.6以上)

※本記事のLoRAは、あまり性能が良いとは言えませんのでご了承ください(お試しで学習方法を学びたい、程度であれば現在でも有効ですが、古い記事なので操作方法が変わっている可能性があります)。別のLoRAについて記事を公開した際は、こちらでお知らせします。
※DreamBoothのextensionが古いままの状態で本体をアップデートすると、本体が起動できなくなる場合があります。ご注意ください。
※東北ずん子さんの公式画像を学習した例が、「5. 学習例」にあります。先にそちらをご覧いただいても結構です。
※LoRAは多少の動作確認しかできておらず、適切な設定や詳細については分かりませんし、内容も誤り等があるかもしれません。ご了承ください。
1. 概要
目的
LoRA(Low-rank Adaptation)は、既存のDreamBoothよりも短時間で効率よく学習(ファインチューニング)ができる手法です。その他のメリットとしては、「使用メモリ(VRAM)がより少ない」「学習結果のデータが小さい」「学習結果を任意のモデルに結合できる」ことが挙げられます。
本記事では、AUTOMATIC1111氏のStable Diffusion web UI(以下web UI)上からLoRAを利用する手順を説明します。
ディレクトリ構成
本記事での作業ディレクトリは「\aiwork」です("\" は半角の "¥"と同じ)。主な構成は以下のとおりです。その他、学習に使用する画像が入っているディレクトリが必要です。
\aiworkディレクトリ内の構成
stable-diffusion-webui\ web UI本体
stable-diffusion-webui\models\dreambooth\ 変換後のモデル(DiffUsers)
stable-diffusion-webui\models\Stable-diffusion\ モデルの設置場所(ckpt)
stable-diffusion-webui\models\lora\ 学習結果の保存場所
webui.bat web UI起動用のバッチ本記事ではこれだけしか使用しませんが、他の用途でも「\aiwork」を使用するため、このような構成になっています。
ちなみに「\aiwork\webui.bat」ですが、「\aiwork\stable-diffusion-webu\webui-user.bat」を少しだけ書き換えたもので、ディレクトリを移動するのが手間なので用意したものです。基本は以下の内容です。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
cd stable-diffusion-webui
call webui.bat
cd ..必要に応じて「COMMANDLINE_ARGS=--xformers」にする等、オプションを追加してください。
PCの環境
バージョン11.6以上のCUDA Toolkit(CUDA)が必要です。その他、web UIが利用できる環境も必要です(Python 3.10は必須、Gitは推奨、詳細は以下の記事を参照)。
2. web UIのインストール
Windows PCでweb UIを利用する手順については、以下の記事で説明しています。未導入の方は、手順に従ってインストールと動作確認を行ってからweb UIを終了してください。
3. DreamBoothの環境を構築
LoRAはDreamBoothに含まれているようなので、web UI上でインストールします。事前の準備がありますので、web UIを起動していない状態で以下の作業を始めてください。
学習元モデルの用意
学習元にするStable Diffusionモデル(ckptファイル)は、あらかじめ「\aiwork\stable-diffusion-webui\models\Stable-diffusion」に置いてください。
PyTorchの差し替え
web UIにインストールされているPyTorch(torchとtorchvision)はCUDA 11.3用ですが、DreamBoothでは11.6用が必要との情報がありました。以下のコマンドを実行して差し替えてください。アンインストール時に確認があるので「y」を入力してください。バージョン自体は同じなので支障は無いと思います。
cd \aiwork\stable-diffusion-webui
venv\Scripts\activate
pip uninstall torch torchvision
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
deactivateここでxFormersが入っていると「xformers 0.0.14.dev0 requires pyre-extensions==0.0.23, which is not installed.」みたいに言われるようですが、そのままでも影響は無いと思います。試しに「pip install pyre-extensions==0.0.23」を実行したところ、「mypy-extensions-0.4.3 pyre-extensions-0.0.23 typing-inspect-0.8.0」がインストールされました。おそらく必要無いです。
DreamBoothのインストール
web UIを起動して、Webブラウザでアクセスしてください。
cd \aiwork
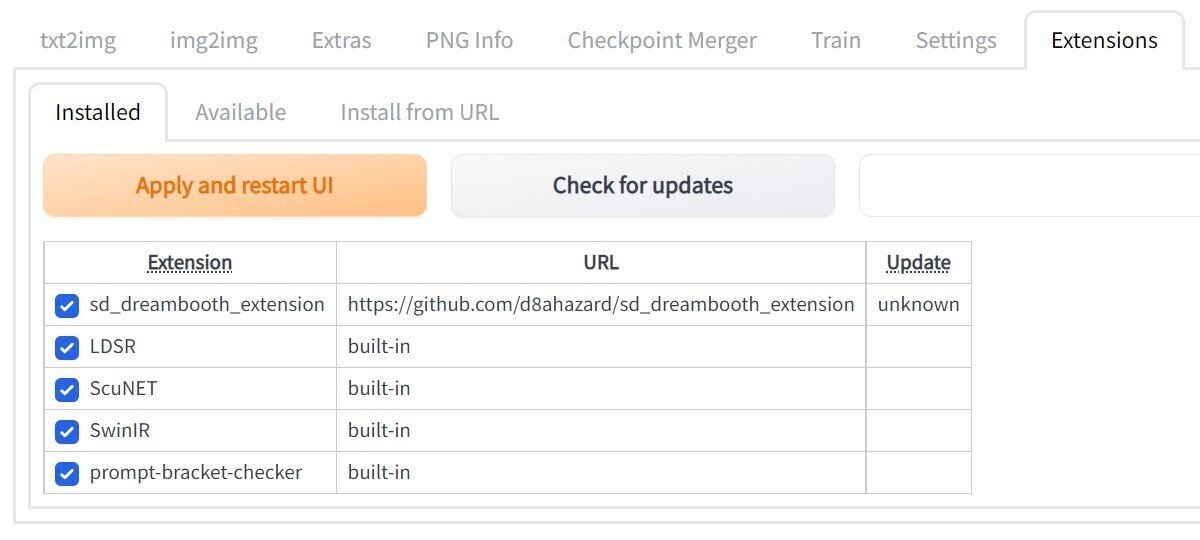
webuiweb UIの画面が出たら、「Extensions」「Available」の順にタブを切り替えてください。「Load from:」をクリックすると一覧が出てくるので、「Dreambooth」の右にある「Install」をクリックすると「Installing…」に変わります。インストイールが完了すると「Dreambooth」の行が消えます。
「Installed」のタブへ切り替えると、「sd_dreambooth_extension」が追加されていることがわかります。しかし「DreamBooth」のタブが無いので利用できません。web UIを終了して起動し直すと初期設定が行われ、起動完了後にWebブラウザをリロードすると表示されます。
4. LoRAを利用した学習
画像の準備
学習したい画像と正則化画像(無くても大丈夫ですが推奨します)は、予め用意しておいてください。どのような画像が良いのかは、「Classification Dataset」について記述しているあたりを参考にしてください。基本的にはDreamBoothと同じ要領です。正則化画像は、web UI上で「Class Prompt」を使用して生成する方法があります。
画像のサイズは512x512を基本とします。これより大きい場合は内部でリサイズされている模様です。正方形ではない画像が含まれる場合は、後述の「設定1」の画面で「Center Crop」にチェックを入れると上下か左右を切り落としてくれると思います(未確認)。左右反転した画像は不要です(「設定1」の「Apply Horizontal Flip」にデフォルトでチェックが入っています)。
モデルの変換
web UIが使用するモデルはStable Diffusion形式(ckpt)ですが、学習はDiffUsers形式に対して行うため変換が必要です。「Dreambooth」「Create Model」の順にタブを切り替えてください。次に、「Source Checkpoint」にて学習元にしたいモデルを選んで、「Name」に適当な名前を設定してください。最後に「Create」をクリックすると変換が始まります。
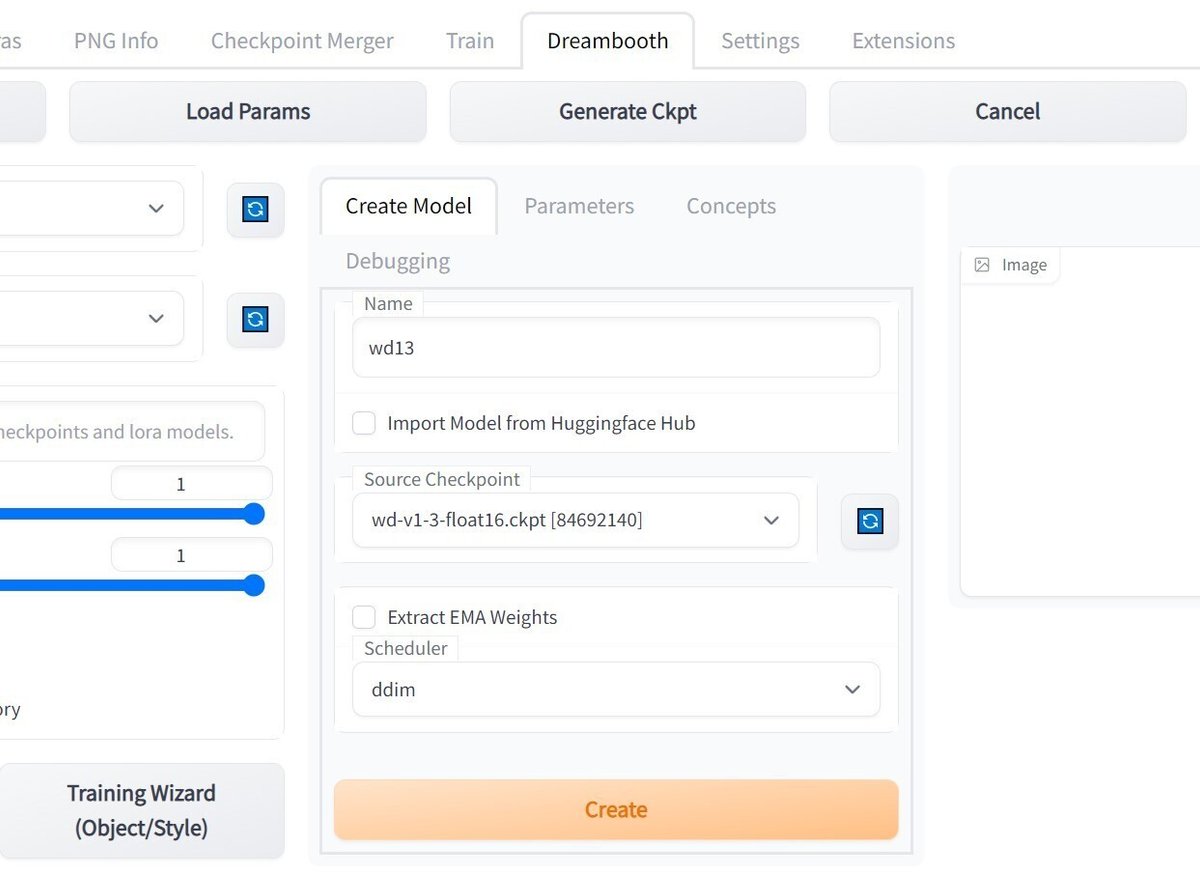
変換したモデルは「\aiwork\stable-diffusion-webui\models\dreambooth\(Name)」に保存されます。数GBになるので、不必要になったモデルはディレクトリごと削除することをおすすめします。
設定1
「Create Model」の隣にある「Parameters」のタブに切り替えてください。一番下に「Advanced」があるので三角をクリックして展開し、「Use LORA」にチェックを入れます(忘れないよう先に設定します)。

他にも見直すべき設定項目はありますが、まずは正常動作の確認を優先するべくそのままにしてください。
ここでは一点だけ、「Memory Attention」について説明します。xFormersが入っている場合は「xformers」を選択することができますが、「Mixed Precision」は「fp16」または「bf16」を選択する必要があります(「no」よりも精度は落ちます)。メモリに余裕がある場合は「default」を選択してください。それ以外の場合は、メモリ消費の少ない「flash attention」を選択してください(速度は落ちます)。基本的に、メモリ消費量と速度はトレードオフの関係にあります。
VRAMが8GBの場合は、「Use 8bit Adam=on」「Mixed Precision=fp16」「Memory Attention=flash attention」とするのが良いようです。実行できなかった場合は「Train Text Encorde=off」にしてみてください(学習効果は落ちます)。なお、デフォルトで有効になっている「Gradient Checkpointing」も、メモリを節約する設定です。
設定2
「Parameters」の隣にある「Concepts」のタブに切り替えてください。今回は「Concept1」のタブのみ設定します(2と3も同時に学習することは可能ですがリニアに時間が増えます)。
Dataset directory
学習したい画像が入ったディレクトリのパスを指定します。Classification Dataset Directory
正則化画像が入ったディレクトリを指定します。通常はこちらを指定して、ディレクトリに存在する画像の数を「Total Number of Class/Reg Images」に設定してください。指定したディレクトリに存在する画像の枚数が「Total Number of Class/Reg Images」よりも少ない場合は、足りない分だけ自動的に生成されます。
ディレクトリが空欄で「Total Number of Class/Reg Images」が1以上の場合は、「\aiwork\stable-diffusion-webui\models\dreambooth\(学習元Model名)\classifiers_0」のようなディレクトリが生成され、そのディレクトリに画像が生成されます。補足:DatasetとClassification DatasetとPromptについて
例として「女の子のAさん」を学習することを考えてみます。この時、「女の子のAさん」のプロンプトを「sks girl」、「(普通の)女の子」のプロンプトを「girl」に指定して、それぞれ画像と一緒に与えることとします。その結果、「女の子」に属する「Aさん」の特徴的な概念が、「sks」というプロンプトに紐付くようになります。Datasetは「Aさん」の画像を、Classification Datasetは「女の子」の画像を指定します。これらを考慮して、学習させたい概念と画像とPromptを決めてください。Filewords
各画像ファイルに対し、ファイル名が同じテキストファイルに書かれたプロンプトを設定するための仕組みです。今回は使用しません。Instance Prompt
Datasetの画像に対応するプロンプトを指定します。例えば、特定の女の子であれば「sks girl」、猫の写真であれば「photo of sks cat」などとします。「sks」に当たる部分は、モデルが認識(理解)できないような3文字が推奨されます。Kohya S氏は「shs sts scs cpc coc cic msm nen usu ici lvl」を候補として挙げています。複数の概念を学習させる場合は、別々の文字にする必要があります。Class Prompt
Classification Datasetの画像に対応するプロンプトを指定します。Instance Promptに対して、例えば「girl」「photo of cat」などとします。Total Number of Class/Reg Images
正則化画像の枚数を指定します。正則化画像のディレクトリに指定した枚数の画像がなければ、自動的に生成されます。0の場合は正則化画像を使用しない学習を行うようですが、このモードの動作は未検証です。
学習の実行
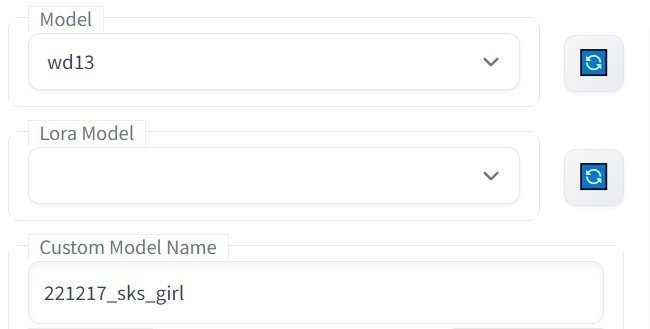
画面左上の部分にて、「Model」は変換後のモデルの名前を選択してください。「Custom Model Name」は学習結果のファイル名を入れますが、空欄の場合は「Model」の名前が使われるようです。「Lora Model」が選択されている場合、それが使用されるかどうかは未確認です。
以上で設定は終わりですので、動作することを祈りながら「Train」をクリックしてください。学習が始まると進捗が表示されます。学習が完了すると、コマンド プロンプトの方に以下のような表示が出ます。
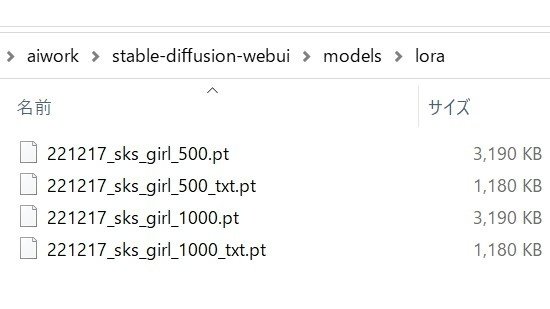
Returning result: Training finished. Total lifetime steps: 1000学習結果は「\aiwork\stable-diffusion-webui\models\lora」に保存されています。
モデルを結合
DiffUsersのモデルとLoRAのモデルを結合して、Stable Diffusionのモデルに変換します。結合する「Model」と「Lora Model」を選択して、「Generate Ckpt」をクリックしてください。結合されたモデルは「\aiwork\stable-diffusion-webui\models\Stable-diffusion」に保存されます。ファイル名は「Custom Model Name」に「_1000_lora.ckpt」のような文字が付加されるようです。
「Half Model」にチェックを入れると、生成されるモデルのファイルサイズが小さくなります。「Save Checkpoint to Subdirectory」にチェックを入れると、「Custom Model Name」の名前のディレクトリが生成されて、その中に保存されます。
5. 学習結果を確認してみる
モデルの選択
このままでは「Stable Diffusion checkpoint」の一覧に出てこないので、右側の青いボタンを押してからモデルを選んでください。

推論
モデルを選んで読み込みが終わったら「txt2img」のタブを選択して、Prompt等を設定して「Generate」をクリックすると画像が生成されます。まずは学習時に設定した「sks girl」等で確認してから、複雑なPromptにしていくのが良いと思います。生成した画像は「\aiwork\stable-diffusion-webui\outputs」の下に保存されます。
5. 学習例
短時間でお試し学習できる例を用意しました(その分、学習効果は弱いです)。動作確認も兼ねてチャレンジしてみてください。
学習用画像の準備
東北ずん子さんが公式イラストを学習に使っても良いと明言されているので、お言葉に甘えさせていただきます。
公式イラストのずん子達はファインチューニングや転移学習に利用して良いので、どんどんAIイラストにもチャレンジしてくださいねヽ(。>▽︎<。)ノ
— 東北ずん子💚C101南1F、12/30 ずんだホライずん放送TokyoMX (@t_zunko) October 29, 2022
イラストは、公式サイトの「コンテンツ」→「イラスト/3D」にあります。今回は短時間で済むことを優先したいので、厳選した5枚を適当なディレクトリに置いておきます(枚数と実行時間は比例します)。

デフォルトで左右反転画像の学習が行われるので、左右反転しただけ(特に顔が)みたいな画像は必要ないと思います。
モデルの変換
それでは作業を始めるためにweb UIを使用します。DreamBoothが利用可能な状態になっていることが前提です。
まず、学習に使用するモデルをDiffUsers形式に変換します。今回はWaifu Diffusion v1.3(https://huggingface.co/hakurei/waifu-diffusion-v1-3)の「Float 16 EMA Pruned」を使用しました。こちらは「2. web UIのインストールと起動」で紹介した別記事に導入方法が書いてあります。
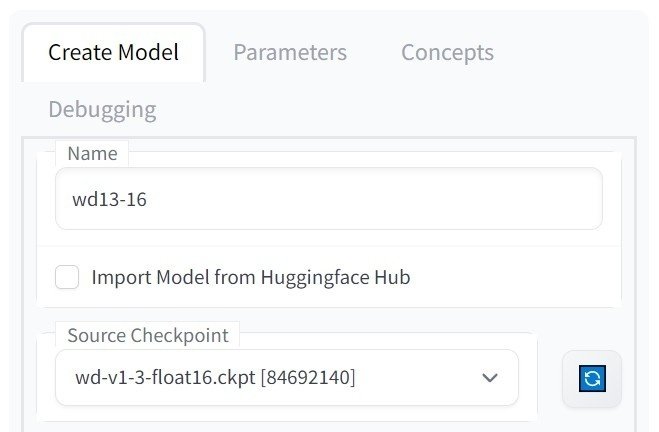
上記のように設定して「Create」をクリックすると、変換されたモデルが「\aiwork\stable-diffusion-webui\models\dreambooth\wd13-16」に保存されます。
学習の設定
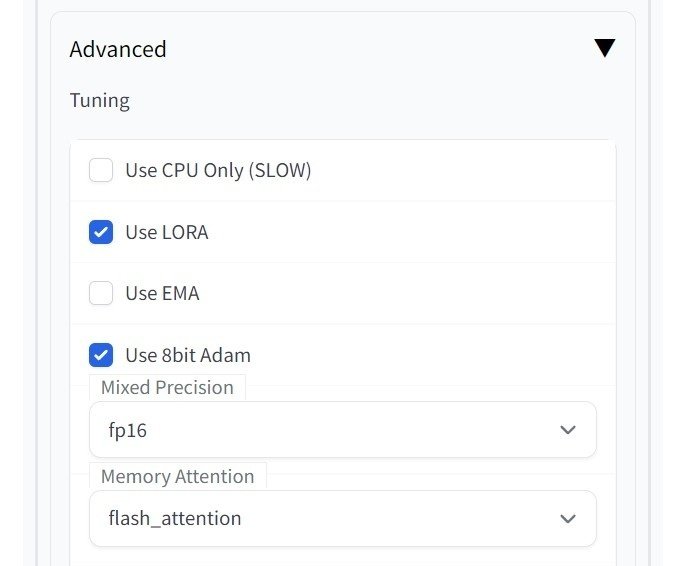
続いて「Parameters」のタブをクリックします。下の方の「Advanced」にある三角をクリックすると開くので、設定を行います。以下は一例として、VRAMが8GBでも動作する内容となっています。もしメモリ不足で実行できなかった場合は、「Train Text Encoder」のチェックを外してください。なお、「Use LORA」にチェックを入れないとDreamBoothになってしまうのでご注意ください。
次は「Concepts」のタブです。まず、先ほど画像を置いたディレクトリを指定します。画像の解像度はいずれも512x512ではありませんが、正しく学習できたので内部でリサイズしている模様です。正則化画像のディレクトリは、何も入っていないディレクトリを作っておきました。

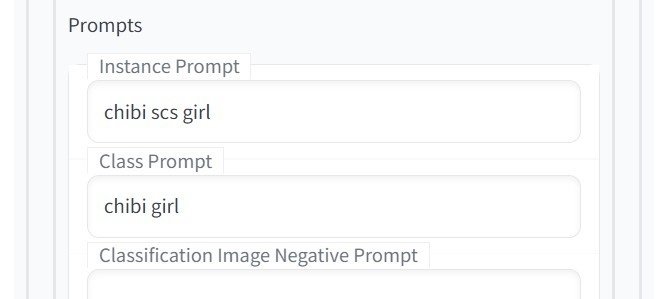
学習で使用するPromptを設定します。Waifu Diffusionではデフォルメキャラとして「chibi」のPromptが有効なので、「chibi scs girl」と「chibi girl」にしました。
正則化画像の数は学習用画像の10倍程度が良いそうなのですが、今回は時間優先なので「10」に設定します(画像の生成にかなり時間がかかるためです)。

学習の実行
以上で準備が整いましたが、念のためモデルの設定を確認してください。

それでは「Train」をクリックします。

コマンド プロンプトの画面に進捗が表示されます。正則化画像の数を10に設定したのに画像が1枚も無いので、10枚が自動生成されます。
Concept requires 10 images.
Class dir C:\aiwork\class_chibi_girl has 0 images.続いて学習が始まります。VRAMの消費は7GB少々(タスク マネージャーで確認)、学習にかかった時間は10分近くでした。
モデルを結合
学習したデータとモデルを結合させます。結合元モデル2つと結合後の名前を設定して「Generate Ckpt」をクリックすると実行されます。他のモデルと結合することもできます。
推論
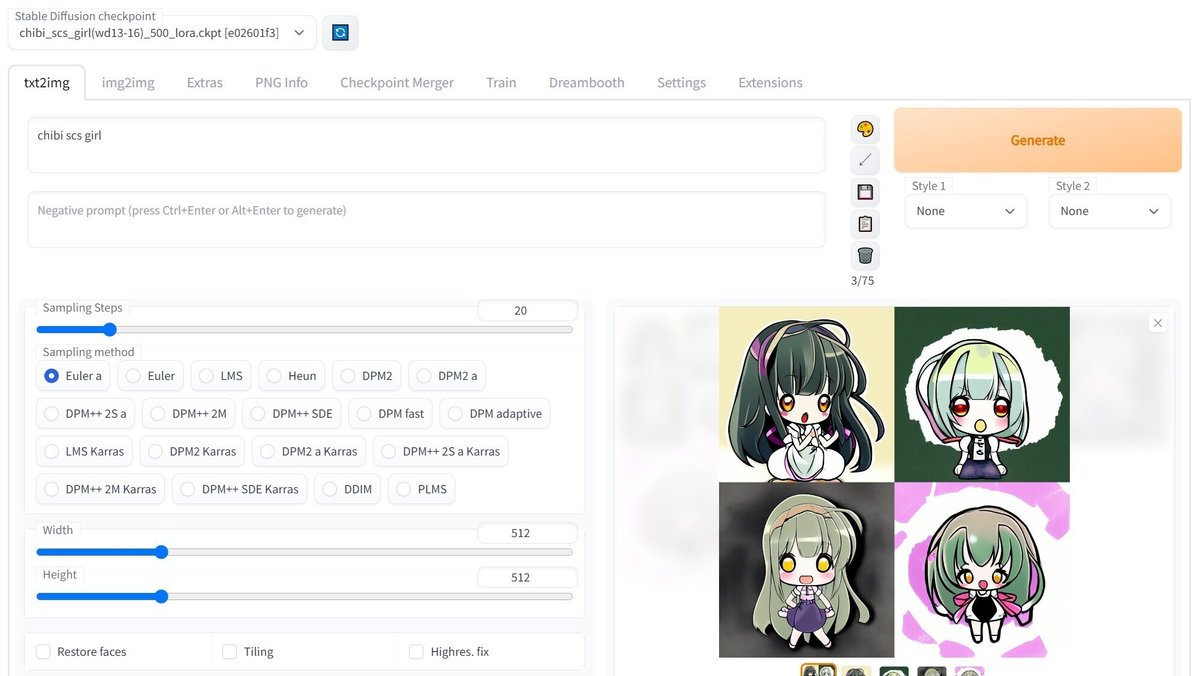
それでは学習の成果を確認しましょう。上段のタブを「txt2img」に変更します。最上部のモデル選択で結合したモデルが一覧に無いので、右側にある青いアイコンのボタンを押してください。これで選べるようになります。
まずは、学習時に指定した「chibi scs girl」のみで試してみます。「Batch count」を変更すると、指定した枚数を一度に生成してくれます。「Generate」ボタンを押すと生成を開始します。
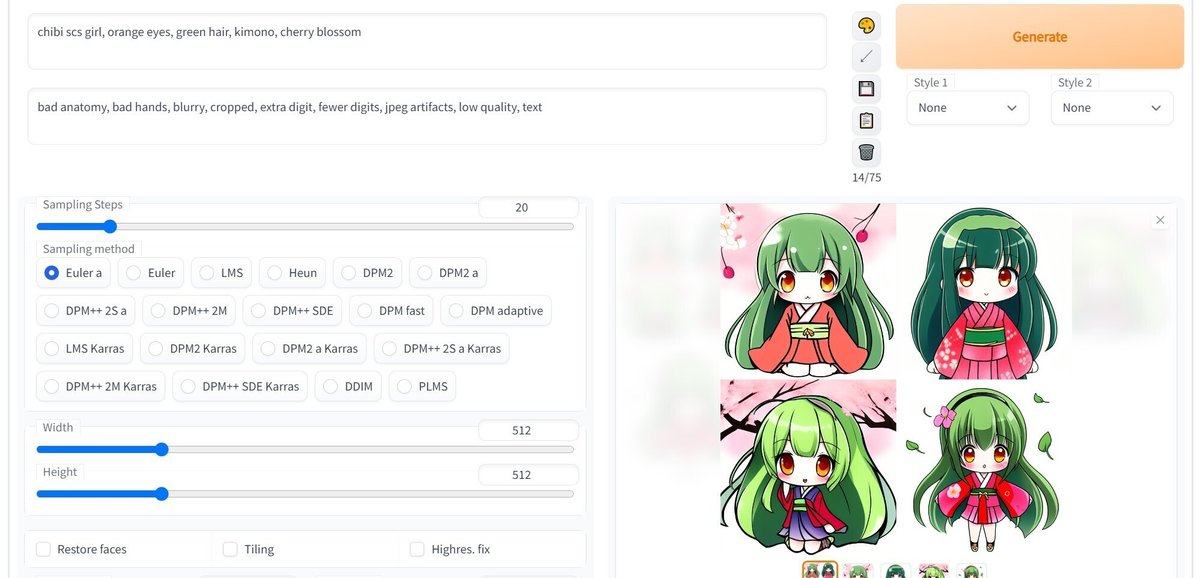
Promptを変えると出力も変わるので、遊んでみてください。余裕があれば、学習や結合に使用するモデルを変えてみるのも良いでしょう。
なお、生成した画像は「\aiwork\stable-diffusion-webui\outputs」の下に保存されます。大量に出力させておいて、後でじっくり選ぶという使い方ができます。
コメント
今回はお試しレベルにとどめましたが、「chibi scs girl」で出力された画像から、元の画像の特徴が学習されている様子が確認できました。数十枚ほど出力したり、「chibi girl」の出力と比較したりすると分かりやすいです。
学習させる画像の枚数を増やすか、Training Steps Per Imageの値を上げるだけでも学習効果は上がると思います。また、正則化画像をきちんと用意してやることにも意味があるかもしれません。さらに良い効果を得たい場合はDreamBoothが良いでしょう。下記の記事を参照してください。
6. 補足
未確認事項
同じ名前の(変換した)モデルに対して複数回の学習を行うと、左下に表示されている「Model Revision」が上がっていき、学習終了時の「Total lifetime steps」の表示や、ファイル名に付加される数字も上がります。追加学習ができるものと思われますが、使い方などの詳細は不明です。確認ができたら追記したいところですが、既にそれっぽい設定項目があることは確認済みです(デフォルトで「Use Lifetime Steps/Epochs When Saving」にチェックが入っている)。
その他
LoRAを利用する場合はweb UIの起動オプションに「--test-lora」を付ける、という情報がありますが必要ありませんでした。このオプションが現在も実装されているか、されている場合の挙動がどうなのかは未確認です。
7. twitterの連絡先
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?