
Amazon SageMakerを使ってAWSサービス一覧をCSV形式で出力する

サマリー
Amazon SageMakerのノートブックインスタンスを作成すると、自分のPCにanacondaをインストールしなくても、手軽にJupyter Notebookが使えて便利です。
この記事では、Amazo SageMakerでJupyter Notebookを使い、AWSのサービス一覧のHTML内の表からCSVファイルを作成する方法をご紹介します。
Jupyter Notebookを起動するまで
AWSマネジメントコンソールでのノートブックインスタンスの作成
公式のデベロッパーガイドを参考に作成します。
AWSマネジメントコンソールにIAMユーザーでログインする
利用リージョンを選択して"Amazon SageMaker"を開く
左のメニューから[ノートブック]を展開して[ノートブックインスタンス]を開く
[ノートブックインスタンスの作成]を選択する
[ノートブックインスタンスの作成]ページで以下を入力し、[ノートブックインスタンスの作成]をクリック
[ノートブックインスタンス設定]は例えば以下のように入力する
ノートブックインスタンス名:英数字またはハイフンで名前を適当につける
[ノートブックインスタンスのタイプ]:試行用でスペックにこだわりがない場合は初期表示"ml.t3.medium"を選択(用途によってお財布と相談しながら適切なスペックを選ぶ)
[Elastic Inference]:デフォルト(なし)
今回のユースケースでは必要なし。気になる人はこちらを参照「Amazon Elastic Inference よくある質問」(https://aws.amazon.com/jp/machine-learning/elastic-inference/faqs/)
[プラットフォーム識別子]:デフォルト(Amazon Linux2, Jupyter Lab3)
[アクセス許可と暗号化]
[IAMロール]:Amazon SageMaker ExcecutionRoleが未作成なら新規作成
筆者は新規作成したロールに「AmazonSageMakerFullAccess 」というポリシーを付与しました
[ルートアクセス - オプション]:有効化 ノートブックへのルートアクセス権をユーザーに付与する
詳しく知りたい人はこちら参照「Control root access to Amazon SageMaker notebook instances」
[暗号化キー - オプション]:カスタム暗号化なし
取り扱うデータの機密性が高い場合はKMSキーを選ぶか、KEYのARNを入力する。今回のユースケースでは不要
[ネットワーク - オプション]
[VPC - オプション]:非VPC(SageMaker で提供されたインターネットアクセス)
企業のポリシーでプライベートネットワークの環境で使いたい場合にはVPC内にノートブックインスタンスを作る方がよいのかもしれません
[Gitリポジトリ - オプション]:リポジトリなしで作成
[タグ - オプション]:タグ未指定
そこそこの規模で使うときは活用したほうがよいかもしれません
ノートブックを開く
ノートブックインスタンスを作成し、利用可能になったら[ステータス]が"InService"に変わる。[アクション]で"Jupyterを開く"リンクをクリックする
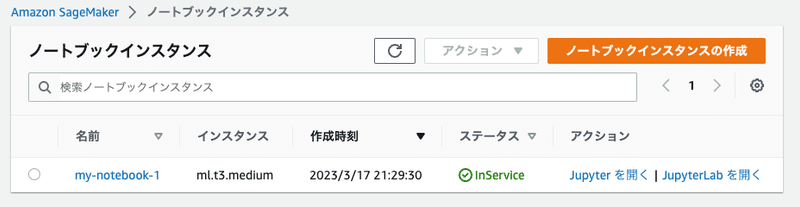
ノートブックを操作する
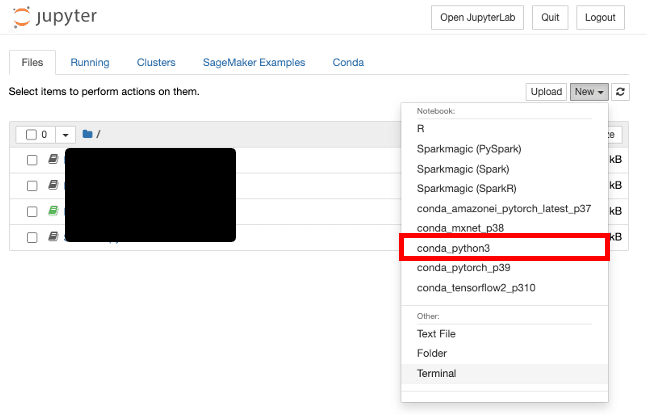
新しくノートブックを作成する
[New]で"conda_python3"を選んでノートブックを作成する
ノートブックが開いたら適当に名前を付ける
必要なパッケージを追加する(Terminal操作)
追加のPythonパッケージを導入するときは[New]-[Terminal]を開く
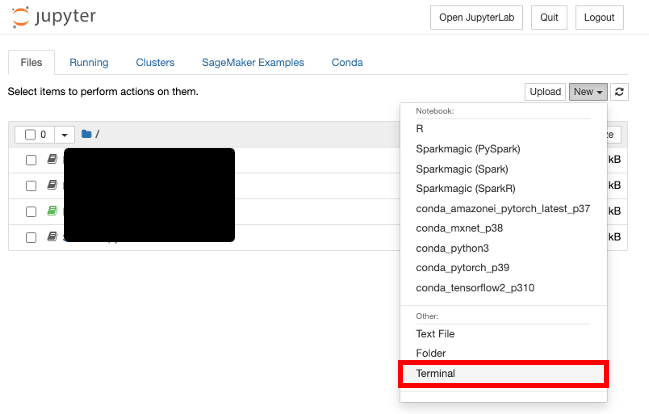
ブラウザの新しいタブが開きTerminalが起動する
今回のユースケースでは、Terminalで以下のコマンドを順番に入力してEnterキーで実行する
source activate python3
pip install requests beautifulsoup4 lxml
参考「Amazon SageMaker ノートブックインスタンスの Conda 環境に Python パッケージをインストールするにはどうすればよいですか?」
ノートブックに命令を入力する
以下1行ずつ[In:]に入力して[Run]を選択し、逐次実行しながら作りました。
# pandasをインポート
import pandas as pd# requestsをインポート
import requests# lxmlをインポート
import lxml# AWS services mapped to AWS regionsのhtmlファイルをurlに指定
url = "https://aws-new-features.s3.us-east-1.amazonaws.com/html/aws_services.html"# urlで指定したhtmlよりテーブル形式のデータを読み込む
data = pd.read_html(url, header = 0)# data[0](1つ目の表)の内容を先頭から5行確認する
data[0].head()# data[0]の内容を最終行から5行確認する
data[0].tail()# data[1](2つ目の表)の内容を先頭から5行確認する
data[1].head()# data[1]の内容を最終行から5行確認する
data[1].tail()# 1つ目の表のデータをdf0に入れる
df0 = pd.DataFrame(data[0])# 2つ目の表のデータをdf0に入れる
df1 = pd.DataFrame(data[1])# df0からCSVファイルを作成する(ノートブックと同じディレクトリ)
df0.to_csv('./aws_services_mapped_region_1.csv', index=False)# df1からCSVファイルを作成する(ノートブックと同じディレクトリ)
df1.to_csv('./aws_services_mapped_region_2.csv', index=False)実行結果を確認する
ノートブックと同じディレクトリ(例では「Test」)に2つCSVファイルができた
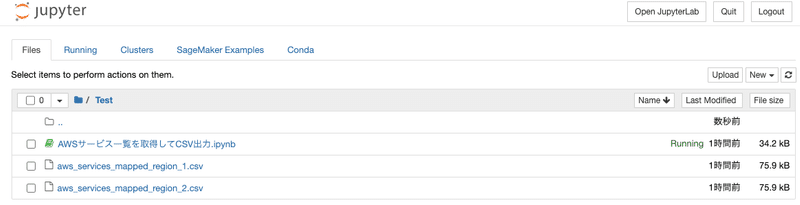
ダウンロードして中を開く
例はNumbersで開いたイメージを部分的に表示したもの

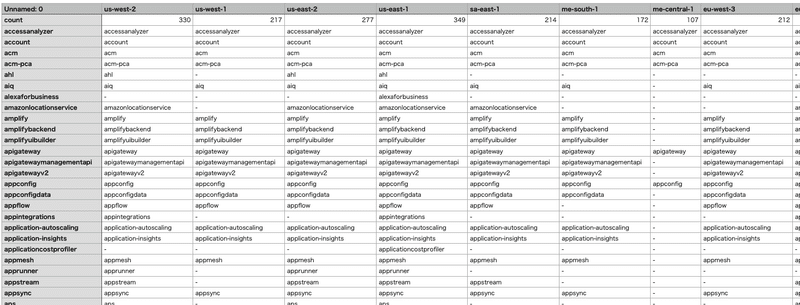
後片付け
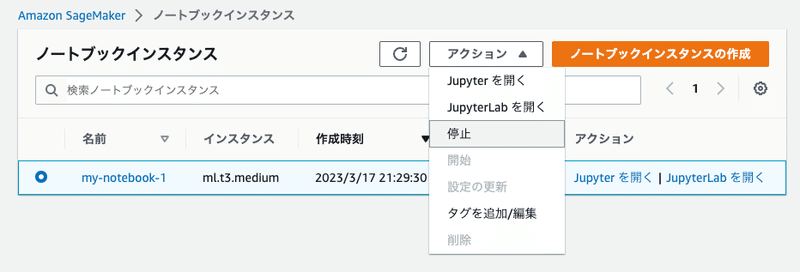
ノートブックを操作しないときは、ノートブックインスタンスを停止しましょう
もう不要なら、停止した後でノートブックインスタンスを削除します
おわりに
Amazon SageMakerを使うと、自分のPCにanacondaをインストールしなくても、手軽にJupyter Notebookが使えて便利!
組織で大規模に使うこともできるし、個人でちょこっと使うこともできるのがいい。筆者は業務ではまだAmazon SageMakerを使ったことがありませんが、時間を見つけていろいろ触ってみたいと思います。
以下のような動画も見ました。今後、業務で大規模な機械学習環境を構築する機会があればアーキテクチャの参考にできそう!
この記事が気に入ったらサポートをしてみませんか?